Нейросети выросли от состояния академической диковинки до массивной индустрии

Специалисты по информатике экспериментируют с НС с 1950-х годов. Однако основы сегодняшней обширной индустрии ГО заложили два крупных прорыва – один произошёл в 1986 году, второй – в 2012. Прорыв 2012 года – революция ГО – была связана с открытием того, что использование НС с большим количеством слоёв позволит нам значительно улучшить их эффективность. Открытию способствовали растущие объёмы как данных, так и вычислительных мощностей.
В данной статье мы введём вас в мир НС. Мы объясним, что такое НС, как они работают и откуда взялись. И мы изучим, почему– несмотря на многие десятилетия предыдущих исследований – НС стали чем-то реально полезным только в 2012 году.
Нейросети появились ещё в 1950-х

Идея НС довольно старая – по крайней мере, по стандартам информатики. Ещё в 1957 году Фрэнк Розенблатт из Корнеллского университета опубликовал отчёт с описанием ранней концепции НС под названием перцептрон. В 1958 году при поддержке ВМФ США он создал примитивную систему, способную анализировать изображение 20х20 пикселей и распознавать простейшие геометрические фигуры. Основной целью Розенблатта было не создание практической системы классификации изображений. Он пытался понять, как работает человеческий мозг, создавая вычислительные системы, организованные по его подобию. Однако эта концепция вызвала чрезмерный энтузиазм третьих лиц.
«Сегодня ВМФ США раскрыл миру зародыш электронного компьютера, который, как ожидается, сможет ходить, говорить, видеть, писать, воспроизводить себя и осознавать своё существование», — писали в The New York Times. По сути, каждый нейрон в НС представляет собой просто математическую функцию. Каждый нейрон высчитывает взвешенную сумму входных данных – чем больше вес входа, тем сильнее эти входные данные влияют на выходные данные нейрона. Затем взвешенная сумма скармливается нелинейной функции «активации» – на этом шаге НС способны моделировать сложные нелинейные явления.
Способности ранних перцептронов, с которыми экспериментировал Розенблатт – и НС в общем – проистекают из их возможности «обучаться» на примерах. НС обучают через подстройку входных весов нейронов на основе результатов работы сети с входными данными, выбранными для примера. Если сеть правильно классифицирует изображение, веса, вносящие свой вклад в правильный ответ, увеличиваются, а другие уменьшаются. Если сеть ошибается, веса подстраиваются в другом направлении.
Такая процедура позволяла ранним НС «обучаться» способом, немного напоминающим поведение нервной системы человека. Шумиха вокруг этого подхода не умолкала в 1960-е. Однако затем влиятельная книга 1969 года за авторством специалистов по информатике Марвина Минского и Сеймура Паперта показала, что у этих ранних НС есть значительные ограничения. У ранних НС Розенблатта было всего один-два обучаемых слоя. Минский и Паперт показали, что подобные НС математически неспособны моделировать сложные явления реального мира.
В принципе, более глубокие НС были более способными. Однако такие НС перенапрягли бы те жалкие вычислительные ресурсы, что были у компьютеров в те времена. Простейшие алгоритмы поиска восхождением к вершине, использовавшиеся в первых НС, не масштабировались для более глубоких НС. В итоге НС растеряли всю поддержку в 1970-х и начале 1980-х – это была часть эры «зимы ИИ».
Прорывной алгоритм

Удача вновь повернулась лицом к НС благодаря знаменитой работе 1986 года, введшей в обиход концепцию обратного распространения – практический метод обучения НС. Допустим, вы работаете программистом в воображаемой компании, производящей ПО, и вам дали поручение сделать приложение, определяющее, есть ли на изображении хот-дог. Вы начинаете работу со случайным образом инициализированной НС, принимающей на вход изображение, и выдающей на выход значение от 0 до 1 – где 1 означает «хот-дог», а 0 означает «не хот-дог».
Для обучения сети вы набираете тысячи изображений, под каждой из которых есть метка, обозначающая, есть ли на этом изображении хот-дог. Вы скармливаете ей первое изображение – и хот-дог на нём есть – в нейросеть. Она выдаёт выходное значение в 0,07, что означает «хот-дога нет». Это неправильный ответ; сеть должна была выдать ответ, близкий к 1.
