«Ты узнаешь ее из тысячи...» или классифицируем изображения с веб-камеры в реальном времени с помощью PyTorch
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2019-12-01 23:52
теория распознавания образов, свёрточные нейронные сети, работа головного мозга
Вот бывает же в жизни такое. Сидишь себе не шалишь, никого не трогаешь, починяешь примус, а тут из этого примуса, из телевизора, да и вообще из каждого утюга, до тебя доносится: «нейронные сети, глубокое обучение, искусственный интеллект, цифровая экономика…».
Я — человек, а значит существо любопытное и алчное . В очередной раз не удержался и решил узнать на практике, что такое нейронные сети и с чем их едят.
Как говориться: «Хочешь научиться сам — начни учить других», на этом я перестану сыпать цитатами и перейдем к делу.
В данной статье мы вместе с вами попробуем, решить задачу, которая как оказалось будоражит не только мой ум.
Не имея достаточных фундаментальных знаний в области математики и программирования мы попробуем в реальном времени классифицировать изображения с веб-камеры, с помощью OpenCV и библиотеки машинного обучения для языка Python — PyTorch. По пути узнаем о некоторых моментах, которые могли бы быть полезны новичкам в применении нейронных сетей.
Вам интересно сможет ли наш классификатор отличить Arduino-совместимые контроллеры от малины? Тогда милости прошу под кат.

Содержание: Часть I: введение Часть II: распознаем изображение с помощью нейронных сетей Часть III: готовимся использовать PyTorch Часть IV: пишем код на Python Часть V: плоды трудов
Часть I: введение
Если честно, еще практически сразу после прохождения специализации на Coursera по машинному обучению, я хотел подготовить какой-нибудь материал в цикл статей по машинному обучению глазами новичка.
Однако, собраться с силами и написать получилось только сейчас. Для начала надо предупредить, подумайте хорошо, готовы ли вы погрузиться в этот удивительный мир?
На подготовку этой статьи у меня ушло полных четыре выходных дня и еще пара будних вечеров. А также куча безуспешных попыток разобраться с вопросом без предварительной подготовки. Поэтому в данном случае будет уместно переиначить известную графическую юмореску с Максом Планком.

Также надо сказать, что для понимания примеров кода из этой статьи все же будут необходимы базовые знания языка Python и его распространённых библиотек машинного обучения (например, NumPy). В данной статье не будет теоретических выкладок или подробного описания нейронных сетей и принципов их работы, поскольку не прилично пытаться с умным видом говорить, о том в чем сам не до конца разобрался. Поэтому мы просто посмотрим, как я мучился, постараемся не совершить тех же ошибок, а в конце сможем даже что-то распознать.
Вы еще читаете этот текст? Отлично, теперь я уверен в силе вашего духа и стойкости.
Часть II: распознаем изображение с помощью нейронных сетей
Благодаря, тому, что разработкой всего что связанно с нейронными сетями занимается куча умных и наверняка талантливых людей, существует множество бесплатных инструментов и примеров решения задач от распознавания номеров автомобилей до перевода текстов.
Хотите с помощью веб-камеры с высокой достоверностью распознать, что перед вами человек или монитор, не вопрос, просто находим реализованный пример, копируем менее ста строчек кода и «вуаля» «voil?».

Всё это может создать обманчивую иллюзию простоты. Сложности возникнут если вы захотите сделать, что-то свое. Ведь всегда же хочется если уж не собрать свой велосипед, то хотя бы прикрутить к нему клевый рожок и фонарик.
Итак, в примере выше нам встречается функция:
net = cv2.dnn.readNetFromCaffe(args_prototxt, args_model)
Которая явно намекает, даже неподготовленному человеку, что для нейронной сети используется, что-то с названием «Caffe».
Как выяснилось Caffe это – фреймворк для глубокого машинного обучения. Сложно, сказать, что именно мне по незнанию не понравилось, может быть сайт проекта со скучными обоями , может просто на слуху был TensorFlow, но я твердо решил, что начинать с Caffe не буду.
Не подумайте ничего, я не хочу критиковать Caffe я предполагаю, что это хороший фреймворк, просто первое впечатление не сложилось. Я наверняка вернусь к нему, когда-то попозже.
Ну что же взглянем на TensorFlow. Если верить русскоязычной «Википедии»:
TensorFlow — открытая программная библиотека для машинного обучения, разработанная компанией Google для решения задач построения и тренировки нейронной сети с целью автоматического нахождения и классификации образов, достигая качества человеческого восприятия.
Я решил, что это очень круто, побежал тыкать во все попавшиеся туториалы, в том числе по обучению уже готовых моделей для классификации изображений на своих наборах данных. После коротких мгновений ликования, я радостно нахожу в OpenCV метод:
cv.dnn.readNetFromTensorflow(model[, config] )
А дальше радостно бегу в Интернет пополнять очередь из людей задающих следующие вопросы:
«Как конвертировать модель в .h5 в .pb файл»
«Как получить замороженный (frozen)_ .pb файл»
«Как из .pb файла сделать .pbtxt»
Давно я не чувствовал такого единения как с людьми, вопрошающими эти и другие дилетантские вопросы на Stack overflow.
Причем во всех примерах, что мне попадались был какой-то подвох и что-то наработало даже пример от OpenCV выдавал ошибку при запуске. В итоге первая неделя ушла на попытки, не вникая в детали и не изучая основ добиться, хоть чего-то от TensorFlow и OpenCV.
Но после того, как в один из дней в четыре часа утра, программа посмотрела на меня своим беспристрастным глазом веб-камеры и сказала, что я с 22% вероятностью – аэроплан, ко мне пришло осознание, что пора что-то менять в подходе к делу.
Как и в случае с Caffe прошу вас не думать, что я имею, что-то против TensorFlow. Это очень крутая библиотека с огромным сообществом, просто я не смог взять её «штурмом» разочаровался и пошел искать решение дальше. Но на самом деле я обязательно к ней вернусь более подготовленным и напишу небольшую статью, об этом.
А пока продолжим отслеживать метания возбужденного и опечаленного неудачей ума.
Посмотрим еще раз какие у OpenCV бывают методы для работы с нейронными сетями и находим:
cv.dnn.readNetFromTorch(model[, isBinary[, evaluate]])
Ого! Похоже пришло время познакомится с еще одной библиотекой для машинного обучения.
