Туториал по созданию системы фильтров Snapchat с использованием Deep Learning
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2022-01-08 18:57
Датасет

Я использовал следующий датасет: https://www.kaggle.com/c/facial-keypoints-detection, предоставленный доктором Йошуа Бенжио из Университета Монреаля.
Каждая прогнозируемая ключевая точка задается парой действительных чисел (x, y) в пространстве индексов пикселей. Есть 15 ключевых точек, которые представляют различные элементы лица. Входное изображение задается в последнем поле файлов данных и состоит из списка пикселей (упорядоченных по строкам) в виде целых чисел в диапазоне (0,255). Изображения имеют размер 96х96 пикселей.
Теперь, когда у нас есть хорошее представление о представлении данных, с которыми мы имеем дело, нам нужно предварительно обработать их, чтобы мы могли использовать их в качестве входных данных для нашей модели.
Шаг 1: Предварительная обработка данных и другие махинации
В приведенном выше датасете есть два файла, к которым мы должны обратиться -? training.csv и test.csv. Файл training содержит 31 столбец: 30 столбцов для координат ключевой точки и последний столбец, содержащий данные изображения в строковом формате. Он содержит 7049 объектов, однако многие из этих примеров имеют значения «NaN» в некоторых ключевых моментах, которые усложняют нам задачу. Поэтому мы будем рассматривать только образцы без каких-либо значений NaN. Вот код, который делает именно это: (Следующий код также нормализует данные изображений и ключевых точек, что является очень распространенным этапом предобработки данных)
# Check if row has any NaN values def has_nan(keypoints): for i in range(len(keypoints)): if math.isnan(keypoints[i]): return True return False # Read the data as Dataframes training = pd.read_csv('data/training.csv') test = pd.read_csv('data/test.csv') # Get training data imgs_train = [] points_train = [] for i in range(len(training)): points = training.iloc[i,:-1] if has_nan(points) is False: test_image = training.iloc[i,-1] # Get the image data test_image = np.array(test_image.split(' ')).astype(int) test_image = np.reshape(test_image, (96,96)) # Reshape into an array of size 96x96 test_image = test_image/255 # Normalize image imgs_train.append(test_image) keypoints = training.iloc[i,:-1].astype(int).values keypoints = keypoints/96 - 0.5 # Normalize keypoint coordinates points_train.append(keypoints) imgs_train = np.array(imgs_train) points_train = np.array(points_train) # Get test data imgs_test = [] for i in range(len(test)): test_image = test.iloc[i,-1] # Get the image data test_image = np.array(test_image.split(' ')).astype(int) test_image = np.reshape(test_image, (96,96)) # Reshape into an array of size 96x96 test_image = test_image/255 # Normalize image imgs_test.append(test_image) imgs_test = np.array(imgs_test) Все хорошо? Не на самом деле нет. Похоже, что было только 2140 образцов, которые не содержали значений NaN. Это гораздо меньше образцов, чем требуется для обучения обобщенной и точной модели. Таким образом, чтобы создать больше данных, нам нужно дополнить наши текущие данные.
Аугментация данных — это методика, в основном используемая для генерации большего количества данных из существующих данных с использованием таких методов, как масштабирование, перемещение, вращение и т.д. В моем случае я отразил каждое изображение и соответствующие ему ключевые точки, поскольку такие методы, как масштабирование и поворот, могли бы исказить изображения лица и, таким образом, испортили бы модель. Наконец, я объединил исходные данные с новыми дополненными данными, чтобы получить в общей сложности 4280 образцов.