Цель алгоритма обратного распространения – так подстроить входные веса, чтобы сеть выдавала более высокое значение в случае, если ей снова выдать это изображение – и, желательно, другие изображения, где есть хот-доги. Для этого алгоритм обратного распространения начинает с изучения входных нейронов слоя, являющегося выходным. У каждого значения есть переменная веса. Алгоритм обратного распространения подстраивает каждый вес в таком направлении, чтобы НС выдавала более высокое значение. Чем выше входное значение, тем больше увеличивается его вес.
Пока что я описываю простейший алгоритм восхождения к вершине, знакомый исследователям ещё в 1960-х. Прорыв обратного распространения стал следующим шагом: алгоритм использует частные производные для распределения «вины» за неверный выход среди входов нейронов. Алгоритм подсчитывает, как на окончательный выход нейрона будет влиять небольшое изменение каждого входного значения, и подвинет ли это изменение результат ближе к правильному ответу, или наоборот.
В итоге получается набор значений ошибок для каждого нейрона в предыдущем слое – по сути, сигнал, оценивающий, было ли значение каждого нейрона слишком большим или слишком малым. Затем алгоритм повторяет процесс подстройки для новых нейронов из второго [с конца] слоя. Он немного изменяет входные веса каждого нейрона, чтобы подтолкнуть сеть ближе к правильному ответу.
Затем алгоритм снова использует частные производные для расчёта того, как значение каждого входа предыдущего слоя повлияло на ошибки выхода этого слоя – и распространяет эти ошибки назад, на пред-предыдущий слой, где процесс снова повторяется.
Это просто упрощённая модель работы обратного распространения. Если вам нужны подробные математические детали, рекомендую книгу Майкла Нильсена по этой теме [и у нас есть её перевод / прим. перев.]. Для наших целей достаточно того, что обратное распространение радикально изменило диапазон обучаемых НС. Люди уже не были ограничены простыми сетями с одним-двумя слоями. Они могли создавать сети с пятью, десятью или пятидесятью слоями, и у этих сетей могла быть произвольно сложная внутренняя структура.
Изобретение обратного распространения запустило второй бум НС, начавший выдавать практические результаты. В 1998 году группа исследователей из AT&T показала, как можно использовать нейросети для распознавания рукописных цифр, что позволило автоматизировать обработку чеков.
«Основной посыл этой работы в том, что мы можем создавать улучшенные системы распознавания закономерностей, больше полагаясь на автоматическое обучение и меньше – на разработанную вручную эвристику», — писали авторы.
И всё же в этой фазе НС были лишь одной из многих технологий в распоряжении исследователей машинного обучения (МО). Когда я обучался на курсе ИИ в институте в 2008 году, нейросети были всего лишь одним из девяти алгоритмов МО, из которых мы могли выбирать вариант, подходящий для выполнения задания. Однако ГО уже готовилось затмить остальные технологии.
Большие данные демонстрируют всю мощь глубокого обучения

Обратное распространение облегчило процесс обсчёта НС, однако более глубоким сетям всё равно требовалось больше вычислительных ресурсов, чем мелким. Результаты исследований, проводимых в 1990-х и 2000-х годах часто показывали, что от дополнительного усложнения НС можно было получать всё меньше выгоды.
Затем мышление людей изменила знаменитая работа 2012 года, где описывалась НС под именем AlexNet, названная в честь ведущего исследователя Алекса Крижевского. Куда как более глубокие сети могли обеспечивать прорывную эффективность, но только в сочетании с изобилием компьютерных мощностей и огромным количеством данных.
AlexNet разработала троица специалистов по информатике из университета Торонто для участия в научном конкурсе ImageNet. Организаторы конкурса насобирали в интернете миллион изображений, каждое из которых было размечено и отнесено к одной из тысяч категорий объектов, например, «вишня», «контейнеровоз» или «леопард». Исследователям ИИ предлагалось обучить свои МО-программы на части из этих изображений, а потом попытаться проставить правильные метки для других изображений, с которыми ПО не встречалось до этого. ПО должно было выбрать пять возможных меток для каждой картинки, и попытка считалась удачной, если одна из них совпадала с реальной.
Это было сложной задачей, и до 2012 года результаты были не очень хорошими. У победителя 2011 года процент ошибок составлял 25%.
В 2012 году команда AlexNet обошла всех конкурентов на голову, выдав ответы с 15% ошибок. У ближайшего конкурента этот показатель равнялся 26%.
