Data Mining из песочницы
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2016-06-07 14:50


Недавно я озадачился поиском б.у. автомобиля, взамен только что проданного, и, как это обычно бывает, на эту роль претендовали несколько конкурентов.
Как известно, для покупки авто на территории РФ существует несколько крупных авторитетных сайтов (auto.ru, drom.ru, avito.ru), поиску на которых я и отдал предпочтение. Моим требованиям отвечали сотни, а для некоторых моделей и тысячи, автомобилей, с перечисленных выше сайтов. Помимо того, что искать на нескольких ресурсах неудобно, так еще, прежде чем ехать смотреть авто -вживую-, я хотел бы отобрать выгодные (цена которых относительно рынка занижена) предложения по априорной информации которую предоставляет каждый из ресурсов. Я, конечно, очень хотел решить несколько переопределенных систем алгебраических уравнений (возможно и нелинейных) высокой размерности вручную, но пересилил себя, и решил этот процесс автоматизировать.
Сбор данных
Данные я собирал со всех описанных выше ресурсов, а интересовали меня следующие параметры:
- цена (price)
- год выпуска (year)
- пробег (mileage)
- объем двигателя (engine.capacity)
- мощность двигателя (engine.power)
- тип двигателя (2 индикаторные взаимоисключающие переменные diesel и hybrid, принимающие значения 0 или 1, для дизельных и гибридных двигателей соответственно). Тип двигателя по умолчанию - бензиновый (не вынесен в третью переменную во избежании мультиколлинеарности).
Таким образом: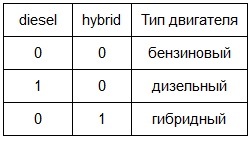
Далее подобная логика для индикаторных переменных подразумевается по умолчанию. - тип кпп (индикаторная переменная mt (manual transmission), принимающая булево значение, для механической коробки передач). Тип кпп по умолчанию - автоматическая.
Необходимо отметить, что к автоматическим коробкам передач я относил не только классический гидравлический автомат, но также роботизированную механику и вариатор. - тип привода (2 индикаторные переменные front.drive и rear.drive, принимающие булевы значения). Тип привода по умолчанию - полный.
- тип кузова (7 индикаторных переменных sedan, hatchback, wagon, coupe, cabriolet, minivan, pickup, принимающих булевы значения). Тип кузова по умолчанию - внедорожник/кроссовер
Незаполненные ленивыми продавцами данные я отмечал как NA (Not Available), чтобы можно было корректно обрабатывать эти значения с помощью R.
Визуализация полученных данных
Дабы не вдаваться в сухую теорию, давайте рассмотрим конкретный пример, будем искать выгодные Mercedes-Benz E-klasse не старше 2010 года выпуска, стоимостью до 1.5 млн. рублей в Москве. Для того, чтобы начать работать с данными, первым делом заполняем пропущенные значения (NA) на медианные, благо для этого в R есть функция median().
Для остальных переменных процедура идентична, поэтому опущу этот момент.