# Data Augmentation by mirroring the images def augment(img, points): f_img = img[:, ::-1] # Mirror the image for i in range(0,len(points),2): # Mirror the key point coordinates x_renorm = (points[i]+0.5)*96 # Denormalize x-coordinate dx = x_renorm - 48 # Get distance to midpoint x_renorm_flipped = x_renorm - 2*dx points[i] = x_renorm_flipped/96 - 0.5 # Normalize x-coordinate return f_img, points aug_imgs_train = [] aug_points_train = [] for i, img in enumerate(imgs_train): f_img, f_points = augment(img, points_train[i]) aug_imgs_train.append(f_img) aug_points_train.append(f_points) aug_imgs_train = np.array(aug_imgs_train) aug_points_train = np.array(aug_points_train) # Combine the original data and augmented data imgs_total = np.concatenate((imgs_train, aug_imgs_train), axis=0) points_total = np.concatenate((points_train, aug_points_train), axis=0)
Шаг 2: Архитектура модели и обучение
Теперь давайте погрузимся в раздел проекта «Глубокое обучение». Наша цель — предсказать значения координат для каждой ключевой точки, поэтому это задача регрессии. Поскольку мы работаем с изображениями, сверточные нейронные сети являются довольно очевидным выбором для извлечения признаков. Эти извлеченные признаки затем передаются в полносвязную нейронную сеть, которая выводит координаты. В конечном полносвязном слое нужно 30 нейронов, потому что нам нужно 30 значений (15 пар координат (x, y)).
# Define the architecture def get_model(): model = Sequential() model.add(Conv2D(64, kernel_size=3, strides=2, padding='same', input_shape=(96,96,1), activation='relu')) model.add(MaxPooling2D(pool_size=(2, 2), padding='same')) model.add(Conv2D(128, kernel_size=3, strides=2, padding='same', activation='relu')) model.add(MaxPooling2D(pool_size=(2, 2), padding='same')) model.add(Conv2D(128, kernel_size=3, strides=2, padding='same', activation='relu')) model.add(MaxPooling2D(pool_size=(2, 2), padding='same')) model.add(Conv2D(64, kernel_size=1, strides=2, padding='same', activation='relu')) model.add(MaxPooling2D(pool_size=(2, 2), padding='same')) model.add(Flatten()) model.add(Dense(128, activation='relu')) model.add(Dropout(0.1)) model.add(Dense(256, activation='relu')) model.add(Dropout(0.2)) model.add(Dense(128, activation='relu')) model.add(Dropout(0.1)) model.add(Dense(30)) return model; def compile_model(model): # Compile the model model.compile(loss='mean_absolute_error', optimizer='adam', metrics = ['accuracy']) def train_model(model): # Fit the model checkpoint = ModelCheckpoint(filepath='weights/checkpoint-{epoch:02d}.hdf5') model.fit(imgs_train, points_train, epochs=300, batch_size=100, callbacks=[checkpoint]) # Train the model model = get_model() compile_model(model) train_model(model) - Активация «ReLu» используются после каждого сверточного и полносвязного слоя, за исключением последнего полносвязного слоя, так как это значения координат, которые нам нужны в качестве выходных данных.
- Регуляризация Dropout используется для предотвращения переобучения
- MaxPooling добавлен для уменьшения размерности
Модель смогла достичь минимальных потерь ~ 0,0113 и точности ~ 80% , что, на мой взгляд, было достаточно приличным. Вот несколько результатов производительности модели на тестовой выборке:
def test_model(model): data_path = join('','*g') files = glob.glob(data_path) for i,f1 in enumerate(files): # Test model performance on a screenshot for the webcam if f1 == 'Capture.PNG': img = imread(f1) img = rgb2gray(img) # Convert RGB image to grayscale test_img = resize(img, (96,96)) # Resize to an array of size 96x96 test_img = np.array(test_img) test_img_input = np.reshape(test_img, (1,96,96,1)) # Model takes input of shape = [batch_size, height, width, no. of channels] prediction = model.predict(test_img_input) # shape = [batch_size, values] visualize_points(test_img, prediction[0]) # Test on first 10 samples of the test set for i in range(len(imgs_test)): test_img_input = np.reshape(imgs_test[i], (1,96,96,1)) # Model takes input of shape = [batch_size, height, width, no. of channels] prediction = model.predict(test_img_input) # shape = [batch_size, values] visualize_points(imgs_test[i], prediction[0]) if i == 10: break test_model(model) 
