
Промышленная разработка программных систем требует большого внимания к отказоустойчивости конечного продукта, а также быстрого реагирования на отказы и сбои, если они все-таки случаются. Мониторинг, конечно же, помогает реагировать на отказы и сбои эффективнее и быстрее, но недостаточно. Во-первых, очень сложно уследить за большим количеством серверов – необходимо большое количество людей. Во-вторых, нужно хорошо понимать, как устроено приложение, чтобы прогнозировать его состояние. Следовательно, нужно много людей, хорошо понимающих разрабатываемые нами системы, их показатели и особенности. Предположим, даже если найти достаточное количество людей, желающих заниматься этим, требуется ещё немало времени, чтобы их обучить.
Что же делать? Здесь нам на помощь спешит искусственный интеллект. Речь в статье пойдет о предиктивном обслуживании (predictive maintenance). Этот подход активно набирает популярность. Написано большое количество статей, в том числе и на Хабре. Крупные компании вовсю используют такой подход для поддержки работоспособности своих серверов. Изучив большое количество статьей, мы решили попробовать применить этот подход. Что из этого вышло?
Введение
Разработанная программная система рано или поздно поступает в эксплуатацию. Пользователю важно, чтобы система работала без сбоев. Если внештатная ситуация все же произойдет, она должна устраняться с минимальными задержками.
Для упрощения технической поддержки программной системы, особенно если серверов много, обычно используются программы мониторинга, которые снимают метрики с работающей программной системы, дают возможность диагностировать её состояние и помогают определить, что именно вызвало сбой. Этот процесс называется мониторингом программной системы.
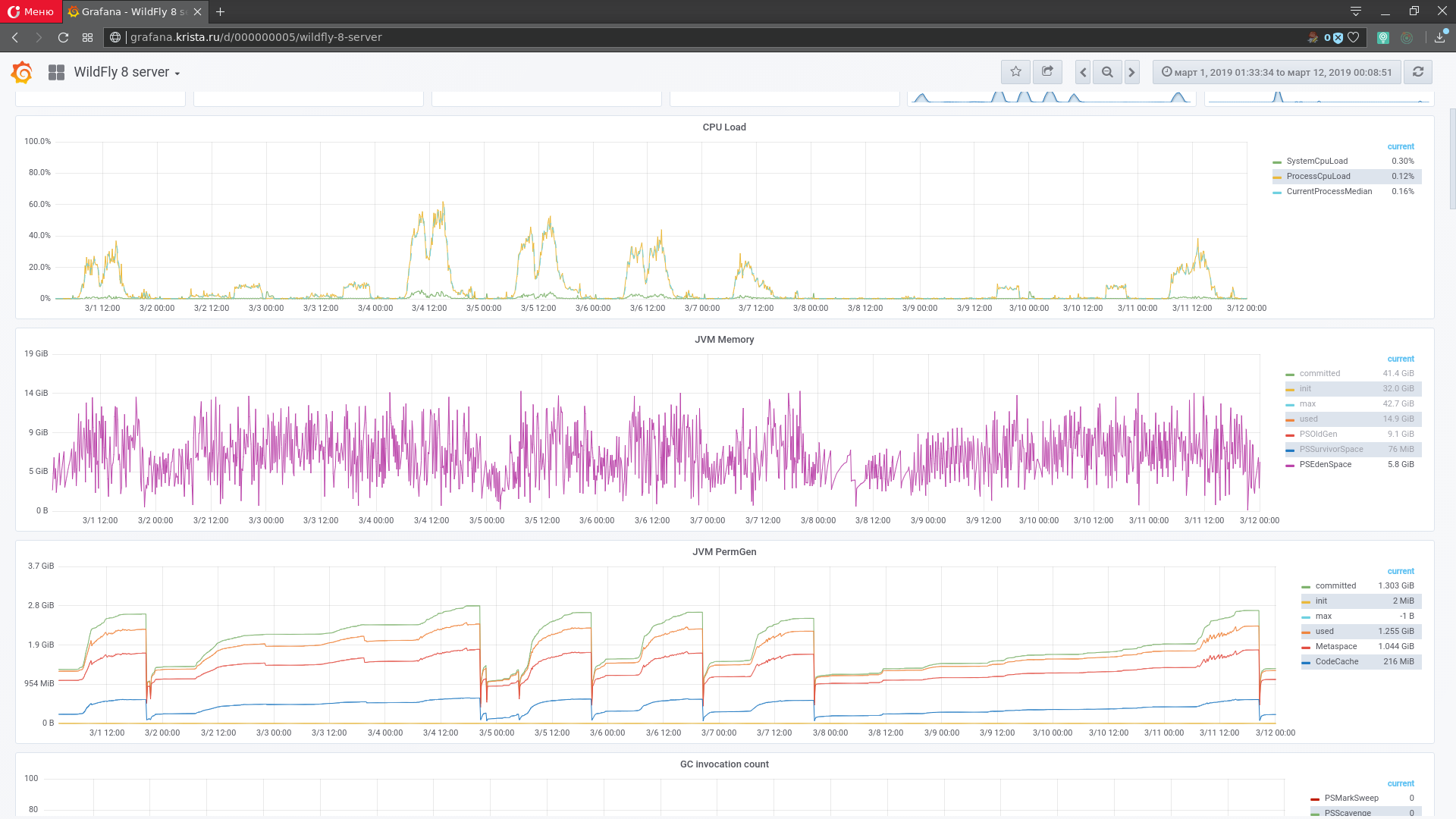
Рисунок 1. Интерфейс для мониторинга grafana
Метрики – это различные показатели программной системы, среды её исполнения или физической вычислительной машины, под которой запущена система с меткой времени, того момента, когда метрики были получены. В статическом анализе данные метрик называются временными рядами. Для наблюдения за состоянием программной системы метрики отображают в виде графиков: по оси X – время, а по оси Y – значения (рисунок 1). С работающей программной системы может сниматься несколько тысяч метрик (с каждого узла). Они образуют пространство метрик (многомерных временных рядов).
