
Поговорим о Natural Language Processing
Итак, анализ текстов на естественных языках, или Natural Language Processing, — это широкий план задач, которые можно разделить на 3 части. Natural Language Understanding — понимание,Natural Language Generation — генерация, все это касается текстов. И, наконец, устная речь — распознавание и синтез. В статье мы будем подробно говорить именно о понимании текста. Natural Language Understanding имеет самостоятельную ценность, когда мы делаем систему, которая автоматически анализирует текстовый контент, извлекает факты об интересующих нас организациях, продуктах, людях.
Для понимания текста, прежде всего, нужно выделить семантику: определить, что написано, класс подписей, пользовательское намерение, интонацию, тональность и, наконец, о чем вообще идет речь в тексте, о каких объектах реального мира, людях, организациях, местах, данных. Задача выделения объектов называется распознаванием именованных сущностей (Natural Entity Recognition), определения того, что хочет человек, —классификацией пользовательских намерений, или Classification Intent. И, наконец, распознавание тональностей — это SentimentАnalysis. Задачи достаточно известные, подходы к их решению существуют давно.
Распознавание именованных сущностей. Есть некий текст, сгенерированный клиентом, из которого нужно выделить именованные сущности (NamedEntities). Прежде всего, это имена людей, названия организаций и геолокаций. Также есть социальные сущности: более подробны еадреса, телефоны, геополитические сущности.
Когда мы общаемся с чат-ботом, ему важно знать, чего мы от него хотим. Понимание пользовательских намерений позволит определить место в графе диалога и наиболее адекватную реакцию чат-бота. Интенты (пользовательские намерения) могут выражаться по-разному. Вот фрагменты реальных чатов с клиентами бота: «Симку, говорю, заблокируйте!» или«Могу я отключить на время номер?». Казалось бы, классификацию интентов можно делать по ключевым словам. Но, как видите, даже эти два простых примера, относящиеся к одному и тому же интенту — блокировка сим-карты — вообще не содержат пересекающихся слов. Поэтому лучше всего сделать систему на основе машинного обучения, которая бы сама классифицировала тексты, выстроить и настраивать чат-бот на новый набор классов интентов в зависимости от того, где будут этот чат-бот эксплуатировать.
И, наконец, классическая задача анализа тональности. В определенном смысле здесь все проще, чем в классификации интентов. Если для каждого чат-бота набор интентов свой, в зависимости от того, общается он на тему телекоммуникационных провайдеров, заказа пиццы или банковских вопросов, то в области анализа тональности набор классов тональности стандартный: 3 (нейтральная эмоция) либо 2 класс (негатив или позитив). Однако сама задача выделения тональности более сложная, поскольку часто люди пишут саркастично или неявно выражают эмоцию.
Для всех этих задач эффективнее всего строить модель, которая обучается с учителем. Человек — не раб своих вещей. Соответственно, если мы используем человека для разметки датасета, он может выделить, какие эмоции в тексте упомянуты, к каким классам отнести те или иные пользовательские тексты, к какой тональности — запросы к оператору call-центра. После этого можно придумать признаковое описание и на его основе получать вектора текстов либо слов текста и дальше обучать систему. Тема классическая, проверенная. Она прекрасно работает, однако не лишена проблем.
Как готовить данные
Для подготовки различных текстовых корпусов существует множество инструментариев. На картинке ниже я привел скриншот одного из наиболее популярных инструментариев —bratannotationtool. Мы можем загрузить в него набор текстов, а сами учителя с помощью мыши выделяют слова из текста: например, название организации именованной сущности класса org, именованная сущность класса money. Интерфейс достаточно удобный, наглядный, тем не менее различать большие объемы текстов здесь очень долго и утомительно.

Нейронная сеть за счет своей многослойной структуры является одновременно и классификатором, и иллюстратором признаков. Младшие слои извлекают элементарные особенности изображения: черточки, графические примитивы. И чем ближе к выходу из нейронной сети, тем более высокоуровневые, абстрактные элементы изображения извлекаются. Если мы обучим сетьраспознаванию картинок с ImageNet (сайтом с более чем 14 миллионами различных изображений, на которых можно построить очень крутую глубокую нейронную сеть), потом уберем несколько последних слоев, «отрежем» ейголову и оставим только «тело» — начальные слои, то знания, аккумулированные в виде начальных слоев, уже позволяют получать элементарные ответные изображения. А поскольку любой слой состоит из элементарных, мы решаем задачу обучения нейросети не с нуля. Берем обычное «тело» для любой задачи в этой же области, например, в компьютерном зрении, пришиваем новую «голову» и дообучаем уже всю ее структуру вместе.
Революция ELMo
Однако возникает вопрос: как быть с анализом текстов? Ведь тексты — разные для каждого языка, и делать такую гигантскую размеченную коллекцию проблематично.
