Алгоритм классификации Random Forest на Python
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2022-01-25 14:23

Случайный лес (Random forest, RF) — это алгоритм обучения с учителем. Его можно применять как для классификации, так и для регрессии. Также это наиболее гибкий и простой в использовании алгоритм. Лес состоит из деревьев. Говорят, что чем больше деревьев в лесу, тем он крепче. RF создает деревья решений для случайно выбранных семплов данных, получает прогноз от каждого дерева и выбирает наилучшее решение посредством голосования. Он также предоставляет довольно эффективный критерий важности показателей (признаков).
Случайный лес имеет множество применений, таких как механизмы рекомендаций, классификация изображений и отбор признаков. Его можно использовать для классификации добросовестных соискателей кредита, выявления мошенничества и прогнозирования заболеваний. Он лежит в основе алгоритма Борута, который определяет наиболее значимые показатели датасета.
Алгоритм Random Forest
Давайте разберемся в алгоритме случайного леса, используя нетехническую аналогию. Предположим, вы решили отправиться в путешествие и хотите попасть в туда, где вам точно понравится.
Итак, что вы делаете, чтобы выбрать подходящее место? Ищите информацию в Интернете: вы можете прочитать множество различных отзывов и мнений в блогах о путешествиях, на сайтах, подобных Кью, туристических порталах, — или же просто спросить своих друзей.
Предположим, вы решили узнать у своих знакомых об их опыте путешествий. Вы, вероятно, получите рекомендации от каждого друга и составите из них список возможных локаций. Затем вы попросите своих знакомых проголосовать, то есть выбрать лучший вариант для поездки из составленного вами перечня. Место, набравшее наибольшее количество голосов, станет вашим окончательным выбором для путешествия.
Вышеупомянутый процесс принятия решения состоит из двух частей.
- Первая заключается в опросе друзей об их индивидуальном опыте и получении рекомендации на основе тех мест, которые посетил конкретный друг. В этой части используется алгоритм дерева решений. Каждый участник выбирает только один вариант среди знакомых ему локаций.
- Второй частью является процедура голосования для определения лучшего места, проведенная после сбора всех рекомендаций. Голосование означает выбор наиболее оптимального места из предоставленных на основе опыта ваших друзей. Весь этот процесс (первая и вторая части) от сбора рекомендаций до голосования за наиболее подходящий вариант представляет собой алгоритм случайного леса.
Технически Random forest — это метод (основанный на подходе «разделяй и властвуй»), использующий ансамбль деревьев решений, созданных на случайно разделенном датасете. Набор таких деревьев-классификаторов образует лес. Каждое отдельное дерево решений генерируется с использованием метрик отбора показателей, таких как критерий прироста информации, отношение прироста и индекс Джини для каждого признака.
Любое такое дерево создается на основе независимой случайной выборки. В задаче классификации каждое дерево голосует, и в качестве окончательного результата выбирается самый популярный класс. В случае регрессии конечным результатом считается среднее значение всех выходных данных ансамбля. Метод случайного леса является более простым и эффективным по сравнению с другими алгоритмами нелинейной классификации.
Как работает случайный лес?
Алгоритм состоит из четырех этапов:
- Создайте случайные выборки из заданного набора данных.
- Для каждой выборки постройте дерево решений и получите результат предсказания, используя данное дерево.
- Проведите голосование за каждый полученный прогноз.
- Выберите предсказание с наибольшим количеством голосов в качестве окончательного результата.
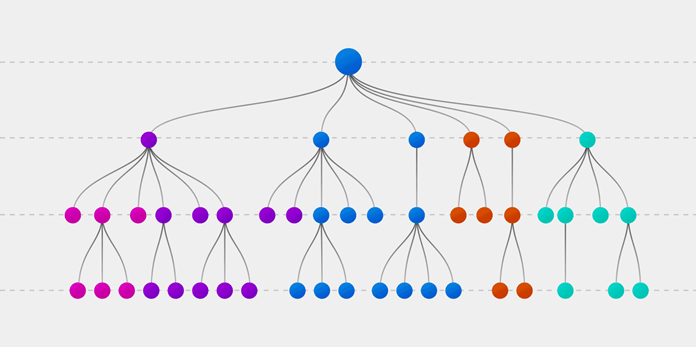
Поиск важных признаков
Random forest также предлагает хороший критерий отбора признаков. Scikit-learn предоставляет дополнительную переменную при использовании модели случайного леса, которая показывает относительную важность, то есть вклад каждого показателя в прогноз. Библиотека автоматически вычисляет оценку релевантности каждого признака на этапе обучения. Затем полученное значение нормализируется так, чтобы сумма всех оценок равнялась 1.
Такая оценка поможет выбрать наиболее значимые показатели и отбросить наименее важные для построения модели.