Теперь посмотрим как цена зависит от регрессоров (визуализация индикаторных переменных на данном этапе нас не интересует).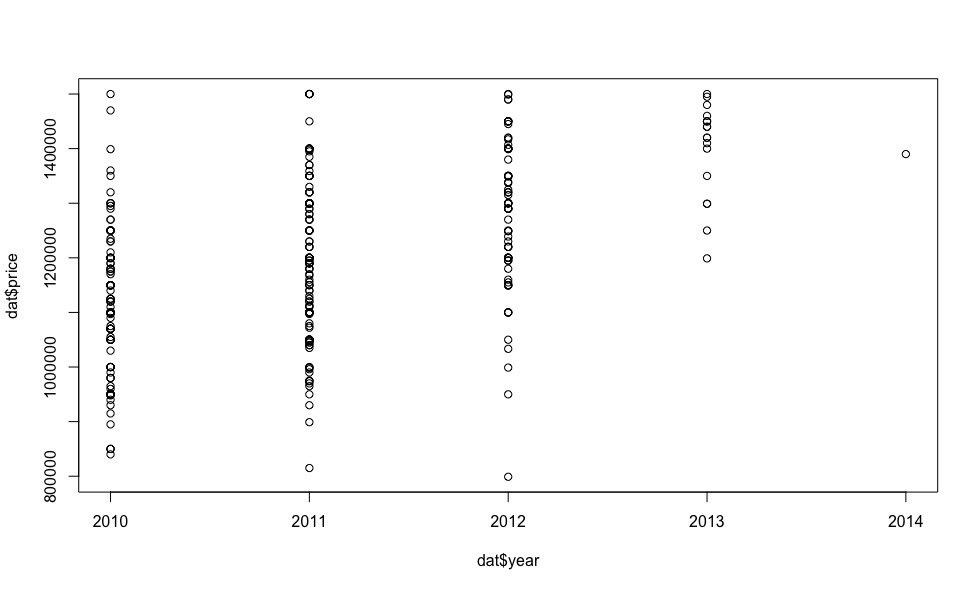
Оказывается за эти деньги есть несколько машин 2013 года и даже одна 2014!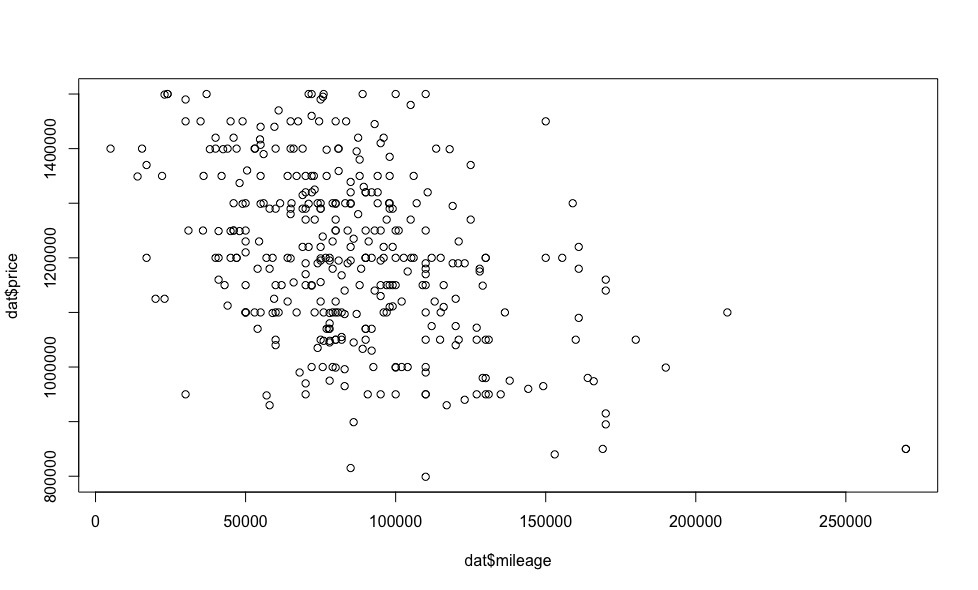
Очевидно, что чем меньше пробег, тем цена выше.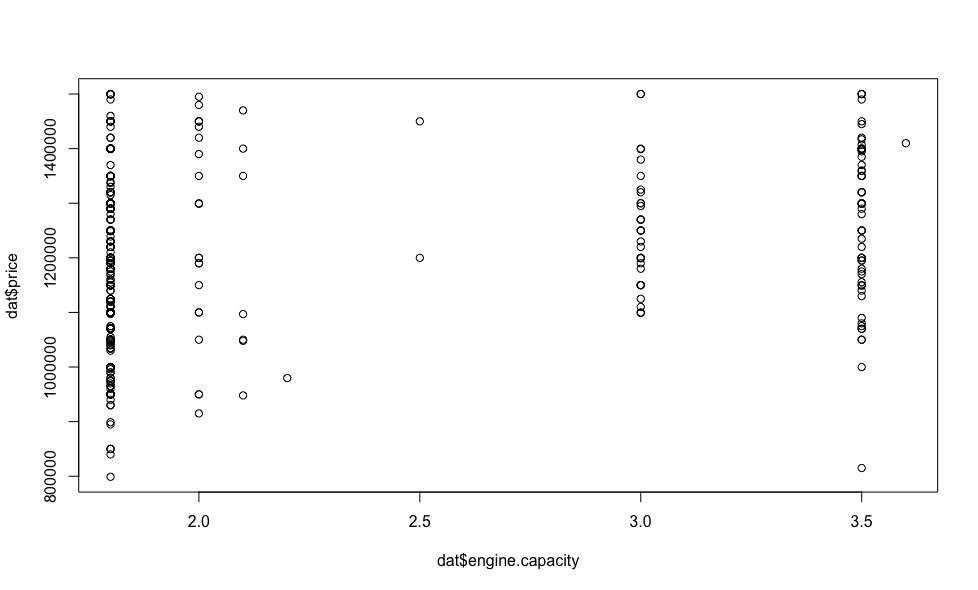

На некоторых из графиков мы видим точки выделяющиеся из общей выборки - выбросы, исключив которые, можно сделать предположение о линейной зависимости цены от параметров автомобиля.
Хочу обратить ваше внимание на тот факт, что в большинстве статей по машинному обучению, которые попадались мне в последнее время, в том числе на -Хабре-, очень мало внимания уделяется обоснованию правомерности использования выбранной модели, ее диагностики и ошибках.
Поэтому, дабы оценки полученные нами были состоятельными, разумно рассмотреть вопрос о корректности выбранной нами модели.
Диагностика модели
В предыдущем разделе, на основе экспериментальных данных, было сделано предположение о линейности рассматриваемой модели относительно цены, поэтому в этом разделе речь пойдет о множественной линейной регрессии, ее диагностике и ошибках.
Чтобы модель была корректной, необходимо выполнение условий теоремы Гаусса-Маркова:
- Модель данных правильно специфицирована, т.е.:
- отсутствуют пропущенные значения.
Подробнее
- отсутствует мультиколлинеарность между регрессорами.
Подробнее
- отсутствуют выбросы.
Подробнее
- отсутствуют пропущенные значения.
- Все регрессоры детерминированы и не равны.
Подробнее
- Ошибки не носят систематического характера, дисперсия ошибок одинакова (гомоскедастичность)
Подробнее
- Ошибки распределены нормально.
Подробнее
Опробирование выбранной модели
Итак, настал момент, когда с бюрократией покончено, корректность использования модели линейной регрессии не вызывает сомнений. Нам остается только посчитать коэффициенты линейного уравнения, по которым мы сможем получить свои, предсказанные цены на автомобили и сравнить их с ценами из объявлений.
А теперь, давайте-ка соберем все проделанные исследование в кучу, ради одного самого информативного графика, который покажет нам самую желанную для любого автомобильного перекупщика величину, величину выгоды от покупки конкретного авто относительно рыночной цены.
