Эволюция нейросетей для распознавания изображений в Google: Inception-v3
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2016-06-14 11:44


Продолжаю рассказывать про жизнь Inception architecture - архитеткуры Гугла для convnets.
(первая часть - вот тут)
Итак, проходит год, мужики публикуют успехи развития со времени GoogLeNet.
Вот страшная картинка как выглядит финальная сеть:
Что же за ужас там происходит?
Disclaimer: пост написан на основе отредактированных логов чата closedcircles.com, отсюда и стиль изложения, и уточняющие вопросы.
В этот раз авторы пытаются сформулировать какие-то основные принципы построения архитектуры эффективных сетей (собственно статья - http://arxiv.org/abs/1512.00567). (напомню, цель Inception architecture - быть прежде всего эффективной в вычислениях и количестве параметров для реальных приложений, за то и любим)
Принципы они формулируют следующие:
- Очень много сигналов близки друг к другу в пространстве (т.е. в соседних "пикселах"), и этим можно пользоваться, чтобы делать convolution меньшего размера.
Мол, раз соседние сигналы часто скоррелированы, то можно уменьшить размерность перед convolution без потери информации. - Для эффективного использования ресурсов нужно увеличивать и ширину, и глубину сети. Т.е. если ресурсов стало например в два раза больше, эффективнее всего и сделать слои шире, и сеть глубже. Если сделать только глубже, будет неэффективно.
- Плохо иметь резкие bottlenecks, то есть леер с резким уменьшением параметров, особенно в начале.
- "Широкие" слои быстрее обучаются, что особенно важно на высоких уровнях (но локально, т.е. вполне можно после них уменьшать размерность)
Напомню, прошлая версия кирпичика построения сети выглядела вот так:
Какие они делают в нем модификации
Во-первых, замечаем, что можно заменить большой и жирный 5x5 convolution на два последовательных по 3x3, и мол так как сигналы скоррелированы, немного потеряем. Экспериментально оказывается, что делать между этими 3x3 нелинейность лучше, чем не делать.
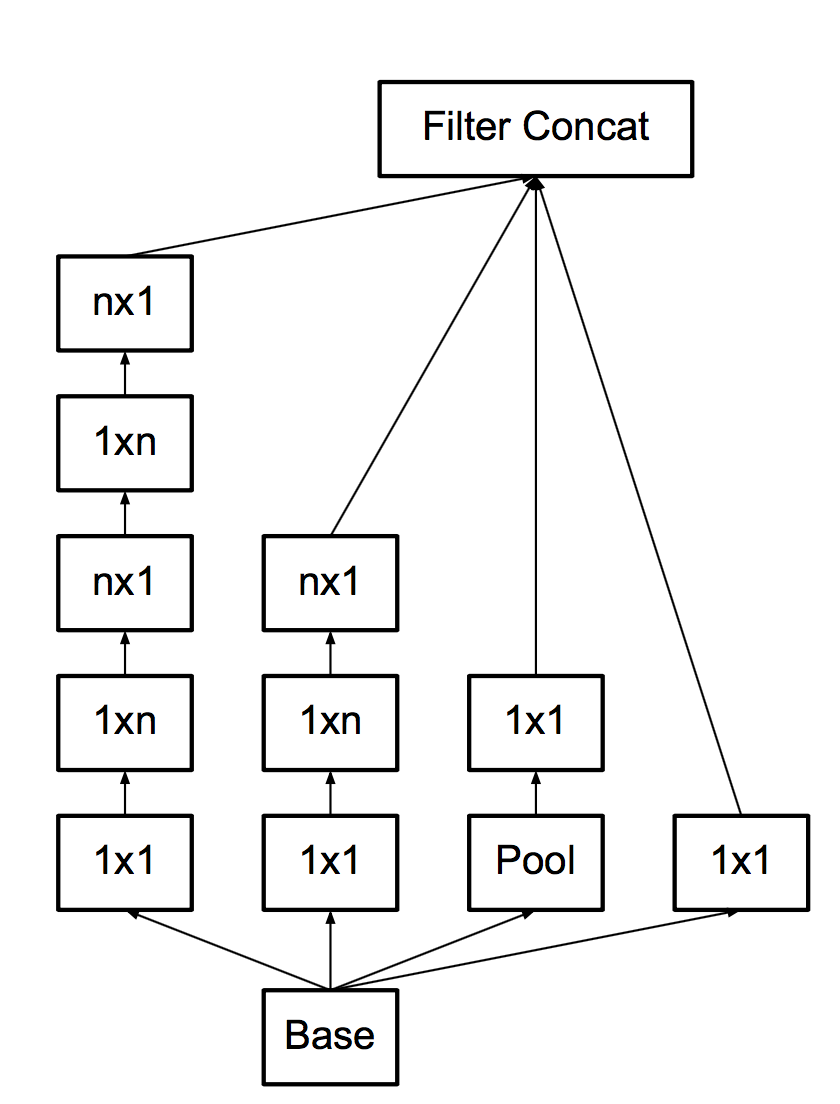
- Во-вторых, раз уж такая пьянка, давайте заменим 3x3 на 3x1 + 1x3.
