Создатели нейросетевого переводчика с якутского языка столкнулись с проблемой — перевод повседневных текстов оказался слишком эпичным
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2022-01-31 12:20

Россия в интернете была многоязычной с самого начала. И дело не только в неизбежном переключении между русским и английским в ранние годы существования сети. Речь именно о языках народов России. Уже в 1990-е в интернете делали сайты на татарском, общались на башкирском, чувашском и других крупных национальных языках.
Сегодня лингвистический ландшафт сети ещё разнообразнее. Языков России в интернете — не меньше 40. Вы можете почитать Википедию на вепсском (хотя у этого языка всего-то три с небольшим тысячи носителей), кулинарные рецепты на луговом марийском (365 тысяч носителей) или паблики с мемами на якутском (450 тысяч носителей).
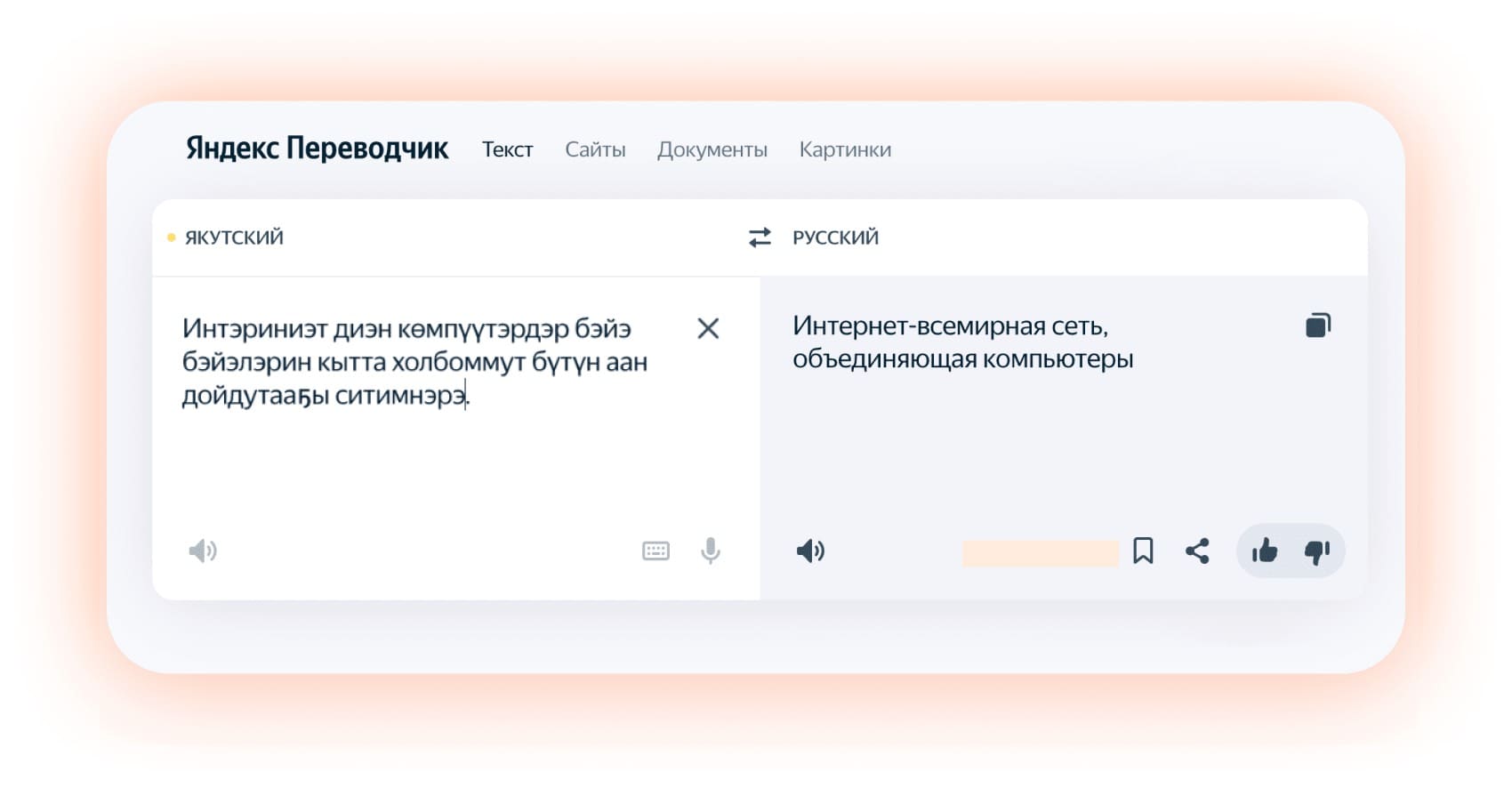
А если вы не знаете язык, но вам очень нужно прочитать запись в таком паблике, то к вашим услугам — машинный перевод. Например, Яндекс умеет переводить с того же якутского. Ещё из языков России в Яндекс.Переводчике есть, например, татарский, башкирский, удмуртский, чувашский, луговой и горный марийский. Но делать машинный перевод для таких сравнительно небольших языков сложнее, чем для пар «русский — английский» или «русский — немецкий». Приходится изобретать технические хитрости, а ещё — опираться на помощь локальных энтузиастов. Давайте разберёмся, в чём тут сложность и как с ней справляются.