Начиная с 2017 года в области компьютерной лингвистики и анализа текста стала происходить своего рода революция. Эффективные методы TransferLearning пришли и сюда. С применением двух моделей: ELMo (EmbeddingsfromLanguageModels) и BERT (BidirectionalEncoderRepresentationsfromTransformers) TransferLearning в области лингвистики вышел на абсолютно новый уровень.
Специально так получилось или нет, неизвестно, но эти аббревиатуры созвучны именам персонажей из сериала «Улица Сезам». ELMo исторически стала первой моделью. Она позволяет учитывать глубокую семантику в тексте. Распознавание именованных сущностей, классификация текста, анализ тональности —все эти задачи основаны на семантике текста и извлечении смысла. Таким образом, мы учим глубокую нейронную сеть языковому моделированию, поиску зависимостей в текстах.
Например, картинка ниже иллюстрирует, как мы можем решать анафору: «Программист Вася любит пиво. Каждый вечер после работы он заходит в “Джонатан” и пропускает бокал-другой». Программист Вася — это человек, который любит пиво. Каждый вечер после работы он заходит в «Джонатан» и пропускает бокал-другой. Он — это кто? Он — это вечер, он — это пиво? Пиво — это оно. Он — это программист Вася? Скорее всего, программист Вася.
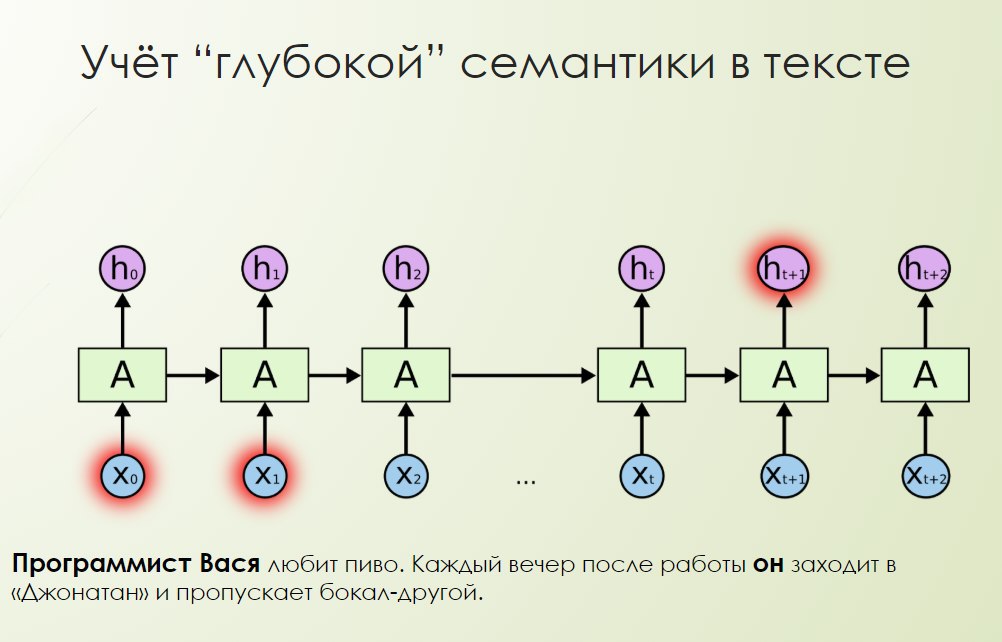
Получается, что не нужно долго делать разметку для каждого языка— можно генерировать языковые модели для любых языков очень легко с использованием компьютера.После обучения модели в режиме эксплуатации подается на вход текст, ипри обработке каждого слова в тексте модель пытается спрогнозировать следующее слово. Берутся скрытые состояния на всех уровнях нейронной сети, обратной рекуррентной нейронной сети, и таким образом получается векторное представление этого слова в тексте. Так работает ELMo.
При forwardlanguagemodel и backwardlanguagemodel подается цепочка слов, модель обучается, и когда нужно получить embedding (например, слово stick в этом тексте —Let'sstickto), берется состояние рекуррентной нейронной сети на первом слове, на втором и на этот момент времени. Обратная модель — на первом, на втором, и получается большое векторное представление. Преимущество таких моделей в том, что будет учитываться контекст при генерации векторного представления слов: embedding генерируется с учетом окружения других слов.
ELMoучитывает глубокую семантику, решает проблему омонимии, однако и эта модель не лишена недостатков. Рекуррентные нейронные сети, с одной стороны, могут учитывать легкие зависимости, а с другой— они очень тяжело обучаются и не всегда могут хорошо анализировать длинные последовательности— так или иначе, проблема с забыванием у них есть.
BERT
Скажем решительное «нет» рекуррентным нейронным сетям и используем другую архитектуру —BERT. Вместо рекуррентных нейронных сетей будем использовать модель Transformer, основанную не на обратной связи, а на так называемом механизме внимания. При чтении текста невольно выделяются ключевые слова, которые несут наибольшую семантическую нагруженность.
