Последние разработки в архитектурах LLM: совместное использование ключ-значение, mHC и сжатое внимание
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2026-05-18 11:04

От Gemma 4 до DeepSeek V4: как новые LLM-модели с открытыми весами снижают затраты на обработку длинных контекстов.
После небольшого семейного отдыха я рад вернуться и наверстать упущенное за последние несколько недель, посвященных релизам LLM с открытым исходным кодом. Больше всего меня впечатлило, насколько новые архитектуры ориентированы на эффективность в контексте длинных операций.
Поскольку модели рассуждений и рабочие процессы агентов удерживают все больше токенов (в течение более длительного времени), размер KV-кэша, объем памяти и стоимость внимания быстро становятся основными ограничениями, и разработчики LLM добавляют все больше архитектурных приемов для снижения этих затрат.
Основные примеры, которые я хочу рассмотреть, — это совместное использование ключ-значение и послойное встраивание в Gemma 4, послойное распределение внимания в Laguna XS.2, сжатое сверточное внимание в ZAYA1-8B и mHC плюс сжатое внимание в DeepSeek V4.
Большинство этих изменений на моих архитектурных схемах выглядят как небольшие корректировки, но некоторые из них представляют собой довольно сложные изменения в дизайне, заслуживающие более подробного обсуждения.
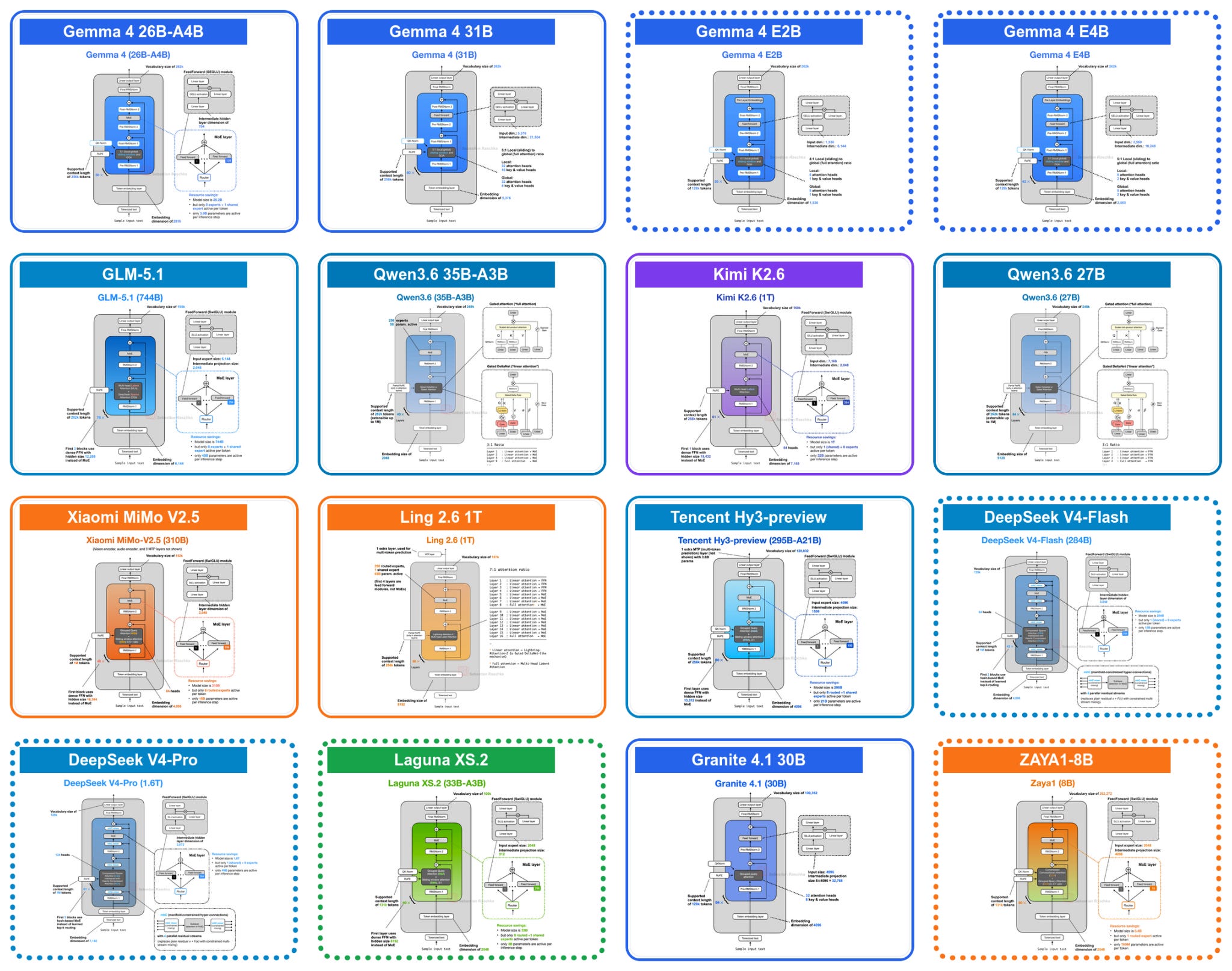
Рисунок 1. Архитектурные чертежи LLM последних крупных релизов с открытыми весами (апрель-май). Изображения и более подробная информация доступны в моей галерее архитектур LLM . Показаны не все размеры моделей; Qwen3.6 включает варианты 27B и 35B-A3B, а ZAYA1 представлена моделью 8B (без ZAYA1-base и ZAYA1-reasoning-base). Архитектуры, выделенные пунктирными рамками, более подробно описаны в этой статье.
Обратите внимание, что эта статья посвящена архитектурным решениям, поэтому я в основном пропущу разделение наборов данных, графики обучения, детали постобучения, алгоритмы обучения с подкреплением, таблицы бенчмарков и сравнения продуктов. Даже при таком узком охвате есть много чего обсудить. И, как всегда, статья получилась длиннее, чем я ожидал, поэтому я сосредоточусь на изменениях внутри блока трансформера, остаточного потока, кэша ключ-значение или вычисления механизма внимания.
Также обратите внимание, что я рассматриваю только те темы, которые представляют собой интересные (новые) дизайнерские решения и которые я еще нигде не освещал. В этот список входят:
Совместное использование ключ-значение и послойное встраивание в Gemma 4
Сжатое сверточное внимание в ZAYA1
Внимание к составлению бюджета в Лагуна XS.2
mHC и сжатое внимание в DeepSeek V4
Я также преобразовал несколько из этих объяснений в короткие, самостоятельные страницы с учебными материалами в Галерее архитектуры LLM . Например, читатели могут найти краткие пояснения к GQA, MLA, механизму внимания с скользящим окном, механизму разреженного внимания DeepSeek, маршрутизации MoE и другим концепциям, ссылки на которые можно найти на соответствующих карточках моделей и метках концепций.
1. Повторное использование тензоров ключ-значение в разных слоях для уменьшения размера кэша (Гемма 4)
В рамках этого обзора достижений и усовершенствований в архитектуре мы вернемся к началу апреля, когда Google выпустила свой новый набор моделей Gemma 4 с открытым исходным кодом. Они разделены на 3 основные категории:
Модели Gemma 4 E2B и E4B предназначены для мобильных и небольших локальных (встроенных) устройств (также известных как IoT).
Модель Gemma 4 26B, представляющая собой смесь экспертов (MoE), оптимизированная для эффективного локального вывода.
а также плотную модель Gemma 4 31B для максимального качества и более удобной постобработки (поскольку с поправками на ошибки работать сложнее).
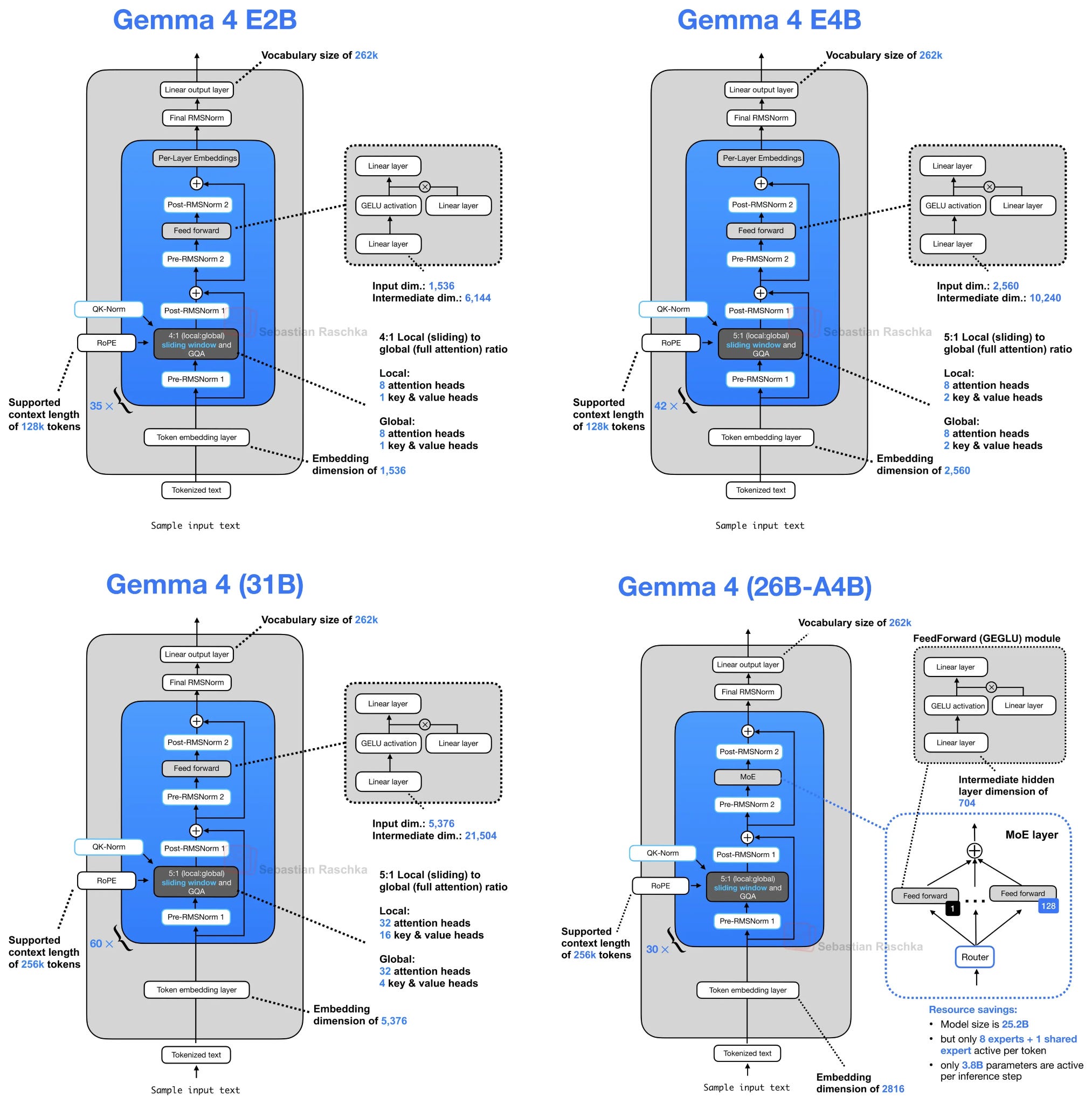
Рисунок 2: Архитектурные чертежи Gemma 4.
Первое небольшое изменение в архитектуре вариантов E2B и E4B заключается в использовании общей схемы кэширования ключ-значение, где последующие слои повторно используют состояния ключ-значение из предыдущих слоев для уменьшения объема памяти и вычислительных ресурсов, необходимых для обработки длительных контекстов.
Такое совместное использование ключ-значение не было изобретено в Gemma 4. Например, см. статью Брэндона и др. « Уменьшение размера кэша ключ-значение в трансформере с помощью межслойного внимания » (NeurIPS 2024). Но это первая популярная архитектура, где я увидел применение этой концепции. (Межслойное внимание не следует путать с межслойным вниманием .)
Прежде чем подробнее объяснить принцип совместного использования ключ-значение (KV-sharing), давайте кратко поговорим о мотивации. Как я писал и говорил в последние месяцы, одной из главных тем в проектировании архитектуры LLM является уменьшение размера KV-кэша. В свою очередь, мотивация уменьшения размера KV-кэша заключается в сокращении необходимого объема памяти, что позволяет нам работать с более длинными контекстами, что особенно актуально в эпоху моделей рассуждений и агентов. Для получения дополнительной информации о кэшировании KV см. мою статью «Понимание и кодирование KV-кэша в LLM с нуля»:
В качестве классического примера (который до сих пор используется в Gemma 4): алгоритм Grouped Query Attention (GQA) уже использует общие заголовки типа «ключ-значение» (KV) для разных заголовков запросов, чтобы уменьшить размер кэша KV, как показано на рисунке ниже.
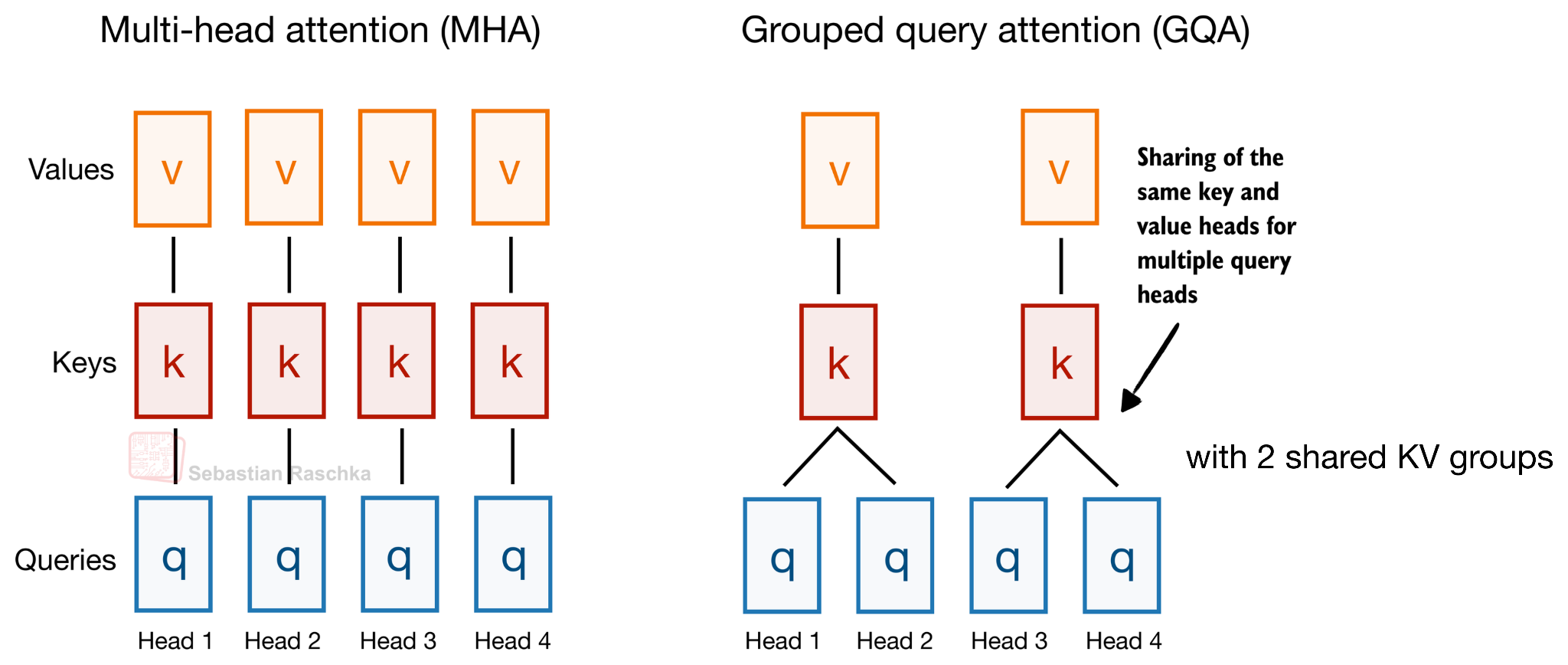
Рисунок 3: В алгоритме группового внимания к запросам (GQA) одни и те же заголовки ключа (K) и значения (V) используются несколькими заголовками запросов (Q).