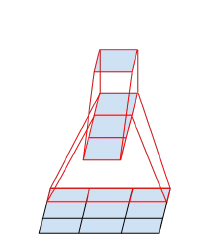
Тут мы обнаруживаем, что свертки-то делать становится дешево, и тогда почему бы вообще делать не 3x1 + 1x3, а сразу nx1 + 1xn!
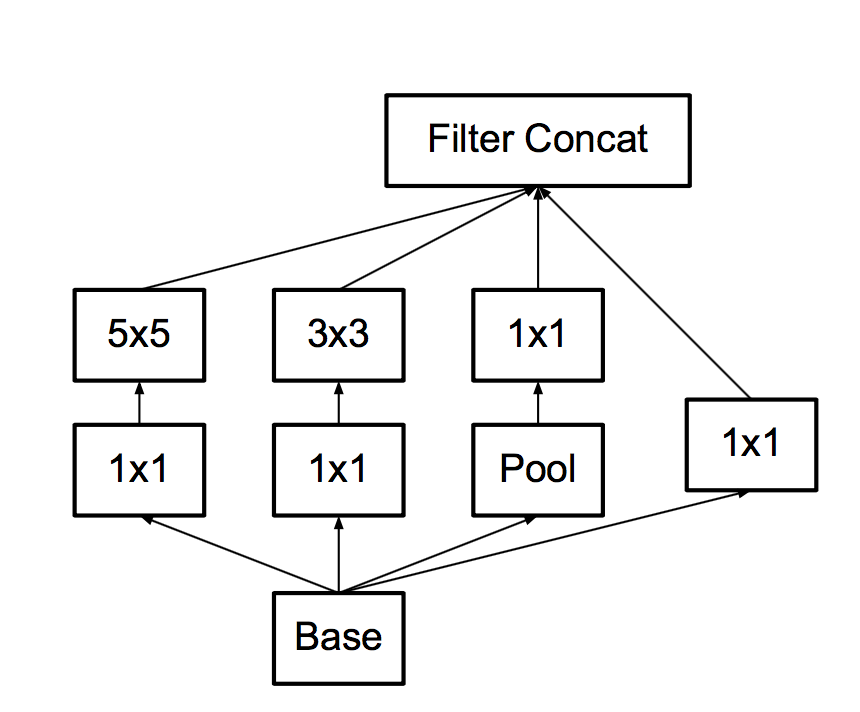
И делают, аж на 7, правда не в начале сетки. Со всеми этими апгрейдами основной кирпич становится таким:
- В-третьих, следуя завету "не создавай боттлнеков", думают про пулинг.
С пулингом какая проблема- Вот пускай пул уменьшит картинку в два раза, а количество фич после пула в два раза больше.
Можно сделать пул, а потом convolution в меньшем разрешении, а можно сначала convolution, а потом пул.
Вот эти варианты на картинке:

Проблема в том, что первый вариант - как раз резко уменьшит количество активаций, а второй - неэффективен с точки зрения вычислений, потому что нужно проводить convolution на полном разрешении.