Машинный перевод изнутри
Современный машинный перевод работает на нейросетевых моделях. Некоторые редкие пары языков ещё используют более старую технологию фразового статистического перевода, но все активно используемые в Яндекс.Переводчике языки, в том числе все языки России, работают на нейросетях.
Как обучается нейросетевой переводчик? Через него прогоняют множество пар параллельных текстов. Для перевода с русского на якутский такой парой будут предложение на русском и его перевод на якутский. Одна нейросеть — энкодер — преобразует якутский текст в абстрактное представление, которое сохраняет свойства этого предложения в виде упорядоченного набора чисел. А другая нейросеть — декодер — генерирует на основе этого представления связный русский текст.
Учитывать контекст при переводе каждого следующего слова удаётся благодаря механизму внимания. Это прорывная технология последних лет, своего рода «умная память» нейросети, позволяющая выборочно припоминать нужные куски текста, например, соотнести слова «ёлочка» и «была» в тексте «в лесу родилась ёлочка, в лесу она росла, зимой и летом стройная, зелёная была». До появления механизма внимания нейросетям было очень сложно держать в памяти много информации о том, что было в тексте раньше: хранимый контекст частично переписывался на каждом шаге и к концу обрабатываемого предложения выглядел как школьная доска к завершению седьмого урока. С появлением механизма внимания проблема была решена.
Подробнее об этом механизме и о том, как разработчики пытались решать проблему забывчивости до него, мы рассказывали в октябрьском выпуске.
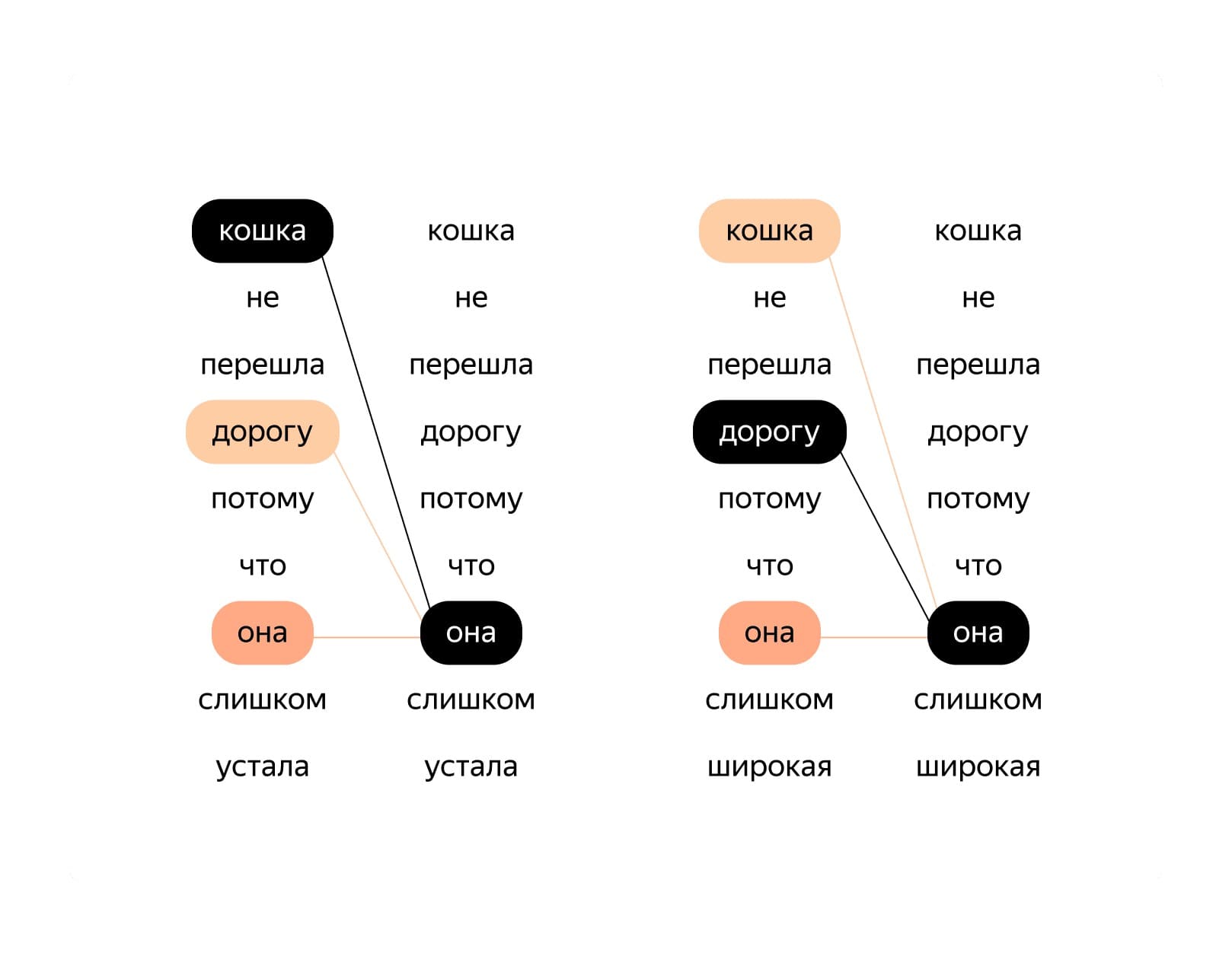
Обе части нейросетевого переводчика — декодер и энкодер — имеют свои механизмы внимания. Это позволяет учитывать как контекст оригинала (например, выбрать правильное значение для многозначного слова вроде якутского «бас» — «глава/голова»), так и контекст получающегося перевода (например, если гендерно-нейтральное татарское «эт» перевелось как «собака», то дальше в русском переводе связанные с ней глаголы будут в женском роде, а если как «пёс» — то в мужском).
Подлейте бензина: в чём сложность с малыми языками
