Это нужно знать: Ключевые рекомендации по глубокому обучению (Часть 2)
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2016-04-13 12:51
Во второй части статьи мы продолжаем обсуждение тонкостей глубокого обучения.
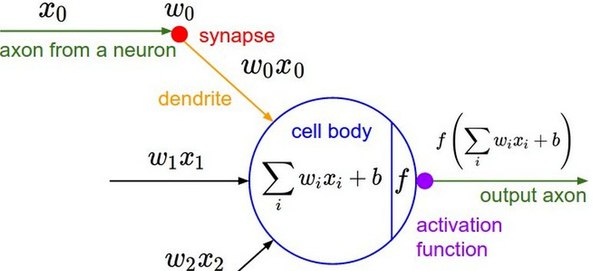
5. Выбор функций активации
Одним из важнейших аспектов глубокой нейронной сети является функция активации (activation function), которая привносит в сеть нелинейность. Далее мы рассмотрим распространенные функции активации и дадим рекомендации по их выбору.

Сигмоида

Сигмоида (sigmoid) выражается следующей формулой: s(x) = 1 / (1 + e-x). Эта функция принимает на входе произвольное вещественное число, а на выходе дает вещественное число в интервале от 0 до 1. В частности, большие (по модулю) отрицательные числа превращаются в ноль, а большие положительные - в единицу. Исторически сигмоида находила широкое применение, поскольку ее выход хорошо интерпретируется, как уровень активации нейрона: от отсутствия активации (0) до полностью насыщенной активации (1).
На текущий момент сигмоида утратила свою былую популярность и используется очень редко. Данная функция имеет два серьезных недостатка:
- Насыщение сигмоиды приводит к затуханию градиентов. Крайне нежелательное свойство сигмоиды заключается в том, что при насыщении функции с той или иной стороны (0 или 1), градиент на этих участках становится близок к нулю. Напомним, что в процессе обратного распространения ошибки данный (локальный) градиент умножается на общий градиент. Следовательно, если локальный градиент очень мал, он фактически обнуляет общий градиент. В результате, сигнал почти не будет проходить через нейрон к его весам и рекурсивно к его данным. Кроме того, следует быть очень осторожным при инициализации весов сигмоидных нейронов, чтобы предотвратить насыщение. Например, если исходные веса имеют слишком большие значения, большинство нейронов перейдет в состояние насыщения, в результате чего сеть будет плохо обучаться.
- Выход сигмоиды не центрирован относительно нуля. Это свойство является нежелательным, поскольку нейроны в последующих слоях будут получать значения, которые не центрированы относительно нуля, что оказывает влияние на динамику градиентного спуска (gradient descent). Если значения, поступающие в нейрон, всегда положительны (например, x > 0 поэлементно в f = yTx + b), тогда в процессе обратного распространения ошибки все градиенты весов y будут либо положительны, либо отрицательны (в зависимости от градиента всего выражения f). Это может привести к нежелательной зигзагообразной динамике обновлений весов. Однако следует отметить, что когда эти градиенты суммируются по пакету, итоговое обновление весов может иметь различные знаки, что отчасти нивелирует описанный недостаток. Таким образом, отсутствие центрирования является неудобством, но имеет менее серьезные последствия, по сравнению с проблемой насыщения.
Гиперболический тангенс

Гиперболический тангенс (hyperbolic tangent, tanh) принимает на входе произвольное вещественное число, а на выходе дает вещественное число в интервале от -1 до 1. Подобно сигмоиде, гиперболический тангенс может насыщаться. Однако, в отличие от сигмоиды, выход данной функции центрирован относительно нуля. Следовательно, на практике всегда предпочтительнее использовать гиперболический тангенс, а не сигмоиду.
ReLU
 В последние годы большую популярность приобрела функция активации под названием «выпрямитель» (rectifier, по аналогии с однополупериодным выпрямителем в электротехнике). Нейроны с данной функцией активации называются ReLU (rectified linear unit). ReLU имеет следующую формулу f(x) = max(0, x) и реализует простой пороговый переход в нуле.
В последние годы большую популярность приобрела функция активации под названием «выпрямитель» (rectifier, по аналогии с однополупериодным выпрямителем в электротехнике). Нейроны с данной функцией активации называются ReLU (rectified linear unit). ReLU имеет следующую формулу f(x) = max(0, x) и реализует простой пороговый переход в нуле.
Рассмотрим положительные и отрицательные стороны ReLU.
Положительные стороны:
- Вычисление сигмоиды и гиперболического тангенса требует выполнения ресурсоемких операций, таких как возведение в степень, в то время как ReLU может быть реализован с помощью простого порогового преобразования матрицы активаций в нуле. Кроме того, ReLU не подвержен насыщению.
- Применение ReLU существенно повышает скорость сходимости стохастического градиентного спуска (в некоторых случаях до 6 раз [Krizhevsky et al.]) по сравнению с сигмоидой и гиперболическим тангенсом. Считается, что это обусловлено линейным характером и отсутствием насыщения данной функции.
Отрицательные стороны:
- К сожалению, ReLU не всегда достаточно надежны и в процессе обучения могут выходить из строя («умирать»). Например, большой градиент, проходящий через ReLU, может привести к такому обновлению весов, что данный нейрон никогда больше не активируется. Если это произойдет, то, начиная с данного момента, градиент, проходящий через этот нейрон, всегда будет равен нулю. Соответственно, данный нейрон будет необратимо выведен из строя. Например, при слишком большой скорости обучения (learning rate), может оказаться, что до 40% ReLU «мертвы» (то есть, никогда не активируются). Эта проблема решается посредством выбора надлежащей скорости обучения.
В настоящее время существует целое семейство различных модификаций ReLU. Далее мы рассмотрим их особенности.