Так как у сложных программных систем снимается большое количество метрик, ручной мониторинг становится сложной задачей. Для сокращения объема анализируемых администратором данных средства мониторинга содержат инструменты для автоматического выявления возможных проблем. Например, можно настроить триггер, срабатывающий в случае уменьшения свободного дискового пространства до указанного порога. Также можно автоматически диагностировать остановку сервера либо критическое замедление скорости обслуживания. На практике средства мониторинга неплохо справляются с обнаружением уже произошедших отказов либо выявлением простых симптомов будущих отказов, но в целом предсказание возможного сбоя остается для них крепким орешком. Предсказание же путем ручного анализа метрик требует привлечения квалифицированных специалистов. Оно низкопродуктивно. Большинство потенциальных отказов могут остаться незамеченными.
В последнее время среди крупных IT-компаний по разработке ПО всё большую популярность приобретает именно так называемое предиктивное обслуживание программных систем. Суть данного подхода заключается в нахождении неполадок, ведущих к деградации системы на ранних этапах, до её отказа с использованием искусственного интеллекта. Данный подход не исключает полностью ручной мониторинг системы. Он является вспомогательным для процесса мониторинга в целом.
Основным инструментом реализации предиктивного обслуживания является задача поиска аномалий во временных рядах, так как при возникновении аномалии в данных велика вероятность того, что через некоторое время возникнет сбой или отказ. Аномалия – это некоторое отклонение показателей программной системы, такое как выявление деградации скорости выполнения запроса одного вида или снижение среднего числа обслуживаемых обращений при постоянном уровне клиентских сессий.
Задача поиска аномалий для программных систем имеет свою специфику. По идее для каждой программной системы необходима разработка или доработка имеющихся методов, так как поиск аномалий очень зависит от данных, в которых он производится, а данные программных систем очень различаются в зависимости от инструментов реализации системы вплоть до того, под какой вычислительной машиной она запущена.