Главная проблема работы с малыми языками — на них недостаточно данных в цифровой форме. Нейросеть действительно способна запомнить многое, но для этого модели нужно сначала много и разнообразно ошибаться — примерно как человеку при изучении нового языка. Разница в том, что модель благодаря скоростям современных компьютеров может совершать свои ошибки очень-очень быстро и выучивается на переводчика за считаные дни или часы. Но для этого нейросети нужны миллионы параллельных примеров, то есть разных пар «оригинал — перевод».

Для языковых пар вроде «русский — английский» такие примеры находятся без труда. С английского на русский и обратно переводят уже не одно столетие, есть сотни тысяч художественных книг, научных публикаций, технических инструкций, миллион парных статей из Википедии и много чего ещё. В конце концов, даже первый в истории опыт машинного перевода в 1954 году — и тот происходил именно между этими двумя языками, о чём мы подробно рассказывали в нашем материале.
Другое дело — якутский, у которого к середине XX века только-только утвердилась письменность. Текстов на якутском на несколько порядков меньше, чем на русском, а уж в цифровой форме — тем более. Это могут быть тысячи, десятки тысяч, но уж точно не миллионы текстов (автоматические переводы не в счёт).
Такие языки в компьютерной лингвистике называют малоресурсными — под «ресурсом» здесь имеются в виду именно тексты в цифровой форме, пригодные для обучения компьютерных моделей, а также сами модели. Данные часто называют «новой нефтью» — и это действительно важнейшее топливо для современных интеллектуальных систем, в том числе и переводчиков. Многократно показано, что даже самые хитроумные алгоритмы не спасают при недостаточном количестве обучающих примеров.
Когда нужно подключить к переводу малоресурсный язык, это всегда вызов для разработчиков. «Ты не можешь просто нажать кнопку и сделать как привык. Скорее всего, сеть недообучится и будет выдавать неправильные переводы — и грамматически, и по смыслу», — объясняет руководитель отдела NLP в Яндексе Антон Дворкович. Чтобы справиться с дефицитом данных, разработчикам приходится изощряться.