Случайный лес использует критерий Джини, также известный как среднее уменьшение неопределенности (MDI), для расчета важности каждого признака. Кроме того, критерий Джини иногда называют общим уменьшением неопределенности в узлах. Он показывает, насколько снижается точность модели, когда вы отбрасываете переменную. Чем больше уменьшение, тем значительнее отброшенный признак. Таким образом, среднее уменьшение является необходимым параметром для выбора переменной. Также с помощью данного критерия можете быть отображена общая описательная способность признаков.
Сравнение случайных лесов и деревьев решений
- Случайный лес — это набор из множества деревьев решений.
- Глубокие деревья решений могут страдать от переобучения, но случайный лес предотвращает переобучение, создавая деревья на случайных выборках.
- Деревья решений вычислительно быстрее, чем случайные леса.
- Случайный лес сложно интерпретировать, а дерево решений легко интерпретировать и преобразовать в правила.
Создание классификатора с использованием Scikit-learn
Вы будете строить модель на основе набора данных о цветках ириса, который является очень известным классификационным датасетом. Он включает длину и ширину чашелистика, длину и ширину лепестка, и тип цветка. Существуют три вида (класса) ирисов: Setosa, Versicolor и Virginica. Вы построите модель, определяющую тип цветка из вышеперечисленных. Этот датасет доступен в библиотеке scikit-learn или вы можете загрузить его из репозитория машинного обучения UCI.
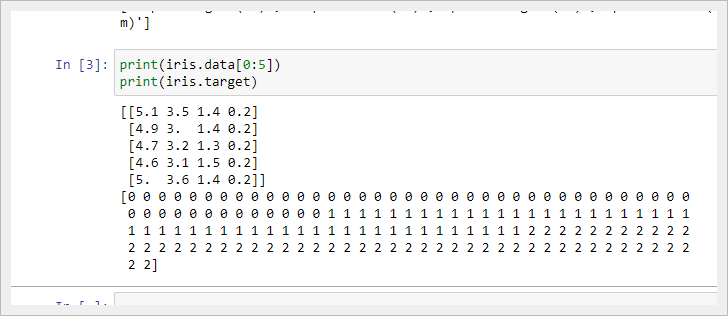
Начнем с импорта datasets из scikit-learn и загрузим набор данных iris с помощью load_iris().
Копировать Скопировано Use a different Browser
from sklearn import datasets # загрузка датасета iris = datasets.load_iris()
Вы можете отобразить имена целевого класса и признаков, чтобы убедиться, что это нужный вам датасет:
Копировать Скопировано Use a different Browser
print(iris.target_names) print(iris.feature_names)
['setosa' 'versicolor' 'virginica'] ['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)']Рекомендуется всегда хотя бы немного изучить свои данные, чтобы знать, с чем вы работаете. Здесь вы можете увидеть результат вывода первых пяти строк используемого набора данных, а также всех значений целевой переменной датасета.
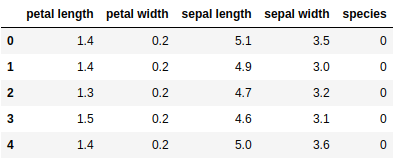
Ниже мы создаем dataframe из нашего набора данных об ирисах.
Копировать Скопировано Use a different Browser
import pandas as pd data=pd.DataFrame({ 'sepal length':iris.data[:,0], 'sepal width':iris.data[:,1], 'petal length':iris.data[:,2], 'petal width':iris.data[:,3], 'species':iris.target }) data.head()
Далее мы разделяем столбцы на зависимые и независимые переменные (признаки и метки целевых классов). Затем давайте создадим выборки для обучения и тестирования из исходных данных.
Копировать Скопировано Use a different Browser
from sklearn.model_selection import train_test_split X = data[['sepal length', 'sepal width', 'petal length', 'petal width']] y = data['species'] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=85)
После этого мы сгенерируем модель случайного леса на обучающем наборе и выполним предсказания на тестовом.
Копировать Скопировано Use a different Browser
from sklearn.ensemble import RandomForestClassifier clf = RandomForestClassifier(n_estimators=100) clf.fit(X_train, y_train) y_pred = clf.predict(X_test)
После создания модели стоит проверить ее точность, используя фактические и спрогнозированные значения.
Копировать Скопировано Use a different Browser
from sklearn.ensemble import RandomForestClassifier clf = RandomForestClassifier(n_estimators=100) clf.fit(X_train, y_train) y_pred = clf.predict(X_test)
Accuracy: 0.9333333333333333 Вы также можете сделать предсказание для единственного наблюдения. Предположим, sepal length=3, sepal width=5, petal length=4, petal width=2.
Мы можем определить, к какому типу цветка относится выбранный, следующим образом:
Копировать Скопировано Use a different Browser
clf.predict([[3, 5, 4, 2]]) # результат - 2
Выше цифра 2 указывает на класс цветка «virginica».
