Разработчики Яндекс.Браузера о технической стороне Дзена, персональных рекомендаций на основе машинного обучения и нейросетей
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2016-06-08 15:44
новости нейронных сетей, алгоритмы машинного обучения, поисковые системы


В будущем, как нам кажется, все популярные браузеры выйдут за рамки программ для открытия веб-страниц и научатся лучше понимать людей, которые ими пользуются. Сегодня я расскажу вам, каким мы видим это будущее на примере персональной ленты Дзен в Яндекс.Браузере, которая теперь доступна пользователям Windows, Android и iOS.
Несмотря на кажущуюся простоту, в основе Дзена лежат довольно сложные технологии. Я расскажу немного о том, как это реализовано у нас, где и почему мы использовали традиционное машинное обучение, а где - нейронные сети и искусственный интеллект, и буду благодарен за ваше мнение об этом подходе.
Рекомендации хорошо знакомы всем, кто активно пользуется сетью. Интернет-магазины предлагают схожие товары. Онлайн-кинотеатры советуют фильмы. Музыка, книги, игры, приложения - в любой нише можно найти примеры подобных решений. В современном мире, где количество информации растет в геометрической прогрессии, рекомендации помогают людям найти что-то новое и интересное.
Яндекс всегда специализировался на поиске. В широком смысле этого слова. Поиск ответов на свои вопросы. Поиск оптимального маршрута. И даже поиск свободного такси рядом с вами. Примерно два года назад у нас появилась еще одна идея. Научить машину искать в сети тот контент, который был бы интересен конкретному человеку. Персонализированный поиск, где в качестве запроса выступают не слова, а интересы. Из этой идеи и родилась лента рекомендованного контента Дзен.