Часть III: Готовимся использовать PyTorch
Как было сказано PyTorch это еще один достаточно популярный фреймворк в области машинного обучения, к которому приложили руки люди из Facebook. Субъективно, мне показалось, что на сайте PyTorch меньше учебных примеров и что сообщество у фреймворка несколько меньше, чем у TensorFlow, но забегая вперёд скажу, что именно с ним у меня получилось сделать, почти то что изначально было задумано. Итак, как я уже написал выше на второй неделе пришло понимание, что просто «копипастить» в слепою чужие примеры вообще не понимая, что делаешь в надежде, собрать готовую модель и распознать с помощью OpenCV изображение с веб-камеры — это путь в никуда.
Поэтому было решено параллельно писать скрипт и узнавать о нейронных сетях.
Очень хорошим подспорьем в этом деле является книга Рашида Тарика «Создаем нейронную сеть», о ней уже упоминалось на Хабре habr.com/ru/post/440190. В этой книге очень доступным языком написано о базовых концепциях нейронных сетей, но, естественно, она не научит нас пользоваться PyTorch.
Поэтому не лишним будет пробежать туториал про глубокое обучение с PyTorch за 60 минут. Это действительно не займет много времени, но даст хотя бы частичное понимание основных принципов работы. Вы можете выполнять код как на Google Colab, так и локально. Вот мы плавно и подошли к вопросу о том, как писать код на своей машине.
На официальном сайте нам предложат различные варианты установки в зависимости от операционной системы, желаемой версии питон и способа установки. Для начинающих любителей машинного обучения с помощью Python я предлагаю установить PyTorch используя дистрибутив Anaconda, который хорошо работает и под Windows и под Linux. После чего создать в Anaconda отдельное окружение для наших экспериментов и начать потихоньку ставить туда все необходимые пакеты, в том числе и OpenCV.
В Anaconda можно установить PyTorch можно как через графический интерфейс, так и через консоль (Anaconda Prompt для Windows).

Для распознавания изображений нам понадобится библиотека tourchvision. Также возможно в тексте, введённом в консоль вы уже разглядели «cudatoolkit=10.1» и у вас возник вопрос, что такое CUDA какую версию надо ставить и надо ли вообще.
Как я понимаю, CUDA позволяет перенести вычисления с процессора на видеокарту от Nvidia. Судя по отзывам это в разы ускоряет процесс вычисления модели. Но в бочке меда есть ложка дегтя, если Вы как и я счастливый обладатель древней видеокарты, то в после установки при попытке использовать CUDA PyTorch может вас вначале попросить обновить драйвер видеокарты, а потом разбить все надежды, сообщив, что ваша видеокарта слишком старая и не поддерживается.
Например, моя GTX 760, судя по всему, поддерживалась CUDA версии 3.5. Я не нашел списка видеокарт, поддерживаемых той или иной версией CUDA, но думаю, что все обладатели достаточно старых видеокарт, могут не колебаться между версией 9.2 и 10.1, а сразу ставить версию без её поддержки.
Остались буквально последние штрихи перед тем как мы начнем писать код.
Мы же хотим, чтобы модель распознавала, объекты близкие нашему сердцу, а значит нам необходимо собрать свой набор изображений.
В данном случае нам поможет класс torchvision.datasets.ImageFolder, который в связке с классом torch.utils.data.DataLoader позволяет из структурированного набора папок с изображениями создать свой датасет.
Структура нашего набора изображений будет выглядеть примерно так:
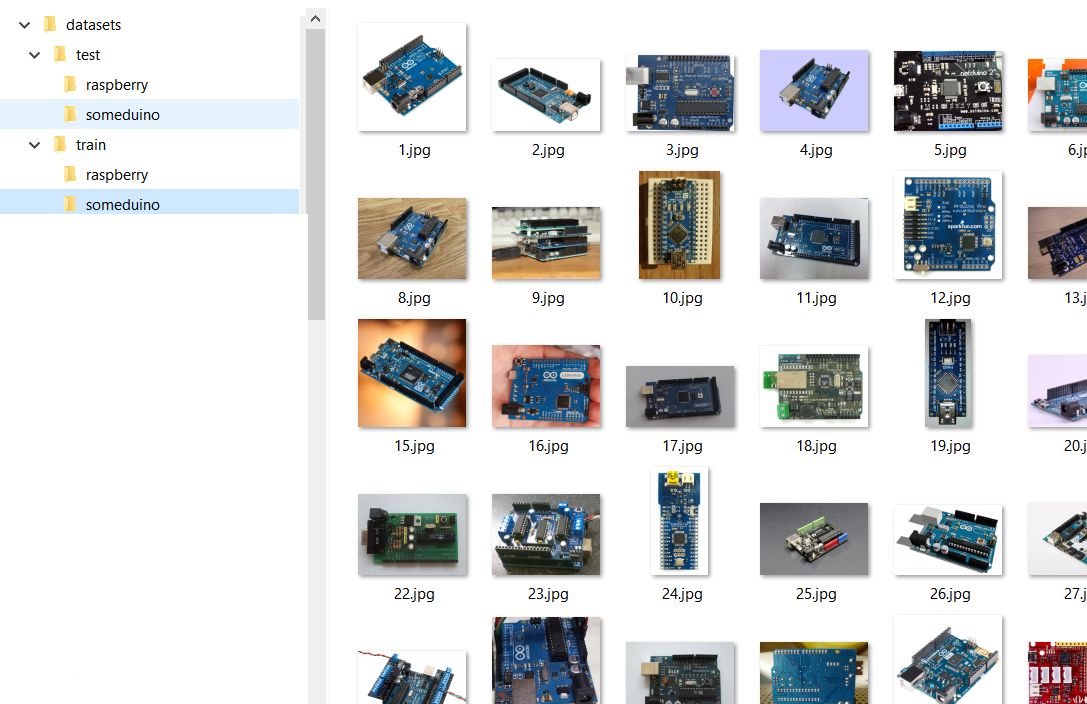
То есть у нас есть папки Test и Train в которых, расположены папки с распознаваемыми классами классами «someduino» и «raspberry». В учебном выборке для каждого класса представлено 128 изображений в тестовой – 28. Надо сказать, что по хорошему нейронную сеть с нуля надо учить на миллионах или хотя бы сотнях тысяч картинок, но мы себе практических задач особо не ставим и попробуем справиться с тем, что удалось собрать. Кстати два слова о сборе изображений для своего датасета.
