Глубокое обучение, проклятие размерности и автокодировщики
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2016-06-16 12:29

Автокодировщик (autoencoder) - это впечатляющий новый подход к машинному обучению без учителя. Во многих задачах данный подход позволил превзойти методы, наработанные в процессе многолетней практики ручного отбора признаков.
Предположим, что мы работаем над проектом по обработке изображений, и нашей задачей является создание алгоритма, способного идентифицировать эмоции, выраженные на лице человека. Мы хотим, чтобы наш алгоритм принимал на входе изображение в градациях серого размером 256-256 пикселей, а на выходе давал ответ, характеризующий выражение лица. Например, если передать алгоритму следующее изображение, мы ожидаем, что он классифицирует выражение лица, как «веселое».

Изображение веселого человека.
В целом, это вроде бы хороший подход, но прежде, чем мы на нем остановимся, давайте подумаем, что же он на самом деле означает. Изображение в градациях серого размером 256-256 соответствует входному вектору, содержащему более 65000 измерений! Другими словами, мы пытаемся решить задачу в 65000-мерном пространстве. Это не так просто сделать даже для компьютера! Многомерные входные данные не только сложно хранить, перемещать и обрабатывать, большая размерность также порождает некоторые другие серьезные проблемы.
Размерность экспоненциально усложняет решение задачи
Давайте разберемся, как сложность задачи машинного обучения зависит от размерности. Согласно исследованию, проведенному в 1982 году, время, необходимое для обучения модели (в частности, непараметрической регрессии), в лучшем случае пропорционально выражению 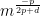
Мы можем продемонстрировать описанную выше взаимосвязь графически. Алгоритм равномерно делит пространство признаков на интервалы и отображает все обучающие примеры. Затем каждому интервалу мы присваиваем метку, соответствующую классу, преобладающему в этом интервале. Наконец, чтобы классифицировать любой новый пример, необходимо лишь определить интервал, в который попадает этот пример!
Для нашей демонстрационной задачи вначале мы возьмем один признак (т.е. одномерный вход) и разобьем пространство этого признака на 3 интервала:

Простая задача с одномерным входом.
Мы видим, что классы существенно накладываются друг на друга, поэтому мы добавляем второй признак, чтобы улучшить отделимость классов. Однако если количество обучающих примеров останется прежним, мы получим сильно разреженные двумерные данные. На основе этих разреженных данных очень трудно будет установить какие-либо значимые взаимосвязи, если не увеличить количество обучающих примеров. Если мы перейдем к трехмерным входным данным, ситуация ухудшится еще больше, поскольку теперь мы будем заполнять еще большее количество ячеек пространства (33 = 27) тем же количеством обучающих примеров. Трехмерное пространство будет почти пустое!
С увеличением размерности разреженность увеличивается экспоненциально.
Важно отметить, что эту проблему невозможно легко решить с помощью более эффективных вычислений или модернизированного оборудования! Для многих задач машинного обучения сбор обучающих примеров является наиболее трудоемким этапом. Следовательно, описанная выше закономерность вынуждает нас обращать особое внимание на размерность данных. Если мы сможем преобразовать входные данные к достаточно малому количеству измерений, нерешаемая в исходной форме задача может стать вполне решаемой!
Отбор признаков вручную
Вернемся к исходной задаче классификации выражения лица. Очевидно, что для решения данной задачи нам не нужны все 65000 измерений. В частности, существуют определенные ключевые признаки, которые наш мозг автоматически использует, чтобы быстро определить, какие эмоции выражает лицо человека. Например, кривая губ, изгиб бровей, а также форма глаз помогают нам понять, что человек улыбается. Данные признаки можно обобщить, оценив расстояния между различными ключевыми точками лица.

Ключевые точки, определяющие выражение лица.
Этот подход позволяет нам существенно уменьшить размерность входных данных (с 65000 до примерно 60), но здесь есть определенные ограничения! Чтобы выработать эффективную методику ручного отбора признаков, могут потребоваться годы исследований. Кроме того, во многих случаях значимые признаки не так легко выразить. Например, очень трудно отобрать признаки для обобщенного распознавания объектов, где алгоритм должен эффективно классифицировать птиц, лица, автомобили и т.д. Так каким же образом мы можем извлечь из входных данных наиболее информативные измерения? Ответ на этот вопрос дает раздел машинного обучения, называемый обучением без учителя.