Исследователи из Торонто скомбинировали несколько техник для достижения прорывных результатов. Одной из них было использование свёрточных нейростей (СНС). По сути, СНС как бы обучает небольшие нейросети – входные данные которых представляют собой квадраты со стороной 7-11 пикселей – а потом «накладывают» их на более крупное изображение. «Это похоже на то, как если бы вы взяли небольшой шаблон или трафарет, и пытались сравнить его с каждой точкой изображения, — рассказал нам в прошлом году исследователь ИИ Цзе Тан. – У вас есть трафарет собачки, и вы прикладываете его к изображению, и смотрите – есть ли там собачка? Если нет, сдвигаете трафарет. И так для всей картинки. И неважно, где на картинке появляется собачка. Трафарет с ней совпадёт. Каждая подсекция сети не должна становиться отдельным классификатором собак».
Ещё одним ключевым фактором успеха AlexNet стало использование графических карт для ускорения процесса обучения. У графических карт есть параллельные вычислительные мощности, хорошо подходящие для повторяющихся вычислений, необходимых для обучения нейросети. Перенеся груз вычислений на пару GPU — Nvidia GTX 580, по 3 Гб памяти на каждой – исследователи смогли разработать и обучить чрезвычайно крупную и сложную сеть. У AlexNet было восемь обучаемых слоёв, 650 000 нейронов и 60 млн параметров.
Наконец, успех AlexNet обеспечил ещё и большой размер базы обучающих изображений из ImageNet: миллион штук. Нужно очень много изображений для точной подстройки 60 млн параметров. Достичь решительной победы AlexNet помогла комбинация из сложной сети и крупного набора данных.
Интересно, почему же подобный прорыв не произошёл ранее:
- Пара GPU потребительского качества, использованная исследователями AlexNet, была далеко не самым мощным вычислительным устройством для 2012 года. За пять и даже за десять лет до этого существовали более мощные компьютеры. Кроме того, технология ускорения обучения НС при помощи графических карт была известна по крайней мере с 2004.
- База из миллиона изображений была необычно большой для обучения алгоритмов МО в 2012 году, однако сбор подобных данных не был новой технологией для того года. Исследовательская группа с хорошим финансированием смогла бы без особых проблем собрать базу данных такого размера ещё на пять или десять лет раньше.
- Основные алгоритмы, использовавшиеся в AlexNet, не были новыми. Алгоритм обратного распространения к 2012 году существовал уже примерно четверть века. Ключевые идеи, связанные со свёрточными нейросетями были выработаны в 1980-х и 1990-х.
Так что каждый из элементов успеха AlexNet существовал по отдельности задолго до происшедшего прорыва. Очевидно, никому не пришло в голову скомбинировать их – по большей части потому, что никто не догадался, насколько это будет мощная комбинация.
Увеличение глубины НС практически не улучшало эффективность их работы, если использовались недостаточно большие наборы обучающих данных. А расширение набора данных не улучшало эффективности небольших сетей. Чтобы увидеть прирост эффективности, нужны были как более глубокие сети, так и более крупные наборы данных – плюс значительные вычислительные мощности, позволяющие провести процесс обучения за разумное время. Команда AlexNet стала первой, собравшей все три элемента в одной программе.