Можно локализовать какие-то объекты на изображении либо в тексте. Механизм внимания присутствует в нейронных сетях и основан примерно на том же принципе. Определенный слой взвешивает каждый элемент последовательности, затем — каждую последовательность в каждый момент времени. Получается, что можно видеть, какие элементы последовательности на данном шаге наиболее или наименее важны. В Transformer используется специальный вариант внимания — Multi-HeadAttention. Более того, Transformer целиком и полностью использует не целые слова, а квазиморфемы— BPE, потому что это оказалось более эффективно и удобно. В чем смысл? Выделяются наиболее устойчивые сочетания символов в тексте и создаются слова из символов. Проблема словаря очень остро стоит для языков типа русского, у которых есть множество словоформ: «мама», «мамочка», «мамуля», «маме» — падежи, уменьшительно-ласкательные формы и пр.
Если хранить словарь всех словоформ, это выльется в несколько миллионов, что, конечно, очень неудобно.В итоге было найдено компромиссное решение. Выделяются наиболее устойчивые подслова в слове статистически, самые частотные биграммы (повторение символов) и заменяются на спецсимволы BPE. В итоге получается словарь BPE.
Рассмотрим пример BPE— текст с биографией Ивана Павлова: «Весной 1890 года Варшавский и Томский университеты избирают его профессором». Вообще слова — это «весной», «1890», «Варшавский», но мы выделяем фрагменты слов – «В##есной»; «В## ар##ша##вский» и так далее. Таким образом можно эффективно сократить размер словаря до нескольких десятков тысяч BPE, более того, можно делать системы, одновременно работающие с несколькими языками. Забегая вперед, скажу, что один из вариантов был обучен на 105 языках, и словарь BERT составил чуть более 100 тысяч BPE.
Чему обучаем BERT?
Предположим, есть некий текст: «Let’s stick to improvisation in this skit». Начинается он с квазитокена, который означает начало, и в каждом тексте случайным образом 10–15% слов заменяются на mask – спецсимвол. Это входной сигнал. То есть мы заставляем BERT учиться восстанавливать пропущенные слова, которые замаскированы под словом mask, —какие слова должны быть в тексте, в предложении, в абзаце по контексту.
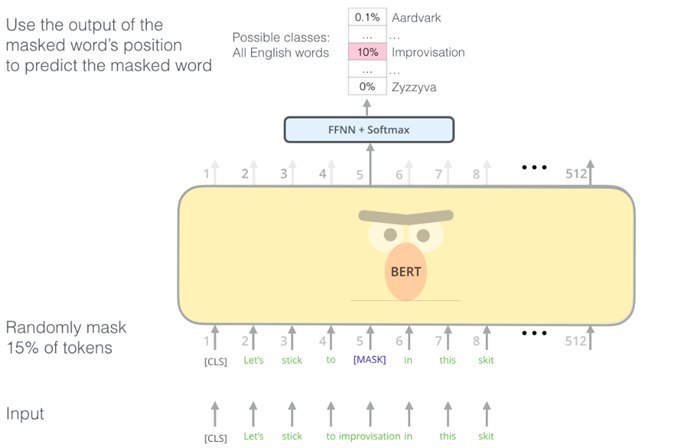
Первые результаты в случае и с BERT, и с ELMo были получены для английского языка, и они действительно были впечатляющими. Однако что делать, если мы хотим анализировать русский язык? Первый вариант — это Multilingual BERT, подготовленный специалистами Google, обученный на текстах из «Википедии». «Википедия» — это не просто энциклопедия, а еще и источник текстов на многих языках. В результате получилсяMultilingual BERT со 110 миллионами параметров. Более подробное описание — по ссылке. Предобученная модель есть на tfhub. Ее очень просто использовать и генерировать фичи. Multilingual BERT — это хорошо, но есть BERT и локализованные. В частности, для русского языка можно взять Multilingual BERT и адаптировать его именно для русских текстов. ВiPavlovсейчас ведутся такие работы, и первые результаты уже получены. BERT быладаптирован на новостных текстах на русском языке, и получился более адаптированным для нашего языка. Его можно скачать по ссылке в рамках проекта iPavlov и использовать для решения разных задач.
DeepNER
Проведя ряд экспериментов, я решил сделать объект, который можно было бы не только использовать для исследовательских целей, а применять на практике, решая конкретные задачи распознавания именованных сущностей. Я создал Deep NER — глубокуюнейронную сеть, которая обучается на основе transferlearning, в качестве основы можно указывать объект класса ELMoили BERT. Deep NER — это своего рода депозитарий.С максимально простым интерфейсом.
Заключительно о transferlearning
В первую очередь стоит сказать о том, что перенос обучения позволяет эффективно решать различные задачи, особенно когда нет возможности создавать большие аналитические центры. Второй момент: при тонкой и глубокой семантике в текстах сложные модели лидируют, по сравнению с простыми, с большим отрывом. И, наконец, NER и классификацию текстов для русского языка теперь можно сделать проще, потому что есть модели и наработанная база, которую можно использовать для своих задач и получать эффективные, работающие, полезные решения.