Как уже упоминалось, Gemma 4 использует GQA. Однако, помимо совместного использования ключ-значение между запросами в рамках GQA, Gemma 4 также совместно использует проекции ключ-значение между различными слоями, вместо того чтобы вычислять их в рамках модуля внимания в каждом слое. Эта схема совместного использования ключ-значение, также называемая межслойным вниманием, показана на рисунке ниже.
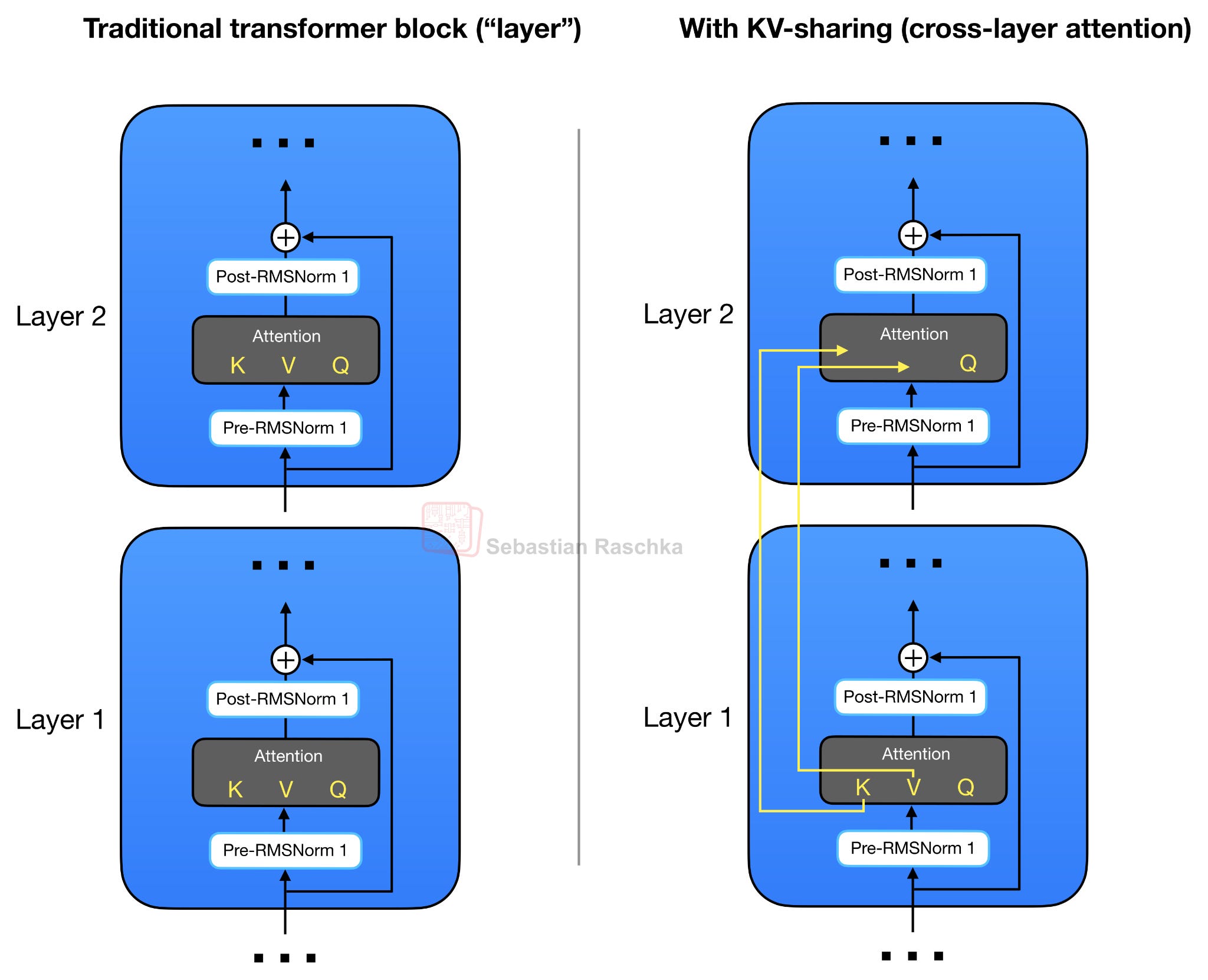
Рисунок 4: Обычные блоки трансформера вычисляют отдельные проекции Q, K и V в каждом модуле внимания (слева). Межслойные схемы внимания (справа) используют одни и те же проекции K и V на нескольких слоях.
Как кратко показано в обзоре архитектуры на рисунке 2, Gemma 4 E2B использует обычный GQA и механизм внимания со скользящим окном в соотношении 4:1. (Точнее, Gemma 4 E2B использует MQA, который является частным случаем GQA с одним KV-головком).
В случае GQA (или MQA) совместное использование ключ-значение работает следующим образом. Последующие слои больше не вычисляют собственные проекции ключа и значения, а повторно используют тензоры ключ-значение из самого последнего, более раннего, неразделяемого слоя того же типа внимания. Другими словами, слои со скользящим окном совместно используют ключ-значение с предыдущим слоем со скользящим окном. Слои с полным вниманием совместно используют ключ-значение с предыдущим слоем с полным вниманием. Слои по-прежнему вычисляют собственные проекции запроса, поэтому каждый слой может формировать свой собственный шаблон внимания, но дорогостоящий и ресурсоемкий кэш ключ-значение используется повторно в нескольких слоях.
Например, Gemma 4 E2B имеет 35 трансформерных слоев, но только первые 15 вычисляют свои собственные проекции KV; последние 20 слоев повторно используют тензоры KV из самого последнего, более раннего, неразделяемого слоя того же типа внимания. Аналогично, Gemma 4 E4B имеет 42 слоя, при этом 24 слоя вычисляют свои собственные KV, а последние 18 слоев разделяют их.
Насколько это действительно экономит ресурсы? Поскольку мы используем примерно половину ключ-значений для разных слоев, мы экономим примерно половину размера кэша ключ-значение. Для самой маленькой модели E2B это приводит к экономии 2,7 ГБ (при точности bfloat16) в контекстах с длиной 128 КБ, как показано ниже. (Для варианта E4B это экономит около 6 ГБ при 128 КБ.)
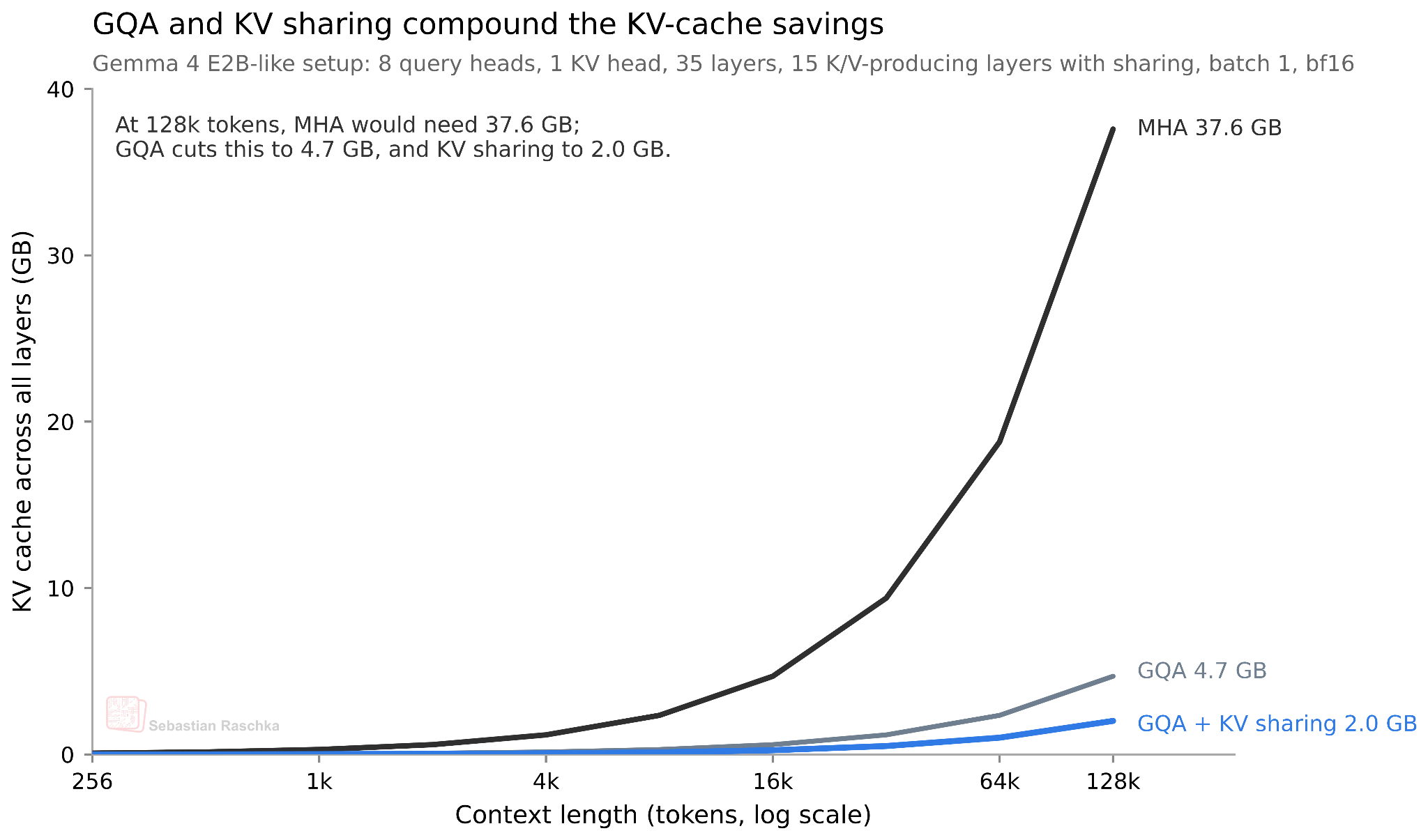
Рисунок 5: Экономия памяти в KV-кэше за счет GQA и межслойного совместного использования KV в конфигурации, аналогичной Gemma 4 E2B. Для простоты дополнительная экономия за счет внимания скользящего окна не показана.
Недостатком совместного использования ключ-значение, конечно же, является то, что это «приближение» к реальности. Или, точнее, это снижает возможности модели. Однако, согласно статье о межслойном внимании, влияние может быть минимальным (для небольших моделей, которые были протестированы).
2. Встраивание данных по слоям и «эффективный» размер (Gemma 4 E2B/E4B)
Варианты Gemma 4 E2B и E4B включают в себя второй вариант проектирования, ориентированный на повышение эффективности, называемый послойным встраиванием (PLE). Это отдельный вариант от описанной выше схемы совместного использования ключ-значение.
Совместное использование ключ-значение уменьшает размер кэша ключ-значение. PLE, напротив, ориентирован на эффективность параметров, позволяя небольшим моделям Gemma 4 использовать больше информации, специфичной для токенов, без того, чтобы основной стек трансформеров был таким же затратным, как у плотной модели с тем же общим количеством параметров.
Например, буква «E» в Джемме 4 E2B и E4B означает «эффективный». В частности, в Джемме 4 E2B указано 2,3 млрд эффективных параметров, или 5,1 млрд параметров с учетом вложений. (Аналогично, в Джемме 4 E4B указано 4,5 млрд эффективных параметров, или 8 млрд параметров с учетом вложений).
Вкратце, в моделях «E» вычислительная мощность основного стека трансформеров ближе к меньшему числу, тогда как большее число включает дополнительные слои таблиц встраивания. (Для иллюстрации принципа работы слоев встраивания см. мой блокнот кода « Понимание разницы между слоями встраивания и линейными слоями ».)
В концептуальном плане новый путь PLE выглядит следующим образом:
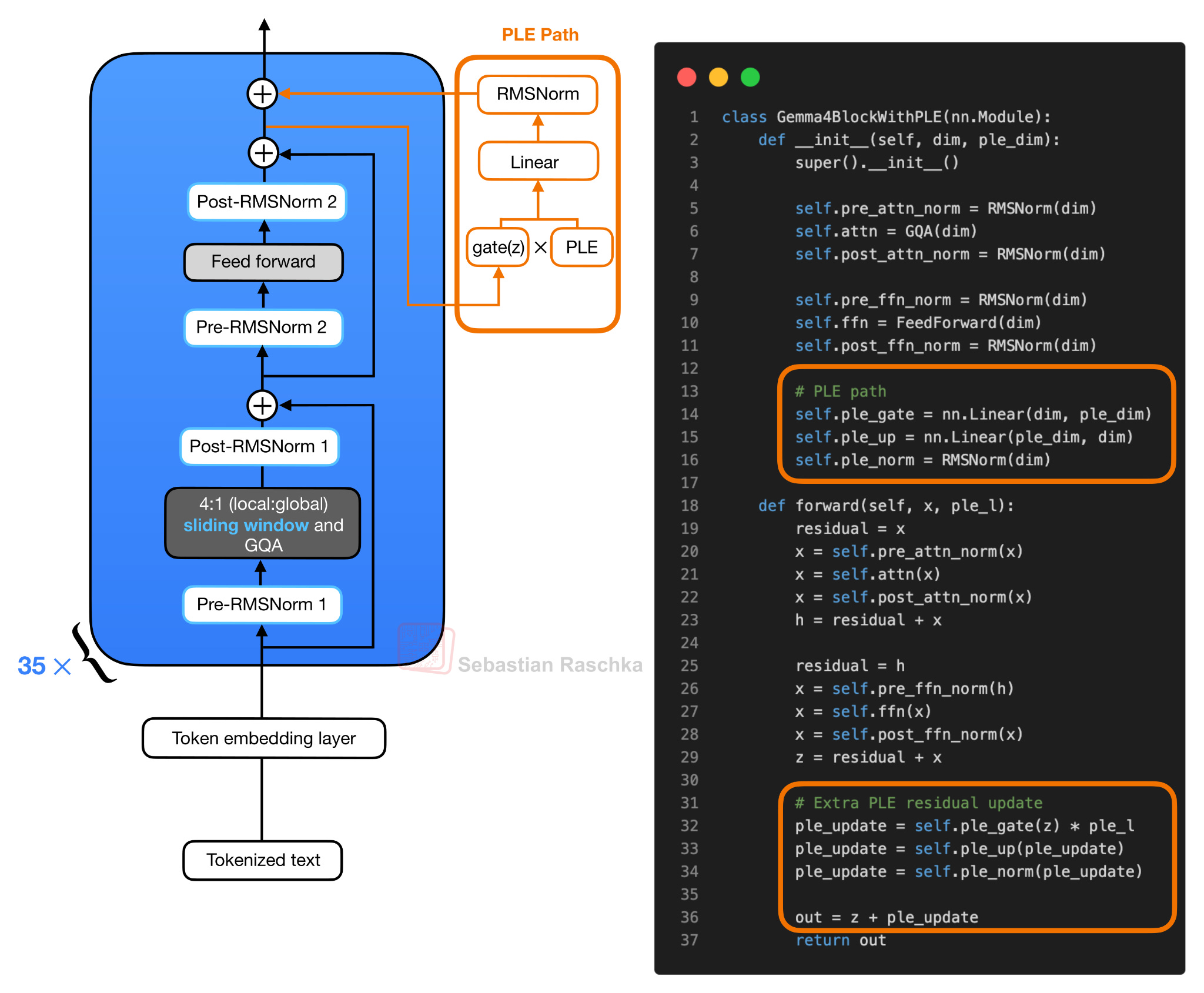
Рисунок 6: Упрощенный блок Gemma 4 с остаточным путем PLE. В обычном блоке сначала вычисляются обновления остаточных значений внимания и прямого распространения. Полученное скрытое состояние управляет вектором PLE, специфичным для слоя, а спроецированное обновление PLE добавляется в качестве дополнительного остаточного обновления в конце блока.