Бум глубокого обучения

Процент ошибок у победителей постепенно снижался – от впечатляющих 16% у AlexNet в 2012 году до 2,3% в 2017 году:
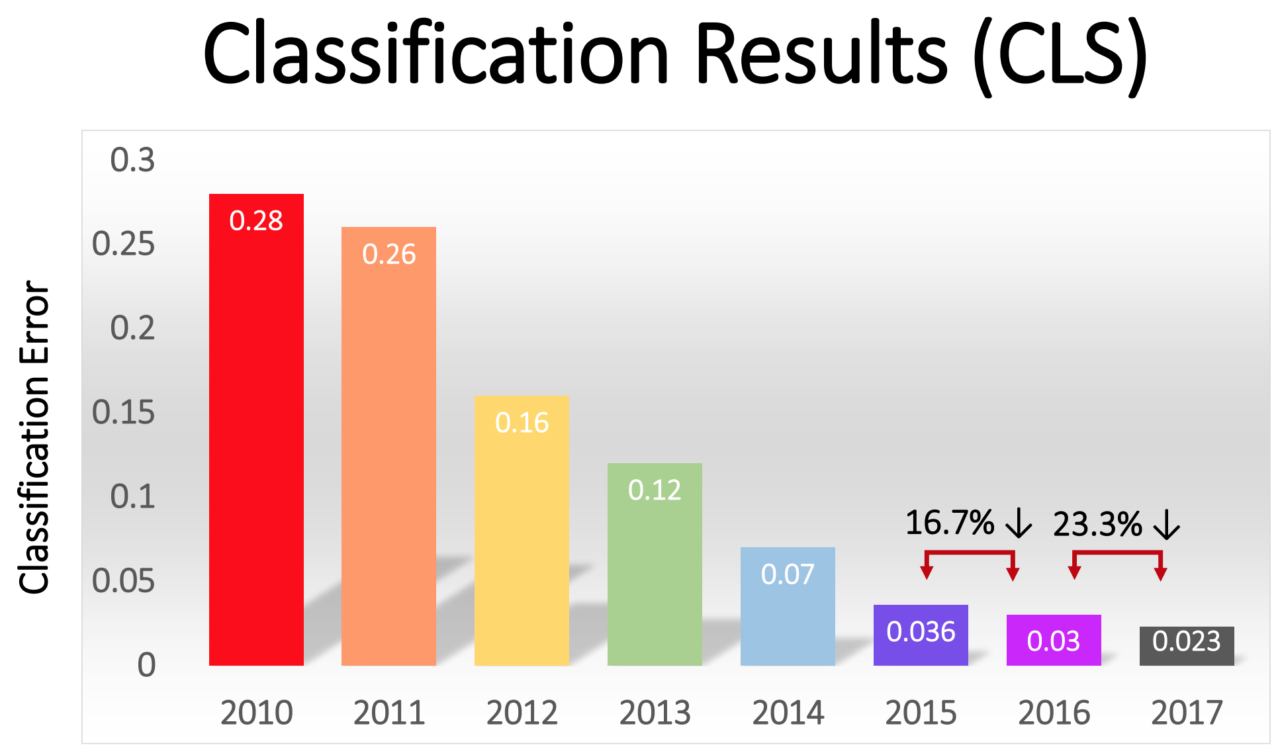
В последние годы в индустрии образовалась самоподдерживающаяся тенденция, в рамках которой увеличение вычислительных мощностей, объёмов данных и глубины сетей поддерживают друг друга. Команда AlexNet использовала GPU потому, что они предлагали параллельные вычисления за разумные деньги. Но за последние несколько лет всё больше компаний начали разрабатывать собственные чипы, специально предназначенные для применения в области МО.
Google объявила о выпуске специально предназначенного для НС чипа Tensor Processing Unit в 2016. В том же году Nvidia объявила о выходе нового GPU под названием Tesla P100, оптимизированного для НС. Intel ответила на вызов своим ИИ-чипом в 2017. В 2018 Amazon объявила о выпуске собственного ИИ-чипа, который можно будет использовать в рамках облачных сервисов компании. Даже Microsoft, как говорят, работает над своим ИИ-чипом.
Производители смартфонов также работают над чипами, которые позволят мобильным устройствам выполнять больше вычислений при помощи НС локально, без необходимости загружать данные на сервера. Подобные вычисления на устройства уменьшают задержки и усиливают конфиденциальность.
Даже Tesla вступила в эту игру со специальными чипами. В этом году Tesla показала новый мощный компьютер, оптимизированный для расчётов НС. Tesla назвала его Full Self-Driving Computer и представила, как ключевой момент стратегии компании по превращению парка Tesla в робомобили.
Доступность компьютерных мощностей, оптимизированных для ИИ, породила запрос на данные, необходимые для обучения всё более сложных НС. Эта динамика наиболее очевидна в секторе робомобилей, где компании собирают данные о миллионах километров реальных дорог. Tesla может собирать такие данные автоматически с автомобилей пользователей, а её конкуренты, Waymo и Cruise платили водителям, которые ездили на их автомобилях по общественным дорогам.

Тому, конечно, есть ограничения. К примеру, некоторые люди баловались с идеей обучения робомобилей при помощи одного лишь ГО – то есть, скармливать изображения, получаемые с камеры, нейросети, и получать от неё инструкции по повороту руля и нажатию педалей. Я скептически отношусь к такому подходу. НС пока ещё не продемонстрировали способности проводить сложные логические рассуждения, которые требуются для понимания определённых условий, возникающих на дороге. Более того, НС представляют собой «чёрные ящики», рабочий процесс которых практически невидим. Оценить и подтвердить безопасность такой системы было бы сложно.
Однако ГО позволило сделать весьма широкие скачки в неожиданно большом спектре приложений. В ближайшие годы можно ожидать очередных подвижек в этой области.