Если вы хотите выложить датасет в сеть и не иметь ночных кошмаров на тему нарушения авторских прав, рекомендую использовать изображения права на, которые позволяют вам это сделать.
Найти их можно, например с помощью поиска по картинкам Google, выбрав соответствующий пункт в фильтрах к поиску, как показано на рисунке ниже.

Ну и часть изображений всегда можно сделать самостоятельно. Я должен попросить прощения если смутил вас, возможно из заглавной картинки статьи вы подумали, что мы будем сравнивать изображения Arduino и raspberry pi, однако для больших различий между классами, мы будем сравнивать изображения различных версий Arduino (и ее клонов) с ягодой малиной.
Часть IV: пишем код на Python
Вот мы и добрались, до самого интересного.
Как всегда все материалы данной статьи, включая изображения я выложил в свободный доступ на GitHub. Начнем мы с блокнота Jupyter в котором будем обучать модель.
Блокнот разбит на две логические части одна посвящена созданию простой модели и обучению её с нуля, а в другой мы применим transfer learning к уже готовой и обученной модели.
В первом случае мы ориентируемся на этот туториал. Я практически ничего не правил в материалах из туториала, так как боялся сломать, то что плохо понимаю, поэтому в принципе вы можете изучить вышеуказанный пример и добиться похожих результатов.
Для начало импортируем необходимые библиотеки (убедитесь, что вы их установили).
from __future__ import print_function, division import torch import torch.nn as nn import torch.optim as optim from torch.optim import lr_scheduler import numpy as np import matplotlib.pyplot as plt import torchvision from torchvision import datasets, models import torchvision.transforms as transforms import matplotlib.pyplot as plt import time import os import copy import torch.nn as nn import torch.nn.functional as F import torch.optim as optim from torch.autograd import Variable import torch.onnx import torchvision %matplotlib inline plt.ion() # interactive moden
Затем определим адрес, из которого будем загружать датасет
#get address such as C:(folder with you notebook) dir = os.path.abspath(os.curdir) # i suppose what your image folders placed in datasets directory data_dir=os.path.join(dir, "datasets")
Ниже идет код для трансформации изображения, в котором мы при необходимости уменьшаем, обрезаем, делаем темнее или ярче данные прежде чем скормить их модели.
В нашем случае мы уменьшаем изображение до 32х32 пикселя и нормализуем его (в математику сейчас лезть не будем).
# Data scaled and normalization for training and testing data_transforms = { 'train': transforms.Compose([ transforms.RandomResizedCrop(32), transforms.ToTensor(), transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5]) ]), 'test': transforms.Compose([ transforms.RandomResizedCrop(32), transforms.ToTensor(), transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5]) ]), }
Далее мы напишем функцию, которая преобразует наши картинки в массив данных (тензоров) для дальнейшего обучения. Функция немного отличается, от представленной в примере, поскольку мы будем использовать ее два раза, в качестве входных параметров используется не только путь к папке, но и схема преобразования.
#Create function to get your(my) images dataset and resize it to size for model def get_dataset(data_dir, data_transforms ): # create train and test datasets image_datasets = {x: datasets.ImageFolder(os.path.join(data_dir, x), data_transforms[x]) for x in ['train', 'test']} dataloaders = {x: torch.utils.data.DataLoader(image_datasets[x], batch_size=4, shuffle=True, num_workers=4) for x in ['train', 'test']} dataset_sizes = {x: len(image_datasets[x]) for x in ['train', 'test']} #get classes from train dataset folders name classes = image_datasets['train'].classes return dataloaders["train"], dataloaders['test'], classes, dataset_sizes
На выходе функция возвращает два датасета в формате необходимом для нашей модели нейронной сети, а также в качестве бонуса информацию о классах картинок полученных из названия папок, и размер учебной и тренировочной выборок.
Когда будете делать свой датасет убедитесь, что структуры папок train и test идентичны (одинаковое количество классов), а также то что вы использовали .jpg изображения. Иногда под видом невинной картинки закрадывается всякий мусор, который при обработке вызывает ошибку.
Воспользуемся, только что созданной функцией.
trainloader, testloader, classes, dataset_sizes=get_dataset(data_dir,data_transforms) print('Classes: ', classes) print('The datasest have: ', dataset_sizes ," images")
Как и ожидалось, у нас есть только два класса: пролетариат и буржуазия 'raspberry' и 'someduino'.
Учебная выборка содержит из 256 изображений, контрольная – 56.
Посмотрим, как выглядят наши данные в учебной выборке.
# create function for print unnormalized images def imshow(img): img = img / 2+0.5 # unnormalize npimg = img.numpy() plt.imshow(np.transpose(npimg, (1, 2, 0))) plt.show() # get some random training images dataiter = iter(trainloader) images, labels = next(dataiter) #images, labels = dataiter.next() # show images imshow(torchvision.utils.make_grid(images)) # print labels print(' '.join('%5s' % classes[labels[j]] for j in range(4)))
Если мы с вами на глазок можем отличать объекты на картинке размеров 32х32, значит и наша нейронная сеть должна суметь.

Далее собственно и сама модель. Здесь мы создаем слои с различными размерностями входа и выхода, а также функции, благодаря которым будут проводиться преобразования. К сожалению, этот этап у меня в голове до конца не уложился, поэтому просто используем его, главное, что он работает.
class Net(nn.Module): def __init__(self): super(Net, self).__init__() self.conv1 = nn.Conv2d(3, 6, 5) self.pool = nn.MaxPool2d(2, 2) self.conv2 = nn.Conv2d(6, 16, 5) self.fc1 = nn.Linear(16 * 5 * 5, 120) self.fc2 = nn.Linear(120, 84) self.fc3 = nn.Linear(84, 2) def forward(self, x): x = self.pool(F.relu(self.conv1(x))) x = self.pool(F.relu(self.conv2(x))) x = x.view(-1, 16 * 5 * 5) x = F.relu(self.fc1(x)) x = F.relu(self.fc2(x)) x = self.fc3(x) return x net = Net() print(net)
В конце этого куска кода мы, собственно, создали нашу нейронную сеть.