Сами векторы PLE подготавливаются вне повторяющихся блоков трансформера. В упрощенной форме, при построении PLE используются два входных параметра. Во-первых, идентификаторы токенов проходят поиск встраивания для каждого слоя. Во-вторых, обычные встраивания токенов проходят линейную проекцию в то же упакованное пространство PLE. Эти две части складываются, масштабируются и преобразуются в тензор с одним срезом на слой. Следует отметить, что каждый блок затем получает свой собственный срез.
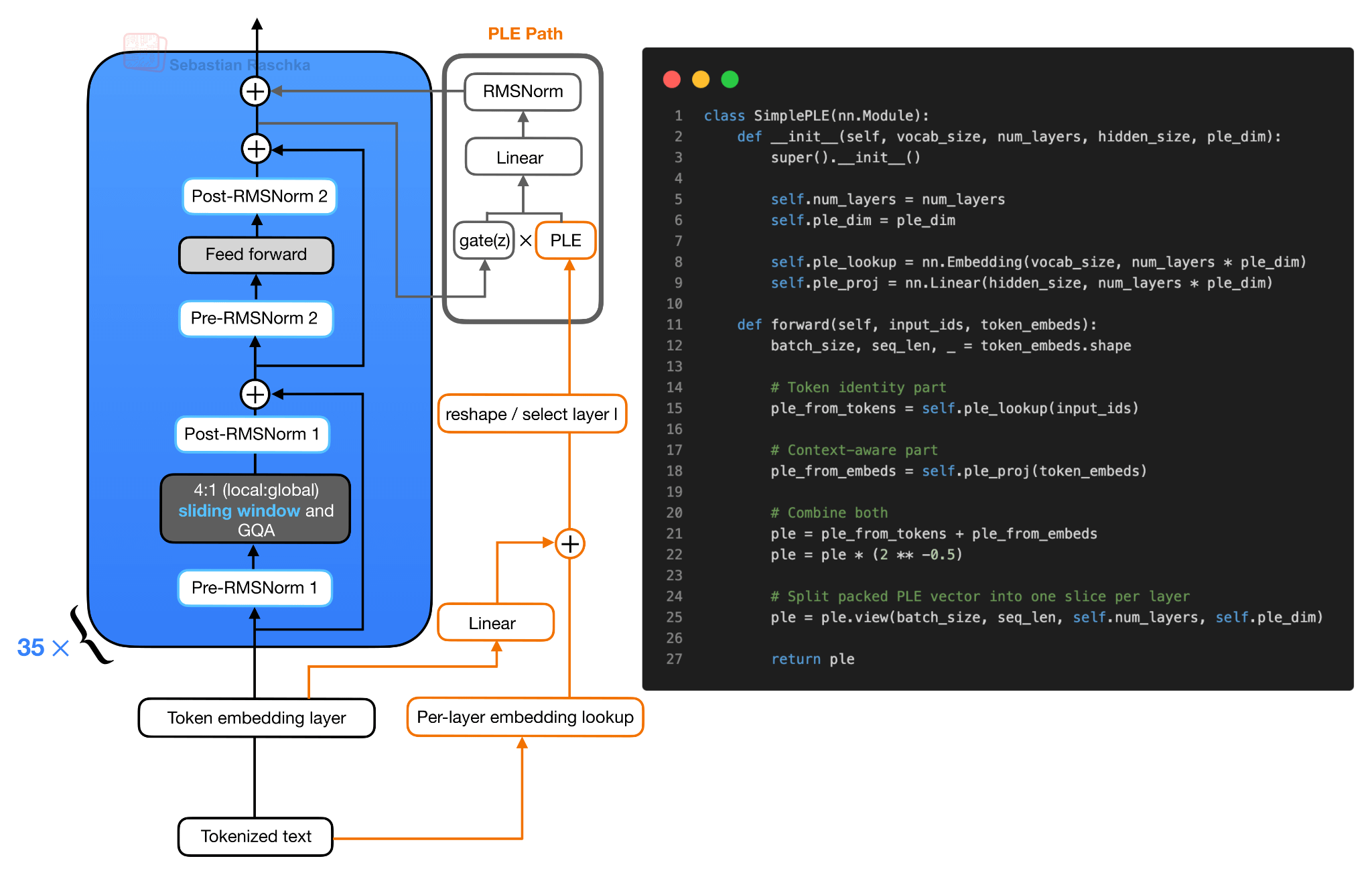
Рисунок 7: Упрощенная конструкция PLE. Идентификаторы токенов обеспечивают поиск векторных представлений для каждого слоя, в то время как обычные векторные представления токенов проецируются в то же пространство. Два компонента объединяются и преобразуются таким образом, чтобы каждый блок преобразователя получал свой собственный срез PLE, специфичный для каждого слоя.
Важная деталь заключается в том, что PLE не предоставляет каждому блоку трансформера полную независимую копию обычного слоя встраивания токенов. Вместо этого поиск встраивания для каждого слоя вычисляется один раз. Затем, как упоминалось ранее, каждому слою предоставляется небольшой фрагмент встраивания, специфичный для токена (с помощью команды «reshape / select layer l»).
Таким образом, для каждого входного токена Gemma 4 подготавливает упакованный тензор PLE, содержащий один небольшой вектор на каждый слой декодера. Затем, во время прямого прохода, слой l получает только свой собственный фрагмент (ple_l в Gemma4WithPLEBlock на рисунке 6).
Внутри блока трансформера обычные ветви внимания и прямого распространения работают как обычно. Сначала блок вычисляет остаточное обновление внимания. Затем он вычисляет остаточное обновление прямого распространения. После этого второго добавления остаточного значения полученное скрытое состояние, которое я обозначил как z в псевдокоде на рисунке 6, используется для управления вектором PLE, специфичным для слоя. Управляемый вектор PLE проецируется обратно на размер скрытого слоя модели, нормализуется и добавляется в качестве одного дополнительного остаточного обновления.
Таким образом, полезная ментальная модель заключается в том, что блок трансформера по-прежнему имеет тот же основной путь внимания и прямой связи, но Gemma 4 добавляет небольшой вектор токенов, специфичный для слоя, после ветви прямой связи. Это увеличивает репрезентативную емкость за счет параметров встраивания и небольших проекций. Это увеличивает вычислительные затраты, но позволяет избежать затрат на масштабирование всего стека трансформеров до большего количества параметров.
Но почему именно PLE? Более простой альтернативой было бы уменьшение размера плотной модели за счет использования меньшего количества слоев, более узких скрытых состояний или меньших сетей прямого распространения. Это уменьшило бы объем памяти и задержку, но также снизило бы производительность тех частей модели, которые выполняют основные вычисления.
В конструкции PLE дорогостоящие блоки преобразователя остаются ближе к меньшему «эффективному» размеру, при этом дополнительная емкость хранится в таблицах встраивания для каждого слоя. Их использование значительно дешевле, чем добавление дополнительных весов внимания или FFN, поскольку они представляют собой в основном параметры поиска, которые можно кэшировать.
Кроме того, нам приходится верить Google на слово, что это эффективное и стоящее дизайнерское решение. Было бы интересно увидеть сравнительные исследования, чтобы увидеть, как эта конструкция E2B соотносится с обычной моделью Gemma 4 2.3B и обычной моделью Gemma 4 5.1B.
Кроме того, в принципе, PLE не ограничивается только небольшими моделями. Мы могли бы добавлять фрагменты встраивания для каждого слоя и к более крупным моделям. Однако у крупных моделей уже достаточно ресурсов, поэтому дополнительные встраивания могут оказаться не слишком полезными. Также для крупных моделей мы уже используем конструкции MoE в качестве приема для увеличения производительности при сохранении меньшей вычислительной нагрузки.
Кстати, если вас интересует относительно простая и читаемая реализация кода, я реализовал модели Gemma 4 E2B и E4B с нуля здесь .
Рисунок 8: Снимок моей реализации Gemma 4, выполненной с нуля .
3. Послойное распределение внимания (Laguna XS.2)
Laguna — это первая модель с открытыми весами от Poolside , европейской компании, специализирующейся на обучении магистров права для работы в сфере программирования. Несколько моих бывших коллег присоединились к Poolside в последние годы, и у них отличная команда с большим количеством талантливых специалистов. Приятно видеть, что все больше компаний также выпускают свои модели в виде вариантов с открытыми весами.
В любом случае, архитектура Laguna XS.2, изображенная ниже, на первый взгляд выглядит очень стандартно. Однако одна деталь, которую я не показал (или не попытался втиснуть туда), — это концепция, которую мы можем назвать «послойным распределением внимания».
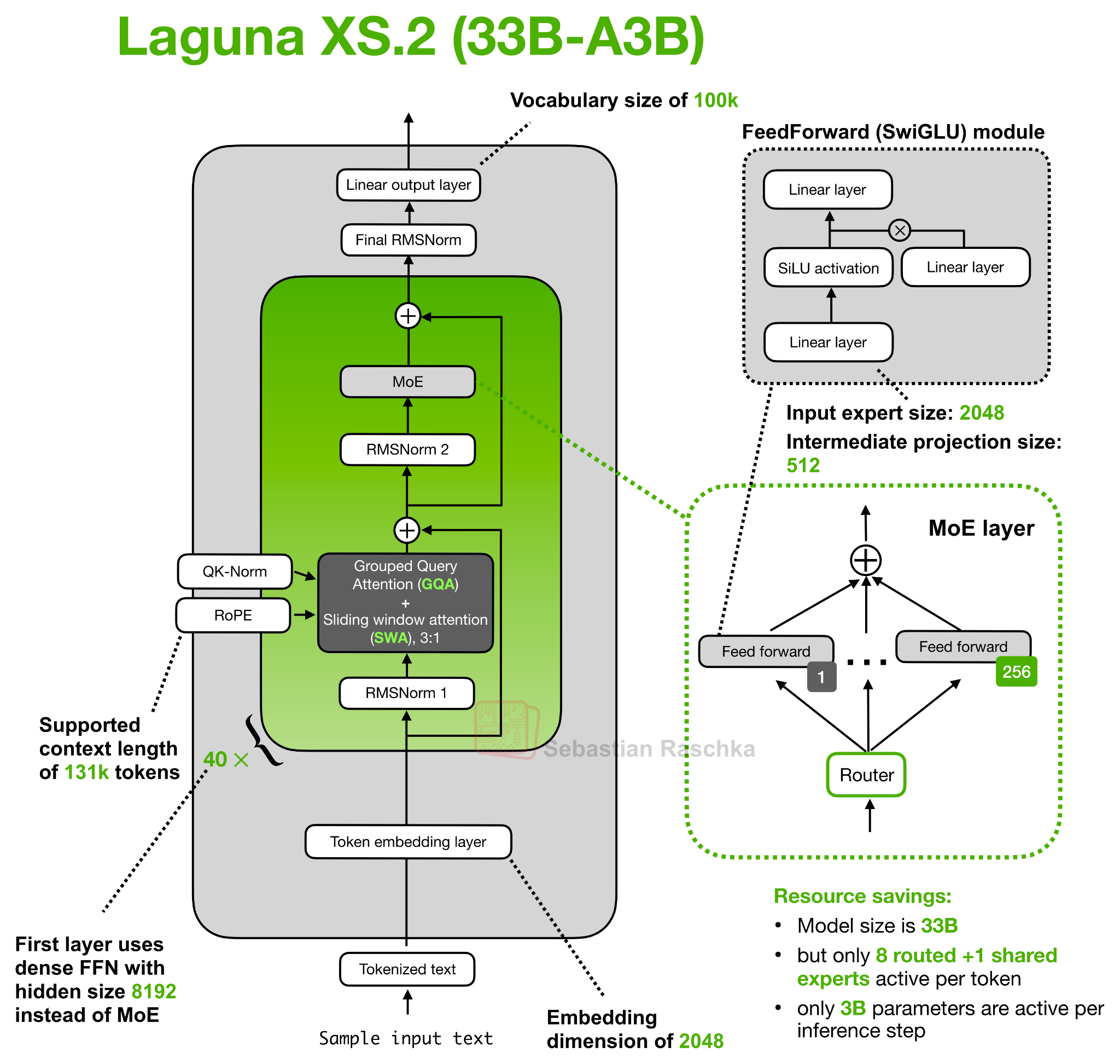
Рисунок 9: Архитектура бассейна Laguna XS.2.
Одна из идей, лежащих в основе распределения внимания, заключается в том, что вместо того, чтобы выделять каждому слою трансформера одинаковый полный бюджет внимания, Laguna XS.2 варьирует стоимость внимания для каждого слоя. Всего в ней 40 слоев: 30 слоев с скользящим окном и 10 глобальных/полных слоев внимания. Как обычно, слои с скользящим окном обрабатывают только локальное окно (здесь: 512 токенов), что снижает затраты на кэш ключ-значение и вычисления внимания. Глобальные слои обходятся дороже, но сохраняют возможность доступа ко всей информации в контекстном окне.
Этот комбинированный шаблон, сочетающий скользящее окно и глобальное/полное внимание, не является уникальным для Laguna XS.2 и используется во многих других архитектурах (включая Gemma 4).
Но новшеством является использование количества запросов к каждому слою. Например, в файле config.json центра обработки моделей Hugging Face есть num_attention_heads_per_layerнастройка, позволяющая слоям иметь разное количество запросов к кэшу ключ-значение, сохраняя при этом совместимость с размерами кэша ключ-значение.