Для LReLU ai имеет фиксированное значение, для PReLU ai определяется на основе данных, для RReLU aji генерируется случайным образом из заданного интервала во время обучения и остается постоянным во время тестирования.
Leaky ReLU
ReLU с «утечкой» (leaky ReLU, LReLU) представляет собой одну из попыток решить описанную выше проблему выхода из строя обычных ReLU. Обычный ReLU на интервале x < 0 дает на выходе ноль, в то время как LReLU имеет на этом интервале небольшое отрицательное значение (угловой коэффициент около 0,01). То есть функция для LReLU имеет вид f(x) = ax при x < 0 и f(x) = x при x - 0, где a - малая константа. Некоторые исследователи сообщают об успешном применении данной функции активации, но результаты не всегда стабильны.
Parametric ReLU
Для параметрического ReLU (parametric ReLU, PReLU) [He et al.] угловой коэффициент на отрицательном интервале не задается предварительно, а определяется на основе данных. Авторы публикации утверждают, что применение данной функции активации является ключевым фактором, позволившим превзойти уровень человека в задаче распознавания изображений ImageNet. Процесс обратного распространения ошибки и обновления для PReLU (стр. 43 слайдов) достаточно прост и подобен соответствующему процессу для традиционных ReLU.
Randomized ReLU
Для рандомизированного ReLU (randomized ReLU, RReLU) угловой коэффициент на отрицательном интервале во время обучения генерируется случайным образом из заданного интервала, а во время тестирования остается постоянным. В рамках Kaggle-соревнования National Data Science Bowl (NDSB) RReLU позволили уменьшить переобучение благодаря свойственному им элементу случайности [Xu et al.]. Как сообщает победитель данного соревнования, во время обучения значение ai генерировалось случайным образом из распределения 1 / U(3, 8), а во время тестирования значение было постоянно и равнялось математическому ожиданию: 2 / (l + u) = 2 / 11.
В работе [Xu et al.] авторы сравнили точность классификации двух сверточных сетей с различными функциями активации на наборах данных CIFAR-10, CIFAR-100 и NDSB. Результаты приведены в таблицах ниже. Обратите внимание, в таблицах a обозначает 1 / a, где a - описанный выше угловой коэффициент.