Дзен
Дзен - это бесконечная лента контента, которая формируется исходя из интересов конкретного человека. Мы хотим помочь пользователям найти интересный контент, а издателям - целевой трафик (клик по рекомендациям открывает материал на сайте-первоисточнике). Обычно рассказы о новых продуктах начинают с описания идеологии и продуктовой стратегии, и здесь я рекомендую вам прочитать пост Романа kukutz Иванова в блоге Яндекса, а мы с вами сразу перейдем к самому важному для Хабра, к технологиям. Тем более, что именно они отличают Дзен в Яндекс.Браузере от любых других браузерных (и не только) аналогов.

Кстати, внимательный читатель может вспомнить, что первые эксперименты с Дзеном проводились в 2015 году на странице zen.yandex.ru. Почему теперь лента рекомендаций стала частью Браузера? На этот раз вопрос я обязательно отвечу чуть позже.
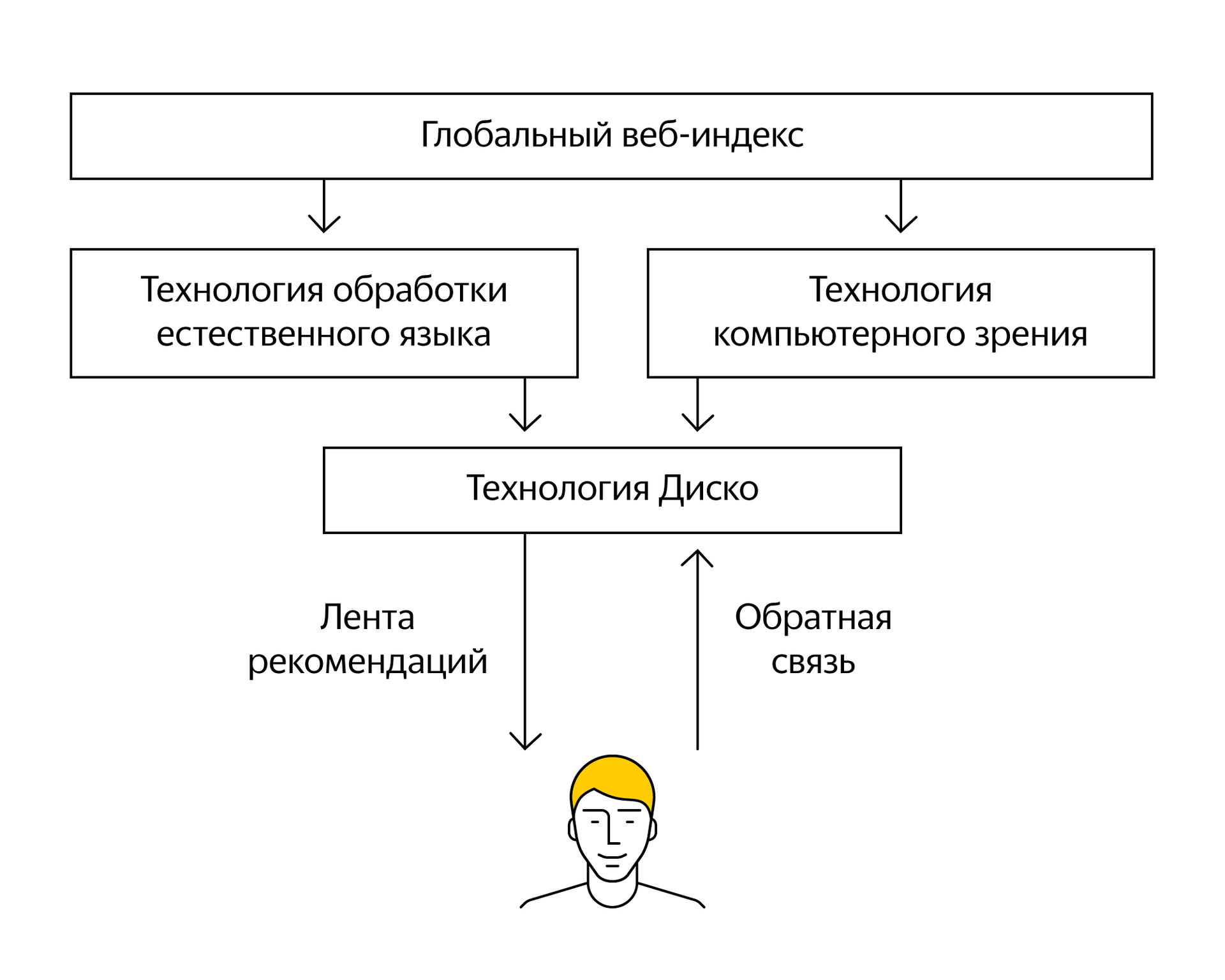
В основе Дзена лежит рекомендательная технология Диско, разработанная в Яндексе и уже нашедшая применение в Яндекс.Музыке и Яндекс.Маркете. Слово «диско» созвучно английскому слову discovery, которое означает «открытие нового» и хорошо описывает суть технологии.
Упрощенная логическая схема работы Диско в случае с Дзеном выглядит так:
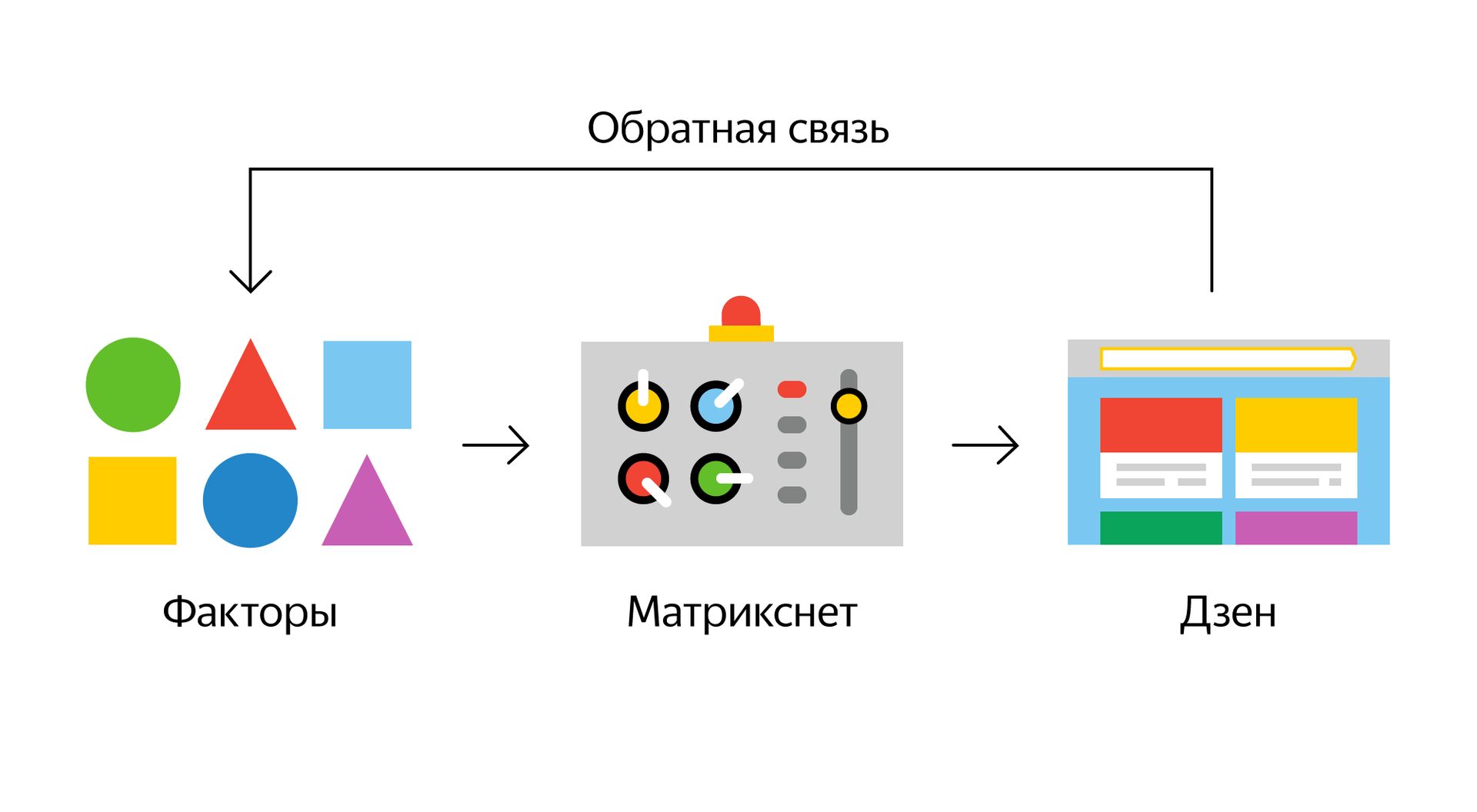 Начнем с самого начала, с исходных данных, которым еще только предстоит как-то превратиться в факторы.
Начнем с самого начала, с исходных данных, которым еще только предстоит как-то превратиться в факторы.
С чего начинаются рекомендации