Далее мы рассмотрим автокодировщик - алгоритм машинного обучения без учителя, основанный на нейронной сети, который был впервые применен Джеффри Хинтоном (Geoffrey Hinton). Мы кратко рассмотрим принцип действия автокодировщика, а также сравним его с традиционными линейными подходами, такими как метод главных компонент (principal component analysis, PCA), применяемый в области компьютерного зрения, и латентно-семантический анализ (latent semantic analysis, LSA), применяемый в области обработки естественного языка.
Краткий обзор автокодировщика
Автокодировщик - это алгоритм машинного обучения без учителя основанный на нейронной сети, который преобразует входные данные большой размерности в представление малой размерности. Традиционно уменьшение размерности выполняется с помощью линейных методов, таких как PCA, который находит направления максимальной дисперсии во входных данных большой размерности. Таким образом PCA стремится выделить направления, несущие максимальное количество информации, соответственно, мы получаем максимально информативное представление, содержащее минимальное количество измерений. Однако, вследствие линейности, возможности PCA существенно ограничены. Автокодировщик позволяет преодолеть эти ограничения благодаря свойственной нейронным сетям нелинейности.
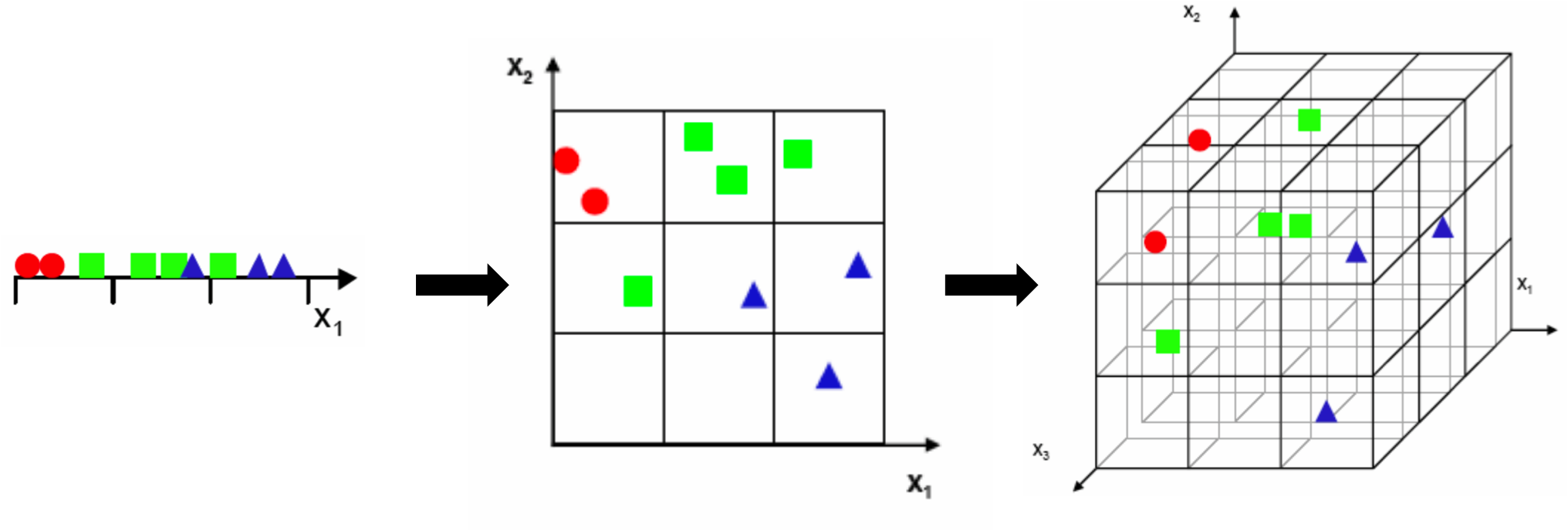
Базовая структура автокодировщика.
Двумя основными компонентами автокодировщика являются две нейронные сети, одна из которых называется кодировщиком (encoder), а другая - декодировщиком (decoder). Кодировщик используется как во время обучения, так и во время применения, тогда как декодировщик используется только во время обучения. Задачей кодировщика является формирование сжатого представления входных данных. В нашем случае мы генерируем 30-мерное представление на основе 2000-мерных входных данных. Декодировщик представляет собой отражение кодировщика и предназначен для восстановления исходных данных с максимально возможной точностью. В процессе обучения декодировщик стимулирует формирование наиболее информативного сжатого представления. Чем точнее восстановленный вход соответствует оригиналу, тем лучше сжатое представление!
Давайте сравним автокодировщик с его линейными конкурентами. Рассмотрим ряд экспериментов, выполненных Хинтоном (Hinton) и Салахутдиновым (Salakhutdinov) в 2006 году на этапе дебюта технологии. Во-первых, давайте посмотрим, насколько точно автокодировщик и PCA способны восстановить оригинальные входные данные на основе 30-мерного сжатого представления.
