Компания Mozilla представила движок распознавания речи DeepSpeech 0.6
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2019-12-08 13:46
Представлен выпуск развиваемого компанией Mozilla движка распознавания речи DeepSpeech 0.6, который реализует одноимённую архитектуру распознавания речи, предложенную исследователями из компании Baidu. Реализация написана на языке Python с использованием платформы машинного обучения TensorFlow и распространяется под свободной лицензией MPL 2.0. Поддерживается работа в Linux, Android, macOS и Windows. Производительности достаточно для использования движка на платах LePotato, Raspberry Pi 3 и Raspberry Pi 4.
В наборе также предлагаются обученные модели, примеры звуковых файлов и инструментарий для распознавания из командной строки. Для встраивания функции распознавания речи в свои программы предложены готовые к применению модули для Python, NodeJS, C++ и .NET (сторонними разработчиками отдельно подготовлены модули для Rust и Go). Готовая модель поставляется только для английского языка, но для других языков по прилагаемой инструкции можно обучить систему самостоятельно, используя голосовые данные, собранные проектом Common Voice.
DeepSpeech значительно проще традиционных систем и при этом обеспечивает более высокое качество распознавания при наличии постороннего шума. В разработке не используются традиционные акустические модели и концепция фонем, вместо них применяется хорошо оптимизированная система машинного обучения на основе нейронной сети, которая позволяет обойтись без разработки отдельных компонентов для моделирования различных отклонений, таких как шум, эхо и особенности речи.
Обратной стороной подобного подхода является то, что для получения качественного распознавания и обучения нейронной сети движок DeepSpeech требует большого объёма разнородных данных, надиктованных в реальных условиях разными голосами и при наличии естественных шумов. Сбором подобных данных занимается созданный в Mozilla проект Common Voice, предоставляющий проверенный набор данных с 780 часами на английском языке, 325 на немецком, 173 на французском и 27 часами на русском.
Конечной целью проекта Common Voice является накопление 10 тысяч часов c записями различного произношения типовых фраз человеческой речи, что позволит достичь приемлемого уровня ошибок при распознавании. В текущем виде участниками проекта уже надиктовано в сумме 4.3 тысячи часов, из которых 3.5 тысячи прошли проверку. При обучении итоговой модели английского языка для DeepSpeech использовано 3816 часов речи, кроме Common Voice охватывающей данные от проектов LibriSpeech, Fisher и Switchboard, а также включающей около 1700 часов транскрибированных записей радиошоу.
При использовании предлагаемой для загрузки готовой модели английского языка уровень ошибок распознавания в DeepSpeech составляет 7.5% при оценке тестовым набором LibriSpeech. Для сравнения, уровень ошибок при распознавании человеком оценивается в 5.83%.
DeepSpeech состоит из двух подсистем - акустической модели и декодировщика. Акустическая модель использует методы глубинного машинного обучения для вычисления вероятности наличия определённых символов в подаваемом на вход звуке. Декодировщик применяет алгоритм лучевого поиска для преобразования данных о вероятности символов в текстовое представление.
Основные новшества DeepSpeech 0.6 (ветка 0.6 не совместима с прошлыми выпусками и требует обновления кода и моделей):
- Предложен новый потоковый декодировщик, обеспечивающий более высокую отзывчивость и не зависящий от размера обрабатываемых звуковых данных. В итоге, в новой версии DeepSpeech удалось снизить задержку на распознавание до 260 мс, что на 73% быстрее, чем раньше, и позволяет применять DeepSpeech в решениях для распознавания речи на лету.
- Внесены изменения в API и проведена работа по унификации имён функций. Добавлены функции для получения дополнительных метаданных о синхронизации, позволяющие не просто получать на выходе текстовое представление, но и отслеживать привязку отдельных символов и предложений к позиции в звуковом потоке.
- В инструментарий для обучения модули добавлена поддержка использования библиотеки CuDNN для оптимизации работы с рекуррентными нейронными сетями (RNN), что позволило добиться существенного (примерно в два раза) увеличения производительности обучения модели, но потребовало внесения в код изменений, нарушающих совместимость с моделями, подготовленными ранее.
- Минимальные требования к версии TensorFlow подняты с 1.13.1 до 1.14.0. Добавлена поддержка легковесной редакции TensorFlow Lite, при использовании которой размер пакета DeepSpeech уменьшен с 98 MB до 3.7 MB. Для использования на встраиваемых и мобильных устойствах с 188 MB до 47 MB также сокращён размер упакованного файла с моделью (для сжатия использован метод квантования после завершения обучения модели).
- Языковая модель переведена на другой формат структур данных, позволяющий выполнять маппинг файлов в память при загрузке. Поддержка старого формата прекращена.
- Изменён режим загрузки файла с языковой моделью, что позволило снизить потребление памяти и уменьшить задержки при обработке первого запроса после создания модели. В процессе работы DeepSpeech теперь потребляет в 22 раза меньше памяти и запускается в 500 раз быстрее.
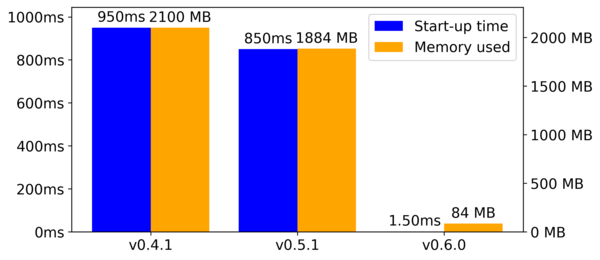
- Проведена фильтрация редких слов в языковой модели. Общее число слов сокращено до 500 тысяч самых популярных слов, встречающихся в тексте, использованном при тренировке модели. Проведённая чистка позволила снизить размер языковой модели с 1800МБ до 900МБ, практически не повлияв на показатели уровня ошибок распознавания.
- Добавлена поддержка различных техник создания дополнительных вариаций (augmentation) звуковых данных, используемых при обучении (например, добавление к набору вариантов, в которые внесены искажения или шумы).
- Добавлена библиотека с биндингами для интеграции с приложениями на базе платформы .NET.
- Переработана документация, которая теперь собрана на отдельном сайте deepspeech.readthedocs.io.

Телеграм: t.me/ainewsline
Источник: www.opennet.ru