Методы поиска аномалий при прогнозировании отказов программных систем
Прежде всего, стоит сказать, что идея прогнозирования отказов была навеяна статьей «Машинное обучение в IT-мониторинге». Для проверки эффективности подхода с автоматическим поиском аномалий была выбрана программная система «Web-Консолидация», которая является одним из проектов компании НПО «Криста». Для неё ранее производился ручной мониторинг по получаемым метрикам. Так как система достаточно сложная, для неё снимается большое количество метрик: показатели JVM (загрузка сборщика мусора), показатели ОС, под которой исполняется код (виртуальная память, % загрузки ЦПУ ос), показатели сети (загрузка сети), самого сервера (загрузка ЦПУ, памяти), метрики wildfly и собственные метрики приложения по всем критичным подсистемам.
Все метрики снимаются с системы при помощи graphite. Изначально использовалась база whisper как стандартное решение для grafana, но с ростом клиентской базы graphite перестал справляться, исчерпав пропускную способность дисковой подсистемы ДЦ. После этого было принято решение о поиске более эффективного решения. Выбор был сделан в пользу graphite+clickhouse, что позволило на порядок уменьшить нагрузку на дисковую подсистему и в пять-шесть раз уменьшить занимаемый дисковый объем. Ниже представлена схема механизма сбора метрик с использованием graphite+clickhouse (рисунок 2).
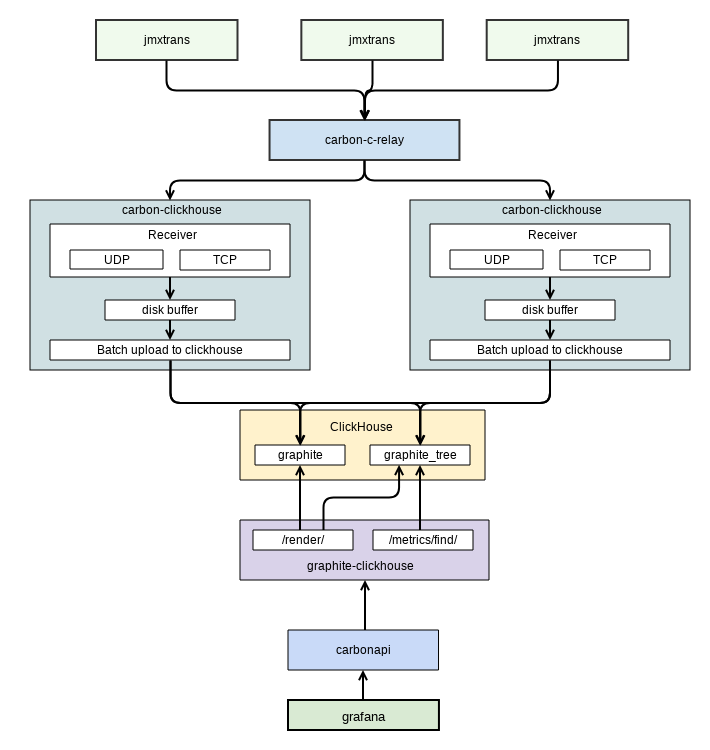
Рисунок 2. Схема снятия метрик
Схема взята из внутренней документации. На ней показан обмен данными между grafana (пользовательский интерфейс для мониторинга, который мы используем) и graphite. Снятие метрик с приложения производит отдельный софт – jmxtrans. Он же складывает их в graphite. У системы «Web-Консолидация» есть ряд особенностей, которые создают проблемы для прогнозирования отказов:
- часто происходит смена тренда. Для данной программной системы выходят различные версии. Каждая из них несет изменения в программной части системы. Соответственно, таким образом разработчики напрямую воздействуют на метрики данной системы и могут вызвать смену тренда;
- особенность реализации, а также цели использования клиентами данной системы часто взывают аномалии без предшествующей деградации;
- процент аномалий относительно всего набора данных мал (< 5%);
- могут возникать разрывы в получении показателей от системы. В некоторые короткие промежутки времени системе мониторинга не удается получить метрики. К примеру, если сервер перегружен. Для обучения нейросети это критично. Возникает необходимость заполнять пробелы синтетически;
- Случаи с аномалиями часто бывают актуальны только для конкретного числа/месяца/времени (сезонность). Данная система имеет четкий регламент использования её пользователями. Соответственно, метрики актуальны только для конкретного времени. Система может использоваться не постоянно, а только в некоторые месяцы: выборочно в зависимости от года. Возникают ситуации, когда одно и то же поведение метрик в одном случае может вести к отказу программной системы, а в другом нет.
