Представление данных для задач обработки естественного языка
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Голосовой помощник
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
Разработка ИИГородские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Внедрение ИИКомпьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Big data
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Работа разума и сознаниеМодель мозгаРобототехника, БПЛАТрансгуманизмОбработка текстаТеория эволюцииДополненная реальностьЖелезоКиберугрозыНаучный мирИТ индустрияРазработка ПОТеория информацииМатематикаЦифровая экономика
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2023-02-21 19:00

В НЛП мы должны найти способ представления наших данных (серии текстов) в наших системах (например, текстовый классификатор). Как спрашивает Йоав Голдберг: "Как мы можем закодировать такие категориальные данные способом, приемлемым для нас статистическим классификатором?" Введите слово вектор.
Мэтью Мэйо, KDnuggets, 13 октября 2022 года в обработке естественного языка
Ранее мы подробно рассмотрели ряд вводных тем по обработке естественного языка (NLP), начиная с подхода к таким задачам и заканчивая предварительной обработкой текстовых данных, началом работы с парой популярных библиотек Python и не только. Я надеялся перейти к изучению некоторых различных типов задач NLP, но мне указали, что я забыл затронуть чрезвычайно важный аспект: представление данных для обработки естественного языка.
Так же, как и в других типах задач машинного обучения, в NLP мы должны найти способ представления наших данных (серии текстов) в наших системах (например, текстовый классификатор). Как спрашивает Йоав Голдберг: "Как мы можем закодировать такие категориальные данные способом, приемлемым для нас статистическим классификатором?" Введите слово вектор.

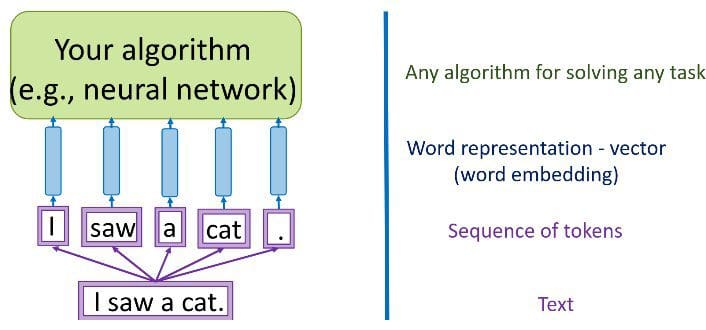
Source: Yandex Data School Natural Language Processing Course
Мы должны перейти от набора категориальных признаков в необработанном (или предварительно обработанном) тексте - слов, букв, POS-тегов, расположения слов, порядка слов и т.д. - к серии векторов. Двумя вариантами достижения такого кодирования текстовых данных являются разреженные векторы (или однократные кодировки) и плотные векторы.
Эти два подхода отличаются несколькими фундаментальными способами. Читайте дальше для обсуждения.
Одноразовое кодирование
До широкого использования нейронных сетей в НЛП - в том, что мы будем называть "традиционным" НЛП - векторизация текста часто происходила с помощью однократного кодирования (обратите внимание, что это сохраняется как полезная практика кодирования для ряда упражнений и не вышло из моды из-за использование нейронных сетей). При однократном кодировании каждое слово или токен в тексте соответствует векторному элементу.
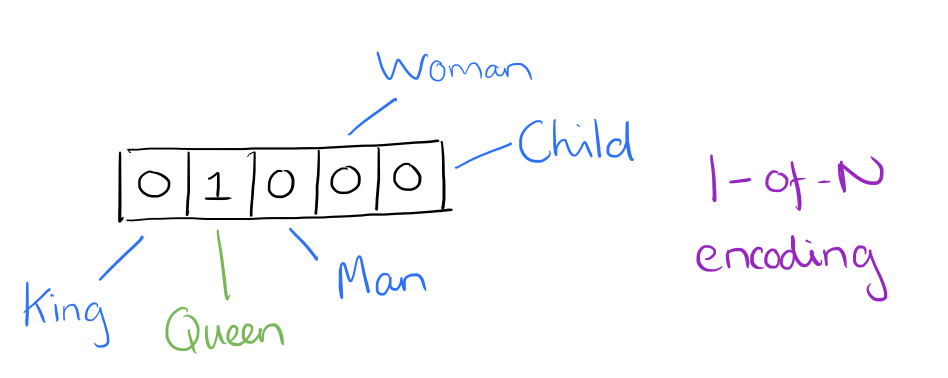
Source: Adrian Colyer
Результатом процесса однократного кодирования в корпусе является разреженная матрица. Представьте, если бы у вас был корпус из 20 000 уникальных слов: один короткий документ в этом корпусе, возможно, из 40 слов, был бы представлен матрицей с 20 000 строками (по одной на каждое уникальное слово) с максимальным количеством 40 ненулевых элементов матрицы (и потенциально намного меньшим, если есть большое количество неуникальных слов в этой коллекции из 40 слов). Это оставляет много нулей и может в конечном итоге занять большой объем памяти для размещения этих запасных представлений.