Прежде чем что-либо советовать человеку, нужно понять его интересы и предпочтения. Дзен для этого использует знания Яндекса о посещаемых людьми сайтах. Благодаря этим знаниям многие новые пользователи Дзена смогут сразу увидеть ленту персональных рекомендаций без необходимости что-то настраивать. Но иногда их недостаточно. Можно было бы попробовать решить эту проблему с помощью ленты, ориентированной на среднестатистического человека. Но мы же знаем, что такого человека в реальности не существует (что хорошо было показано на примере американских военно-воздушных сил). Поэтому пошли другим путем и предложили людям самостоятельно ограничить круг своих интересов. У этих настроек нет своего названия, но внутри мы называем их «Онбордингом».
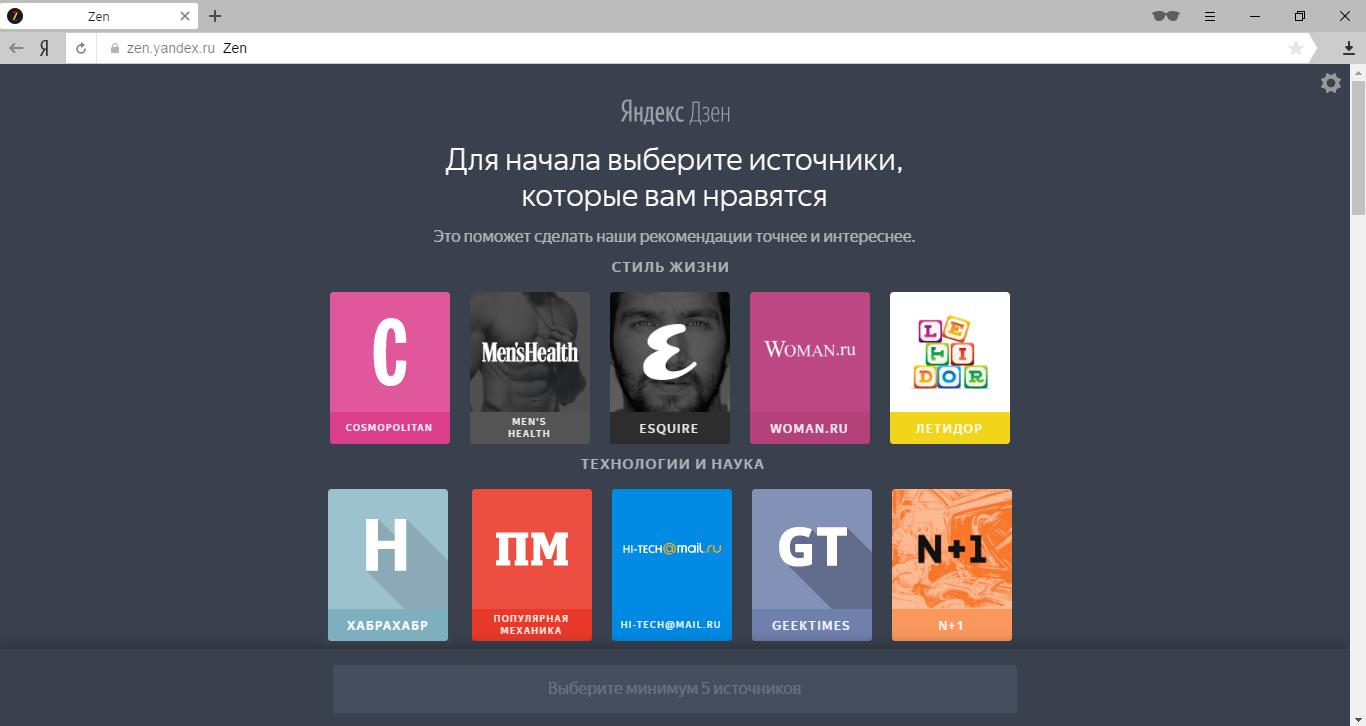 Важно понимать, что Онбординг - это не обязательный этап начальных настроек, а лишь резервный вариант для тех, кому точно нечего предложить. Лента рекомендаций сразу после прохождения Онбординга может достаточно сильно отличаться от подборок, формируемых через несколько недель активного использования Дзена. Эти настройки уже доступны пользователям Яндекс.Браузера для Android и iPhone. Для Windows станут доступны в ближайшее время (а пока можно воспользоваться временным решением).
Важно понимать, что Онбординг - это не обязательный этап начальных настроек, а лишь резервный вариант для тех, кому точно нечего предложить. Лента рекомендаций сразу после прохождения Онбординга может достаточно сильно отличаться от подборок, формируемых через несколько недель активного использования Дзена. Эти настройки уже доступны пользователям Яндекс.Браузера для Android и iPhone. Для Windows станут доступны в ближайшее время (а пока можно воспользоваться временным решением).