Первый путь — использовать помощь языкового сообщества. Энтузиасты сохранения языка нередко сами приходят в IT-компании и предлагают помощь. Именно так был собран первый обучающий набор для якутского: 100 тысяч пар предложений на русском и якутском для Яндекса собрал Алексей Иванов с командой единомышленников. Алексей много лет жил с мечтой об автоматическом переводе между русским и якутским — и сумел организовать краудсорсинг данных для обучения такого переводчика.
Подробности этой истории вы можете узнать из нашего фильма.
Вытягивание себя за волосы из болота
Однако и 100 тысяч пар предложений — это слишком мало для нейросети. Здесь нужны миллионы примеров. Поэтому дальше в ход пошли уже инженерные лайфхаки. Для искусственного увеличения размера обучающих данных применили технику «обратного перевода» (back translation). При этом подходе предложения на русском языке переводятся на якутский (или иной подключаемый малоресурсный язык) автоматически, пусть даже недообученной моделью. Получаются плохие якутские тексты, которым соответствуют хорошие (с точки зрения русского языка) русские переводы. После этого модель учится переводить такой слегка поломанный якутский — обратно на хороший русский.
Это звучит как попытка вытянуть самого себя за волосы из болота — но в мире машинного обучения такое работает. Разбавив качественные пары от краудсорсеров синтетическими примерами «обратного перевода», разработчики Яндекс.Переводчика получили гораздо более качественную модель. А чтобы она не слишком коверкала якутский, переводя в обратную сторону, синтетические примеры помечали специальным тегом — и сеть училась доверять им чуть меньше, чем настоящим человеческим переводам.
Тюркские языки, объединяйтесь!
Хитрость с «обратным переводом» помогает получать более качественный текст на русском языке. Но этот подход ещё не гарантирует хорошей передачи исходного смысла — ведь «честных» якутских оригиналов у нас всё ещё мало. Зато здесь может помочь использование моделью знаний из других схожих языков.
Якутский — это тюркский язык, хотя и довольно обособленный. Он родственник татарского, турецкого, башкирского, чувашского, удмуртского, казахского, узбекского, азербайджанского и ещё нескольких десятков живых и мёртвых языков и диалектов.
Тюркские языки в целом похожи. Говорящий по-татарски сможет легко объясниться с носителем башкирского, кое-что поймет в речи узбеков или азербайджанцев, и даже с носителем якутского у них найдутся общие слова.