Если хотите больше классов, то попробуйте в строке ниже заменить тут двойку на тройку.
self.fc3 = nn.Linear(84, 2)
Осталось чему-то научить модель.
criterion = nn.CrossEntropyLoss() optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9) device = torch.device("cpu") for epoch in range(11): # loop over the dataset multiple times running_loss = 0.0 for i, data in enumerate(trainloader, 0): # get the inputs; data is a list of [inputs, labels] inputs, labels = data # zero the parameter gradients optimizer.zero_grad() # forward + backward + optimize outputs = net(inputs) loss = criterion(outputs, labels) loss.backward() optimizer.step() # print statistics running_loss += loss.item() if i % 15 == 14: # print every 15 mini-batches print('[%d, %5d] loss: %.3f' % (epoch + 1, i + 1, running_loss / 15)) running_loss = 0.0 print('Finished Training')
В вышеуказанном фрагменте кода мы вначале определили критерии оптимизации и завершения обучения. А затем начали учить нашу модель в течение 11 эпох.
Чем больше эпох, тем лучше должна обучиться модель (меньше ошибка предсказания), однако тем больше времени требуется. Наша модель (скорее всего) из-за случайного перемешивания датасетов будет каждый раз выдавать разную ошибку, но к 11 эпохе она все равно будет стремиться ближе к нулю.
В данном цикле, для наглядности периодически выводится информация о ходе обучения.
Вот, что выдает модель, на моем компьютере. Текст длинный пожатому спрячу под спойлер.
Ошибки модели в разные эпохи
[1, 15] loss: 0.597
[1, 30] loss: 0.588
[1, 45] loss: 0.539
[1, 60] loss: 0.550
[2, 15] loss: 0.515
[2, 30] loss: 0.424
[2, 45] loss: 0.434
[2, 60] loss: 0.391
[3, 15] loss: 0.392
[3, 30] loss: 0.392
[3, 45] loss: 0.282
[3, 60] loss: 0.211
[4, 15] loss: 0.292
[4, 30] loss: 0.247
[4, 45] loss: 0.197
[4, 60] loss: 0.343
[5, 15] loss: 0.400
[5, 30] loss: 0.206
[5, 45] loss: 0.254
[5, 60] loss: 0.299
[6, 15] loss: 0.258
[6, 30] loss: 0.231
[6, 45] loss: 0.241
[6, 60] loss: 0.332
[7, 15] loss: 0.243
[7, 30] loss: 0.324
[7, 45] loss: 0.211
[7, 60] loss: 0.271
[8, 15] loss: 0.207
[8, 30] loss: 0.200
[8, 45] loss: 0.201
[8, 60] loss: 0.392
[9, 15] loss: 0.255
[9, 30] loss: 0.207
[9, 45] loss: 0.367
[9, 60] loss: 0.296
[10, 15] loss: 0.180
[10, 30] loss: 0.230
[10, 45] loss: 0.345
[10, 60] loss: 0.232
[11, 15] loss: 0.239
[11, 30] loss: 0.239
[11, 45] loss: 0.218
[11, 60] loss: 0.288
Finished Training
Пришла пора проверить на контрольной выборке, способна ли наша модель классифицировать картинки.
correct = 0 total = 0 with torch.no_grad(): for data in testloader: images, labels = data outputs = net(images) _, predicted = torch.max(outputs.data, 1) for printdata in list(zip(predicted,labels,outputs)): printclass =[classes[int(printdata[0])],classes[int(printdata[1])]] print('Predict class - {0}, real class - {1}, probability ({2},{3}) - {4}'.format( printclass[0],printclass[1], classes[0], classes [1],printdata[2])) total += labels.size(0) correct += (predicted == labels).sum().item() imshow(torchvision.utils.make_grid(images)) #print('GroundTruth: ', ' '.join('%5s' % classes[predicted[j]] for j in range(4))) print('Accuracy of the network on the', dataset_sizes['test'], 'test images: %d %%' % ( 100 * correct / total))
Запускаем код и видим, что да вполне способна. А вот если бы мы провели всего 2 – 3 эпохи, то результат был бы плачевный.
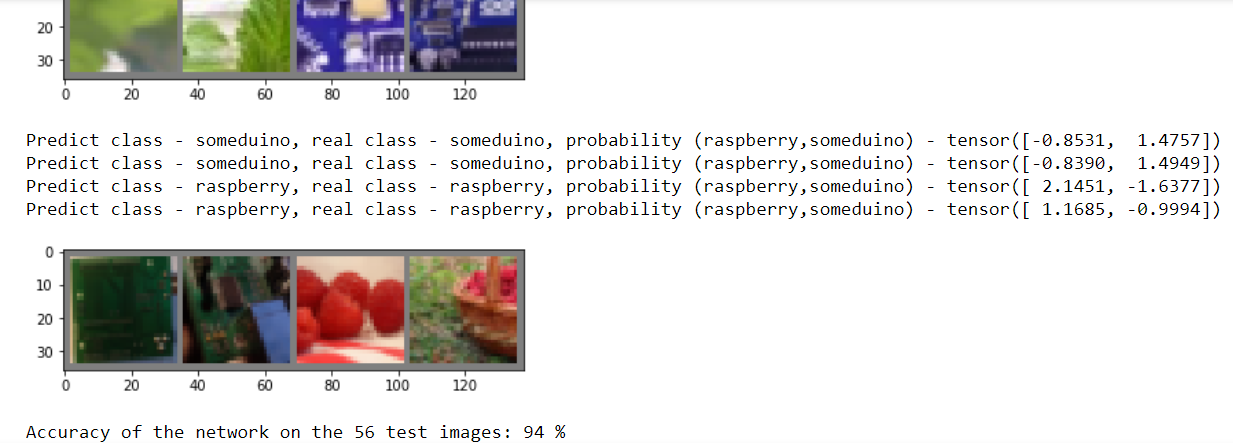
Естественно, вам будут показаны результаты по всем 28 контрольным изображениям, просто по понятным причинам на рисунок они все не влезли. Дальше идет необязательный код. В котором показано, как сохранить и загрузить модель, а также повторно выводится анализ контрольных изображений, подтверждающий, что качество не ухудшилось.
#(Optional) #Save and load model PATH =os.path.join(dir, "my_model.pth") torch.save(net.state_dict(), PATH) net = Net() net.load_state_dict(torch.load(PATH))
Код с выводом картинок аналогичен, тому, что был выше.