Для начала были проанализированы методы обнаружения аномалий в данных мониторинга программных систем. В статьях по этой тематике при малых процентах аномалий относительно остального набора данных чаще всего предлагается использовать нейронные сети.
Основная логика для поиска аномалий при помощи данных нейронных сетей изображена на рисунке 3:

Рисунок 3. Поиск аномалий при помощи нейросети
На результате прогноза или восстановления окна текущего потока метрик рассчитывается отклонение от полученного с работающей программной системы. В случае большой разницы между полученными метриками от программной системы и нейронной сети можно делать вывод об аномальности текущего отрезка данных. Возникает следующий ряд проблем для использования нейронных сетей:
- для корректной работы в потоковом режиме данные для обучения моделей нейронных сетей должны включать в себя только «нормальные» данные;
- необходимо иметь актуальную модель для корректного обнаружения. Смена тренда и сезонности в метриках могут вызвать большое число ложных срабатываний модели. Для её обновления необходимо четко определить время, когда модель является устаревшей. Если обновить модель позднее или раньше, то, вероятнее всего, последует большое количество ложных срабатываний.
Также нельзя забывать о поиске и предотвращении частого возникновения ложных срабатываний. Предполагается, что они будут чаще всего возникать в нештатных ситуациях. Однако они могут быть и следствием ошибки нейронной сети по причине недостататочности её обучения. Необходимо минимизировать количество ложных срабатываний модели. В противном случае ложные прогнозы будут тратить много времени администратора, предназначенного для проверки системы. Рано или поздно кончится тем, что администратор просто перестанет реагировать на «параноидальную» систему мониторинга.
Рекуррентная нейронная сеть
Для обнаружения аномалий во временных рядах можно применить рекуррентную нейронную сеть с памятью LSTM. Проблема есть лишь в том, что она может применяться только для прогнозируемых временных рядов. В нашем случае не все метрики являются прогнозируемыми. Попытка применить RNN LSTM для временного ряда представлена на рисунке 4.
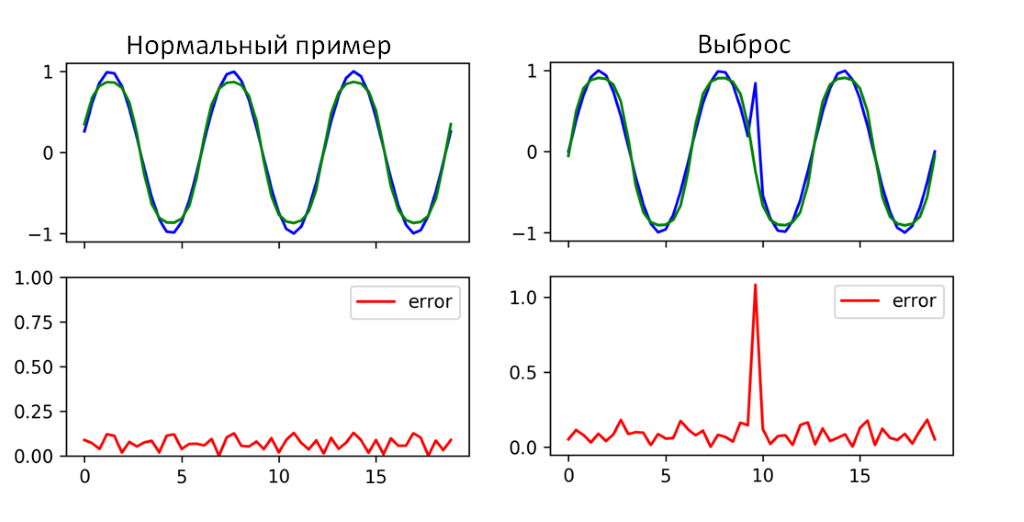
Рисунок 4. Пример работы рекуррентной нейронной сети c ячейками памяти LSTM
Как видно из рисунка 4, RNN LSTM удалось справиться с поиском аномалии на данном участке времени. Там, где результат имеет высокую ошибку прогнозирования (mean error), действительно произошла аномалия по показателям. Использования одной RNN LSTM явно будет недостаточно, поскольку она применима к малому количеству метрик. Можно использовать как вспомогательный метод поиска аномалий.