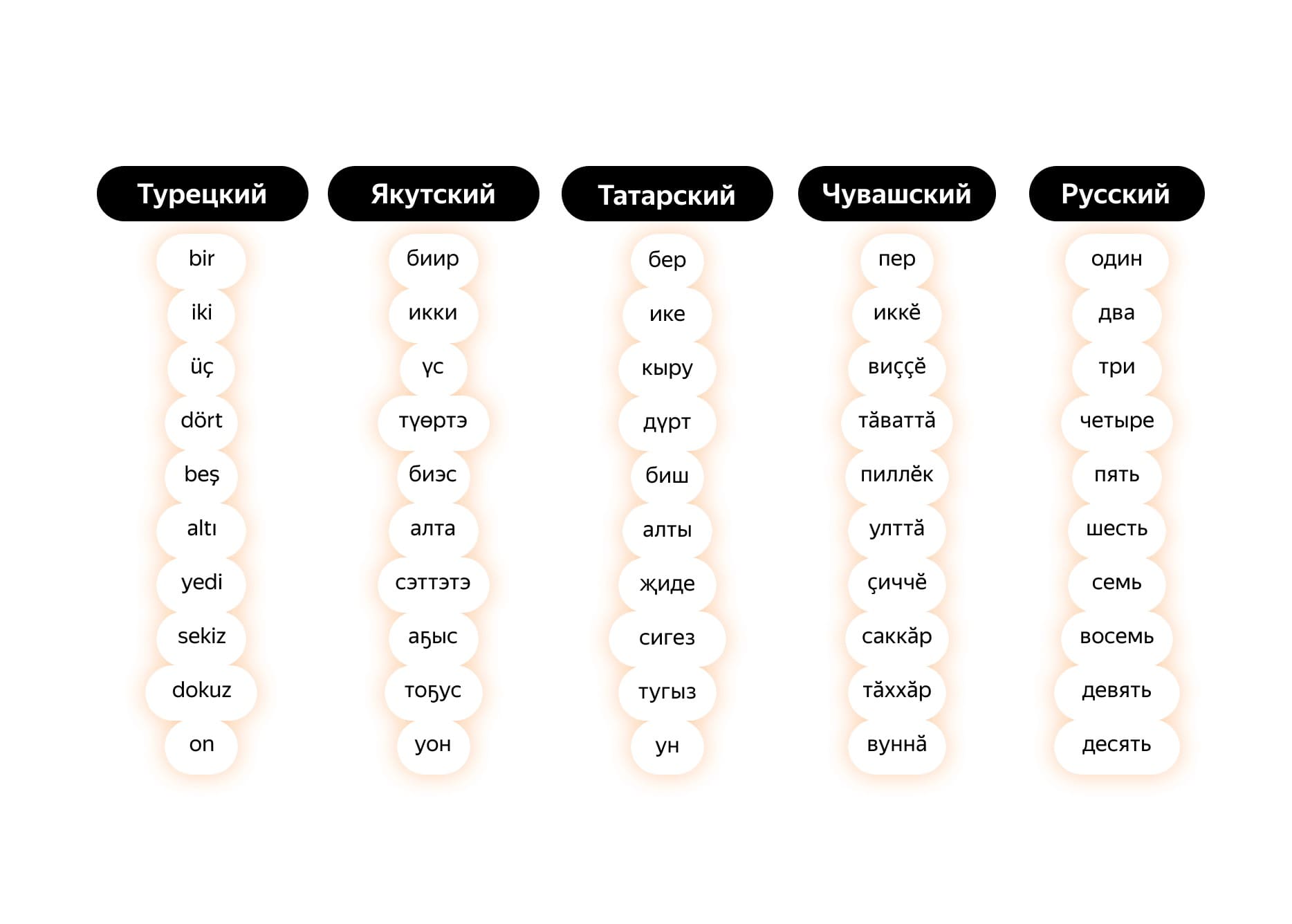
Как видно в этом примере, слова похожи, но далеко не одинаковы. Здесь могут регулярно отличаться отдельные звуки (лингвисты называют такое «регулярными фонетическими соответствиями» — это один из главных критериев установления родства языков), а ещё у разных тюркских языков исторически разная письменность: где-то кириллица, где-то латиница, где-то пробовали и то и другое, а кто-то в прошлом успел и на арабице пожить.
Близость тюркских языков не ограничивается лексикой. У них ещё и очень характерное грамматическое устройство. К корням слов в тюркских языках последовательно приклеиваются суффиксы один за другим. Скажем, корень «успешный» — по турецки muvaffak — может через наращение суффиксов передавать смысл вроде «легко мочь сделать кого-то тем, кто делает других людей неуспешными»: muvaffakiyetsizle?tiricile?tirivermek — и всё это в одно слово. Потенциально такие наращения бесконечны. Это называется «агглютинация» (от лат. agglutinatio — «приклеивание»), она есть и в турецком, и в татарском, и в якутском.
Родство языков позволяет обучать одну общую модель для их перевода. То есть «под капотом» у переводчика одна и та же нейросеть переводит на русский с якутского, татарского, чувашского и других тюркских языков. Этот подход называется many-to-one, то есть «из многих языков — в один». Это более универсальный инструмент, чем классическая двуязычная нейросеть. А главное, именно many-to-one-подход позволяет использовать знания о структуре и лексике тюркских языков, выученные на богатом материале турецкого или татарского, для перевода языков вроде чувашского или якутского — менее «ресурсных», но не менее важных для культурного разнообразия планеты.
В Яндексе для создания единой модели перевода тюркских языков разработали синтетическую общую письменность. В неё переводят любой тюркский язык, чтобы, к примеру, написанное кириллицей татарское «д?рт» («четыре») стало похоже на турецкое d?rt («четыре») не только с точки зрения человека, но и на уровне сходства строк для компьютера.
Выпадающие буквы
Основную массу обучающих данных для переводчика собирают роботы. Они обходят интернет в поисках текстов на нужных языках, а также их потенциальных переводов. Проблему здесь может представлять нестандартная онлайн-орфография малых языков, урезанная под стандартную русскую клавиатуру. В уже упомянутых якутских пабликах с мемами часто высмеивают такую «урезанную» письменность.