Результаты говорят о том, что для всех трех наборов данных модифицированные ReLU превзошли традиционные. В случае LReLU большее значение углового коэффициента a обеспечивает более высокую точность. PReLU склонны к переобучению на малых наборах данных (ошибка на обучающем наборе наименьшая из всех, в то время как ошибка на тестовом наборе больше, чем у конкурирующих модификаций ReLU). При этом PReLU все же превосходит традиционный ReLU. Следует отметить, что RReLU существенно превосходит другие функции активации на наборе данных NDSB. Это говорит о том, что RReLU позволяет избежать переобучения, поскольку этот набор содержит меньше обучающих данных, чем еньше обучающих данных, чем ()аборCIFAR-10 и CIFAR-100.
Вывод. Все три модификации ReLU уверенно превзошли обычный ReLU на указанных наборах данных. Оптимальным выбором являются PReLU и RReLU. В публикации [He et al.] авторы пришли к аналогичным выводам.
6. Регуляризация
Существует несколько методов контроля емкости нейронной сети, позволяющих предотвратить переобучение.
L2-регуляризация
L2-регуляризация, вероятно, является наиболее распространенным методом регуляризации. Данный метод штрафует модель с помощью квадратов весов. То есть, для каждого веса y мы прибавляем к целевой функции слагаемое mky2, где k - коэффициент регуляризации. Множитель m используется для того, чтобы градиент этого слагаемого по параметру y равнялся ky, а не 2ky. Интуитивная интерпретация L2-регуляризации заключается в том, что она сильно штрафует векторы весов с большими значениями, и слабо затрагивает векторы с умеренными значениями.
L1-регуляризация
L1-регуляризация является еще одним распространенным методом регуляризации. В рамках этого метода для каждого веса y мы прибавляем к целевой функции слагаемое k|y|.
Применяется также комбинация L1- и L2-регуляризации: k1|y| + k2y2. Этот метод имеет название эластичная сеть (elastic net).
L1-регуляризация имеет интересное свойство, заключающееся в том, что в ее результате векторы весов становятся разреженными (т.е. очень близкими к нулю). Другими словами, нейроны с L1-регуляризацией в итоге используют только небольшое подмножество наиболее важных входов и, соответственно, почти не подвержены влиянию «шумных» входов.
На практике, если нет необходимости в непосредственном отборе признаков, L2-регуляризация обеспечит лучший результат по сравнению с L1-регуляризацией.
Ограничение нормы вектора весов
Еще одним методом регуляризации является метод ограничения нормы вектора весов (max norm constraint). В рамках данного метода мы задаем абсолютный верхний предел для нормы вектора весов каждого нейрона. Соблюдение ограничения обеспечивается с помощью проецируемого градиентного спуска (projected gradient descent). На практике это реализуется следующим образом: обновление весов выполняется как обычно, а затем вектор весов y каждого нейрона ограничивается так, чтобы выполнялось условие ||y||2 < c. Обычно значение c составляет порядка 3 или 4. Некоторые исследователи сообщают о положительном эффекте при использовании данного метода регуляризации. Одно из полезных свойств этого метода заключается в том, что он позволяет предотвратить «взрывной» рост весов даже при слишком большой скорости обучения, потому что обновления весов всегда ограничены.
Дропаут
Дропаут (dropout) - простой и очень эффективный метод регуляризации, дополняющий вышеназванные методы. Он был недавно предложен в работе [Srivastava et al.]. Суть метода состоит в том, что в процессе обучения из общей сети случайным образом многократно выделяется подсеть, и обновление весов выполняется только в рамках этой подсети. Нейроны попадают в подсеть с вероятностью p, которая называется коэффициентом дропаута. Во время тестирования дропаут не применяется, вместо этого веса умножаются на коэффициент дропаута, в результате чего можно получить усредненную оценку для ансамбля всех подсетей. На практике коэффициент дропаута p обычно выбирают равным 0,5, но его можно подобрать с помощью валидационного набора данных.

Дропаут - одни из самых популярных методов регуляризации. В 2014 году компания Google подала патентную заявку на этот метод.
7. Визуализация
В процессе обучения полезно выполнять визуализацию, чтобы контролировать эффективность обучения.
Как известно, скорость обучения является очень чувствительным параметром. На рисунке 1 ниже мы видим, что при очень большой (very high) скорости обучения кривая ошибки будет иметь неприемлемую форму. При малой (low) скорости обучения ошибка будет уменьшаться очень медленно даже после большого количества эпох. При большой (high) скорости обучения ошибка быстро уменьшается вначале, но потом попадает в локальный минимум, в результате чего сеть может не достичь хороших результатов. В том случае, когда скорость обучения подобрана правильно (good) (красная линия), ошибка уменьшается плавно и в итоге достигает минимального значения.
Теперь давайте рассмотрим кривую ошибки в более крупном масштабе. Эпоха (epoch) соответствует однократному проходу по обучающему набору данных, соответственно, в каждую эпоху входит множество мини-пакетов (mini-batch). Если мы визуализируем ошибку для каждого мини-пакета, кривая ошибки будет иметь вид, изображенный на рисунке 2. Как уже было сказано в отношении рисунка 1, если кривая ошибки имеет форму, близкую к линейной, это свидетельствует о малой скорости обучения. Если ошибка уменьшается медленно, вероятно, скорость обучения слишком большая. «Ширина» кривой соответствует размеру мини-пакета. Если «ширина» слишком большая, то есть разброс между мини-пакетами слишком большой, значит необходимо увеличить размер мини-пакета.
Еще один вывод можно сделать с помощью кривых точности. На рисунке 3 красная кривая представляет точность на обучающем наборе данных, а зеленая - на валидационном. Расстояние между кривыми показывает, насколько эффективна модель. Большое расстояние говорит о том, что сеть хорошо классифицирует обучающие данные и плохо классифицирует валидационные данные. Следовательно, в данном случае имеет место переобучение. Чтобы решить эту проблему, необходимо усилить регуляризацию. Если же расстояние между кривыми отсутствует, причем обе кривые соответствуют низкому уровню точности, значит, наша модель обладает недостаточной обучаемостью. В этом случае для улучшения результата необходимо увеличить емкость модели.