Поиск важных признаков с помощью scikit-learn
В этом разделе вы определяете наиболее значимые признаки или выполняете их отбор в датасете iris. В scikit-learn мы можем решить эту задачу, выполнив перечисленные шаги:
- Создадим модель случайного леса.
- Используем переменную
feature_importances_, чтобы увидеть соответствующие оценки значимости показателей. - Визуализируем полученные оценочные значения с помощью библиотеки seaborn.
Копировать Скопировано Use a different Browser
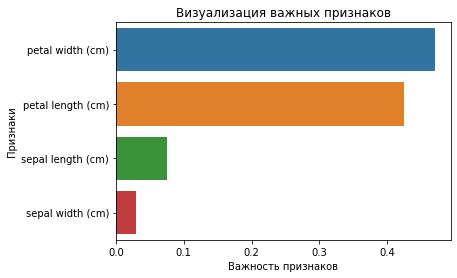
from sklearn.ensemble import RandomForestClassifier import pandas as pd clf = RandomForestClassifier(n_estimators=100) clf.fit(X_train,y_train) feature_imp = pd.Series(clf.feature_importances_,index=iris.feature_names).sort_values(ascending=False) feature_imp
petal width (cm) 0.470224 petal length (cm) 0.424776 sepal length (cm) 0.075913 sepal width (cm) 0.029087Вы также можете визуализировать значимость признаков. Такое графическое отображение легко понять и интерпретировать. Кроме того, визуальное представление информации является самым быстрым способом ее усвоения человеческим мозгом.
Для построения необходимых диаграмм вы можете использовать библиотеки matplotlib и seaborn совместно, потому что seaborn, построенная поверх matplotlib, предлагает множество специальных тем и дополнительных графиков. Matplotlib — это надмножество seaborn, и обе библиотеки одинаково необходимы для хорошей визуализации.
Копировать Скопировано Use a different Browser
import matplotlib.pyplot as plt import seaborn as sns %matplotlib inline sns.barplot(x=feature_imp, y=feature_imp.index) plt.xlabel('Важность признаков') plt.ylabel('Признаки') plt.title('Визуализация важных признаков') plt.show()
Повторная генерация модели с отобранными признаками
Далее мы удаляем показатель «sepal width» и используем оставшиеся 3 признака, поскольку ширина чашелистика имеет очень низкую важность.
Копировать Скопировано Use a different Browser
from sklearn.model_selection import train_test_split X = data[['petal length', 'petal width','sepal length']] y = data['species'] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.7, random_state=85)
После разделения вы сгенерируете модель случайного леса для выбранных признаков обучающей выборки, выполните прогноз на тестовом наборе и сравните фактические и предсказанные значения.
Копировать Скопировано Use a different Browser
from sklearn.ensemble import RandomForestClassifier clf = RandomForestClassifier(n_estimators=100) clf.fit(X_train,y_train) y_pred = clf.predict(X_test) from sklearn import metrics print("Accuracy:", metrics.accuracy_score(y_test, y_pred))
Accuracy: 0.9619047619047619 Вы можете заметить, что после удаления наименее важных показателей (ширины чашелистика) точность увеличилась, поскольку мы устранили вводящие в заблуждение данные и уменьшили шум. Кроме того, ограничив количество значимых признаков, мы сократили время обучения модели.
Преимущества Random Forest:
- Случайный лес считается высокоточным и надежным методом, поскольку в процессе прогнозирования участвует множество деревьев решений.
- Random forest не страдает проблемой переобучения. Основная причина в том, что случайный лес использует среднее значение всех прогнозов, что устраняет смещения.
- RF может использоваться в обоих типах задач (задачах классификации и регрессии).
- Случайный лес также может работать с отсутствующими значениями. Есть два способа решения такой проблемы в Random forest. В первом используется медианное значение для заполнения непрерывных переменных, а во втором вычисляется среднее взвешенное пропущенных значений.
- RF также рассчитывает относительную важность показателей, которая помогает в выборе наиболее значимых признаков для классификатора.
Недостатки Random Forest:
- Случайный лес довольно медленный, так как для работы алгоритм использует множество деревьев: каждому дереву в лесу передаются одни и те же входные данные, на основании которых оно должно вернуть свое предсказание. После чего также происходит голосование на полученных прогнозах. Весь этот процесс занимает много времени.
- Модель случайного леса сложнее интерпретировать по сравнению с деревом решений, где вы легко определяете результат, следуя по пути в дереве.
Заключение
Вы узнали об алгоритме Random forest и принципе его работы, о поиске важных признаков, о главных отличиях случайного леса от дерева решений, о преимуществах и недостатках данного метода. Также научились создавать и оценивать модели, находить наиболее значимые показатели в scikit-learn. Не останавливайся на этом!
Я рекомендую вам попробовать RF на разных наборах данных и прочитать больше о матрице ошибок.
Источник: pythonru.com