Специальные символы существуют в письменностях большинства тюркских языков, использующих кириллицу, ведь их фонетика принципиально отличается от русского — нужно обозначать звуки, которые в славянских языках вообще не встречаются. Например, в татарском к кириллице добавлены буквы ?, ?, ?, ?, ?, ?, а в якутском — ?, ?, ?, ?, ? и два диграфа, «дь» и «нь». Однако набрать эти символы чуть сложнее — нужна либо виртуальная клавиатура, либо подключённая специальная раскладка, которую к тому же приходится помнить, — поэтому многие носители языков в интернете обходятся без них.
Часть таких замен — вроде «ш» вместо ? в чувашском или 5 вместо ? в якутском — отслеживается и исправляется автоматически. Однако замены не всегда последовательны и не всегда их легко восстановить. В татарском вместо ? могут написать «э» или «е» — при этом все три буквы используются в написании слов на татарском. Алгоритм восстановления правильного написания не всегда будет простым.
Эпичный перевод
Ещё у языков, на которых текстов в принципе мало, могут возникнуть диспропорции в обучающих данных. Одни из самых универсальных источников данных для сбора параллельного корпуса — Библия и Коран. Эти тексты переводятся на максимальное число языков, и их роль в развитии машинного перевода редкоязычных пар действительно высока. Коран особенно актуален для тюркских языков России, учитывая цивилизационное и культурное влияние ислама на их народы-носители. Но если ваш параллельный корпус — один Коран, то едва ли вы научитесь с его помощью хорошо переводить современные новости или статьи об IT.
Бывают и другие перекосы. Якутия славится своей фольклорной эпической традицией — олонхо. Поэтому для якутского в изначальной коллекции обучающих данных было очень много народного эпоса. В результате стиль перевода даже повседневных текстов оказывался эпическим: там появлялись мифические персонажи и речевые обороты «былинного» стиля. Эти перекосы исправились, когда модель обучили на большем количестве текстов с использованием уже описанного выше back translation.
Кстати об эпосах. Ещё один очень малоресурсный язык в Яндекс.Переводчике — эльфийский. Язык синдарин придумал Дж. Р. Р. Толкин — автор «Хоббита» и «Властелина колец», а по совместительству профессор филологии в Оксфорде и большой любитель конструирования языков. Толкин был одним из первых фантастов, кто подошёл к изобретению вымышленного языка всерьёз: в синдарине есть множественное число, согласование родов и фонетическая система, близкая к кельтским языкам (в первую очередь к валлийскому). Есть у синдарина и своя письменность — тенгвар, и перевод выдаётся именно на ней.
При создании этой модели переводчики тоже применяли трюки с близостью языков. Поскольку вымышленный синдарин имеет общие черты с реальным валлийским, уже имеющиеся модели для современных кельтских языков были переиспользованы для подготовки данных на синдарине.
Правда, поскольку синдарин всё-таки выдуман одним человеком, слов на нём известно гораздо меньше, чем на любом естественном языке. Поэтому при переводе часть текста просто превращается в английский, транслитерированный на тенгвар.
Цифровой пульс языка в интернете
У одного из персонажей актера Антона Лапенко, известного как Инженер, есть выдающийся монолог «О рутине». В нём Инженер рассказывает о своей работе в НИИ («Мы стараемся, делаем») и в какой-то момент разражается патетическим вопросом в воздух: «Для кого всё это? Для вас?»
Инженерам Яндекса ответить на этот вопрос легче: у них есть конкретные цифры использования подключённых языков. Сегодня только переводом между русским и якутским пользуются 40 тысяч раз в день. Такую же активность — 40 тысяч дневных сессий — показывает русско-чувашский переводчик, для башкирского языка показатель доходит до 70 тысяч сессий, а татарский — второй по величине национальный язык России после русского с 4 миллионами носителей — используют в переводчике Яндекса около 250 тысяч раз в день.
Эти цифры — что-то вроде цифрового пульса малых языков. Пока ежедневно возникают десятки тысяч потребностей перевести якутский текст, можно быть уверенным, что язык продолжает жить. Конечно, некоторые языки живут и без выхода в интернет — но те, что в нём прописались, уже точно оставят за собой цифровой след в памяти человечества. Да и шансов обрести новую жизнь в информационном пространстве будущего у них больше.
Источник: techno.yandex.ru