Знания об интересах человека - это лишь половина необходимой информации. Для того чтобы что-то рекомендовать, нужно для начала это что-то найти. Обычно рекомендательные сервисы решают эту задачу примитивным способом - формируют ограниченный каталог RSS-лент по интересам. В случае с Дзеном таких ограничений нет. Поисковые роботы ищут любые материалы. Это могут быть как авторские публикации с популярных блогов, так и качественные истории с форумов или ролики с YouTube. Это то, что мы называем «диким вебом». Главное, чтобы сайт не был заброшен и на странице содержалось достаточное количество полезного контента.
Итак, с одной стороны у нас знания о любимых публикациях миллионов пользователей, с другой - вся мощь глобального поискового индекса Яндекса. Осталось самое «простое». Научить машину строить рекомендации.
Виды рекомендательных систем
В истории рекомендательных технологий хорошо известны два их основных вида: фильтрация по содержимому и коллаборативная фильтрация. Начнем с первого, который основан на сравнении содержимого рекомендуемых объектов. Для примера предлагаю рассмотреть фильмы. Если два фильма относятся к одному и тому же жанру, и пользователь уже высоко оценил один из них, то с определенной вероятностью можно посоветовать ему и второй. И здесь интересно вспомнить онлайн-кинотеатр Netflix, который увеличил количество жанров с нескольких сотен до десятков тысяч, среди которых можно найти даже «Культовые ужастики со злыми детьми». Большая часть из этих жанров скрыта от глаз зрителей и используется только для построения рекомендаций.