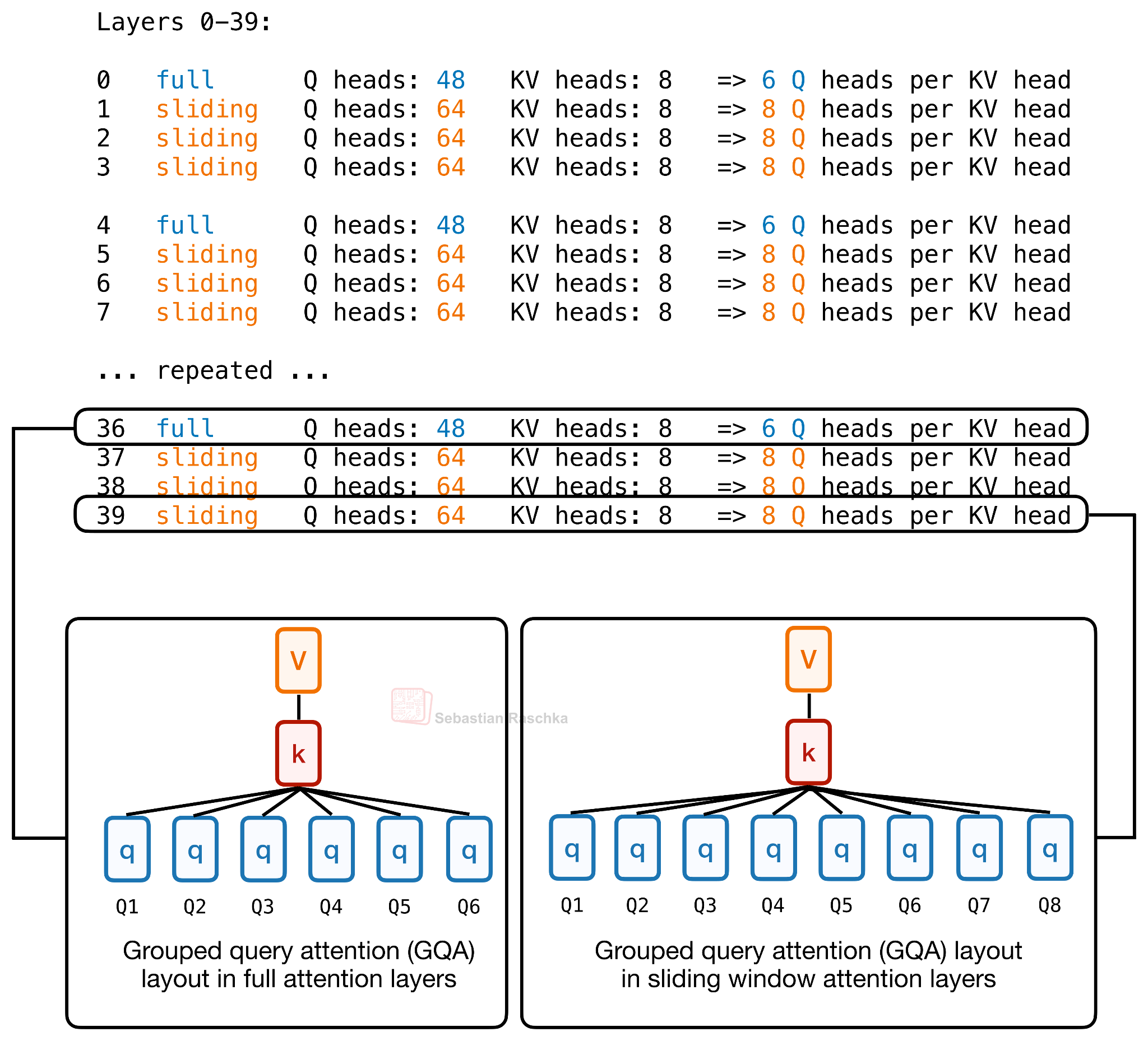
Рисунок 10: Распределение запросов по слоям в Laguna, где полные слои внимания используют 6 запросов на каждый KV-слой, а слои внимания со скользящим окном используют 8 запросов на каждый KV-слой.
Таким образом, Laguna XS.2 выделяет больше запросов слоям со скользящим окном и меньше запросов глобальным слоям, сохраняя при этом фиксированное количество запросов ключ-значение на уровне 8. Это фактическое распределение запросов по слоям, заданное в конфигурации.
Laguna XS.2 — один из наиболее ярких недавних примеров такого распределения ресурсов запросов по слоям в открытой модели, используемой в производственных условиях. Но более широкая идея изменения пропускной способности модели по слоям восходит (по крайней мере) к презентации Apple OpenELM 2024 года .
И снова, в чем смысл такой конструкции? Подобно механизму совместного использования ключ-значение, смысл заключается в том, чтобы распределять ресурсы внимания там, где они наиболее полезны, вместо того, чтобы выделять каждому слою одинаковый бюджет. В частности, слои с полным вниманием обходятся дорого, потому что они анализируют весь контекст, поэтому Laguna выделяет им меньше запросов по сравнению с модулями внимания со скользящим окном.
(Кроме того, еще одна небольшая деталь реализации заключается в том, что Laguna также применяет механизм управления вниманием для каждого отдельного элемента; это чем-то похоже на Qwen3-Next и другие алгоритмы, что я также опускаю здесь, поскольку рассматривал это в предыдущих статьях.)
4. Сжатое сверточное внимание (ZAYA1-8B)
Подобно Laguna, ZAYA1-8B — ещё один новый игрок на рынке моделей с открытыми весами. Он разработан компанией Zyphra , и одной из интересных особенностей релиза является то, что модель обучалась на графических процессорах AMD, а не на более распространённых графических процессорах NVIDIA (или Google TPU).
Однако главной архитектурной деталью является сжатое сверточное внимание (CCA), используемое совместно с вниманием, основанным на групповых запросах. В отличие от конструкций в стиле MLA, которые в основном используют скрытое представление в качестве компактного формата кэша ключ-значение, CCA выполняет операцию внимания непосредственно в сжатом скрытом пространстве, но об этом позже.
(Примечание: в файле config.json модуля ZAYA1-8B указано 80 чередующихся записей слоев, а не 40 обычных блоков трансформеров. Эти записи чередуются между слоями внимания CCA/GQA и слоями прямого распространения MoE. Но для схемы архитектуры удобнее представить это как 40 повторяющихся пар «внимание + MoE», что концептуально эквивалентно.)
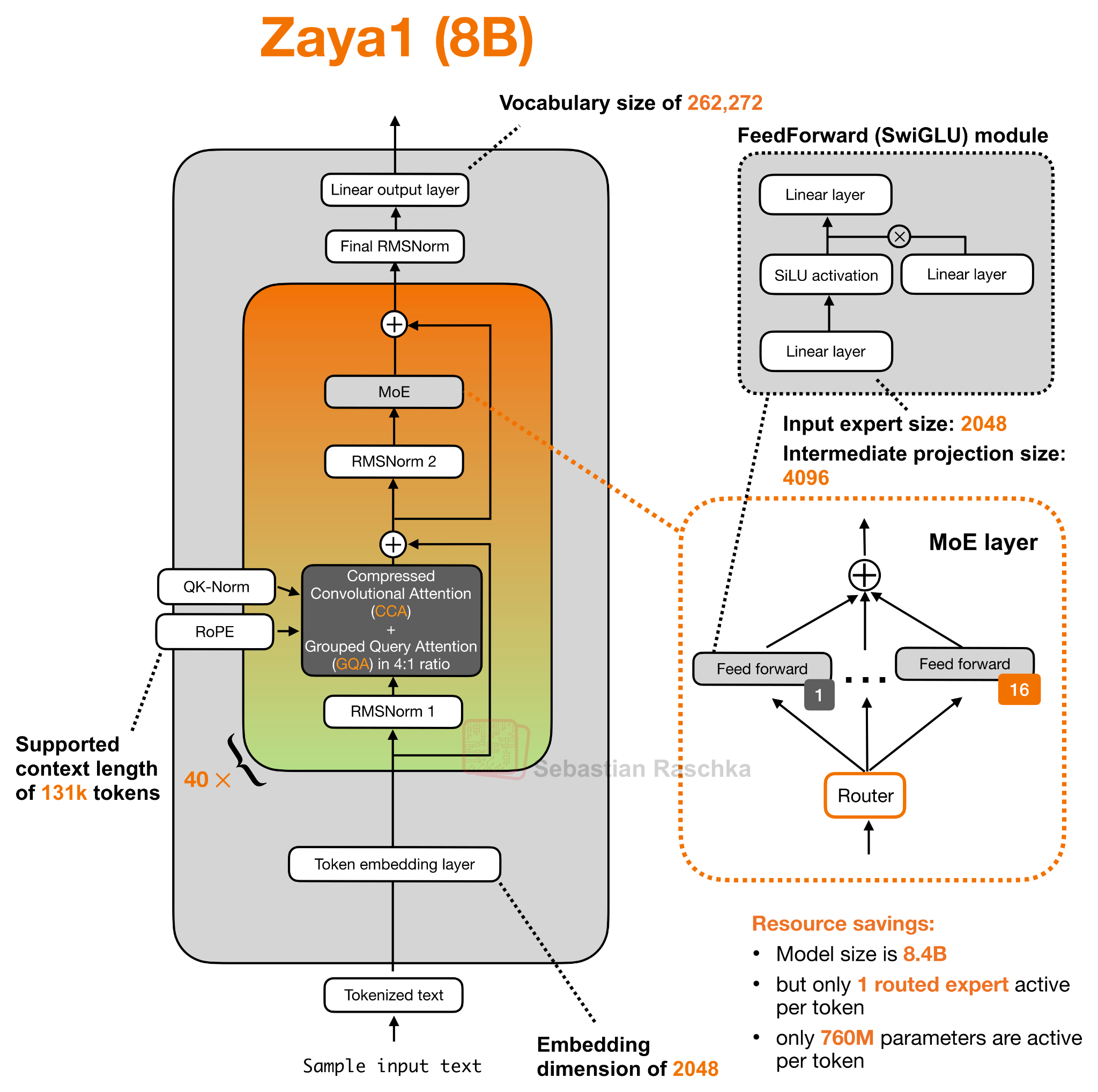
Рисунок 11: Zaya1 (8B) с блоками трансформера, использующими сжатое сверточное внимание.
Как показано на рисунке выше, ZAYA1-8B использует сжатое сверточное внимание (CCA) в сочетании с компоновкой GQA 4:1. Ключевой момент заключается в том, что его блок внимания построен на основе CCA, а не стандартного блока внимания со скользящим окном.
Что такое сжатое сверточное внимание?
Я бы сказал, что CCA по духу похож на многоголовочный механизм скрытого внимания (MLA) в моделях DeepSeek, поскольку оба вводят сжатое скрытое представление в блок внимания. Однако они используют это скрытое пространство по-разному. MLA в основном использует скрытое представление для уменьшения кэша ключ-значение. В MLA тензоры ключ-значение хранятся компактно, а затем проецируются в пространство головки внимания для фактического вычисления внимания.
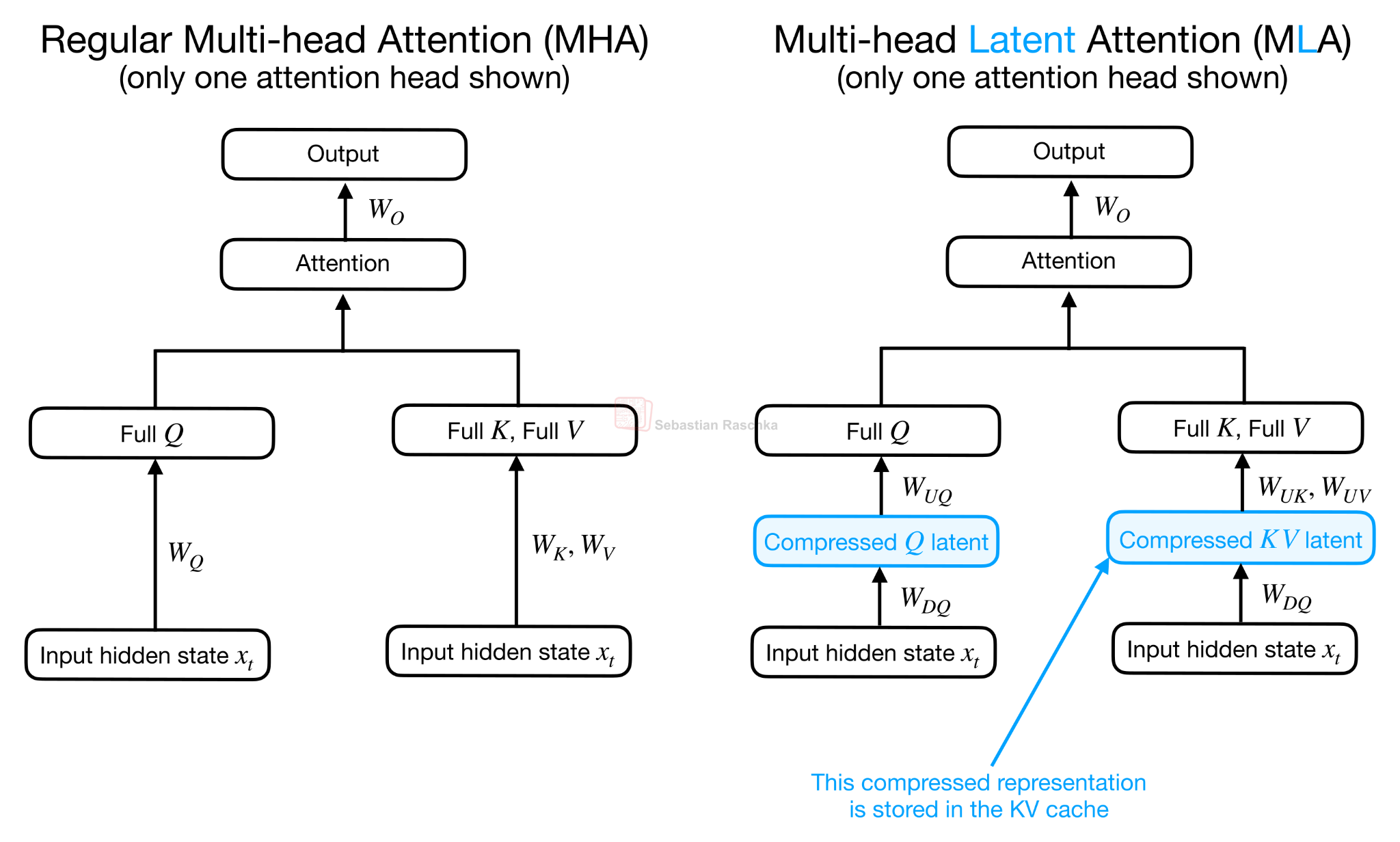
Рисунок 12: Обычное многоголовочное внимание (MHA) и многоголовочное латентное внимание (MLA) показаны рядом.
CCA сжимает Q, K и V и выполняет операцию внимания непосредственно в сжатом латентном пространстве. Именно поэтому CCA может уменьшить не только размер KV-кэша, но и количество операций с плавающей запятой (FLOP) для внимания во время предварительного заполнения и обучения.