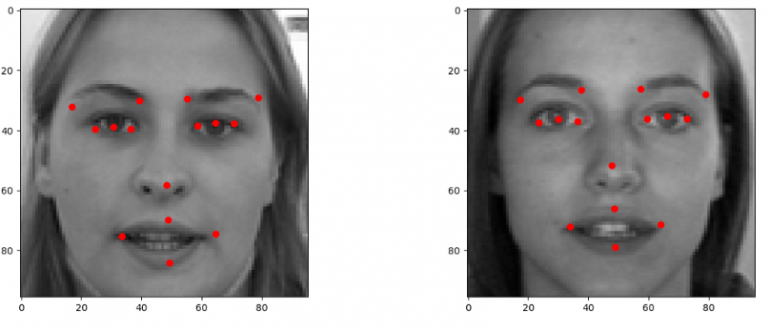
Мне также нужно было проверить производительность модели на изображении с моей веб-камеры, потому что это то, что модель получит во время реализации фильтра. Вот как модель работает на этом изображении моего красивого лица:

Шаг 3: Приведение модели в действие
Наша модель работает, поэтому все, что нам нужно сейчас сделать, это использовать OpenCV для выполнения следующих действий:
- Получить изображения с веб-камеры
- Определить область лица на каждом кадре изображения, потому что другие участки изображения бесполезны для модели (я использовал Каскад Хаара, чтобы обрезать область лица)
- Предобработать эту обрезанную область путем преобразования в оттенки серого, нормализации и изменения формы
- Передать предобработанное изображение в качестве входных данных для модели
- Получить прогнозы для ключевых точек и использовать их, чтобы расположить различные фильтры на лице
Когда я начал тестирование, я не имел в виду никаких конкретных фильтров. Идея проекта появилась у меня примерно 22 декабря 2018 года, и, как и любой другой обычный человек, я был большим поклонником Рождества и решил использовать следующие фильтры:

Я использовал определенные ключевые точки для масштабирования и позиционирования каждого из вышеуказанных фильтров:
- Фильтр очков: расстояние между левой ключевой точкой левого глаза и правой ключевой точкой правого глаза используется для масштабирования. Точка для бровей и левая точка для левого глаза используются для позиционирования очков.
- Фильтр бороды: расстояние между левой и правой точками губ используется для масштабирования. Верхняя ключевая точка губы и левая точка используются для позиционирования бороды.
- Фильтр шляпы: Ширина лица используется для масштабирования. Ключевая точка бровей и левая точка левого глаза используются для позиционирования шляпы.
Код, который делает все вышеперечисленное, выглядит следующим образом:
# Implement the model in real-time # Importing the libraries import numpy as np from training import get_model, load_trained_model, compile_model import cv2 # Load the trained model model = get_model() compile_model(model) load_trained_model(model) # Get frontal face haar cascade face_cascade = cv2.CascadeClassifier('cascades/haarcascade_frontalface_default.xml') # Get webcam camera = cv2.VideoCapture(0) # Run the program infinitely while True: grab_trueorfalse, img = camera.read() # Read data from the webcam # Preprocess input fram webcam gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # Convert RGB data to Grayscale faces = face_cascade.detectMultiScale(gray, 1.3, 5) # Identify faces in the webcam # For each detected face using tha Haar cascade for (x,y,w,h) in faces: roi_gray = gray[y:y+h, x:x+w] img_copy = np.copy(img) img_copy_1 = np.copy(img) roi_color = img_copy_1[y:y+h, x:x+w] width_original = roi_gray.shape[1] # Width of region where face is detected height_original = roi_gray.shape[0] # Height of region where face is detected img_gray = cv2.resize(roi_gray, (96, 96)) # Resize image to size 96x96 img_gray = img_gray/255 # Normalize the image data img_model = np.reshape(img_gray, (1,96,96,1)) # Model takes input of shape = [batch_size, height, width, no. of channels] keypoints = model.predict(img_model)[0] # Predict keypoints for the current input # Keypoints are saved as (x1, y1, x2, y2, ......) x_coords = keypoints[0::2] # Read