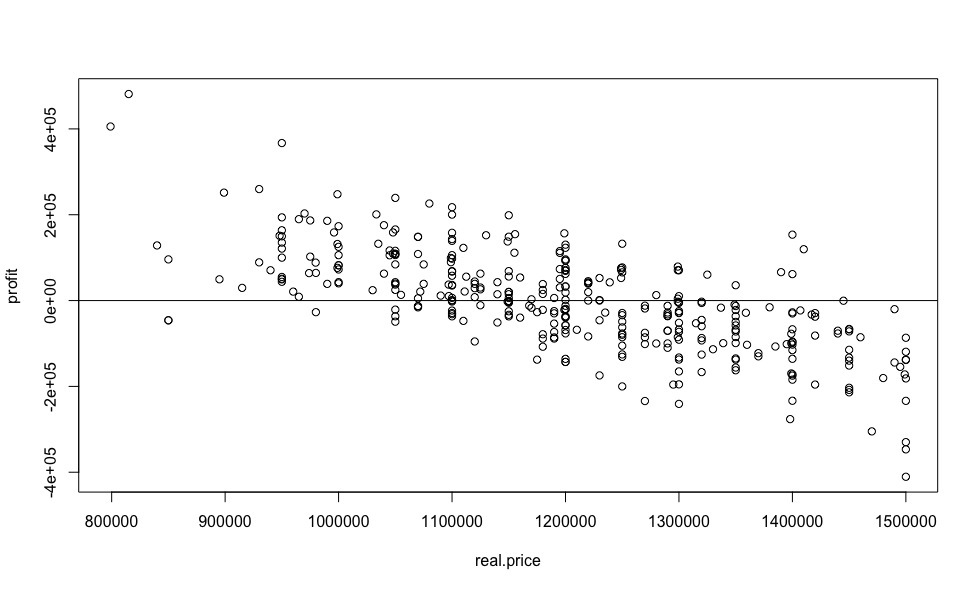
И на какую выгоду в процентном соотношении можно рассчитывать?
Да, экономия 59% это очень здорово, но весьма сомнительно, нужно смотреть авто «вживую», т.к. бесплатный сыр обычно в мышеловке, ну или продавцу срочно нужны деньги. А вот начиная с 4-го места (экономия 28%) и далее, результат кажется вполне реалистичным.
Хотелось бы обратить внимание, что коэффициенты линейной модели формируются по измерениям с исключенными выбросами, для уменьшения ошибки предиктивного анализа, в то время как, предсказываем цену мы для всех предложений на рынке, что несомненно увеличивает вероятность ошибки предсказания цены для выбросов (например, как в нашем случае, в выбросы могут попасть все машины с кузовом универсал, вследствие чего, поправка, которую должна вносит соответствующая индикаторная переменная, не учитывается), что является недостатком выбранной модели. Конечно, можно не предсказывать цену для предложений сильно отличающихся от общей выборки, но высока вероятность того, что среди них как раз и есть самые выгодные предложения.
Напоследок
Дорогие друзья, я сам, прочитав бы подобную статью задал бы в первую очередь 3 вопроса:
- Какая у модели точность?
- Почему выбрана простейшая линейная регрессия и где сравнение с другим моделями?
- А почему бы не сделать сервис для поиска выгодных автомобилей?
Поэтому отвечаю:
- Протестируем модель по схеме 80/20.split <- runif(dim(dat.we)[1]) > 0.2 # разделяем нашу выборку train <- dat.we[split,] # выборка для обучения test <- dat.we[!split,] # тестовая выборка train.model <- lm(price ~ year + mileage + diesel + hybrid + mt + front.drive + rear.drive + engine.power + sedan + hatchback + wagon + coupe + cabriolet + minivan + pickup, data = train) # линейная модель построенная по выборке для обучения predictions <- predict(train.model, test) # проверим точность на тестовой выборке print(sqrt(sum((as.vector(predictions - test$price))^2))/length(predictions)) # точность предсказания цены (в рублях) [1] 11866.34
Много это или мало - можно узнать только в сравнении. - Линейная регрессия, как один из азов машинного обучения позволяет не отвлекаться на изучение алгоритма, а полностью погрузиться в саму задачу.
Поэтому я решил разделить своё повествование на 2 (а там как пойдет) статьи.
В следующей статье речь пойдет о сравнении моделей для решения нашей задачи с целью выявления победителя. - По данной тематике был разработан сервис, в основе которого лежит модель-победитель, о которой речь пойдет в следующей статье.
