
Зачем?
Тональность, или простыми словами хорошо/плохо — естественная характеристика слов. Естественная для человека и его восприятия, но не для понимания компьютером. Язык устроен таким образом, что в нём присутствует симметрия относительно полярности слов и отделить хорошие слова от плохих, не прибегая к внешней разметке, не представляется возможным. Собственно изначально задача создания тонального словаря возникла из потребности кластеризовать получаемые автоматически алгоритмом списки слов в соответствии с их полярностью.
Конечно, тональность является лишь одним из аспектов значения слова и реальное понимание сентимента требует полного семантического анализа, понимание ролей в конкретной ситуации и знание положения, занимаемого наблюдателем. Так, например, «снижение цены акций» для разных сторон может иметь различную тональность, а «издержки выросли» и «прибыль выросла» иметь разнонаправленную полярность, хотя в обоих словосочетаниях употребляется глагол расти, имеющий скорее положительную оценку (согласно нашему датасету).
Существует и довольно обширный спектр причин, по которым мы относим то или иное слово к конкретной тональности. Иногда это наши непосредственные ощущения — радость и тоска; иногда это качества человека — профессионализм и беспечность: а иногда такие понятия как образование или предпринимательство, связанные со сложными социальными институтами и дающие выгоду в долгосрочной перспективе. И оценка таких слов сильно связана с культурой и общественным договором. А, соответственно, может не иметь общепризнанной и универсальной оценки.
Тем не менее язык и коммуникация не могли бы существовать, если бы системы координат разных людей в рамках одной культуры не имели бы ничего общего между собой. А поэтому для достаточно больших групп слов их оценочная составляющая более-менее согласована.
Каким образом?
Существует два основных способа сбора большого объёма лингвистических данных — привлечение экспертов и опрос людей (или более современная версия последнего — краудсорсинг). Не будем повторяться об очевидных различиях этих подходов, а лучше уделим внимание тем из них, которые оказывают непосредственное влияние на свойства получаемого датасета.
Экспертная разметка подразумевает чёткую ориентацию на будущее применение, а соответственно оговаривает способ принятия решения в ситуации неоднозначности, диктуемый данным применением. Для конечного датасета это означает:
- фиксацию предметной области;
- чёткое определение позиции наблюдателя.
Так, если эксперт составляет тональный словарь для анализа новостей, ориентированных на массовую аудиторию, то он занимает позицию обобщённого читателя и принимает на себя негласные соглашения между СМИ и читателями. Скажем «понижение стоимости» в таких установках будет иметь положительную оценку, а «рост тарифов» — отрицательную (согласно датасету РуСентиЛекс-2017).
Краудсорсинг лишён возможности задания подобных рамок и вряд ли является оптимальным средством для решения узкоспециализированных прикладных задач. Но он позволяет захватить другой важный аспект оценки тональности — согласованность между отвечающими. Какие-то слова будут однозначно оценены как положительные или отрицательные; какие-то разделят оценку между нейтральным и полярным вариантами; а небольшая группа слов покажет выраженную рассогласованность оценок.
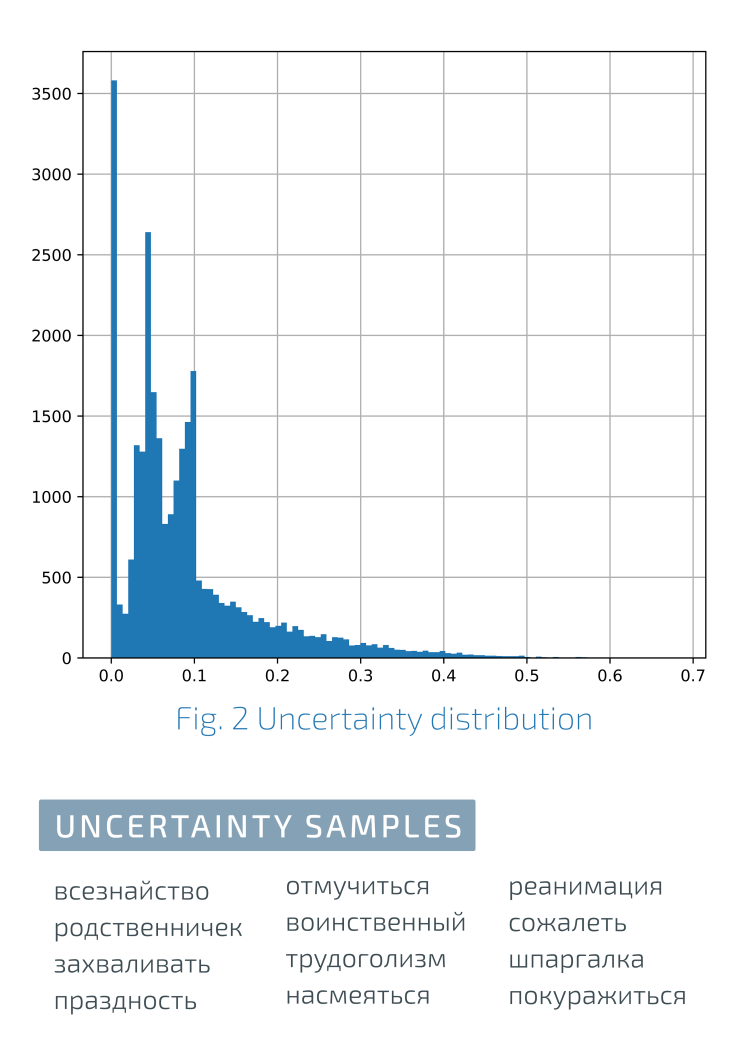
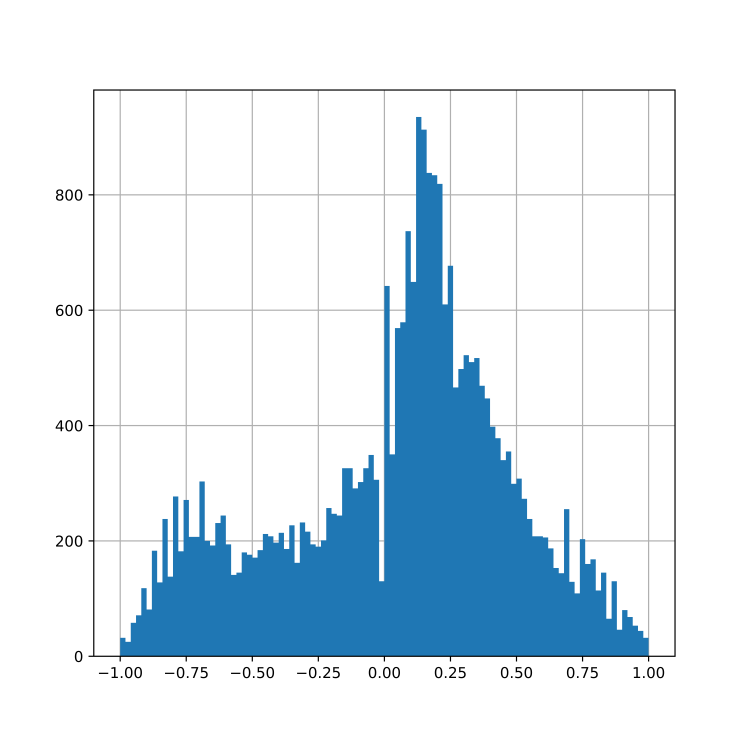
Структура датасета