Помимо потенциальных проблем с объемом памяти, основным недостатком однократного кодирования является отсутствие представления смысла. Хотя при таком подходе мы хорошо улавливаем присутствие и отсутствие слов в конкретном тексте, мы не можем легко определить какой-либо смысл по простому присутствию / отсутствию этих слов. Часть этой проблемы заключается в том, что мы теряем позиционные отношения между словами или порядок слов, используя однократное кодирование. Этот порядок в конечном итоге имеет первостепенное значение для представления смысла в словах, и он рассматривается ниже.
Понятие сходства слов также трудно извлечь, поскольку векторы слов статистически ортогональны. Возьмем, к примеру, пары слов "собака" и "собаки" или "автомобиль" и "авто". Очевидно, что эти пары слов похожи соответственно по-разному. В линейной системе, использующей одноразовое кодирование, традиционные инструменты NLP, такие как стемминг и лемматизация, могут быть использованы в предварительной обработке, чтобы помочь выявить сходство между первой парой слов; однако нам нужен более надежный подход для решения проблемы выявления сходства между второй парой слов.
Основное преимущество векторов слов с однократным кодированием заключается в том, что они фиксируют одновременное появление двоичных слов (их поочередно описывают как набор слов), чего достаточно для выполнения широкого спектра задач NLP, включая классификацию текста, одно из наиболее полезных и распространенных занятий в этой области. Этот тип словесного вектора полезен для линейных алгоритмов машинного обучения, а также для нейронных сетей, хотя чаще всего они ассоциируются с линейными системами. Вариантами однократного кодирования, которые также полезны для линейных систем и которые помогают бороться с некоторыми из вышеуказанных проблем, являются представления n-gram и TF-IDF. Хотя они не совпадают с одноразовым кодированием, они похожи в том, что представляют собой простые векторные представления в отличие от вложений, которые представлены ниже.
Векторы плотного вложения
Векторы разреженных слов кажутся вполне приемлемым способом представления определенных текстовых данных определенными способами, особенно учитывая совместное использование двоичных слов. Мы также можем использовать связанные линейные подходы для устранения некоторых из самых больших и очевидных недостатков однократных кодировок, таких как n-граммы и TF-IDF. Но проникнуть в суть значения текста и семантической взаимосвязи между лексемами по-прежнему сложно без применения другого подхода, и векторы встраивания слов являются именно таким подходом.
В "традиционном" НЛП для определения того, какие лексемы в тексте выполняют какие типы функций (существительное, глагол, наречие, неопределенный артикль и т.д.), могут использоваться такие подходы, как пометка вручную или заученными частями речи (POS). Это форма ручного назначения функций, и эти функции затем могут быть использованы для различных подходов к функциям NLP. Рассмотрим, например, распознавание именованных объектов: если мы ищем именованные объекты в отрывке текста, было бы разумно сначала рассмотреть только существительные (или словосочетания существительных) в попытке идентификации, поскольку именованные объекты почти исключительно являются подмножеством всех существительных.
Однако давайте рассмотрим, если бы мы вместо этого представили объекты в виде плотных векторов - то есть с основными объектами, встроенными в пространство вложения размером d измерений. Если хотите, мы можем сократить количество измерений, используемых для представления 20 000 уникальных слов, возможно, до 50 или 100 измерений. При таком подходе каждый объект больше не имеет своего собственного измерения, а вместо этого сопоставляется вектору.
Как указывалось ранее, оказывается, что значение связано не с бинарным сочетанием слов, а с позиционными отношениями слов. Подумайте об этом так: если я скажу, что слова "foo" и "bar" встречаются в предложении вместе, определить значение будет сложно. Однако; если я скажу "Фу залаял, что напугало молодого бара", становится намного легче определить значения этих слов. Положение слов и их связь со словами вокруг них важны.
"Вы узнаете слово по компании, в которой оно находится".