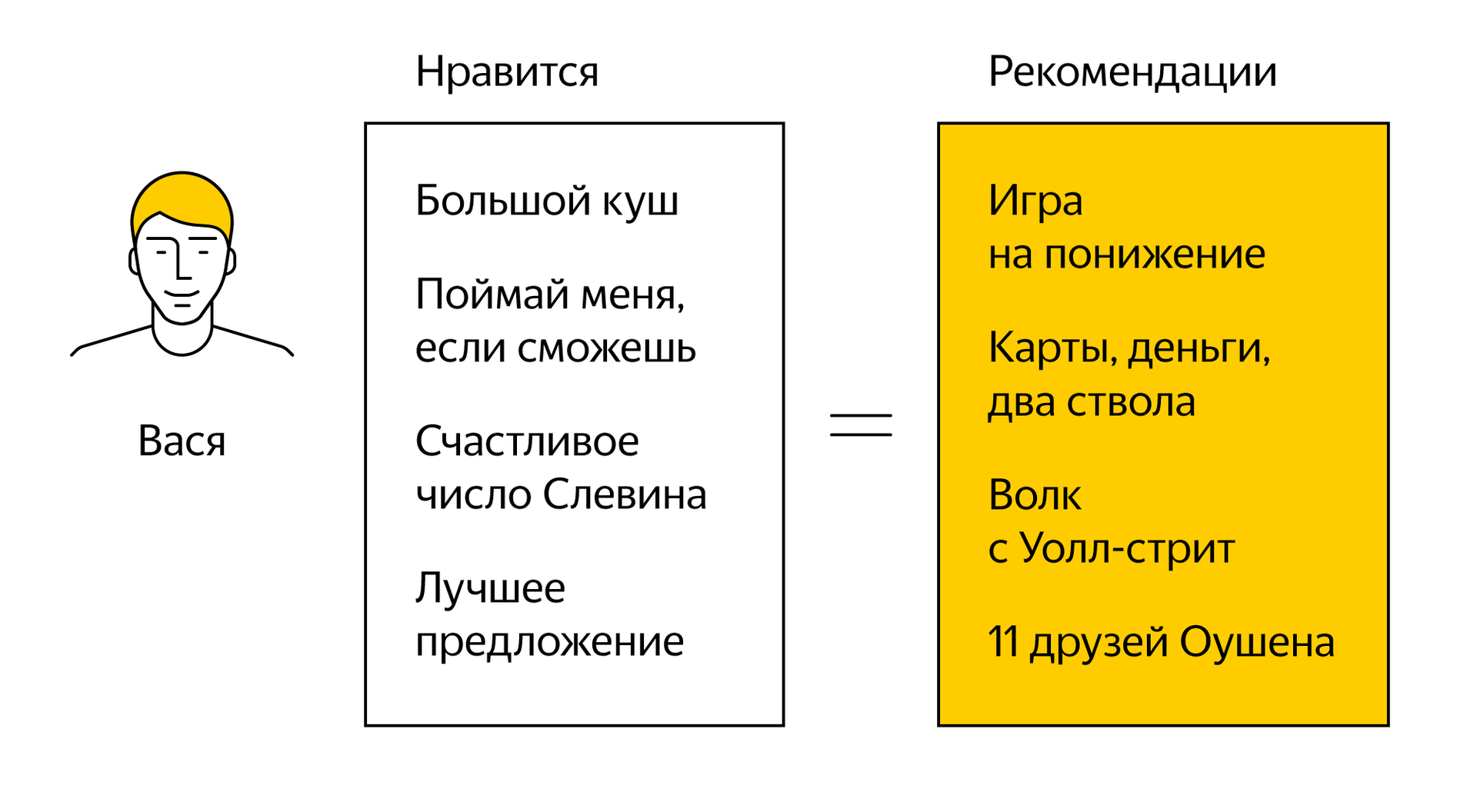 В нашем случае никаких жанров нет. Чтобы сделать вывод о соответствии веб-страницы интересам человека, нужно сравнить ее контент с известными образцами. Причем заниматься этим должен компьютер, которому нужно не просто прочитать материал, но и понять его смысл. И единственный способ решить эту задачу достаточно точно, это использовать опыт Яндекса в области искусственного интеллекта.
В нашем случае никаких жанров нет. Чтобы сделать вывод о соответствии веб-страницы интересам человека, нужно сравнить ее контент с известными образцами. Причем заниматься этим должен компьютер, которому нужно не просто прочитать материал, но и понять его смысл. И единственный способ решить эту задачу достаточно точно, это использовать опыт Яндекса в области искусственного интеллекта.
NLP + CV
Когда речь заходит об искусственном интеллекте, то многие пользователи представляют себе SkyNet, желающий поработить человечество. К счастью, будущее не предопределено и все в наших руках. Но а если серьезно, то наработки в области ИИ уже сейчас помогают нам решать сложные задачи. Способность машины читать, видеть и, что наиболее важно, понимать смысл открывает большие перспективы.
Обработка естественного языка (Natural Language Processing, NLP) и компьютерное зрение (Computer Vision, CV) - два широко применяемых в Дзене направления из области искусственного интеллекта.
Когда мы говорим о рекомендациях, то подразумеваем себе материалы, которые были бы достаточно близки по своему смысловому наполнению к образцам пользователя. Иными словами, машина должна прочитать два текста и сделать вывод: близки ли они по смыслу или нет. Ровно это мы и учимся делать. Специально обученная нейронная сеть преобразует текст в вектор, в котором заключен смысл текста. Два текста могут быть написаны с использованием разных слов и даже на разных языках, но смысл у них будет один. Сравнивая эти векторы, мы можем с определенной вероятностью предсказать интерес человека к новому материалу. Кстати, если векторы почти совпадают, то это уже говорит о смысловом дубликате (рерайт текста или разные статьи об одном и том же событии), с которыми мы боремся в ленте.