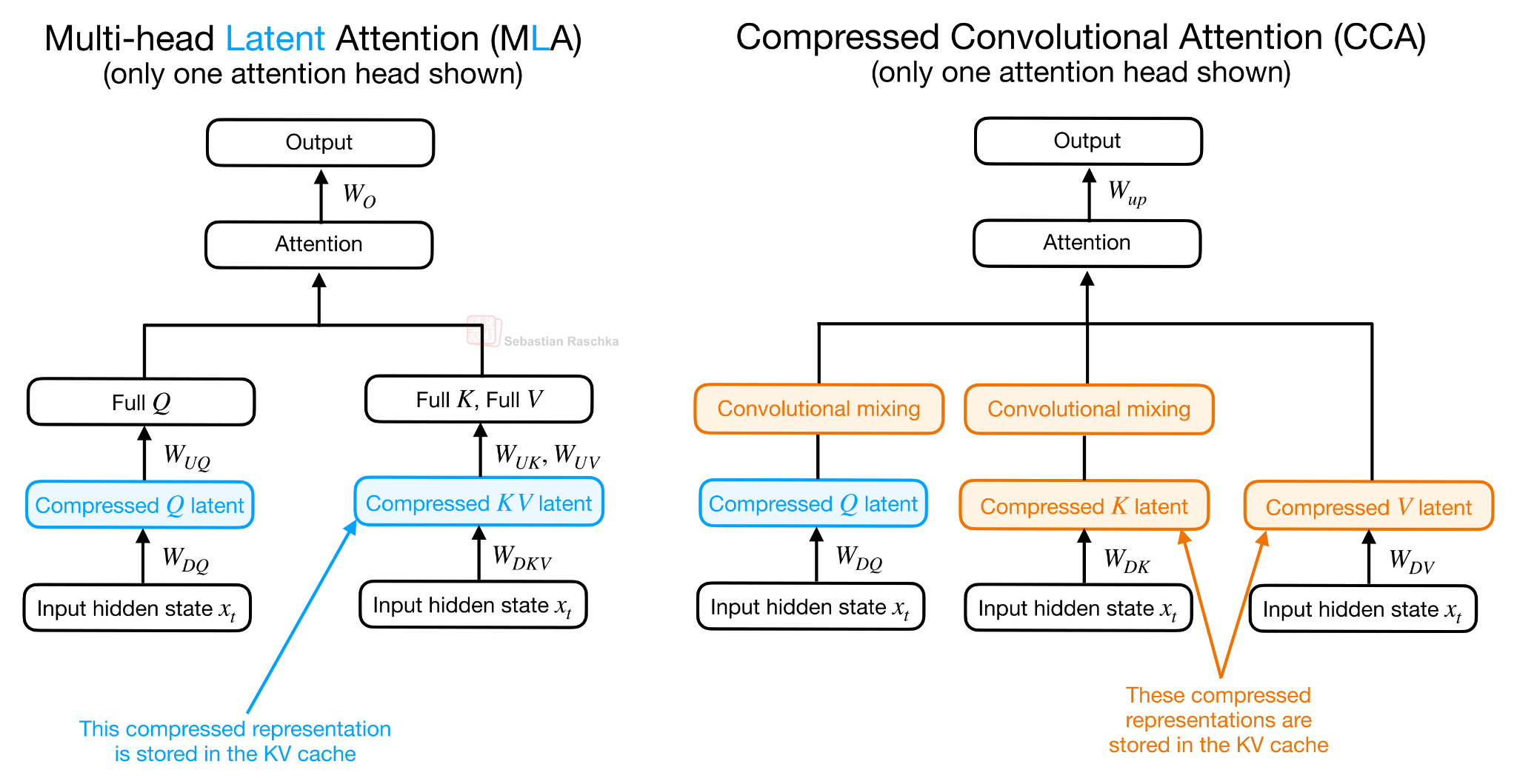
Рисунок 13: Многоголовочная латентная система внимания (MLA) и сжатая сверточная система внимания (CCA) показаны рядом.
Как показано на рисунке 13 выше, в CCA сжатые, скрытые представления поступают непосредственно в механизм внимания, а результирующий сжатый вектор внимания затем проецируется вверх.
Обратите внимание, что это называется сжатым сверточным вниманием, а не просто сжатым вниманием, поскольку происходит дополнительное сверточное смешивание скрытых представлений K и Q. Часть, отвечающая за сверточное смешивание, не показана на рисунке 12, поскольку она была бы слишком перегружена, но она относительно проста.
Как показано на рисунке 12, сверточное смешивание происходит непосредственно на сжатых тензорах Q и K. Суть в том, что сжатие делает Q, K и V уже, что экономит вычислительные ресурсы и кэш, но также может снизить выразительность механизма внимания. Свертки — это недорогой способ придать сжатым векторам Q и K больше локального контекста перед их использованием для вычисления оценок внимания. (Сверточное смешивание применяется только к Q и K, а не к V, поскольку Q и K определяют оценки внимания, а V представляет собой контент, который усредняется по этим оценкам).
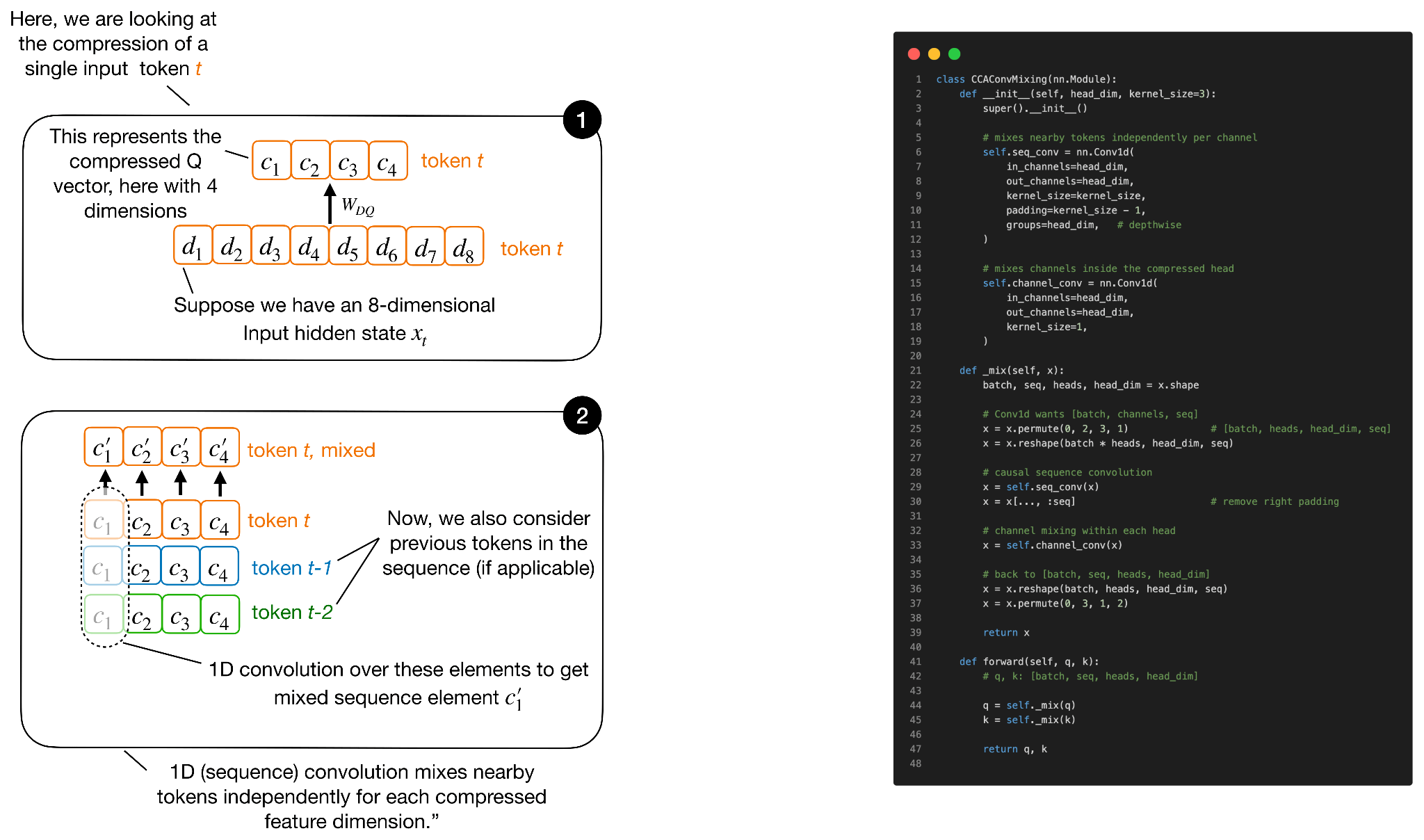
Рисунок 14: концептуальный обзор свертки смешивания последовательностей.
Помимо смешивания последовательностей, показанного на рисунке 13, присутствует также компонент смешивания каналов. В принципе, он похож, поэтому я не буду показывать иллюстрацию.
CCA, по-видимому, представляет собой механизм внимания, предложенный компанией Zyphra, и существовал до технического отчета ZAYA1-8B . Отдельная статья о CCA, «Сжатое сверточное внимание: эффективное внимание в сжатом латентном пространстве» , была впервые опубликована в октябре 2025 года и явно описывает CCA. Затем ZAYA1-8B использует этот механизм в качестве одного из основных элементов.
Но вопрос в том, «лучше ли это, чем MLA»? Согласно собственным экспериментам CCA, да, они сообщают о превосходстве CCA над MLA при сопоставимых настройках сжатия.
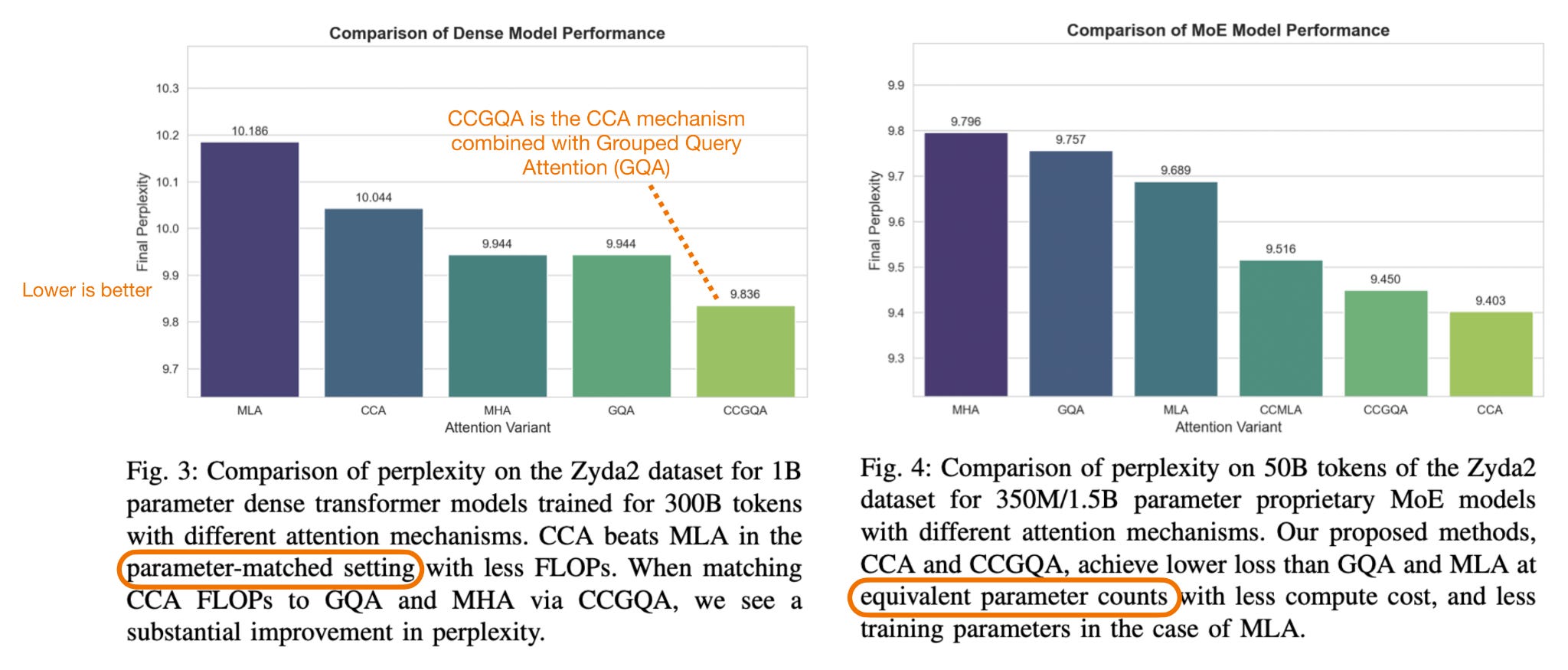
Рисунок 15: Аннотированные рисунки из статьи CCA, https://arxiv.org/abs/2510.04476 .
В целом, интересная часть здесь — это действительно новый механизм внимания. Модель также использует довольно экстремальную (= очень разреженную) конфигурацию MoE, с активным только одним маршрутизируемым экспертом на каждый токен, но эта часть более знакома. CCA более необычна, потому что она выполняет операцию внимания непосредственно в сжатом латентном пространстве, а затем использует сверточное смешивание на сжатых представлениях Q и K, чтобы сделать это сжатое внимание менее ограничивающим. Таким образом, вкратце, ZAYA1-8B пытается сэкономить вычислительные ресурсы не только в прямых слоях, но и в самом механизме внимания.
5. CSA/HCA, mHC и кэш сжатого внимания (DeepSeek V4)
DeepSeek V4 стал самым масштабным релизом года на данный момент, как с точки зрения ажиотажа, так и размера модели. Интересно, что DeepSeek V4-Pro также является моделью с наименьшим количеством параметров среди представленных в таблице ниже, если судить по доле активных параметров, как показано в таблице ниже.