Ну вот и все мы обучили нашу первую модель распознавать картинки, осталось дело за малым вставить ее сохраненную версию в функцию
cv.dnn.readNetFromTorch("my_model.pth")
Но о ужас! Этот код выдаст ошибку, потому что словарь PyTorch и файл модели которую сохраняет Tourch, это не одно и тоже, а от нас тут ждут именно модель Torch.

Не стоит паниковать. Еще раз смотрим, с какими моделями может работать OpenCV и находим
cv.dnn.readTensorFromONNX(path)
Вот он наш замечательный компромисс. Осталось только, конвертировать нашу модель в .onnx
# Export model to onnx format PATH =os.path.join(dir, "my_model.onnx") #(1, 3, 32, 32) – параметры нашей модели, 3 канала цвета 32х32 пикселя, dummy_input = Variable(torch.randn(1, 3, 32, 32)) torch.onnx.export(net, dummy_input, PATH)
Забегая вперед, скажу, что все будет замечательно работать, но прежде, чем перейти к работе с веб-камерой. Давайте попробуем взять более качественную модель и обучить ее на нашем наборе данных.
Данная половина блокнота будет базироваться на этом туториале и обучать мы будем модель resnet18 Обратите внимание для этой модели нужна немного другая подготовка исходных данных. Как правило о параметрах преобразования можно почитать в описаниях к модели или прост позаимствовав чужой пример.
#Data scaled and normalization for training and testing for resnet18 data_transforms = { 'train': transforms.Compose([ transforms.RandomResizedCrop(224), transforms.RandomHorizontalFlip(), transforms.ToTensor(), transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]) ]), 'test': transforms.Compose([ transforms.Resize(256), transforms.CenterCrop(224), transforms.ToTensor(), transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]) ]), }
Дальше идет, по сути, аналогичный код, подготовки датасетов и просмотра картинок, его оставим без комментариев.
# get train and test data trainloader, testloader, classes, dataset_sizes=get_dataset(data_dir, data_transforms) print('Classes: ', classes) print('The datasest have: ', dataset_sizes ," images") # Create new image show function for new transofration def imshow_resNet18(inp, title=None): """Imshow for Tensor.""" inp = inp.numpy().transpose((1, 2, 0)) mean = np.array([0.485, 0.456, 0.406]) std = np.array([0.229, 0.224, 0.225]) inp = std * inp + mean inp = np.clip(inp, 0, 1) plt.imshow(inp) if title is not None: plt.title(title) plt.pause(0.001) # pause a bit so that plots are updated # get some random training images dataiter = iter(trainloader) images, labels = next(dataiter) #images, labels = dataiter.next() # show images imshow_resNet18(torchvision.utils.make_grid(images)) # print labels print(' '.join('%5s' % classes[labels[j]] for j in range(4)))
А вот и функция для обучения модели. Я в ней половину не понял, поэтому пока просто воспользуемся, как есть.
def train_model(model, criterion, optimizer, scheduler, num_epochs=25): since = time.time() best_model_wts = copy.deepcopy(model.state_dict()) best_acc = 0.0 for epoch in range(num_epochs): print('Epoch {}/{}'.format(epoch, num_epochs - 1)) print('-' * 10) # Each epoch has a training and validation phase for phase in ['train', 'test']: if phase == 'train': model.train() # Set model to training mode else: model.eval() # Set model to evaluate mode running_loss = 0.0 running_corrects = 0 # Iterate over data. for inputs, labels in dataloaders[phase]: inputs = inputs.to(device) labels = labels.to(device) # zero the parameter gradients optimizer.zero_grad() # forward # track history if only in train with torch.set_grad_enabled(phase == 'train'): outputs = model(inputs) _, preds = torch.max(outputs, 1) loss = criterion(outputs, labels) # backward + optimize only if in training phase if phase == 'train': loss.backward() optimizer.step() # statistics running_loss += loss.item() * inputs.size(0) running_corrects += torch.sum(preds == labels.data) if phase == 'train': scheduler.step() epoch_loss = running_loss / dataset_sizes[phase] epoch_acc = running_corrects.double() / dataset_sizes[phase] print('{} Loss: {:.4f} Acc: {:.4f}'.format( phase, epoch_loss, epoch_acc)) # deep copy the model if phase == 'test' and epoch_acc > best_acc: best_acc = epoch_acc best_model_wts = copy.deepcopy(model.state_dict()) print() time_elapsed = time.time() - since print('Training complete in {:.0f}m {:.0f}s'.format( time_elapsed // 60, time_elapsed % 60)) print('Best val Acc: {:4f}'.format(best_acc)) # load best model weights model.load_state_dict(best_model_wts) return model
В данном коде мне тоже сложно, что-либо комментировать.
# Let's prepare the parameters for training the model dataloaders = {'train': trainloader, 'test': testloader} model_ft = models.resnet18(pretrained=True) num_ftrs = model_ft.fc.in_features # Here the size of each output sample is set to 2. # Alternatively, it can be generalized to nn.Linear(num_ftrs, len(class_names)). model_ft.fc = nn.Linear(num_ftrs, 2) model_ft = model_ft.to(device) criterion = nn.CrossEntropyLoss() # Observe that all parameters are being optimized optimizer_ft = optim.SGD(model_ft.parameters(), lr=0.001, momentum=0.9) # Decay LR by a factor of 0.1 every 7 epochs exp_lr_scheduler = lr_scheduler.StepLR(optimizer_ft, step_size=7, gamma=0.1)
Но кое-что все же прокомментирую.
dataloaders = {'train': trainloader, 'test': testloader}
Данный словарь был необходим, чтобы ничего не трогать в функции обучения модели из туториала, но при этом сохранить ранее написанную функцию подготовки датасета.
И второй важный момент, как и в прошлом случае если хотите больше классов, замените двойку.
model_ft.fc = nn.Linear(num_ftrs, 2)
Думаю, должно сработать.
Обучим модель.
#Train the model model_ft = train_model(model_ft, criterion, optimizer_ft, exp_lr_scheduler, num_epochs=5)
Обратите внимание нам хватило, меньшего количества эпох чтобы получить ошибку не хуже, чем у первой модели за 11 эпох.