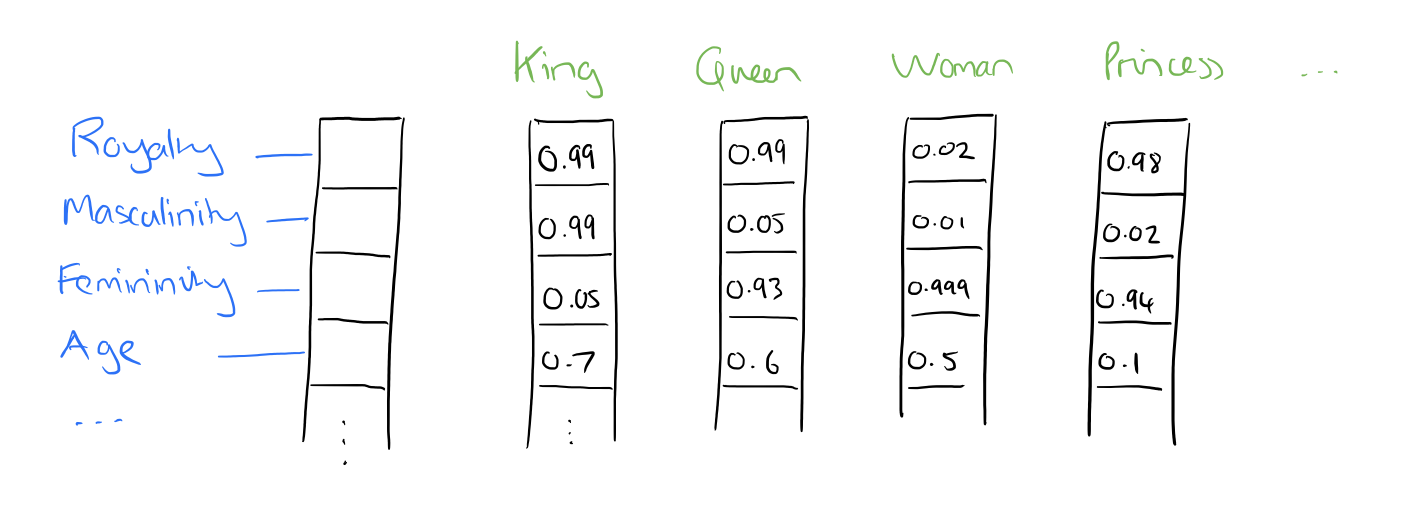
Source: Adrian Colyer
Итак, что же именно представляют собой эти функции? Мы оставляем нейронной сети определять важные аспекты взаимосвязей между словами. Хотя человеческая интерпретация этих особенностей была бы невозможна в точности, изображение выше дает представление о том, как может выглядеть лежащий в основе процесс, относящийся к знаменитому примеру Король - Мужчина + Женщина = королева.
Как изучаются эти функции? Это достигается с помощью двухслойной (неглубокой) нейронной сети - встраивания слов часто группируются вместе с подходами "глубокого обучения" к НЛП, но процесс создания этих встраиваний не использует глубокое обучение, хотя полученные веса часто используются в послесловиях задач глубокого обучения. Популярные оригинальные методы встраивания word2vec Continuous Bag of Words (CBOW) и Skip-gram относятся к задачам прогнозирования слова с учетом его контекста и прогнозирования контекста с учетом слова (обратите внимание, что контекст - это скользящее окно слов в тексте). Мы не заботимся о выходном слое модели; он отбрасывается после обучения, а веса слоя встраивания затем используются для последующих задач нейронной сети NLP. Именно это встраивание слоев аналогично результирующим словесным векторам в подходе однократного кодирования.
Здесь у вас есть 2 основных подхода к представлению текстовых данных для задач NLP. Теперь мы готовы рассмотреть некоторые практические задачи НЛП в следующий раз.
Рекомендации
- Natural Language Processing, National Research University Higher School of Economics (Coursera)
- Natural Language Processing, Yandex Data School
- Neural Network Methods for Natural Language Processing, Yoav Goldberg
Matthew Mayo (@mattmayo13) is a Data Scientist and the Editor-in-Chief of KDnuggets, the seminal online Data Science and Machine Learning resource. His interests lie in natural language processing, algorithm design and optimization, unsupervised learning, neural networks, and automated approaches to machine learning. Matthew holds a Master's degree in computer science and a graduate diploma in data mining. He can be reached at editor1 at kdnuggets[dot]com.
Источник: www.kdnuggets.com