Как transfer learning работает для задач с медицинскими снимками
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2019-12-09 13:56
искусственный интеллект в медицине, реализация нейронной сети

Transfer learning — это метод обучения нейросетей, когда знания нейросети, которая была обучена на одной задаче, переносятся на другую задачу. Такой двухступенчатый метод нашел широкое применение в задачах компьютерного зрения на медицинских снимках. Исследователи в Google AI оценили вклад transfer learning в решение медицинских задач. По результатам, модели со случайно инициализированными весами работают так же, как предобученные на ImageNet модели.
Нейросети применяются к различным сферам. В transfer learning нейросеть обучается в два этапа:
- Предобучение, где сеть обучается на большом датасете с разнообразием классов, как ImageNet;
- Fine-tuning, когда предобученная модель дообучается на данных целевой задачи
Предобучение позволяет нейросети использовать знания, которые были выучены на первом этапе, для решения необходимой задачи.
В контексте transfer learning стандартные архитектуры, которые были разработаны для ImageNet, с весами дообучаются на медицинских задачах. Медицинские задачи в компьютерном зрении варьируются от анализа снимков рентгенов груди до распознавания глазных инфекций. Несмотря на широкое использование этого метода на медицинских данных, ранее не исследовали эффект transfer learning подхода.
Исследователи проанализировали и оценили скрытые представления нейросетей для нескольких задач из медицинской сферы.
Оценка работы предобученных моделей
На первом этапе исследователи изучили влияние предобучения модели на качество ее предсказаний. Для этого они сравнили модели с случайно проинициализированными весами и предобученными на ImageNet весами. В качестве задач для тестирования выбрали диагностирование сахарного диабета и распознавание 5 болезней по рентгеновским снимкам груди. Модели, которые тестировали, включали ResNet50, Inception-v3 и простые сверточные нейросети с 4 или 5 слоями convolution-batchnorm-ReLU.
По результатам сравнения:
- Предобучение незначительно влияет на качество предсказаний нейросети для медицинских задач;
- Модели меньшего размера выдают схожие результаты со стандарными ImageNet архитектурами;
- Из-за того, что медицинские задачи меньше по размеру, чем ImageNet, для крупных архитектур с большим количеством параметров предобучение может вредить качеству предсказаний на медицинской задаче
Анализ скрытых представлений
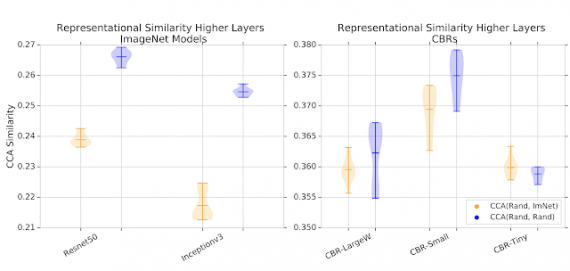
Затем исследователи проверили, как различаются признаки, которые выучивают случайно проинициализированные и предобученные модели. Для этого они сравнили скрытые представления из моделей. Чтобы сравнение было валидным, исследователи использовали singular vector canonical correlation analysis (SVCCA). SVCCA позволяет посчитать метрику схожести для скрытых представлений из разных моделей.
Ниже видно, что для больших моделей (ResNet-50 и Inception-v3) скрытые представления случайно инициализированных моделей схожи сильнее, чем предобученные представления.
Работу представили на NeurIPS 2019.
Телеграм: t.me/ainewsline
Источник: neurohive.io