Нейросети в генерации видео: Imagen video и Phenaki
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2023-02-15 16:00

Мы видели уже большое количество генеративных нейросетей способных превращать текстовые запросы в изображение, но почему все забыли про видео? Разве никто не хочет примерить на себе кресло режиссёра без съёмочной группы и выхода за пределы комнаты с любимым компьютером? Google начал делать первые шаги в этой области, и сейчас мы рассмотрим их нейросети: Imagen video и Phenaki. Приготовьтесь к приключению в глубины машинного обучения, где искусственный интеллект превращает написанное слово в завораживающее зрелище.
Чем видео отличается от картинок?
Видео (по своей сути) представляет собой не что иное, как последовательность изображений, воспроизводимых очень быстро. Тем не менее воздействие видео на человеческий мозг значительно отличается от воздействия отдельных изображений. Движение и прогрессия изображений в видео создают более захватывающий и динамичный опыт, позволяя мозгу взаимодействовать с контентом так, как не могут отдельные изображения. Это всё равно что сравнивать опыт чтения книги с просмотром фильма, основанного на этой книге. Хотя оба варианта предоставляют одну и ту же информацию, последний обеспечивает более увлекательный и захватывающий опыт. Вот почему видео стали таким мощным инструментом общения, образования и развлечения. Они позволяют нам не только потреблять информацию, но и переживать её.

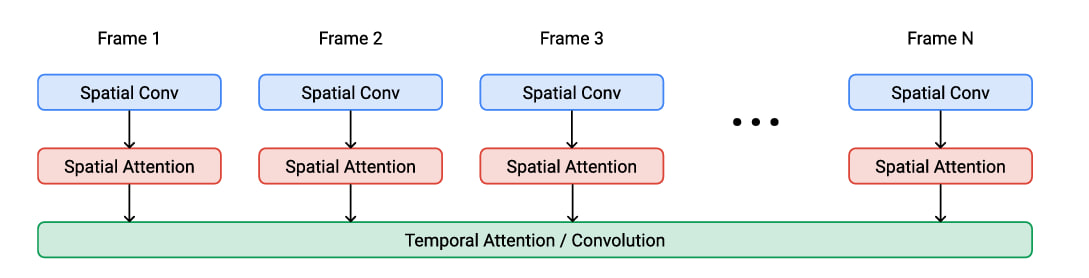
? Imagen video

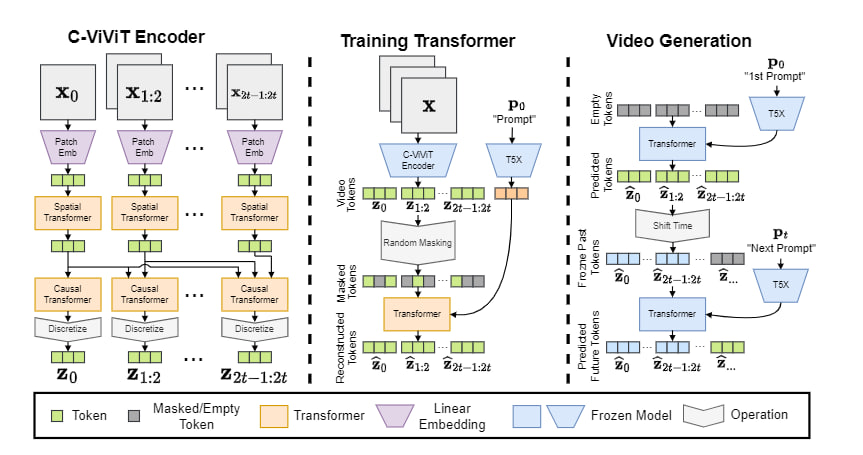
? Phenaki
Чтобы сделать великий фильм, необходимы три вещи — сценарий, сценарий и ещё раз сценарий.
— Альфред Хичкок
Phenaki — это модель, которая может генерировать реалистичное видео из своеобразного сценария. Phenaki использует трансформер — тип модели глубокого обучения для преобразования текстовых токенов (например, слов или фраз) в видео-токены.
(Про генерацию аналогичным образом изображений я писал в этой статье)
Она работает, принимая последовательность текстовых подсказок и сжимая видео в токены с помощью кодера под названием C-ViViT. Затем эти токены де-токенизируются для создания видео, которое может быть произвольной длины и обусловлено изменяющимся во времени текстом или историями. Чтобы максимизировать количество данных, они проводят совместное обучение на парах изображение-текст и меньшем количестве примеров видео-текст из таких наборов данных, как LAION5B и JFT4B, чтобы обобщение выходило за рамки того, что доступно в существующих наборах данных.
Нейросеть использует векторное квантование (VQ) для создания видеопредставления из текста, каузальную вариацию архитектуры ViViT для сжатия кадров видео и двунаправленный трансформер для создания видеотокенов из текста, что позволяет ей генерировать длинные видео с фиксированным шагом дискретизации. Также используются функции потерь, такие как L2, потери восприятия изображений и видео, а также состязательные потери для того, чтобы видео-токены точно соответствовали соответствующему тексту.
Модель использует авторегрессивный подход, то есть создаёт видео со временем, поскольку каждая подсказка соответствует сцене в сюжете. Это позволяет создавать динамически меняющиеся сцены, чего раньше не удавалось сделать с помощью подобной технологии.
Выводы
Модели Imagen Video и Phenaki от Google проложили путь в новую эру технологии создания видео, когда творческие умы могут воплощать свои идеи в жизнь не выходя из-за компьютера. Эти модели демонстрируют мощь глубокого обучения и его способность обрабатывать большие объёмы данных, в результате чего получаются видео высокого разрешения с впечатляющей точностью и качеством. Однако вместе с такой технологией приходит и ответственность, поскольку авторы моделей признают возможность злоупотреблений и наличие предубеждений в обучающих данных. Тем не менее — это значительный шаг к раскрытию всего потенциала генеративных моделей, и будет интересно посмотреть, как эта технология будет развиваться в будущем.
Источник: habr.com