Другой подход к NLP, над которым работает команда Дзена, это автоматическое присвоение меток для любого текста. Вспомните про пример с Netflix'ом и десятками тысяч жанров. Так и здесь. Классификация публикаций с помощью меток помогает повысить точность итоговых рекомендаций.
Работа с компьютерным зрением в целом похожа на NLP. Только вместо чтения текста машина учится «смотреть» и понимать смысл изображения. Помимо прямого применения в рекомендациях у компьютерного зрения есть и другие задачи в Дзене. Например, миниатюры картинок далеко не всегда удобно масштабируются, и их приходится обрезать, а компьютерное зрение помогает находить на картинках людей и спасает их от судьбы Нэда Старка из «Игры престолов».
Компьютерное зрение применяется и для нахождение текста на картинках. Некоторые сайты любят дублировать заголовок в виде изображения. В ленте это смотрится далеко не так красиво, поэтому подобные картинки выявляются и не используются в качестве миниатюр. Существует еще такое труднообъяснимое понятие, как «качество» картинки. Машина учится выбирать на сайте те изображения, которые больше нравятся людям, и использует их в качестве все тех же миниатюр.
SVD
Выше я рассказал вам о подходе к построению рекомендаций, который основан на фильтрации по содержимому объектов. Теперь пришло время вспомнить о коллаборативной фильтрации. В основе этого подхода лежит идея, что похожим людям нравятся похожие объекты. В этом случае вам не нужно знать свойства рекомендуемых объектов, достаточно собрать статистику о том, насколько они соответствуют интересам пользователей. На примере фильмов это может выглядеть так:
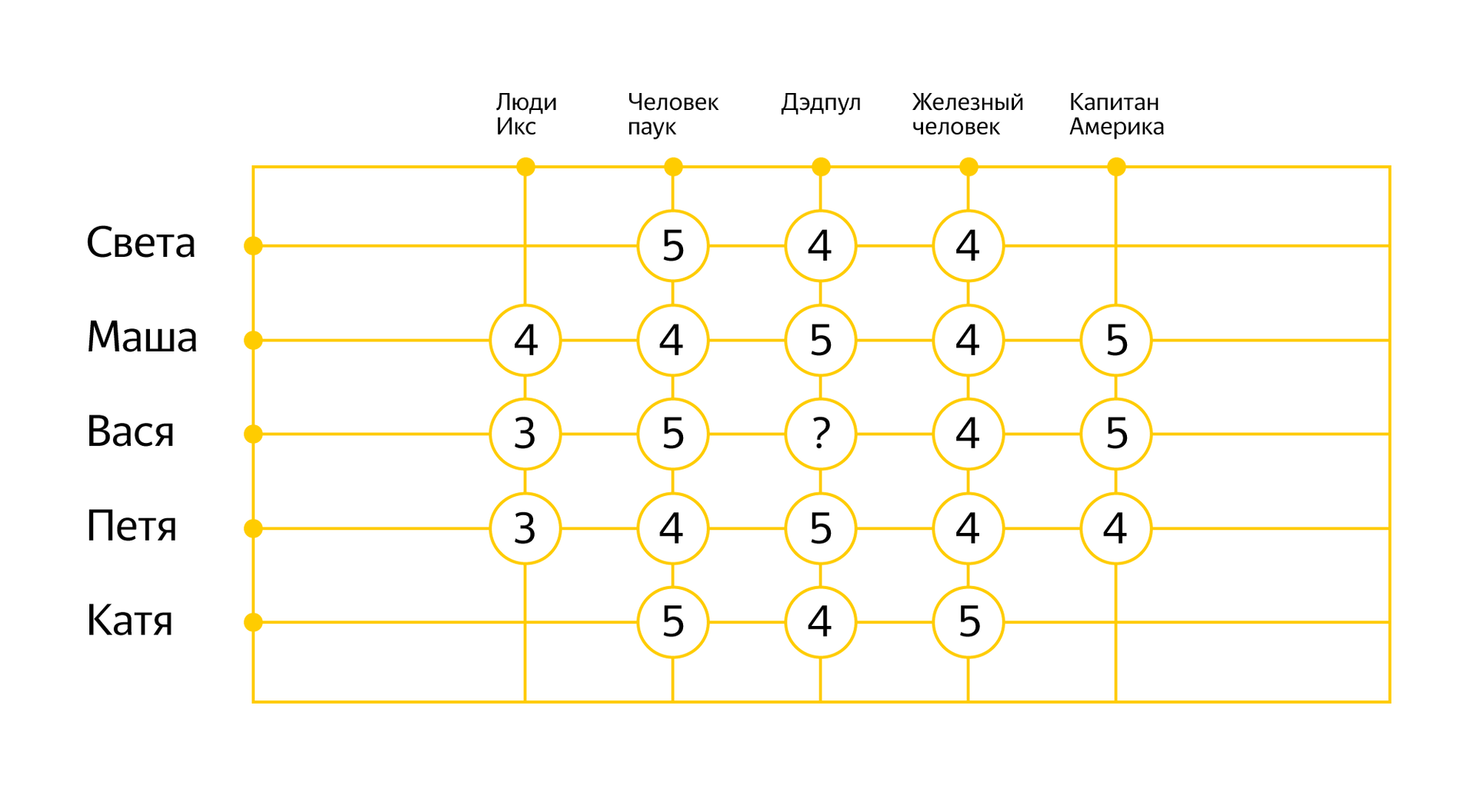
Опираясь на уже известные оценки, можно выявить закономерности в поведении разных людей и попробовать предсказать реакцию на новый фильм. На математическом уровне для применения коллаборативной фильтрации придуманы разные алгоритмы, о которых в свое время на Хабре хорошо рассказал мой коллега Михаил Ройзнер.