Автокодировщик для прогнозирования отказов
Автокодировщик – по сути искусственная нейронная сеть. Входной слой – encoder, выходной слой – decoder. Недостаток всех нейросетей данного типа – плохо локализует аномалии. Была выбрана архитектура синхронного автокодировщика.
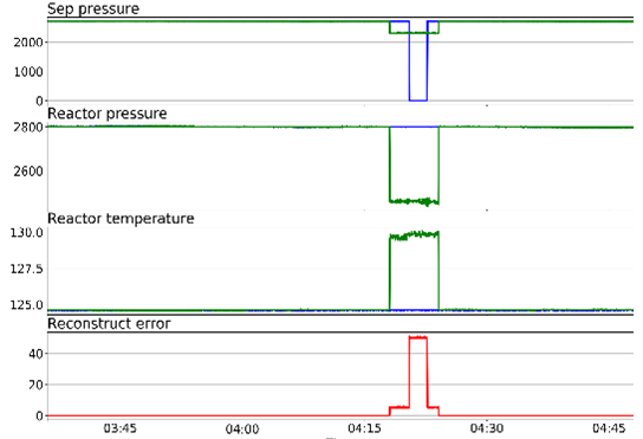
Рисунок 5. Пример работы автокодировщика
Автокодировщики обучаются на нормальных данных и затем находят, что-то аномальное в подаваемых в модель данных. Как раз то, что нужно для данной задачи. Остается только выбрать, какой из автокодировщиков подойдет для данной задачи. Архитектурно простейшая форма автокодировщика представляет собой прямую, невозвратную нейронную сеть, которая очень похожа на многослойный персептрон (multilayer perceptron, MLP), с входным уровнем, уровнем выхода и одним или несколькими скрытыми слоями, соединяющими их. Однако различия между автокодировщиками и MLP заключаются в том, что в автоматическом кодировщике выходной уровень имеет такое же количество узлов, что и входной, и что вместо того, чтобы обучаться предсказанию целевого значения Y, заданному входом X, автокодировщик обучается реконструировать свои собственные X. Поэтому автокодировщики являются неконтролируемыми обучающими моделями.
Задача автокодировщика заключается в нахождении временных индексов r0 … rn, соответствующих аномальным элементам во входном векторе X. Данный эффект достигается за счет поиска квадратичной ошибки.