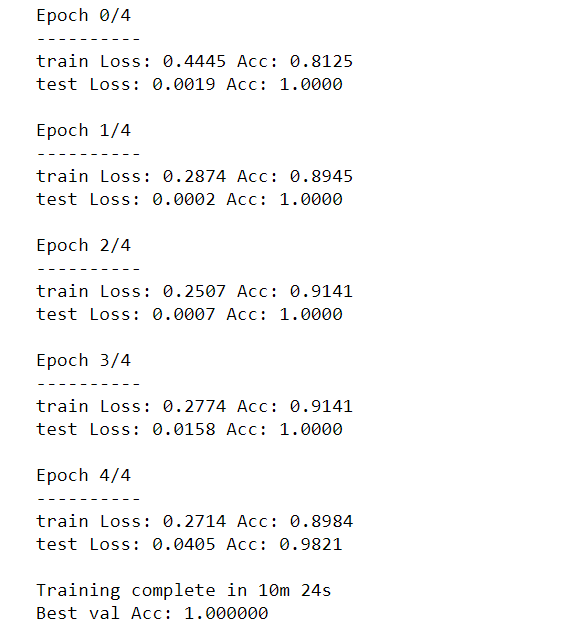
Правда каждая эпоха занимает в разы больше времени. Для более сложных задач, конечно, вам понадобится большее количество эпох. Проверку распознаваемых изображений из исходного туориала, я заменил на слегка адаптированный код, который мы использовали для визуализации результатов распознавания тестовой выборки первой модели.
# Visualization results of analysis test data correct = 0 total = 0 with torch.no_grad(): for data in testloader: images, labels = data outputs = model_ft(images) _, predicted = torch.max(outputs.data, 1) for printdata in list(zip(predicted,labels,outputs)): printclass =[classes[int(printdata[0])],classes[int(printdata[1])]] print('Predict class - {0}, real class - {1}, probability ({2},{3}) - {4}'.format( printclass[0],printclass[1], classes[0], classes [1],printdata[2])) total += labels.size(0) correct += (predicted == labels).sum().item() imshow_resNet18(torchvision.utils.make_grid(images)) #print('GroundTruth: ', ' '.join('%5s' % classes[predicted[j]] for j in range(4))) print('Accuracy of the network on the', dataset_sizes['test'], 'test images: %d %%' % ( 100 * correct / total))
Распозналось – идеально.
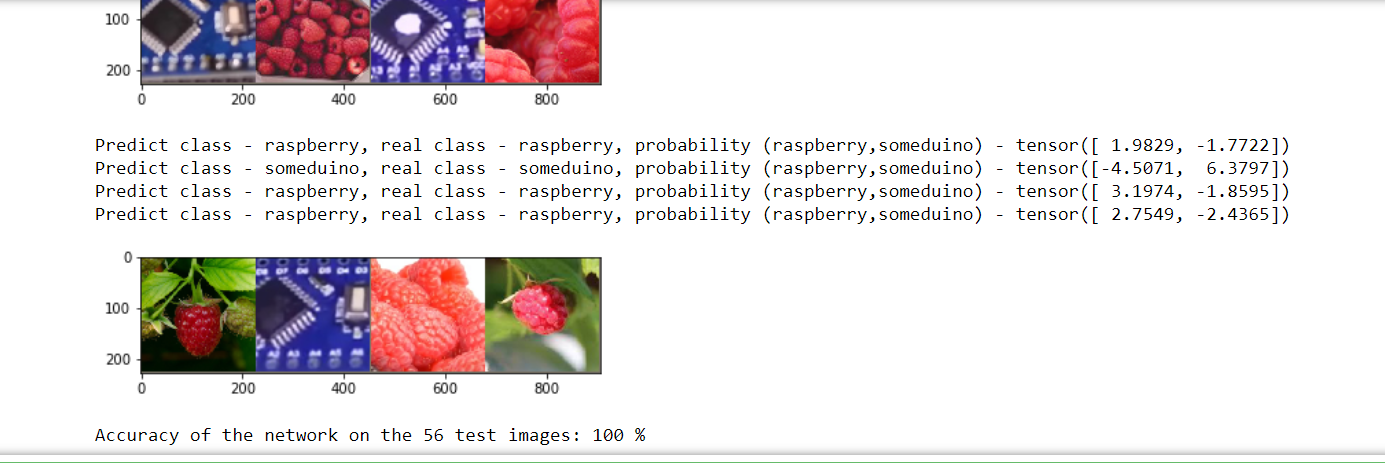
Осталось сохранить.
# Export model to onnx format PATH =os.path.join(dir, "my_resnet18.onnx") dummy_input = Variable(torch.randn(1, 3, 224, 224)) torch.onnx.export(model_ft, dummy_input, PATH)
Часть V: Плоды трудов
Осталось дело за малым, «скормить» сохранённые модели в OpenCV.
Я ориентировался на этот пример , но в принципе вы легко можете написать свой. Для начала импортируем библиотеки.
# import the necessary packages from imutils.video import VideoStream from imutils.video import FPS import numpy as np import imutils import time import cv2 import os
Затем – подготовительный этап.
path=os.path.join(os.path.abspath(os.curdir) , 'my_model.onnx') args_confidence = 0.2 # initialize the list of class labels CLASSES = ['raspberry', 'someduino'] # load our serialized model from disk print("[INFO] loading model...") net = cv2.dnn.readNetFromONNX (path) # initialize the video stream, allow the c #cammera sensor to warmup, # and initialize the FPS counter print("[INFO] starting video stream...") vs = VideoStream(src=0).start() time.sleep(2.0) fps = FPS().start() frame = vs.read() frame = imutils.resize(frame, width=400)
В принципе ничего сложного. Мы указываем, где лежит наша модель, вручную назначаем метки для классификации, загружаем модель и еще инициализируем окошко в котором будет показываться изображение с веб-камеры.