8. Ансамбли глубоких сетей
Ансамблевые методы предполагают обучение и совместное использование нескольких моделей. Как правило, ансамбль намного точнее отдельных моделей. Этот передовой подход позволил добиться высоких результатов при решении многих реальных задач. Почти все призеры различных конкурсов и соревнований по машинному обучению использовали ансамблевые методы.
Рассмотрим несколько вариантов создания моделей, которые можно объединить в ансамбль.
Модели с одинаковыми гиперпараметрами и различной инициализацией
С помощью кросс-валидации подбираем лучший набор гиперпараметров, а затем обучаем несколько моделей с одинаковым лучшим набором гиперпараметров, но с различной случайной инициализацией. Недостаток такого подхода заключается в том, что источником разнообразия служит только инициализация.
Модели с различными гиперпараметрами
С помощью кросс-валидации подбираем несколько лучших наборов гиперпараметров и объединяем в ансамбль модели с этими наборами гиперпараметров. Этот подход обеспечивает разнообразие, но существует опасность включения в ансамбль неоптимальных моделей. На практике данный подход легче реализовать по сравнению с предыдущим, поскольку после кросс-валидации не требуется дополнительное обучение моделей.
Кроме того, для создания ансамбля можно выбрать несколько предварительно обученных передовых моделей, например, из репозитория Caffe Model Zoo.
Различные стадии обучения одной модели
В том случае, когда процесс обучения является очень требовательным к ресурсам, можно объединить в ансамбль различные стадии обучения одной модели (checkpoint), например, после каждой эпохи. Этот подход не обеспечивает большого разнообразия, но на практике может дать достаточно хорошие результаты.
Практический пример:
Если перед нами стоит задача, связанная с высокоуровневой семантикой изображений, например, распознавание событий на статических изображениях, тогда в ансамбль следует объединить несколько глубоких моделей, обученных на различных наборах данных с целью извлечения различных глубоких представлений. Например, в рамках соревнования по распознаванию культурных событий Cultural Event Recognition, проводимого в сотрудничестве с ICCV-15, мы создали ансамбль из пяти различных глубоких моделей, обученных на наборах данных ImageNet, Places Database и на изображениях, предоставленных организаторами. После этого мы извлекли пять глубоких представлений и объединили их с помощью технологий раннего и позднего слияния («early fusion», «late fusion»), описанных в нашей публикации [Wei et al.]. Этот подход обеспечил нам 2-е место в соревновании. Подобная методика была также предложена в работе [Mohammadi et al.].
Другие рекомендации
В реальных задачах данные обычно неравномерно распределены по классам, то есть некоторые классы имеют большое количество обучающих изображений, а некоторые - значительно меньшее количество. Как сообщается в недавнем докладе [Hensman et al.], несбалансированные обучающие данные могут оказывать серьезное негативное влияние на общую эффективность глубоких сверточных сетей. Простейшим решением этой проблемы является дублирование изображений в классах с малым количеством изображений, или исключение изображений из классов с большим количеством изображений. Другим решением данной проблемы, которое мы применили в контексте описанного выше соревнования, является кадрирование. Поскольку исходные изображения культурных событий были неравномерно распределены по классам, мы извлекли фрагменты изображений для классов с малым количеством обучающих экземпляров. С одной стороны, этот подход обеспечил разнообразие обучающих данных, а с другой - позволил решить проблему дисбаланса.
Для решения описанной проблемы также можно применить стратегию тонкой настройки (fine-tuning) предобученных моделей. В частности, исходный обучающий набор данных можно разделить на две части таким образом, что одна часть будет содержать классы, представленные большим количеством изображений, а другая - классы, представленные малым количеством изображений. Каждая часть будет сравнительно сбалансированной. После этого сначала необходимо обучить модель на классах с большим количеством изображений, а затем - на классах с малым количеством изображений.
Телеграм: t.me/ainewsline
Источник: datareview.info