Теперь Google понимает поисковые запросы лучше, чем когда-либо
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2019-12-09 23:36

Панду Найак, вице-президент Google Поиска
За 15 лет работы над Google Поиском я понял, что человеческое любопытство не знает границ. Ежедневно мы видим миллиарды поисковых запросов, и 15% из них — совершенно новые. Чтобы обрабатывать такие запросы, мы создали новые инструменты для Google Поиска.
Когда люди открывают страницу Google Поиска, они не всегда знают, как лучше сформулировать запрос: иногда они не могут подобрать нужные слова или не помнят, как пишутся те или иные термины. Но ведь мы обращаемся к Поиску как раз для того, чтобы узнать что-то новое, и далеко не всегда у нас есть знания, чтобы точно сформулировать запрос.
Наша задача — понять, что именно вы ищете, и подобрать в сети нужную информацию, независимо от того, как был составлен изначальный запрос. Так как в основе работы Google Поиска — понимание языка, мы годами работаем над улучшением понимания поисковых запросов, но все равно иногда по-прежнему попадаем впросак, особенно со сложными и «разговорными» запросами. Это одна из причин, почему люди часто пишут запросы в виде набора ключевых слов, — пользователи думают, что так нам будет проще их понять.
В последнее время благодаря технологиями машинного обучения наши исследователи достигли больших успехов в области понимания языка, и мы стали намного лучше обрабатывать запросы. Это крупнейший прорыв за последние пять лет и один из самых грандиозных успехов за всю историю Google Поиска.
Применение моделей BERT в Google Поиске
В прошлом году мы в открытом доступе представили технологию предварительного обучения обработке текста на естественном языке (NLP), разработанную на базе нейронных сетей, и назвали ее BERT (Bidirectional Encoder Representations from Transformers). С ее помощью каждый может обучить собственную современную вопросно-ответную систему.
Этот прорыв произошел благодаря изучению трансформеров — моделей, которые обрабатывают слова не как последовательность разрозненных языковых единиц, а учитывают в предложении взаимодействие слов друг с другом. Поэтому модели BERT могут обрабатывать не только отдельные слова, но и понимать контекст, в котором они употребляются. Это особенно важно для понимания истинного смысла поисковых запросов.
Но для решения этой задачи нужны не только новые программы. Нам не хватало и технической составляющей. Некоторые модели, которые можно создать с помощью BERT, настолько сложные, что имеющееся в нашем распоряжении оборудование с ними не справлялось. Поэтому мы впервые стали использовать тензорные процессоры (TPU), с помощью которых можно быстро подобрать для пользователя более актуальную информацию.
Понимание сути запроса
Я увлекся техническими подробностями, но чем вся эта работа может быть полезна нашим пользователям? Обрабатывая стандартные и выделенные описания с помощью моделей BERT, мы намного лучше справляемся с поиском нужной информации. Если говорить о стандартных описаниях, то BERT помогает Google Поиску лучше понимать каждый 10-й англоязычный запрос в США.
В основном Google Поиск станет эффективнее для длинных и разговорных запросов, а также запросов с предлогами. Теперь поисковая система будет лучше понимать контекст и показывать соответствующие результаты, а значит вы сможете использовать более естественные запросы.
Чтобы Google Поиском было удобнее пользоваться, мы используем BERT не только для английского, но и для других языков, в том числе и для русского. Созданные нами системы хороши тем, что они могут применить принципы, которым обучились на одном языке, к другим. Так что мы можем взять модели, обученные на базе английского (который используется в подавляющем большинстве материалов в Интернете), и применить их для других языков.
С этого месяца модели BERT станут доступны и для запросов на русском языке. Возьмем, к примеру, поисковый запрос «Может ли преподаватель выгнать студента с занятия?». Этот запрос, обработанный с применением технологии BERT, наиболее точно отвечает на запрос пользователя. В то же время предыдущие результаты выдачи отвечали на вопрос «Имеет ли преподаватель право не пустить студента на пару?». Казалось бы, запросы похожи, но смысл у них разный.

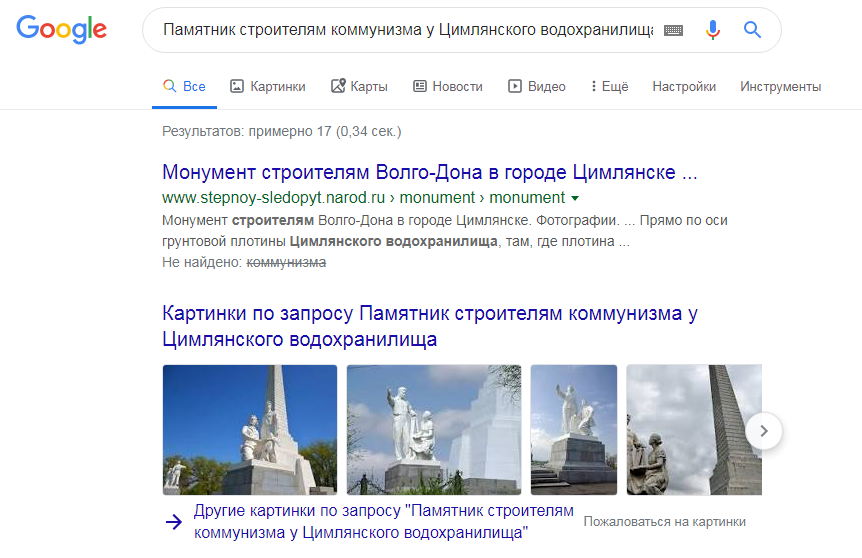
Рассмотрим другой пример: запрос «Памятник строителям коммунизма у Цимлянского водохранилища». Раньше технологии Поиска ориентировались на ключевые слова и выдавали, например, страницу Цимлянской ГЭС на Википедии. BERT помогает выстроить выдачу таким образом, чтобы пользователь получил информацию именно о монументе.
Поиск — это постоянное совершенствование
Понимание языка — это актуальная задача, которая мотивирует нас постоянно улучшать Google Поиск. Мы развиваемся, стараясь понять суть каждого отправленного запроса и найти ресурсы, которые смогут вам помочь.
Телеграм: t.me/ainewsline
Источник: russia.googleblog.com
Комментарии:
Только что задал Гуглу вопрос: Почему я не умею выстраивать здоровые отношения?
Гугл как-то толком ничего и не ответил, только кучу каких-то ссылок надавал...