Посему они предлагают гибридную схему - давайте сделаем на половину фич пул, а на половину - convolution.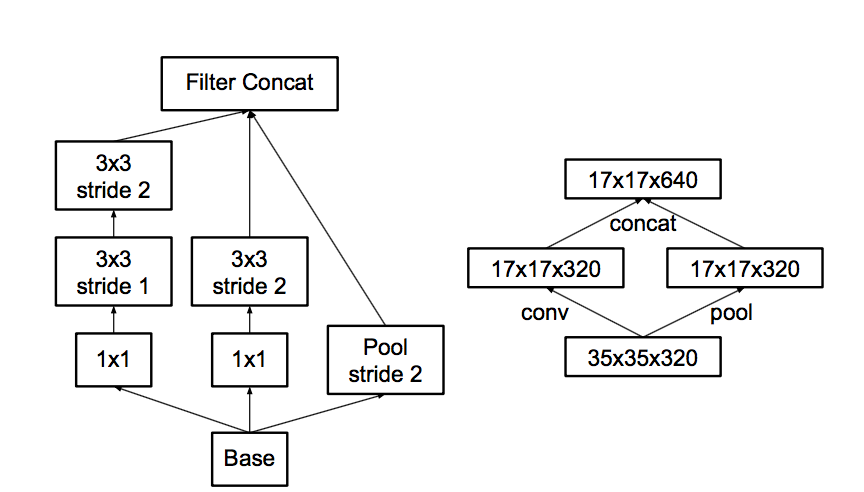
И так как после пула количество фич типично раза в два увеличивается, боттлнека не будет. Пул сожмет предыдущий не уменьшая количество фич, некоторые convolutions будут прогнаны в полном разрешении, но с количеством фич поменьше. Нетворк научится разделять, что требует полного разрешения, а для чего достаточно пула.
- Наконец, они немного модифицируют кирпичик для последних лееров, чтобы он был пошире, хоть и менее глубокий. Чтобы мол лучше обучался, в конце сети это важнее всего.
Отсюда и тот ужас на первом рисунке.
Еще они обнаружили, что дополнительные классификаторы по бокам не сильно-то ускоряют тренировку, а скорее помогают, потому что работают как регуляризаторы - когда они к ним подключили Batch Normalization, сеть стала предсказывать лучше.Что еще...
Они предлагают еще один трюк для дополнительной регуляризации - так называемый label smoothing. Идея вкратце такая: обычно target label для конкретного сэмпла это 1 там где класс правильный, и 0 где класс неправильный.
Это означает, что если нетворк уже очень уверен в правильности класса, градиент все равно будет толкать в увеличение и увеличение этой уверенности, потому что 1 наступает только на бесконечности из-за softmax, что ведет к оверфиттингу.
Итого
И вот вся эта машинерия жрет в 2.5 раз больше вычислительных ресурсов, чем Inception-v1 и достигает значительно лучших результатов. Они называют основную архитектуру Inception-v2, а версию, где дополнительные классификаторы работают с BN - Inception-v3.
Вот эта Inception-v3 достигает 4.2% top5 classification error на Imagenet, а ансамбль из четырех моделей - 3.58%.
Однако, случились ResNets и выиграли Kaiming He сотоварищи из Microsoft Research Asia с результатом- 3.57%!!!
(надо отметить, что в object localization результат у них принципиально лучше)
Но про ResNets я видимо в другой раз расскажу.
интересно средний хомо сапиенс какую ошибку покажет на этих картинках.
Единственный широко обсуждающийся эксперимент был проведен Andrey "наше все" Karpathy.
http://karpathy.github.io/2014/09/02/what-i-learned-from-competing-against-a-convnet-on-imagenet/
Он протестировал себя на какой-то части датасета и у него получилось 5.1%.
Это тоже top5, но может человеку сложнее top5 выбирать.
Кстати можно самому провериться - http://cs.stanford.edu/people/karpathy/ilsvrc/
И это реально сложно. Покажут тебе какой-то подвид средиземноморского зяблика и гадай.
Телеграм: t.me/ainewsline
Источник: habrahabr.ru