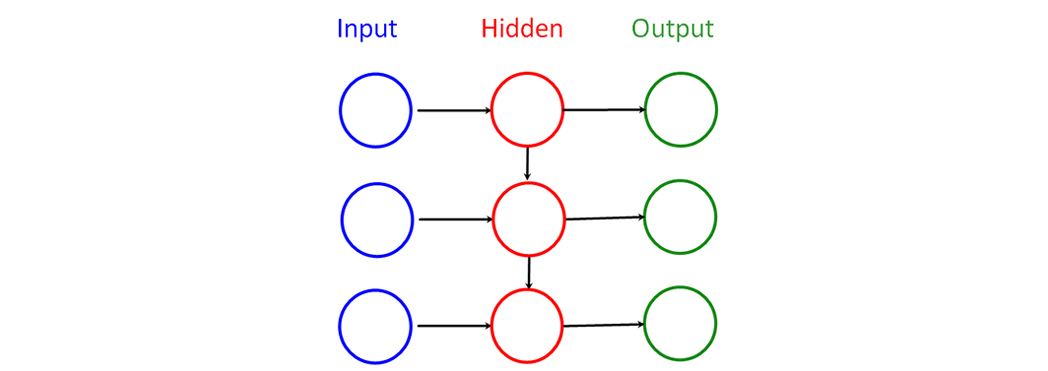
Рисунок 6. Синхронный автокодировщик
Для автокодировщика была выбрана синхронная архитектура. Её преимущества: возможность использования потокового режима обработки и сравнительно меньшее количество параметров нейронной сети относительно других архитектур.
Механизм минимизации ложных срабатываний
В связи с тем, что возникают различные нештатные ситуации, а также возможна ситуация недостаточного обучения нейронной сети, для разрабатываемой модели обнаружения аномалий было принято решение о необходимости разработки механизма минимизации ложных срабатываний. Этот механизм основан на базе шаблонов, которую классифицирует администратор.
Алгоритм динамической трансформации временной шкалы (DTW-алгоритм, от англ. dynamic time warping) позволяет найти оптимальное соответствие между временными последовательностями. Впервые применен в распознавании речи: использован для определения того, как два речевых сигнала представляют одну и ту же исходную произнесённую фразу. Впоследствии было найдено применение ему и в других областях.
Основной принцип минимизации ложных срабатываний – это сбор базы эталонов при помощи оператора, который классифицирует подозрительные случаи, обнаруженные при помощи нейросетей. Далее происходит сравнение проклассифицированного эталона с тем случаем, который обнаружила система, и делается вывод о принадлежности случая к ложному либо приводящему к сбою. Как раз для сравнения двух временных рядов и используется алгоритм DTW. Основным инструментом минимизации всё же является классификация. Предполагается, что после сбора большого количества эталонных случаев система начнет меньше спрашивать оператора по причине схожести большинства случаев и возникновения похожих.