alternate elements starting from index 0 y_coords = keypoints[1::2] # Read alternate elements starting from index 1 x_coords_denormalized = (x_coords+0.5)*width_original # Denormalize x-coordinate y_coords_denormalized = (y_coords+0.5)*height_original # Denormalize y-coordinate for i in range(len(x_coords)): # Plot the keypoints at the x and y coordinates cv2.circle(roi_color, (x_coords_denormalized[i], y_coords_denormalized[i]), 2, (255,255,0), -1) # Particular keypoints for scaling and positioning of the filter left_lip_coords = (int(x_coords_denormalized[11]), int(y_coords_denormalized[11])) right_lip_coords = (int(x_coords_denormalized[12]), int(y_coords_denormalized[12])) top_lip_coords = (int(x_coords_denormalized[13]), int(y_coords_denormalized[13])) bottom_lip_coords = (int(x_coords_denormalized[14]), int(y_coords_denormalized[14])) left_eye_coords = (int(x_coords_denormalized[3]), int(y_coords_denormalized[3])) right_eye_coords = (int(x_coords_denormalized[5]), int(y_coords_denormalized[5])) brow_coords = (int(x_coords_denormalized[6]), int(y_coords_denormalized[6])) # Scale filter according to keypoint coordinates beard_width = right_lip_coords[0] - left_lip_coords[0] glasses_width = right_eye_coords[0] - left_eye_coords[0] img_copy = cv2.cvtColor(img_copy, cv2.COLOR_BGR2BGRA) # Used for transparency overlay of filter using the alpha channel # Beard filter santa_filter = cv2.imread('filters/santa_filter.png', -1) santa_filter = cv2.resize(santa_filter, (beard_width*3,150)) sw,sh,sc = santa_filter.shape for i in range(0,sw): # Overlay the filter based on the alpha channel for j in range(0,sh): if santa_filter[i,j][3] != 0: img_copy[top_lip_coords[1]+i+y-20, left_lip_coords[0]+j+x-60] = santa_filter[i,j] # Hat filter hat = cv2.imread('filters/hat2.png', -1) hat = cv2.resize(hat, (w,w)) hw,hh,hc = hat.shape for i in range(0,hw): # Overlay the filter based on the alpha channel for j in range(0,hh): if hat[i,j][3] != 0: img_copy[i+y-brow_coords[1]*2, j+x-left_eye_coords[0]*1 + 20] = hat[i,j] # Glasses filter glasses = cv2.imread('filters/glasses.png', -1) glasses = cv2.resize(glasses, (glasses_width*2,150)) gw,gh,gc = glasses.shape for i in range(0,gw): # Overlay the filter based on the alpha channel for j in range(0,gh): if glasses[i,j][3] != 0: img_copy[brow_coords[1]+i+y-50, left_eye_coords[0]+j+x-60] = glasses[i,j] img_copy = cv2.cvtColor(img_copy, cv2.COLOR_BGRA2BGR) # Revert back to BGR cv2.imshow('Output',img_copy) # Output with the filter placed on the face cv2.imshow('Keypoints predicted',img_copy_1) # Place keypoints on the webcam input cv2.imshow('Webcam',img) # Original webcame Input if cv2.waitKey(1) & 0xFF == ord("e"): # If 'e' is pressed, stop reading and break the loop break Результат
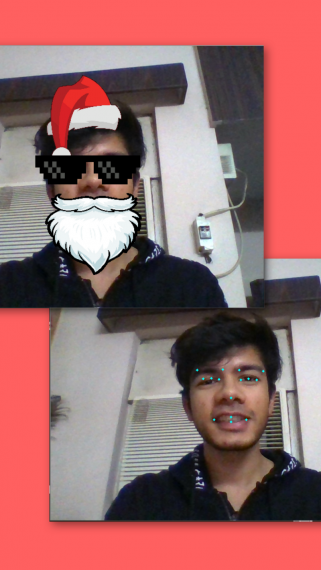
Выше вы можете увидеть окончательный результат проекта, который содержит видео в реальном времени с фильтрами на моем лице и еще одно видео в реальном времени с нанесенными ключевыми точками.
Ограничения проекта
Хотя проект работает довольно хорошо, я обнаружил несколько недостатков, которые делают его немного не идеальным:
- Не самая точная модель. Хотя 80%, на мой взгляд, довольно прилично, у него все еще есть много возможностей для улучшения.
- Эта текущая реализация работает только для выбранного набора фильтров. Мне пришлось выполнить некоторые ручные настройки для более точного позиционирования и масштабирования.
- Процесс применения фильтра к изображению довольно неэффективен по скорости вычислений, потому что для наложения изображения фильтра .png на изображение веб-камеры на основе альфа-канала мне пришлось применять фильтр попиксельно, где альфа не была равна 0. Иногда это приводит к сбою программы, когда она обнаруживает более одного лица на изображении.
Источник: te.legra.ph