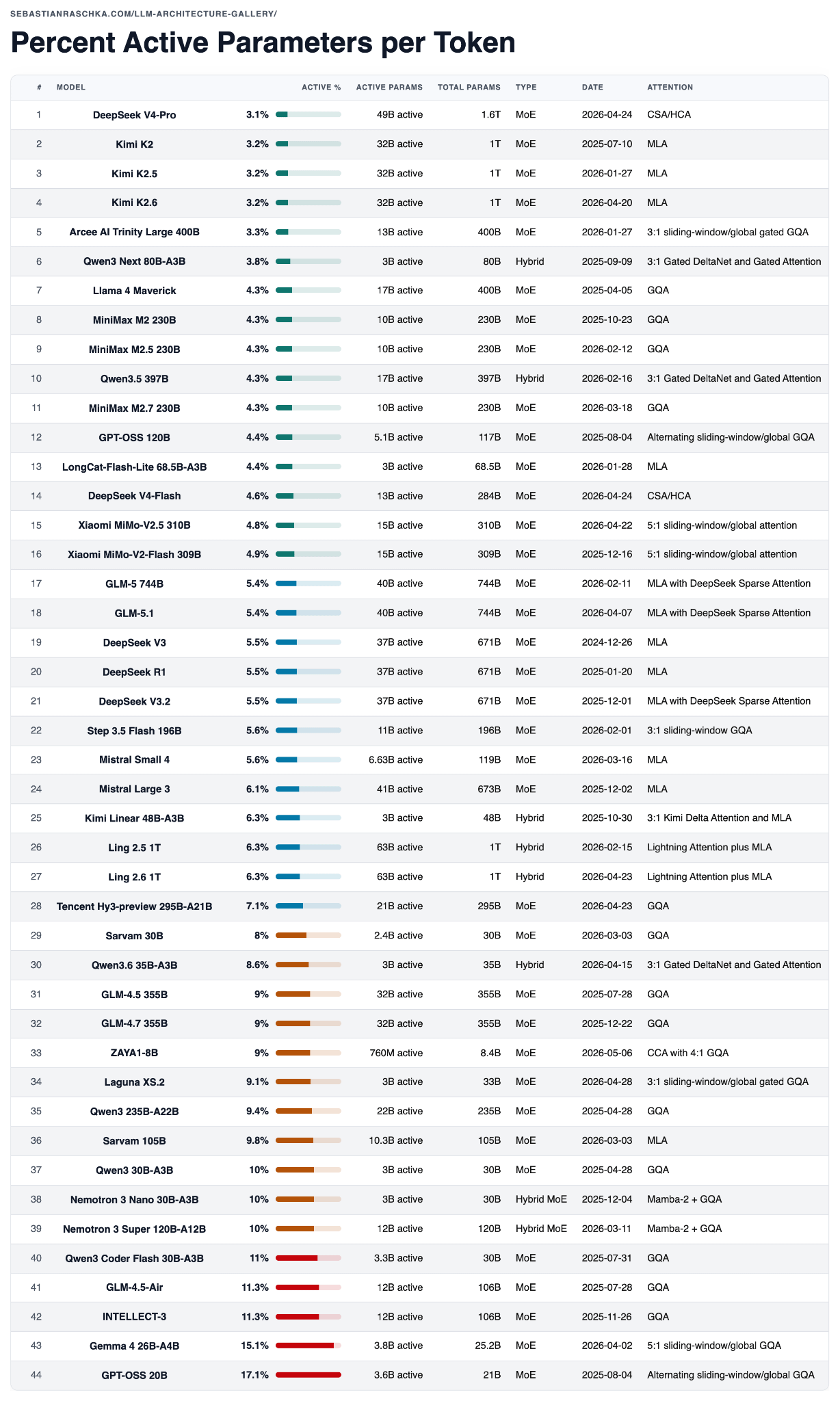
Рисунок 16: График процентного содержания активных параметров для моделей MoE. HTML-версию можно найти по адресу https://sebastianraschka.com/llm-architecture-gallery/active-parameter-ratio/ .
Предостережение: активное совместное использование параметров — это лишь один из способов анализа. Он не учитывает размер кэша ключ-значение, схему внимания, длину контекста, накладные расходы на маршрутизацию, эффективность оборудования или качество обучения. Но это полезная и быстрая проверка при сравнении разреженных моделей.
О DeepSeek V4 можно много чего сказать, но поскольку об этом уже много говорили в новостях, и чтобы не отходить от темы архитектурных изменений, я сосредоточусь на двух наиболее важных новых элементах по сравнению с предыдущими архитектурами:
mHC для более широкого остаточного пути,
CSA/HCA для сжатия внимания в длительном контексте и обеспечения разреженности
Глядя на приведенную ниже архитектуру DeepSeek V4, кажется, что здесь происходит много всего. Наиболее удобный способ интерпретации — это разделение изменений остаточного пути (mHC) от изменений пути внимания (CSA/HCA) и сжатых кэшей внимания.
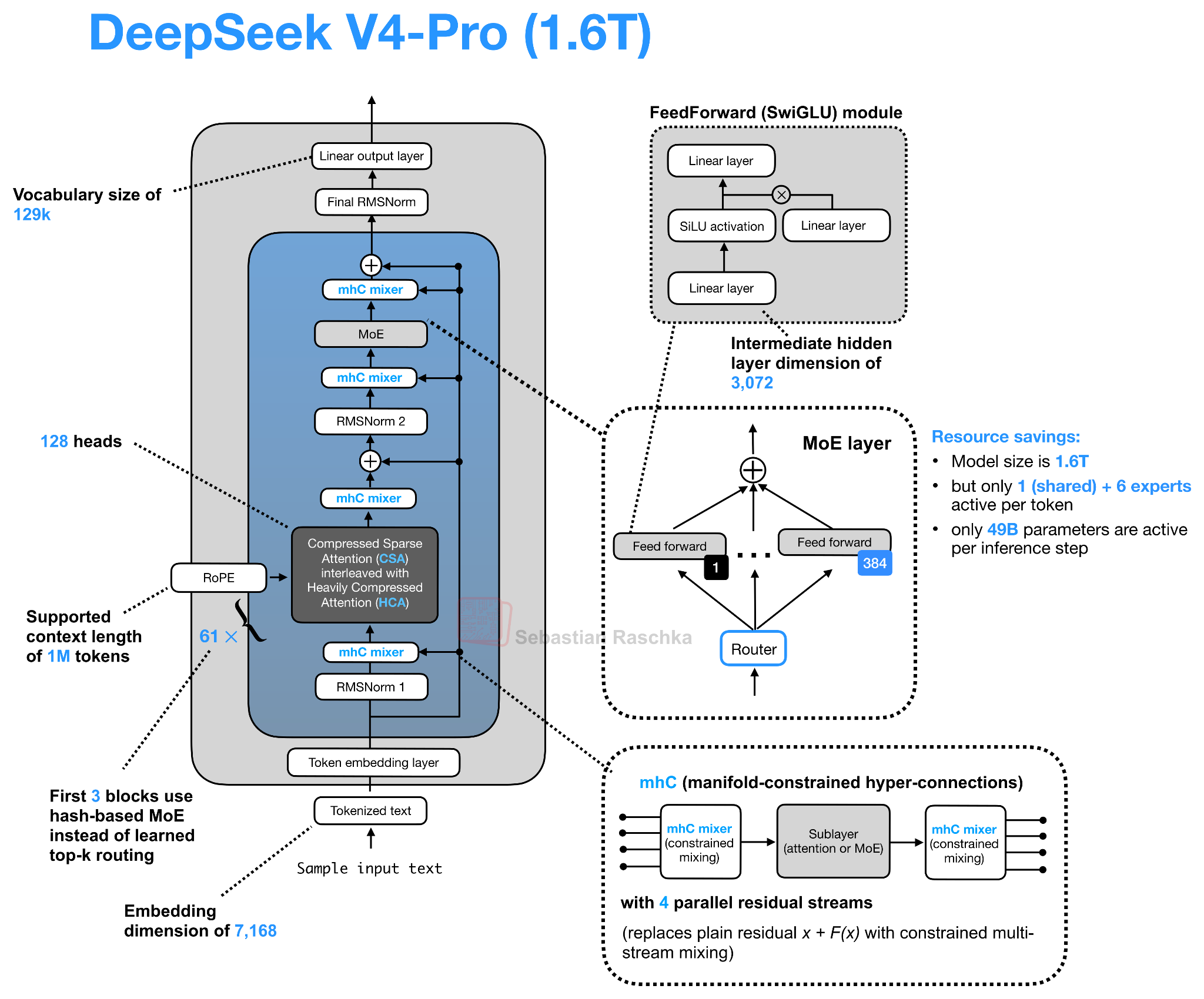
Рисунок 17: Общий вид архитектуры DeepSeek V4-Pro.
5.1 Гиперсвязи с ограничениями на уровне многообразий (mHC)
Начнём с компонента mHC в DeepSeek V4. Он восходит к исследовательской работе, которой команда DeepSeek поделилась в прошлом году (31 декабря 2025 г., mHC: Manifold-Constrained Hyper-Connections ). Однако в этой работе метод тестировался только на экспериментальной модели масштаба 27B. Теперь мы видим его в их флагманской версии, что является хорошим признаком того, что эта идея действительно хорошо работает в производственной среде.
Основная идея mHC заключается в модернизации конструкции остаточных соединений внутри трансформаторного блока, что является позитивным моментом, поскольку изменения архитектуры обычно сосредоточены на механизме внимания, размещении слоя нормализации и компонентах MoE.
Теперь mHC основан на предыдущих работах по гиперсвязям (см. «Гиперсвязи» Чжу и др., 2024), которые следует кратко обсудить в первую очередь. Гиперсвязи, по сути, модифицируют единый остаточный поток внутри блока трансформатора, заменяя его несколькими параллельными остаточными потоками и обученными отображениями между ними.
(Для тех, кто впервые сталкивается с остаточными связями, скажу, что много лет назад я снял видео об остаточных нейронных сетях, где объяснил общий механизм их работы.)
Идея гиперсвязей заключается в расширении остаточного потока. Можно представить это как сохранение нескольких параллельных остаточных потоков с дополнительным линейным преобразованием Res Mapping, которое смешивает их между слоями. Поскольку сам слой Attention или MoE по-прежнему работает с обычным размером скрытого слоя, гиперсвязи также добавляют Pre Mapping, который объединяет параллельные остаточные потоки в один обычный вектор скрытого слоя для слоя, и Post Mapping, который распределяет выходные данные слоя обратно по параллельным остаточным потокам. Это наглядно показано на рисунке ниже.
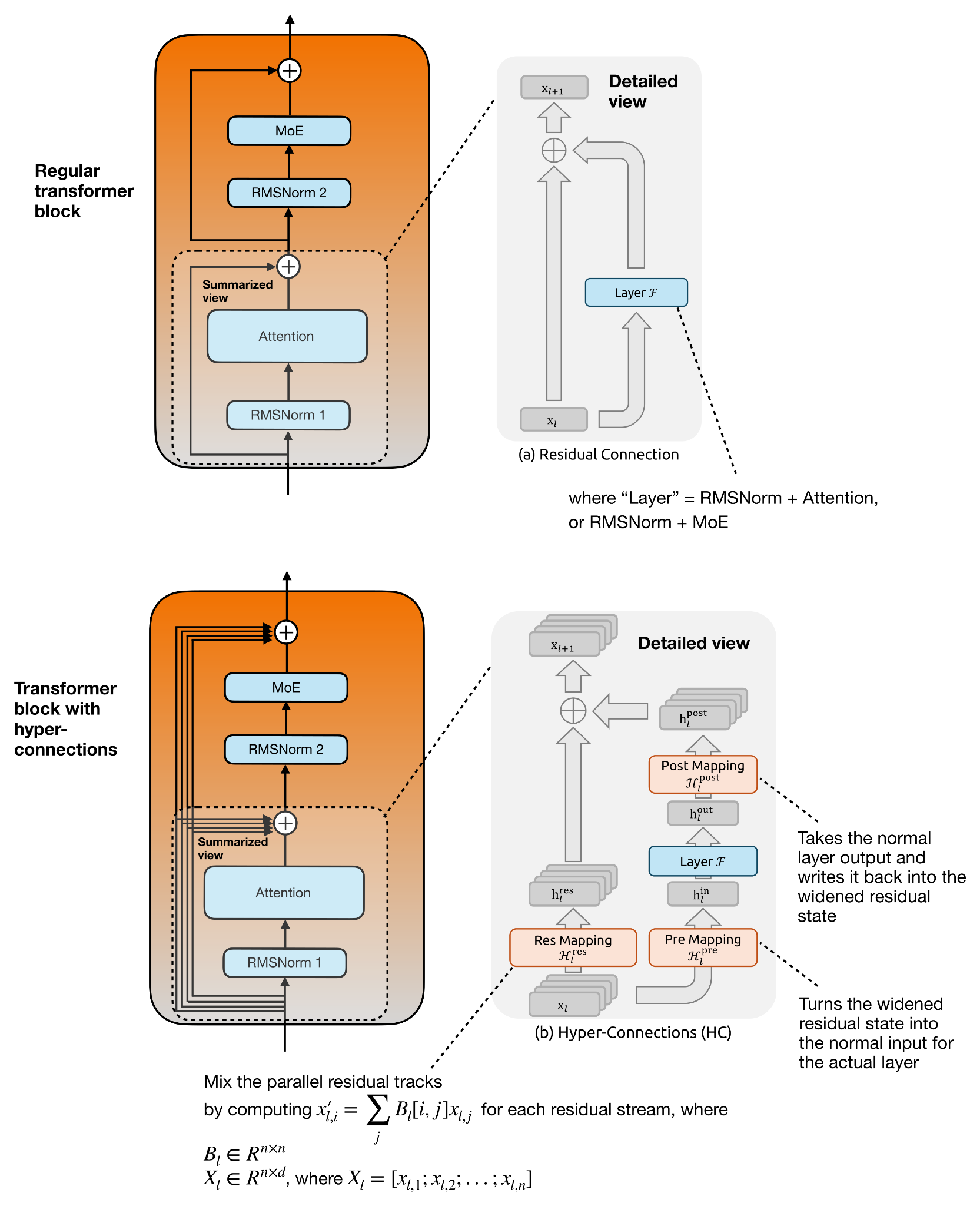
Рисунок 18: Обычный блок трансформатора (сверху) против блока трансформатора с гиперсвязями (снизу), с использованием аннотированных рисунков из статьи mHC, https://arxiv.org/abs/2512.24880 .
На рисунке ниже основное внимание уделено части блока преобразователя, отвечающей за слой внимания, но тот же принцип применим и ко второй остаточной ветви вокруг слоя MoE.
Цель гиперссылок — сделать остаточный путь более выразительным, не увеличивая при этом ширину фактического слоя внимания или слоя MoE. Это лишь незначительно увеличивает затраты в операциях с плавающей запятой, поскольку дополнительные отображения работают по небольшой оси остаточного потока, например, n = 4 в DeepSeek V4, а не по огромному скрытому измерению.
В оригинальной статье о гиперсвязях в эксперименте 7B OLMo MoE производительность увеличилась с 13,36 Гбит/с до 13,38 Гбит/с на токен, что практически не изменилось. Что касается заявленных улучшений, то наблюдались умеренные (но стабильные) показатели, как показано на рисунке ниже.
(Однако рассматривать только операции с плавающей запятой несколько упрощенно. Расширенное остаточное состояние все равно необходимо хранить, перемещать по памяти, перемешивать и т. д. Поэтому практические накладные расходы могут быть связаны скорее с трафиком в памяти и сложностью реализации, чем с арифметическими операциями, которые явно не измеряются. Тем не менее, учитывая, что DeepSeek V4 ориентирован на эффективность, это кажется полезным дополнением.)