В итоге на основе вышеописанных методов нейронных сетей была построена экспериментальная программа для прогнозирования отказов системы «Web-Консолидация». Целью этой программы было, используя существующий архив данных мониторинга и информацию об уже случившихся сбоях, оценить компетентность данного подхода для наших программных систем. Схема работы программы представлена ниже, на рисунке 7.
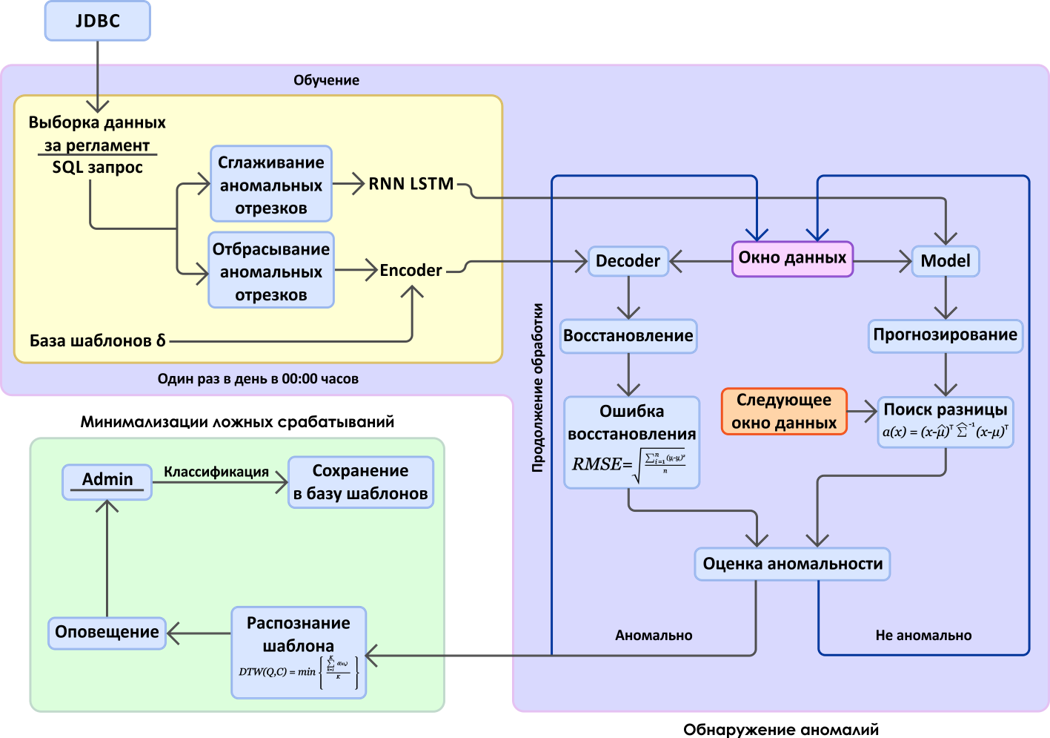
Рисунок 7. Схема прогнозирования отказов на основе анализа пространства метрик
На схеме можно выделить два основных блока: поиск аномальных отрезков времени в потоке данных мониторинга (метриках) и механизм минимизации ложных срабатываний. Примечание: в экспериментальных целях данные получаются через JDBC-соединение из базы данных, в которую их сохранят graphite.
Далее представлен интерфейс полученной в результате разработки системы мониторинга (рисунок 8).
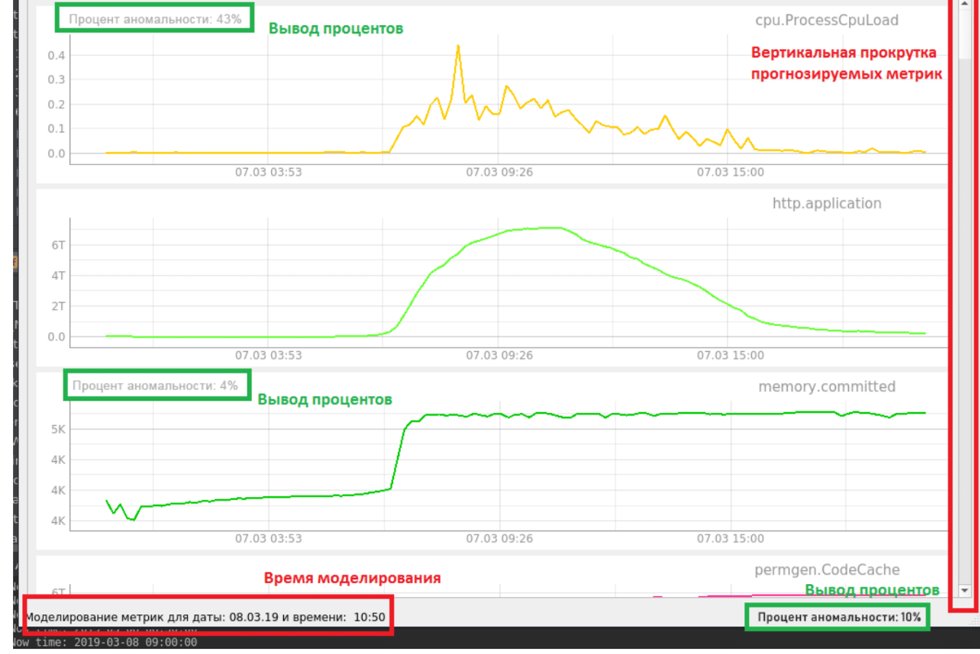
Рисунок 8. Интерфейс экспериментальной системы мониторинга
На интерфейсе отображается процент аномальности по получаемым метрикам. В нашем случае получение моделируется. Мы уже имеем все данные за несколько недель и грузим их постепенно для проверки случая с аномалией, приводящей к отказу. В нижнем статусбаре отображается общий процент аномальности данных в данный момент времени, который определяется при помощи автокодировщика. Также для прогнозируемых метрик отображается отдельный процент, который рассчитывает RNN LSTM.