И вот, что из этого получилось - Mercedes-Benz E-klasse не старше 2010 года выпуска, стоимостью до 1.5 млн. рублей в Москве.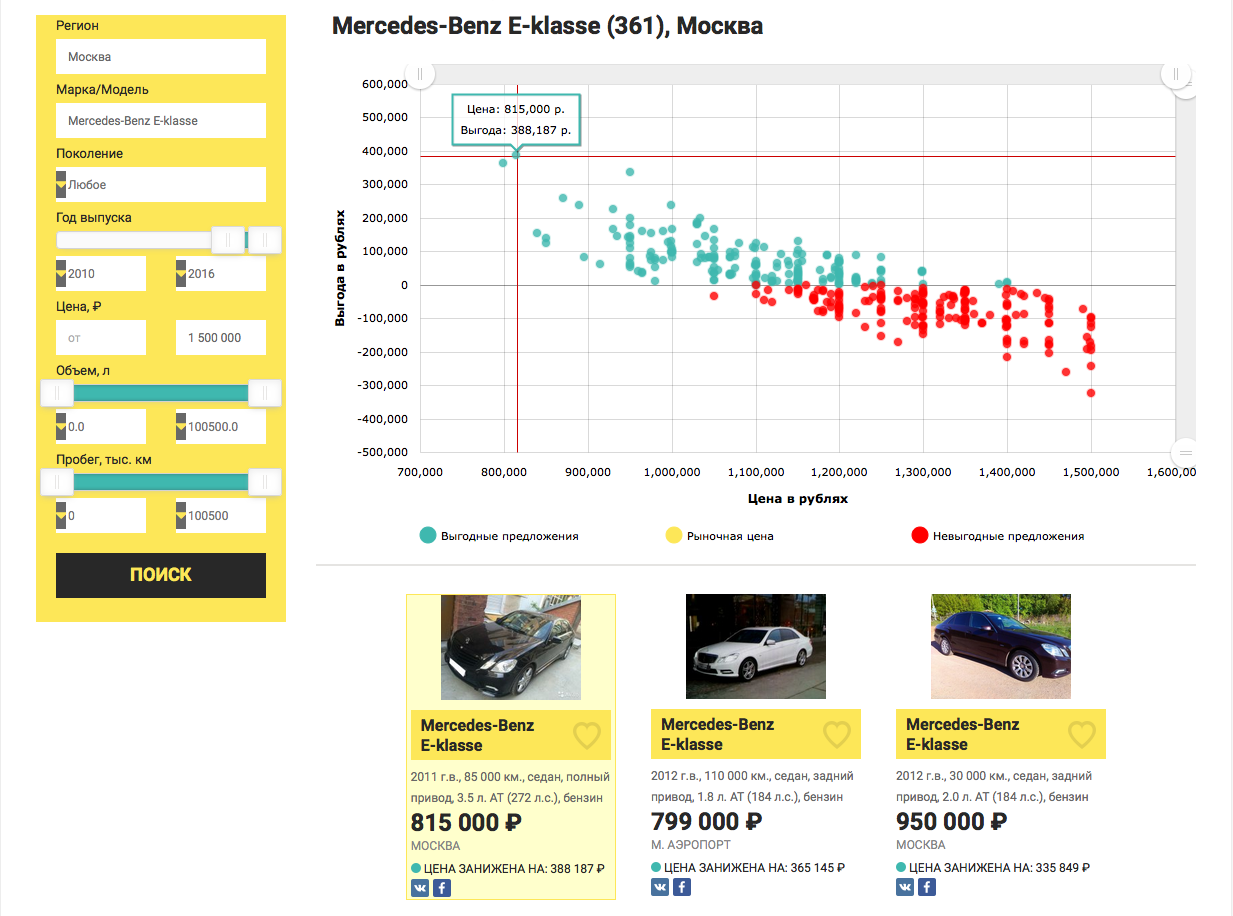
Телеграм: t.me/ainewsline
Источник: vk.com