Далее основной цикл, в котором происходит распознавание.
while True: # grab the frame from the threaded video stream and resize it # to have a maximum width of 400 pixels frame = vs.read() frame = imutils.resize(frame, width=400) # grab the frame dimensions and convert it to a blob (h, w) = frame.shape[:2] blob = cv2.dnn.blobFromImage(cv2.resize(frame, (32, 32)),scalefactor=1.0/32 , size=(32, 32), mean= (128,128,128), swapRB=True) cv2.imshow("Cropped image", cv2.resize(frame, (32, 32))) # pass the blob through the network and obtain the detections and # predictions net.setInput(blob) detections = net.forward() print(list(zip(CLASSES,detections[0]))) # loop over the detections # extract the confidence (i.e., probability) associated with # the prediction confidence = abs(detections[0][0]-detections[0][1]) print("confidence = ", confidence) # filter out weak detections by ensuring the `confidence` is # greater than the minimum confidence if (confidence > args_confidence) : class_mark=np.argmax(detections) cv2.putText(frame, CLASSES[class_mark], (30,30),cv2.FONT_HERSHEY_SIMPLEX, 0.6, (242, 230, 220), 2) # show the output frame cv2.imshow("Web camera view", frame) key = cv2.waitKey(1) & 0xFF # if the `q` key was pressed, break from the loop if key == ord("q"): break # update the FPS counter fps.update() # stop the timer and display FPS information fps.stop() # do a bit of cleanup cv2.destroyAllWindows() vs.stop()
Думаю здесь стоит пояснить.
blob = cv2.dnn.blobFromImage(cv2.resize(frame, (32, 32)),scalefactor=1.0/32 , size=(32, 32), mean= (128,128,128), swapRB=True)
Это трансформация картинки в массив данных аналогичная той, что мы делали в блокноте Jupyter. Мы уменьшаем изображение до 32 пикселей, и задаем среднее по RGB каналам (помните у нас было 0.5, 0.5, 0.5?). Масштаб можно задать любой, он будет влиять только на величину чисел в предсказаниях модели, которые мы получаем с помощью detections = net.forward().
Detections представляет собой вектор в котором первое число это вероятность, того что наш объект можно отнести к первому классу (малина), а второе число – соответственно ко второму.
Итак посмотрим, что у нас получается.
Для запуска этого кода я использовал Spider, который входит в комплект Anaconda. Также я установил OpenCV 4-й версии.
Начнем с Ардуино.
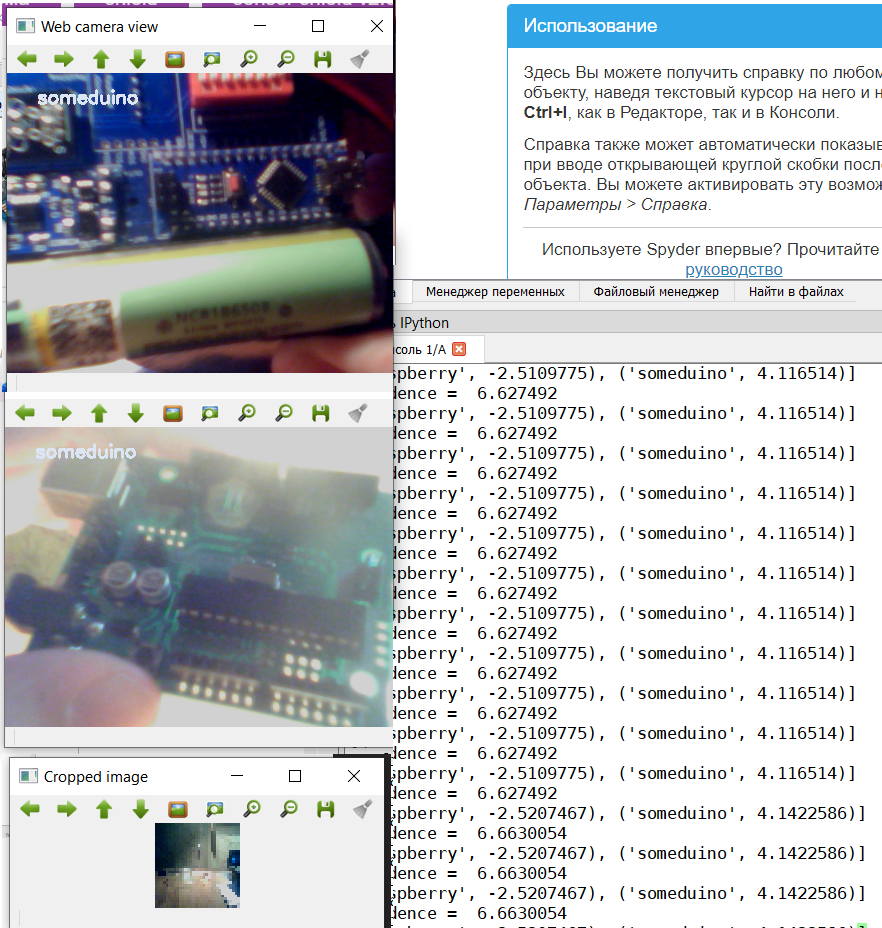
Поскольку в учебной выборке были разные виды Arduino-подобных устройств, то модель распознает и CraftDuino v 1.0. и Arduino Nano, которое мой друг DrZugrik впаял на плату вместе с другими компонентами. Живой малины у меня нет поэтому распознаем фотки с листочка (с экрана смартфона тоже можно).