Пример обнаружения аномалии по показателям ЦПУ при помощи нейросети RNN LSTM (рисунок 9).

Рисунок 9. Обнаружение RNN LSTM
Довольно-таки простой случай, по сути обычный выброс, однако приводящий к отказу системы, был успешно вычислен при помощи RNN LSTM. Показатель аномальности в этом участке времени равен 85 – 95%, все, что выше 80% (порог определен экспериментально), считается аномалией.
Пример обнаружения аномалии, когда система не смогла загрузиться после обновления. Данную ситуацию детектирует автокодировщик (рисунок 10).
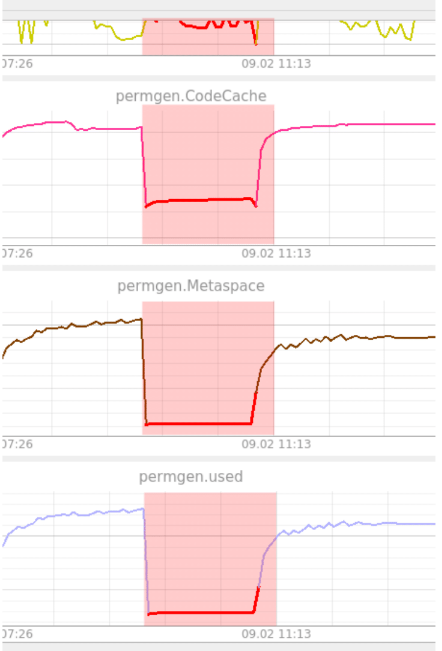
Рисунок 10. Пример обнаружения автокодировщиком
Как видно из рисунка, PermGen завис на одном уровне. Автокодировщик посчитал это странным, потому что ранее не видел ничего подобного. Здесь аномальность держится все 100% до возвращения системы в работоспособное состояние. Аномальность отображается по всем метрикам. Как говорилось ранее, автокодировщик не умеет локализировать аномалии. Оператор призван выполнять эту функцию в данных ситуациях.
Заключение
ПК «Web-Консолидация» разрабатывается не первый год. Система находится в достаточно стабильном состоянии, и число регистрируемых инцидентов невелико. Тем не менее, удалось найти аномалии, ведущие к отказу за 5 – 10 минут до возникновения отказа. В ряде случаев оповещение об отказе заблаговременно помогло бы сэкономить регламентное время, которое выделяется на проведение «ремонтных» работ.
По тем экспериментам, которые удалось провести, окончательные выводы делать еще рано. На данный момент результаты являются противоречивыми. С одной стороны, видно, что алгоритмы на основе нейронных сетей способны находить «полезные» аномалии. С другой стороны, остается большой процент ложных срабатываний, и не все аномалии, выявляемые квалифицированным специалистом у нейросети, получается обнаружить. К минусам можно отнести и то, что сейчас нейросеть требует обучения с учителем для нормальной работы.
Для дальнейшего развития системы прогнозирования отказов и доведения её до удовлетворительного состояния можно предусмотреть несколько путей. Это более подробный анализ случаев с аномалиями, которые приводят к сбою, за счет этого дополнения списка важных метрик, очень влияющих на состояние системы, и отброс лишних, которые не влияют на неё. Также, если двигаться в данном направлении, можно предпринять попытки специализации алгоритмов конкретно под наши случаи с аномалиями, которые приводят к отказам. Есть и другой путь. Это усовершенствование архитектур нейронных сетей и повышение за счёт этого точности обнаружений с сокращением времени на обучение.
Выражаю благодарность коллегам, помогавшим мне с написанием и поддержкой актуальности этой статьи: Виктору Вербицкому и Сергею Финогенову.