В случае с Дзеном мы используем коллаборативную фильтрацию (а точнее алгоритм SVD) для предсказания интереса человека к определенному сайту в целом. Эта информация дополняет рекомендации, построенные для отдельных материалов с помощью искусственного интеллекта (NLP+CV). Позволяет отсеять излишний шум и выявить нетривиальные закономерности (скажем, может выясниться, что люди, которые интересуются Хабром и историями с Пикабу, чаще других читают «N+1»).
Подытожим. Используя исходные данные о сайтах и пользователях, мы с помощью технологий обработки естественного языка, компьютерного зрения и алгоритма SVD формируем комплект различных факторов, которые характеризуют интересы человека к тем или иным сайтам/материалам.
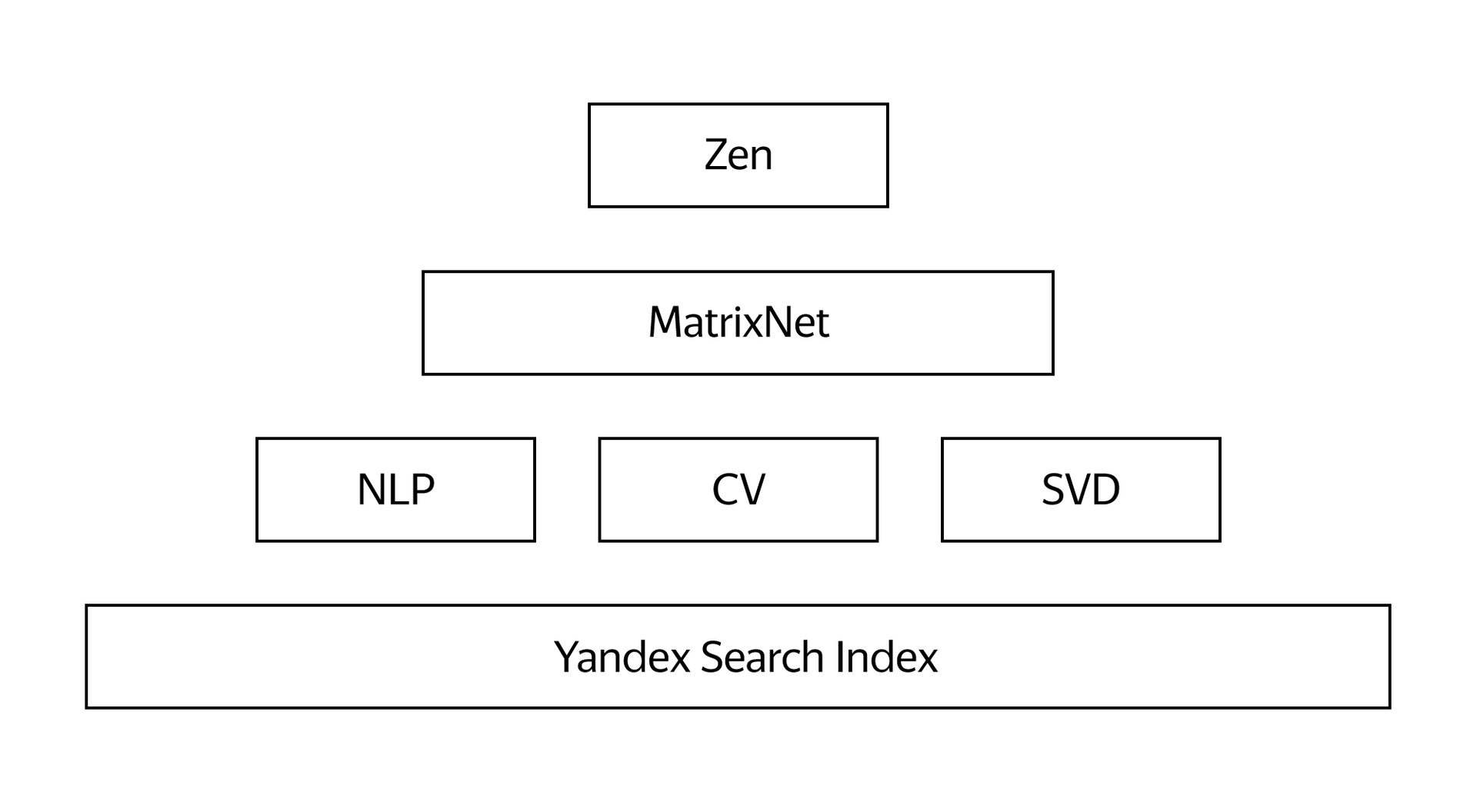
Точность итоговых рекомендаций напрямую зависит от количества и разнообразия исходных данных, поэтому в качестве факторов используются и многие другие наши знания. Например, знания Яндекса о конкретном сайте или странице, информация о том, как человек использует Дзен, его обратная связь в виде кликов, «больше такого» и «меньше такого», местоположение и даже время суток. Общее количество отдельных факторов, которые мы закладываем в систему рекомендаций, исчисляется тысячами. Сложность системы достигает такого уровня, что одних алгоритмов уже мало. Нужна технология, которая будет сама вычислять идеальную формулу для построения итоговой ленты. И здесь нам пригодился опыт Яндекса в области машинного обучения.
Матрикснет
Термин «машинное обучение» появился еще в 50-х годах. Он обозначает попытку научить компьютер решать задачи, которые легко даются человеку, но формализовать путь их решения сложно. В результате машинного обучения компьютер может демонстрировать поведение, которое в него не было явно заложено.
Каждый день наша поисковая система отвечает на миллионы запросов, многие из которых - неповторяющиеся. Поэтому невозможно написать такую программу, в которой предусмотрен каждый запрос и для каждого запроса известен лучший ответ. Поисковая система должна уметь принимать решения самостоятельно, то есть сама выбирать из миллионов документов тот, который лучше всего отвечает пользователю. Для этого нужно научить ее обучаться.
