4 крутых функции Numpy, которые я использую постоянно
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2019-12-17 17:20
В этой статье я хочу рассказать о нескольких функциях Numpy, которые я использую для анализа данных постоянно. Это ни в коем случае не исчерпывающий список, но думаю, что инструменты, о которых пойдёт речь, пригодятся каждому без исключения.

Сталкиваясь с новой задачей, я раз за разом думал: «Это достаточно специфичная вещь, вряд ли для неё найдётся встроенная функция». В случае с Numpy, чаще я был неправ, чем прав.
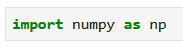
Но давайте ближе к делу. Единственная строка импорта, которая нам нужна:
where()
Функция where() возвратит элементы, удовлетворяющие определённому условию. Посмотрим на примере.
Создадим список оценок (произвольных):

Теперь можно воспользоваться where(), чтобы найти оценки большие, скажем, чем 3:
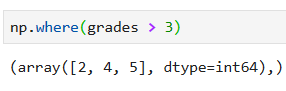
Обратите внимание, что возвращаются индексы искомых элементов.
Но это, разумеется, ещё не всё, функция может принимать два опциональных параметра:
- первый заменит собой значения, удовлетворяющие условию
- второй сделает это для значений, условию не удовлетворяющих

Поскольку статья задумана краткой, на этом и остановимся.
argmin(), argmax(), argsort()
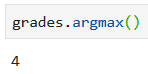
Функция argmin() возвращает индекс минимального значения. Для того же массива оценок, что мы использовали выше, результат будет:

argmax(), как вы наверняка догадались, делает прямо противоположное — возвращает индекс максимального элемента:
Последняя из троицы argsort() вернёт список индексов отсортированных элементов массива. Не забывайте про неё: вы столкнётесь с огромным количеством ситуаций, когда это нужно.

intersect1d()
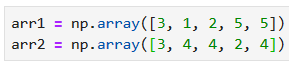
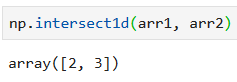
Функция intersect1d() возвратит пересечение двух массивов, т.е. уникальные элементы, которые встречаются в обоих. В отличие от предыдущих примеров, она вернёт не индексы, а сами значения.
Создадим два массива:
Найдём общие элементы:
allclose()
Напоследок рассмотрим функцию allclose(). Она возвратит True, если элементы двух массивов равны в пределах допуска. Опять же, вы не представляете, как часто это нужно при работе с данными.
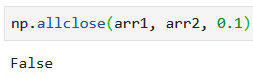
Объявим два массива, разница между соответствующими элементами которых не более 0.2:

Функция allclose() с допуском в 0.1 должна вернуть False:
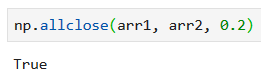
Повысим допуск до 0.2, чтобы получить приблизительное равенство массивов:
Напутствие
Не счесть количество раз, когда я был (и есть) виноват в изобретении колеса. Часто мы думаем, что наша проблема уникальна, и никто не догадался создать инструмент для её решения. Иногда это правда, но часто чувствуешь себя последним идиотом, найдя удобную стандартную функцию взамен той, на создание которой уже потратил кучу времени.
Потратьте лучше немного этого времени на изучение возможностей популярных библиотек, ведь именно благодаря им библиотеки и стали популярны.
Телеграм: t.me/ainewsline
Источник: habr.com