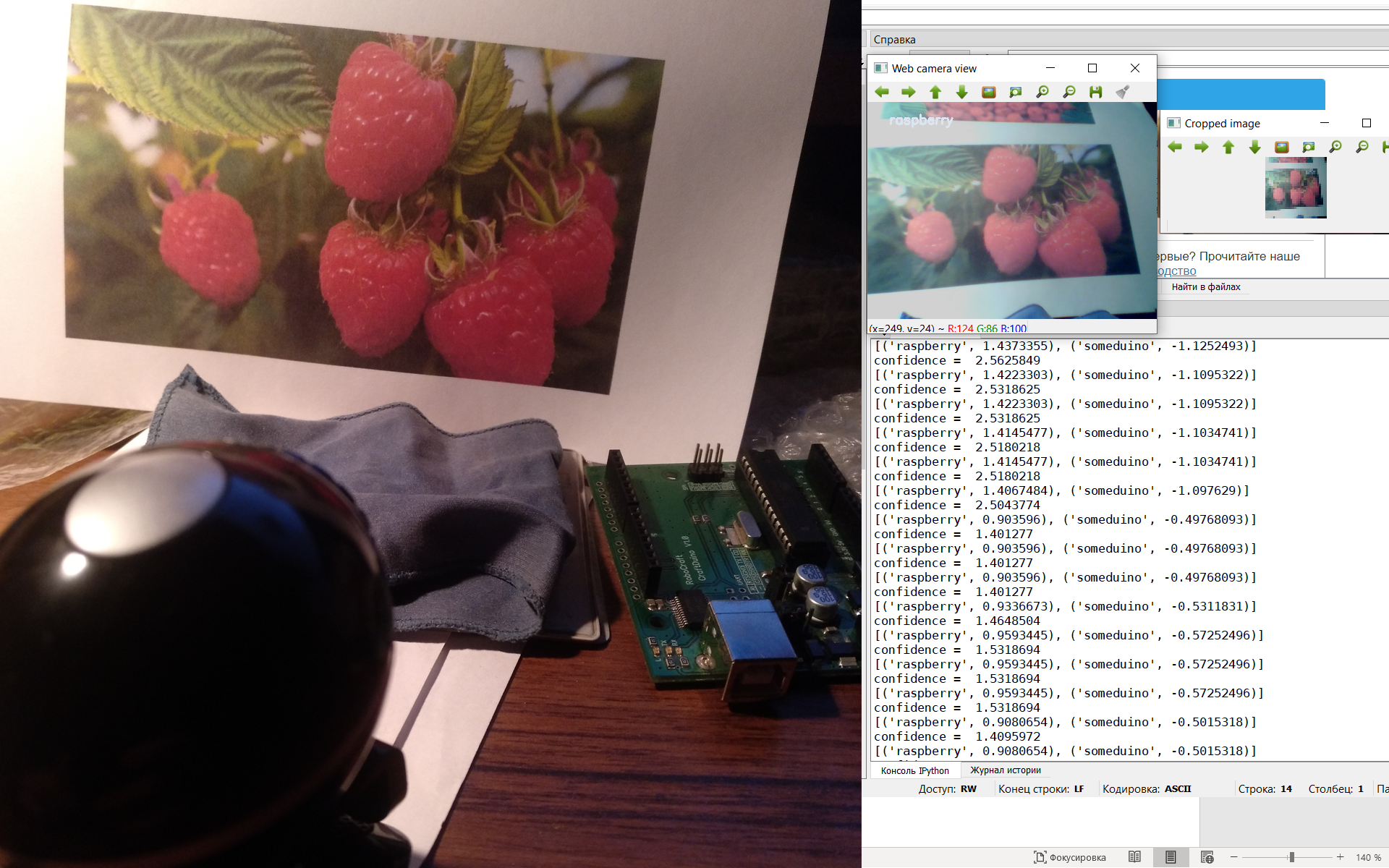
Итак, наша первая модель справилась, давайте посмотрим, как справится вторая. Код для второй модели почти не отличается, кроме параметров преобразования картинки. Поэтому спрячем его под спойлер.
код для модели Resnet18
#based on https://proglib.io/p/real-time-object-detection/ # import the necessary packages from imutils.video import VideoStream from imutils.video import FPS import numpy as np import imutils import time import cv2 import os path=os.path.join(os.path.abspath(os.curdir) , 'my_resnet18.onnx') args_confidence = 0.2 # initialize the list of class labels CLASSES = ['raspberry', 'someduino'] # load our serialized model from disk print("[INFO] loading model...") net = cv2.dnn.readNetFromONNX (path) # initialize the video stream, allow the c #cammera sensor to warmup, # and initialize the FPS counter print("[INFO] starting video stream...") vs = VideoStream(src=0).start() time.sleep(2.0) fps = FPS().start() frame = vs.read() frame = imutils.resize(frame, width=400) # loop over the frames from the video stream while True: # grab the frame from the threaded video stream and resize it # to have a maximum width of 400 pixels frame = vs.read() frame = imutils.resize(frame, width=400) # grab the frame dimensions and convert it to a blob (h, w) = frame.shape[:2] blob = cv2.dnn.blobFromImage(cv2.resize(frame, (224, 224)),scalefactor=1.0/224 , size=(224, 224), mean= (104, 117, 123), swapRB=True) cv2.imshow("Cropped image", cv2.resize(frame, (224, 224))) # pass the blob through the network and obtain the detections and # predictions net.setInput(blob) detections = net.forward() print(list(zip(CLASSES,detections[0]))) # loop over the detections # extract the confidence (i.e., probability) associated with # the prediction confidence = abs(detections[0][0]-detections[0][1]) print(confidence) # filter out weak detections by ensuring the `confidence` is # greater than the minimum confidence if (confidence > args_confidence) : class_mark=np.argmax(detections) cv2.putText(frame, CLASSES[class_mark], (30,30),cv2.FONT_HERSHEY_SIMPLEX, 0.6, (242, 230, 220), 2) # show the output frame cv2.imshow("Web camera view", frame) key = cv2.waitKey(1) & 0xFF # if the `q` key was pressed, break from the loop if key == ord("q"): break # update the FPS counter fps.update() # stop the timer and display FPS information fps.stop() # do a bit of cleanup cv2.destroyAllWindows() vs.stop()
Поверьте мне на слово, что эта модель распознает как минимум не хуже. Поэтому мы приготовим ей задачку по сложнее.
А именно распознать Raspberry pi.
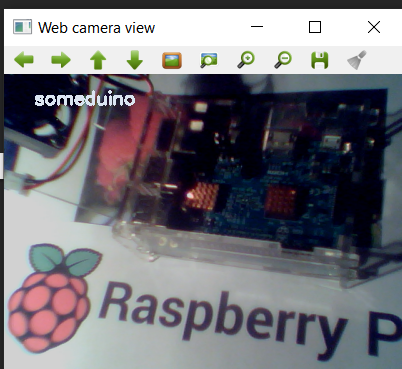
Ну что же, тут все не так однозначно, хотя вполне ожидаемо, ведь «Хоть розой назови ее, хоть нет» не смотря на свое название «Малина» внешне больше похожа на Ардуино. Напоследок.
В данном решении есть один большой недостаток, мы выбрали неправильную модель для распознавания. Поэтому даже если камера смотрит в пустоту, она все равно пытается классифицировать объект либо как малину, либо как контроллер.
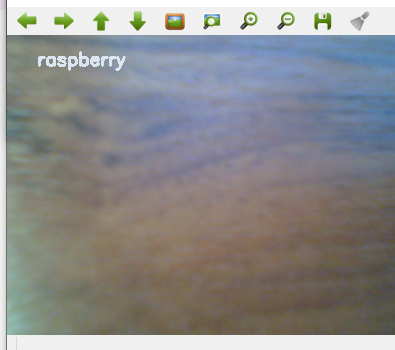
Для того, чтобы распознавать изображения с цветной рамочкой, нам надо не просто использовать модели для классификации, а модели для распознавания объектов на изображении. Но это уже совсем другая история, о которой я напишу несколько позже.
Телеграм: t.me/ainewsline
Источник: habr.com