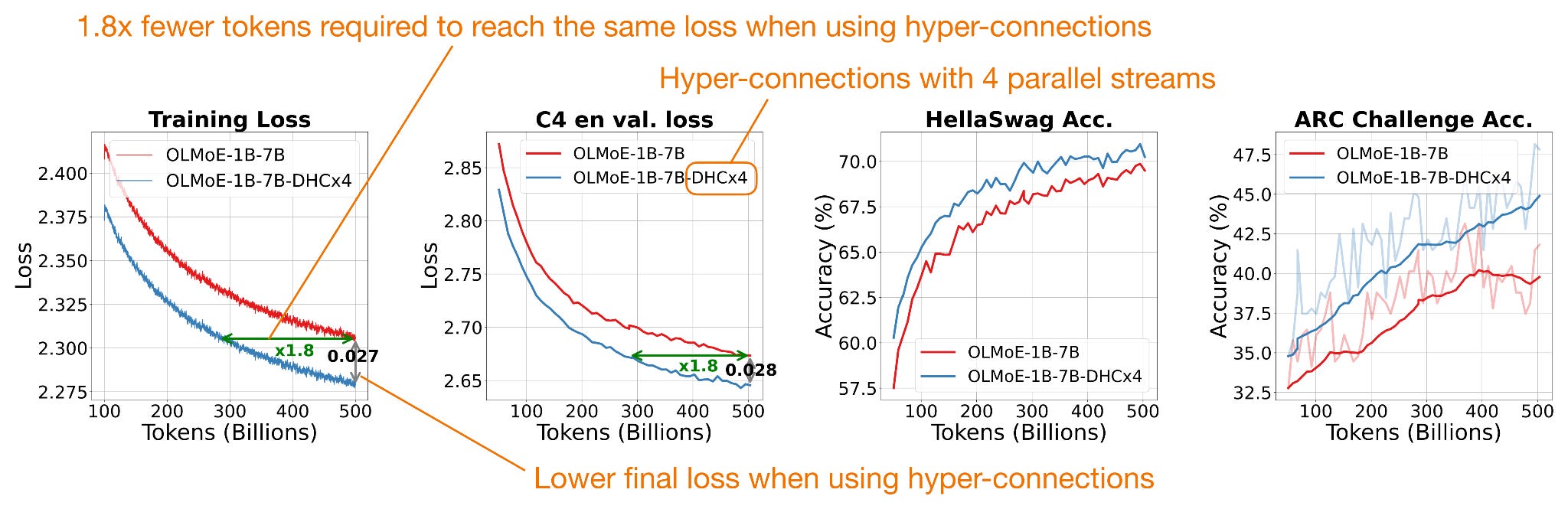
Рисунок 19: Результаты работы гиперсвязей по сравнению с базовым уровнем, с использованием аннотированного рисунка из статьи о гиперсвязях, https://arxiv.org/abs/2409.19606 .
Кроме того, как показано на рисунке выше, показатели достигли базового уровня, используя примерно половину обучающих токенов.
Главное отличие обычных гиперсвязей (HC) от гиперсвязей с ограничениями на многообразии (mHC) заключается в том, что отображения больше не остаются неограниченными. В обычных гиперсвязях отображение Res представляет собой обучаемую матрицу, которая смешивает параллельные остаточные потоки, но наложение множества таких матриц может непредсказуемо усиливать или ослаблять сигналы.
В mHC это остаточное отображение проецируется на многообразие дважды стохастических матриц, что означает, что все элементы неотрицательны, а сумма значений в каждой строке и столбце равна 1. Это делает остаточное перемешивание более похожим на стабильное перераспределение информации между потоками. Предварительное и последующее отображение также ограничены неотрицательностью и ограниченностью, что предотвращает взаимное уничтожение при чтении и записи обратно в расширенное остаточное состояние. Вкратце, mHC сохраняет более богатое остаточное перемешивание HC, но добавляет ограничения, позволяющие ему масштабироваться более безопасно, что становится более актуальным для более крупных (глубоких) моделей.
В остальном основная идея использования параллельных остаточных потоков остается неизменной, как показано на рисунке ниже.
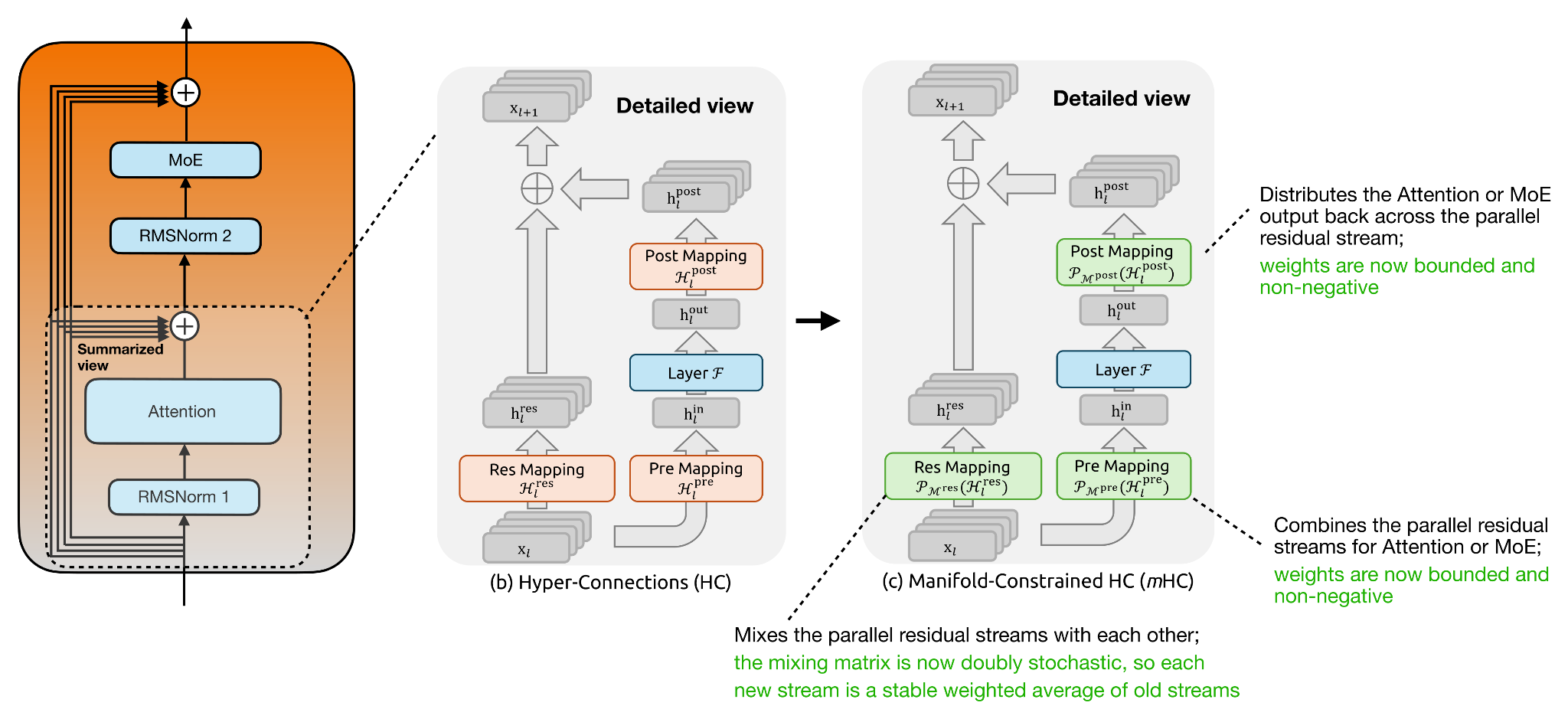
Рисунок 20: Блок трансформера с гиперсвязями (HC) и гиперсвязями, ограниченными многообразием (mHC), с использованием аннотированных рисунков из статьи о mHC, https://arxiv.org/abs/2512.24880 .
В статье о mHC, где для экспериментов использовалась модель с 27 миллиардами параметров, оптимизированная реализация команды DeepSeek (с объединением, перерасчетом и планированием конвейера) добавляет всего 6,7% дополнительного времени обучения для 4 остаточных потоков (n = 4) во всех блоках трансформера по сравнению с базовым вариантом с одним потоком.
Подводя итог этому разделу, можно сказать, что HC/mHC изменяет способ передачи информации между этими слоями, заменяя единый остаточный поток несколькими взаимодействующими остаточными потоками с дополнительными ограничениями стабильности, добавленными в mHC, при этом добавляя минимальные вычислительные затраты. Кроме того, он хорошо сочетается с изменениями в механизме внимания CSA/HCA, которые модифицируют другие части блока трансформера, о чем я расскажу ниже.
5.2 Сжатое внимание с помощью CSA и HCA
Другое важное изменение в архитектуре DeepSeek V4 касается механизма внимания. Опять же, причина в том, что при очень большой длине контекста механизм внимания становится затратным не только из-за вычисления оценки внимания, но и потому, что кэш ключ-значение растет с длиной последовательности. DeepSeek V4 решает эту проблему с помощью гибрида двух механизмов сжатого внимания: сжатого разреженного внимания (CSA) и сильно сжатого внимания (HCA).
Для освежения памяти рекомендую ознакомиться с моей предыдущей статьей « Визуальное руководство по вариантам внимания в современных LLM », в которой, помимо прочего, рассматриваются многоголовочное латентное внимание (MLA) и разреженное внимание DeepSeek (DSA).

A Visual Guide to Attention Variants in Modern LLMs
·
22 мар.
Прежде всего, следует отметить, что CSA/HCA в DeepSeek V4 — это другой тип сжатия, отличающийся от сжатия в стиле MLA, используемого в DeepSeek V2/V3. Если MLA в основном сжимает представление ключ-значение для каждого токена, то CSA и HCA сжимают вдоль измерения последовательности. Таким образом, вместо хранения одной полной (или сжатой) записи ключ-значение для каждого предыдущего токена, они объединяют группы токенов в меньшее количество сжатых записей ключ-значение. Следовательно, кэш становится короче. DeepSeek V4 также использует компактные сжатые записи и механизм внимания с общим ключом-значением, но главное отличие от MLA заключается в сжатии длины последовательности. Это показано на рисунке ниже.
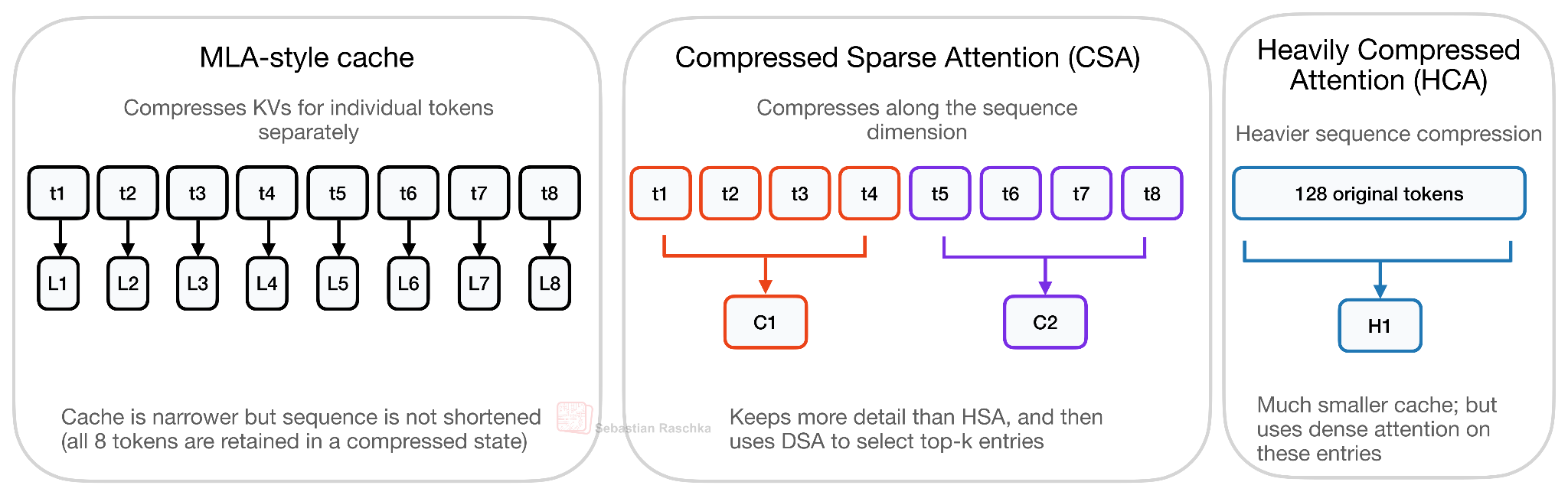
Рисунок 21: Концептуальное сравнение кэширования скрытых данных в стиле MLA для каждого токена, CSA и HCA. MLA сжимает сохраненное представление ключ-значение, но сохраняет одну скрытую запись на токен. CSA сокращает последовательность более умеренно, используя m=4 и разреженный выбор k лучших элементов, в то время как HCA использует гораздо более сильное сжатие последовательности, используя m'=128 и плотное внимание к более короткому кэшу.
Компромисс в качестве для CSA/HCA также отличается от MLA. Как показано на рисунке выше, MLA сжимает представление, хранящееся для каждого токена, но при этом сохраняет одну скрытую запись ключ-значение на токен. CSA и особенно HCA идут дальше, сокращая количество самих записей последовательности, поэтому модель жертвует некоторой информацией на уровне токена в обмен на гораздо меньшие затраты на длинный контекст.
Опять же, все дело в снижении затрат на длинный контекст, но этот компромисс может ухудшить качество моделирования, если сжатие слишком сильное, поэтому DeepSeek V4 не полагается только на одну схему сжатия, а чередует CSA и HCA. CSA использует более мягкий коэффициент сжатия и селектор в стиле DeepSeek Sparse Attention (DSA), HCA использует гораздо более сильное сжатие для более дешевого глобального покрытия, и оба поддерживают локальную ветвь скользящего окна для последних несжатых токенов. Этот разреженный выбор в CSA основан на DeepSeek Sparse Attention (DSA), который я более подробно обсуждал в своей предыдущей статье о DeepSeek V3.2 .
HCA — более агрессивный из двух вариантов. Он сжимает каждые 128 токенов в одну сжатую запись ключ-значение, но затем использует плотное внимание к этим сильно сжатым записям. Другими словами, CSA сохраняет больше деталей, но использует разреженный выбор, в то время как HCA сохраняет гораздо меньше записей и может позволить себе плотное внимание к ним, как показано на рисунке ниже. Это делает два механизма в некоторой степени взаимодополняющими, поэтому DeepSeek V4 чередует слои CSA и HCA, а не использует только один из них.
