Как обучают нейросетевые модели для распознавания речи
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2019-12-19 12:35

Разработка разговорных систем состоит из трех шагов: обработка и траскрибирование аудиозаписи, понимание поставленного вопроса и генерация ответа в виде текста. Первый шаг достигается с помощью модели для распознавания речи. На втором шаге используются модели из обработки естественного языка. За выполнение третьего шага отвечает модель для генерации речи из текста. Исследователи из Nvidia описали пайплайн обучения нейросети для распознавания речи. Для решения этой задачи в Nvidia используют NeMo ASR.
Оптимизация каждого из шагов разработки разговорных агентов требует обучения одной или более моделей. С этой проблемой в Nvidia борются с помощью инструмента для обучения нейросетей NeMo. NeMo основан на PyTorch и упрощает процесс тестирования и внедрения нейросетей.
Пайплайн обучения модели для распознавания речи
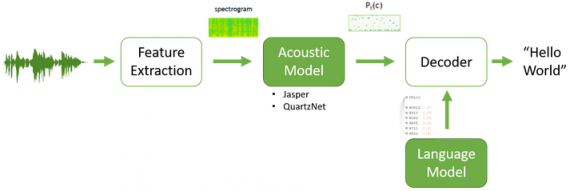
Автоматическое распознавание речи (ASR) состоит из таких подзадач, как сегментация речи, акустическое моделирование и языковое моделирование. ASR модель принимает на вход аудиозапись и выдает текстовое содержание аудиозаписи. Connectionist Temporal Classification (CTC) позволяет обучать AST модель end-to-end.
Процесс обучения включает в себя:
- Извлечение признаков: нормализация аудиозаписи, использование окон, спектрограммы;
- Акустическое моделирование: нейросеть на основе CTC для временной единицы аудиозаписи предсказывает вероятностное распределение букв;
- Декодирование: жадный отбор букв с максимальной вероятностью или языковое моделирование
Языковое моделирование исправляет ошибки акустической модели и делает предсказанный текст более реалистичным.
Телеграм: t.me/ainewsline
Источник: neurohive.io