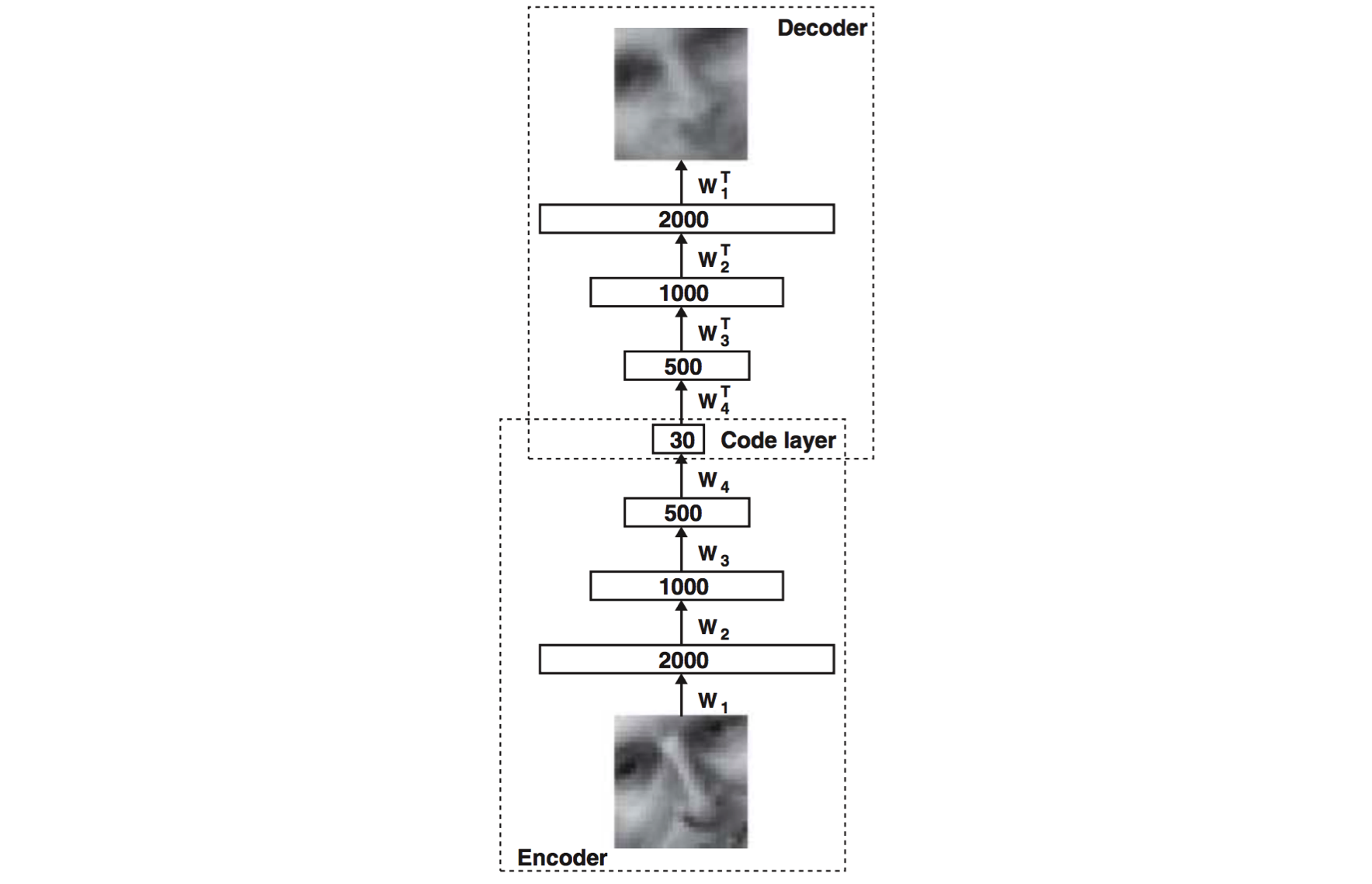
Сравнение точности восстановления исходных данных.
Верхний ряд - оригинальные входные изображения.
Средний ряд - результат восстановления с помощью автокодировщика.
Нижний ряд - результат восстановления с помощью PCA.
Результат автокодировщика выглядит заметно лучше, чем результат PCA, что является многообещающим началом.
Теперь давайте посмотрим, может ли автокодировщик улучшить отделимость классов в наборе рукописных цифр MNIST. Сравним двумерные представления, сгенерированные с помощью автокодировщика и PCA.