Структура датасета довольно простая: это тональный словарь, ставящий в соответствие словам их оценку в диапазоне от -1 (предельная отрицательная оценка) до +1 (предельная положительная оценка). Для удобства указывается человекопонятный тег из набора «положительное», «нейтральное», «отрицательное» рассчитанный с использованием пороговых значений.
Примеры положительных, нейтральных и отрицательных слов из датасета
- положительные: надёжный, помириться, доброта, помилование, добросовестный, окрыляться, фотогеничный, прибыль, воспитанность, воссоединение, воодушевить, доверие, восторг, ребятушки, преобразиться, оздоровительный, новоселье, уют, вразумительный, учёность, волонтёрский;
- нейтральные: аббревиатура, причислить, прилеплять, туника, многогранник, касание, мебельный, житель, кликнуть, таять, словоупотребление, перешагнуть, автодорожный, ингредиент, сдуть, подчеркнуть, эмблема, ложиться, длиннорукий, семёрка, ничья;
- отрицательные: прогульщик, зажраться, проболтаться, заложник, жлоб, заносчивый, фальшивый, загрязнённость, завистник, придушить, замёрзнуть, протранжирить, жульнический, деградировать, зависимый, загрызть, простуда, придраться, напугаться, грабитель, неуч;
Дальнейшие планы
Разметка сентимента — одна из частных задач в рамках исследования семантической системы языка. Как мы уже отмечали выше, полезность представленного набора данных напрямую зависит от возможности связать представленные в нём значения полярности с другой семантической информацией. С классами слов, например. Мы начали эту работу и планируем развивать её в дальнейшем.
Также важным направлением исследования является стремление понять причину окрашивания тех или иных слов, разведение слов, связанных с чувствами, эмоциями и непосредственной оценкой и тех слов, где описываемый ими концепт или ситуация сулят отложенную выгоду или потерю. А следовательно такие слова больше подвержены культурному и социальному влиянию.
Также планируется расширить разметку словосочетаниями, включая устойчивые выражения и фразеологизмы. Но здесь речь уже идёт о совсем других объёмах лексики, поэтому общая задача понять, как сентимент работает на более общем уровне (подробнее под спойлером).
При внимательном рассмотрении становится понятно, что язык оперирует компактным относительно количества слов и их сочетаний набором концептов, каждый из которых может выражаться более чем одним способом. Это наблюдение нашло подробное отражение в работах отечественных лингвистов и в созданной ими модели «Смысл — Текст».
Так например «снижение цен», «падение цен», «цены рухнули», «цены снизились» — это разные способы описать схожий процесс, но выраженный различными языковыми средствами. При этом в схожих контекстах можно встретить и другие концепты, имеющие количественное выражение — «падение уровня доверия», «рост уровня доходов» и т.д. В каждом случае достаточно понимать соответствие выше/ниже — хорошо/плохо (уровень знаний и мире) и какими лексическими средствами выражается движение в заданную сторону (уровень языка).
Обратная связь и распространение датасета
Будем рады любой обратной связи в комментариях — от критики работы и выбранных нами подходов до ссылок на интересные исследования и статьи по теме.
Если у вас есть знакомые или коллеги, которым может быть интересен опубликованный датасет, перешлите им ссылку на статью или репозиторий, чтобы помочь в распространении открытых данных.
Ссылка на датасет и лицензия
Датасет: открытый тональный словарь русского языка Объём датасета составляет 28197 слов.
Датасет распространяется по лицензии CC BY-NC-SA 4.0.