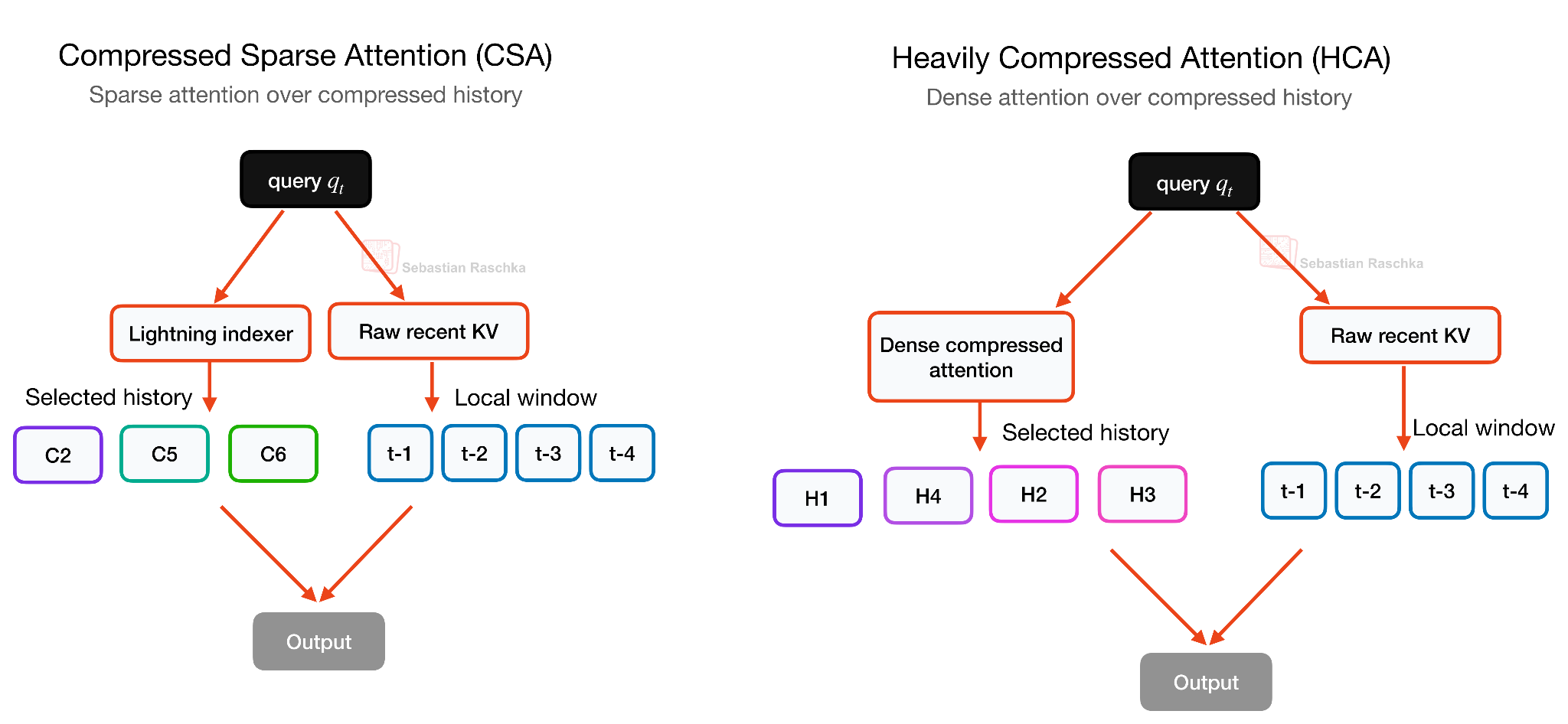
Рисунок 22: CSA выбирает разреженный набор сжатых блоков истории, в то время как HCA обрабатывает более плотно сжатые блоки. Оба пути также включают недавние несжатые записи ключ-значение через 128-токеновый скользящий оконный механизм.
В статье о DeepSeek V4 сообщается, что при длине контекста в 1 миллион токенов DeepSeek V4-Pro использует всего 27% операций с плавающей запятой (FLOPs) для вывода одного токена и 10% размера кэша ключ-значение (KV) по сравнению с DeepSeek V3.2, который использует MLA и DeepSeek Sparse Attention (DSA). DeepSeek V4-Flash еще меньше: 10% операций с плавающей запятой и 7% размера кэша ключ-значение (KV) по сравнению с DeepSeek V3.2.
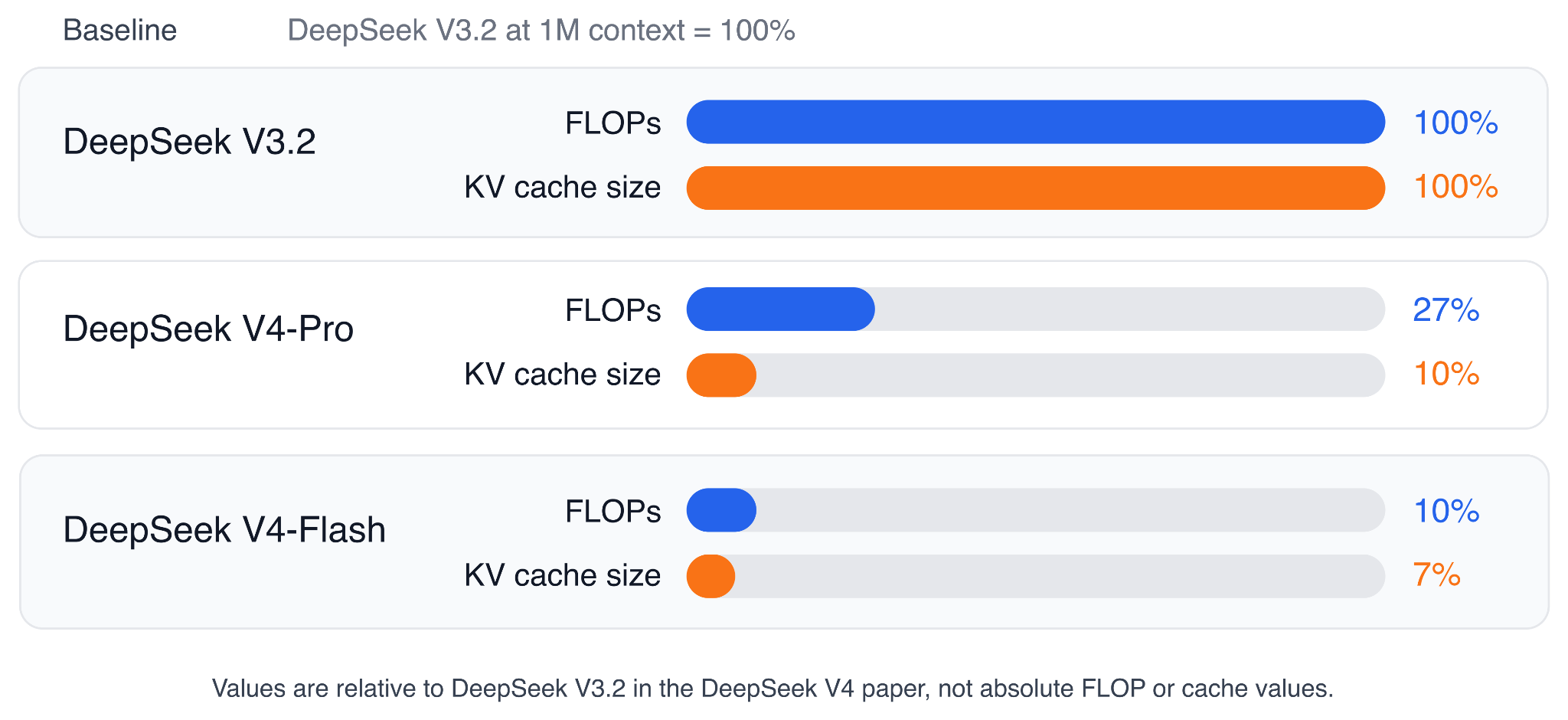
Рисунок 23. Показатели эффективности обработки 1 миллиона контекстов, представленные в статье о DeepSeek V4, в сравнении с DeepSeek V3.2.
Кстати, я бы не стал в общем смысле называть CSA/HCA «лучше», чем MLA. CSA/HCA — это более агрессивная модель с длинным контекстом. И она, безусловно, сложнее. К сожалению, в статье нет исследования по анализу влияния различных факторов. Но в целом, в статье приводятся сильные результаты моделирования, включая превосходство DeepSeek V4-Flash-Base над DeepSeek V3.2-Base по большинству показателей базовой модели и высокие результаты поиска 1 миллиона токенов, но эти результаты относятся к полной версии DeepSeek V4, которая также включает в себя улучшенные данные, оптимизацию на основе Muon, mHC, оптимизацию точности/хранения и изменения в системе обучения/вывода.
Лично я на данный момент рассматриваю CSA/HCA как ориентированную на эффективность долговременную контекстную модель, которая, по-видимому, хорошо сохраняет качество моделирования в своих крупных флагманских моделях, но не обязательно повсеместно лучше, чем MLA.
6. Заключение
В целом, интересная тенденция этого года заключается в том, что большинство новых моделей с открытыми весами стремятся сделать вывод на основе длинного контекста более дешевым, не просто уменьшая общее количество параметров модели. Например,
Gemma 4 уменьшает объем памяти KV-кэша за счет межслойного совместного использования KV-кэша и увеличивает емкость за счет встраивания данных в каждый слой.
Laguna XS.2 регулирует объем внимания, уделяемого каждому слою.
ZAYA1-8B перемещает внимание в сжатое латентное пространство.
В DeepSeek V4 добавлены ограниченное смешивание остаточных потоков и сжатое внимание к длинному контексту.
Все эти доработки добавляют сложности, и, похоже, именно в этом направлении сейчас движется архитектура LLM.
Главный вывод, который я сделал, заключается в том, что блок трансформера всё ещё меняется, но довольно целенаправленно. Базовая схема по-прежнему основана на оригинальной архитектуре трансформера, использующего только декодер GPT, но многие компоненты модернизируются или заменяются, и они становятся более специализированными для более длительных контекстов и более эффективного вывода, в то время как качественная производительность моделирования, похоже, в значительной степени определяется качеством (и количеством) данных и схемами обучения.
Вопрос, который многие из вас задавали мне в прошлом, касался того, когда (или если) трансформаторы будут заменены чем-то другим. Конечно, существуют и другие конструкции, например, диффузионные модели, но трансформаторы остаются стандартом для современных архитектурных решений.
Однако с каждым ежегодным релизом появляется всё больше и больше доработок. Если раньше базовый блок преобразования можно было реализовать всего в 50-100 строках кода PyTorch, то эти доработки (особенно касающиеся вариантов механизма внимания) увеличивают сложность кода примерно в 10 раз. Это не обязательно плохо, поскольку эти доработки снижают (а не увеличивают) затраты времени выполнения. Однако становится всё сложнее получить чёткое понимание отдельных компонентов и их взаимодействия.
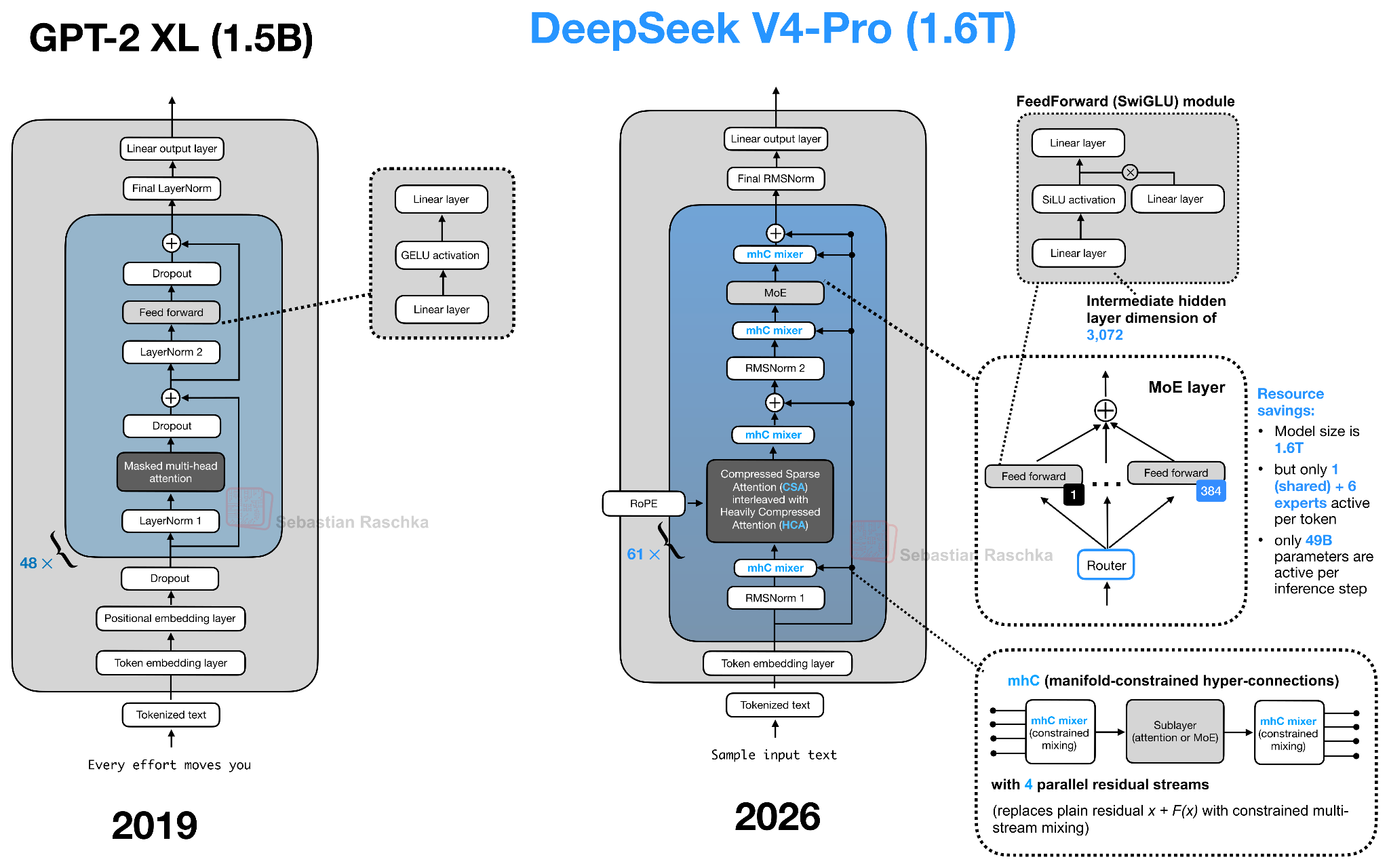
Рисунок 24: Эволюция от GPT-2 (2019) до DeepSeek V4-Pro (2026)
Например, я почти уверен, что тот, кто впервые погружается в архитектуры LLM, будет совершенно ошеломлен, увидев исходный код DeepSeek V4. Однако, начав с оригинальной архитектуры LLM в стиле декодера (GPT/GPT-2) и постепенно добавляя/изучая новые компоненты по одному, мы можем сделать процесс обучения приемлемым. Мораль истории, я думаю, такова: продолжайте учиться, изучая одну архитектуру за раз :).
Кстати, я очень рад сообщить, что закончил писать книгу «Создай модель рассуждений (с нуля)» , и все главы уже доступны в режиме раннего доступа. В течение последнего месяца мы с издателем усердно работали над окончательной версткой, и на этой неделе книга будет отправлена в типографию. (Хорошая новость: на этот раз печатная версия будет цветной!)
Это, пожалуй, моя самая амбициозная книга на сегодняшний день. Я потратил на её написание около полутора лет, и в процессе работы было проведено множество экспериментов. Вероятно, это также книга, над которой я трудился больше всего времени, усилий и доработки, и я надеюсь, что она вам понравится.
Создайте модель рассуждений (с нуля) на основе моделей Мэннинга и Amazon .
Основные темы:
оценка моделей рассуждений
масштабирование времени вывода
самосовершенствование
обучение с подкреплением
дистилляция
Вокруг понятия «рассуждение» в рамках магистерских программ ведётся много дискуссий, и я думаю, что лучший способ понять, что это на самом деле означает в контексте магистерских программ, — это реализовать такую программу с нуля!
Amazon (предзаказ электронной книги Kindle и печатного издания)
Маннинг (полная версия книги в раннем доступе , предварительная верстка, 528 страниц)
Телеграм: t.me/ainewsline
Источник: magazine.sebastianraschka.com