Сравнение отделимости классов на основе двумерных представлений, сгенерированных с помощью PCA (слева) и автокодировщика (справа) для набора данных MNIST.
Наконец, еще более существенное преимущество автокодировщика наблюдается при сравнении с методом LSA, который является золотым стандартом в сфере обработки естественного языка.
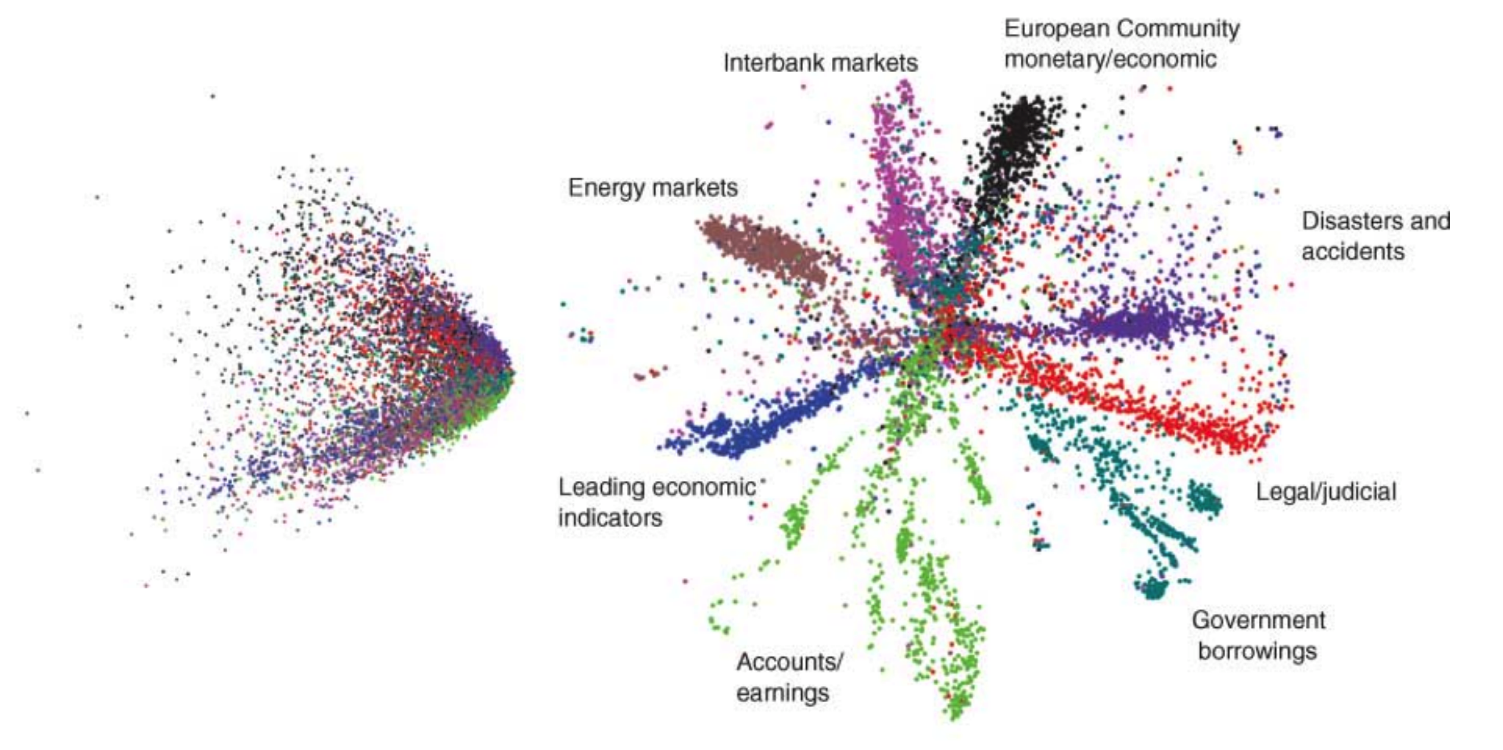
Сравнение отделимости классов на основе двумерных представлений, сгенерированных с помощью LSA (слева) и автокодировщика (справа) для набора новостных сообщений.
Заключение
Автокодировщик - это впечатляющая техника машинного обучения без учителя, во многих задачах позволившая превзойти методы ручного отбора признаков! В сегодняшней статье мы рассмотрели основы, являющиеся лишь вершиной айсберга. В следующей статье мы более подробно рассмотрим принципы работы автокодировщиков, эффективные методы их обучения и другие подходы, направленные на оптимизацию.
Телеграм: t.me/ainewsline
Источник: datareview.info