С 2009 года поиск Яндекса использует собственный метод машинного обучения Матрикснет. С его помощью можно построить очень длинную и сложную формулу ранжирования, которая учитывает множество различных факторов и их комбинаций. Кроме того, Матрикснет сам определяет разную чувствительность для разных значений факторов ранжирования. Эта технология достаточно универсальна, поэтому впоследствии нашла применение не только в Яндексе, но и в Европейском Центре ядерных исследований.
Способность компьютера учитывать тысячи факторов и самостоятельно искать наилучшее решение - это то, без чего невозможно построить современную рекомендательную систему. Именно поэтому Матрикснет был взят за основу при создании собственной рекомендательной технологии.
Результат работы Матрикснета - это именно то, что пользователь и видит в ленте Дзен. Со стороны разработчиков не существует каких-либо правил вида «Если человек любит А, то рекомендуем ему Б». Все подобные закономерности рождаются и постоянно меняются внутри Матрикснета. И чем больше у него данных, тем точнее рекомендации. Именно поэтому Дзен - это часть Яндекс.Браузера, а не самостоятельный веб-сервис или приложение. Отдельному приложению сложнее понять интересы пользователя, который после двух-трех дней может просто перестать его запускать. Чтобы магия Дзена и машинного обучения вступила в полную силу, им нужно активно пользоваться или хотя бы регулярно проходить рядом. И браузер, как единая точка выхода в интернет, подходит для этого лучше всего. Само собой, любой пользователь может отказаться от использования Дзена в Браузере.
В этом посте я рассказал вам о том, как формируется лента персональных рекомендаций в Яндекс.Браузере, и почему Дзен - это не очередная «лента новостей», а результат работы серьезных технологий. Наработки из области искусственного интеллекта уже сейчас помогают машине понимать смысл контента и интересы человека. Но это лишь самое начало. Кто знает, может быть, однажды компьютеры будут понимать нас лучше, чем мы сами?
Телеграм: t.me/ainewsline
Источник: vk.cc