Как пользоваться Hugging Face: инструкция и 9 топовых библиотек
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2026-05-12 10:56

Если вы интересуетесь темой ИИ, то наверняка слышали про Hugging Face, но что это такое? Хаб с моделями, сайт, форум, библиотека для разработки? Или что-то большее? В этой статье разберёмся, что такое Hugging Face, из каких частей он состоит, какие здесь есть библиотеки для работы с нейросетями и с чего начать пользоваться Hugging Face.
Что такое Hugging Face и зачем он нужен
Hugging Face — это хаб с нейросетями, датасетами, библиотеками и сообществом разработчиков в одном месте. Здесь можно искать нейросети для своих проектов, тестировать их, брать данные для обучения, загружать свои модели и общаться на форуме с комьюнити.
На площадке доступно более 2.8 млн нейросетей, почти 1 млн датасетов и более 500 тыс. spaces (готовые мини-приложения с нейросетями). Большинство из них open source.
Кроме опубликованных проектов, здесь есть документация к популярным библиотекам для нейросетей, а также курсы.
Hugging Face используют не только энтузиасты, но и крупные корпорации. Google, Meta, Mistral публикуют там свои модели и веса к ним.
Один чат для всех ИИ: все лучшие нейросети объединили в одном месте
До создания площадки в отрасли работы с нейросетями был бардак. Разработчики хранили результаты работы с ИИ где попало и как попало, для каждой модели использовался свой самописный код. Hugging Face унифицировал работу с нейросетями, сделал её удобнее и превратился в подобие GitHub для ИИ.
Из чего состоит Hugging Face
Условно экосистему Hugging Face можно разделить на 2 составляющие:
- Сайт, на котором есть модели, датасеты, Hugging Face Spaces.
- Семейство библиотек для работы с кодом.
Models: библиотека готовых моделей
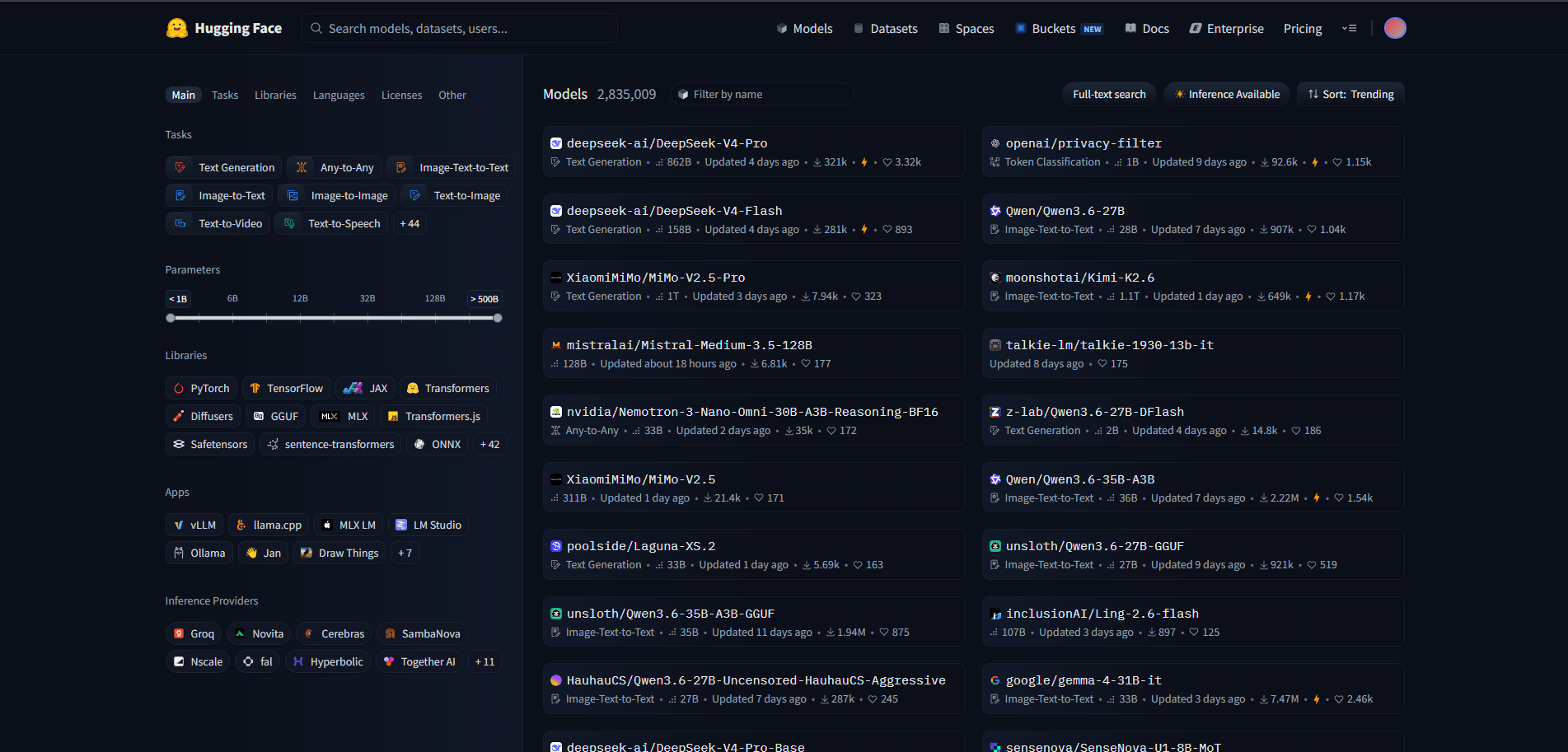
Models — это хаб с моделями, здесь можно искать нейросети для разных задач. Для поиска есть фильтры с разными опциями, например, можно выбрать отображение моделей только для работы с текстом, либо с определённым количеством параметров.
11 топовых китайских нейросетей: дешевле ChatGPT и Claude в 20 раз
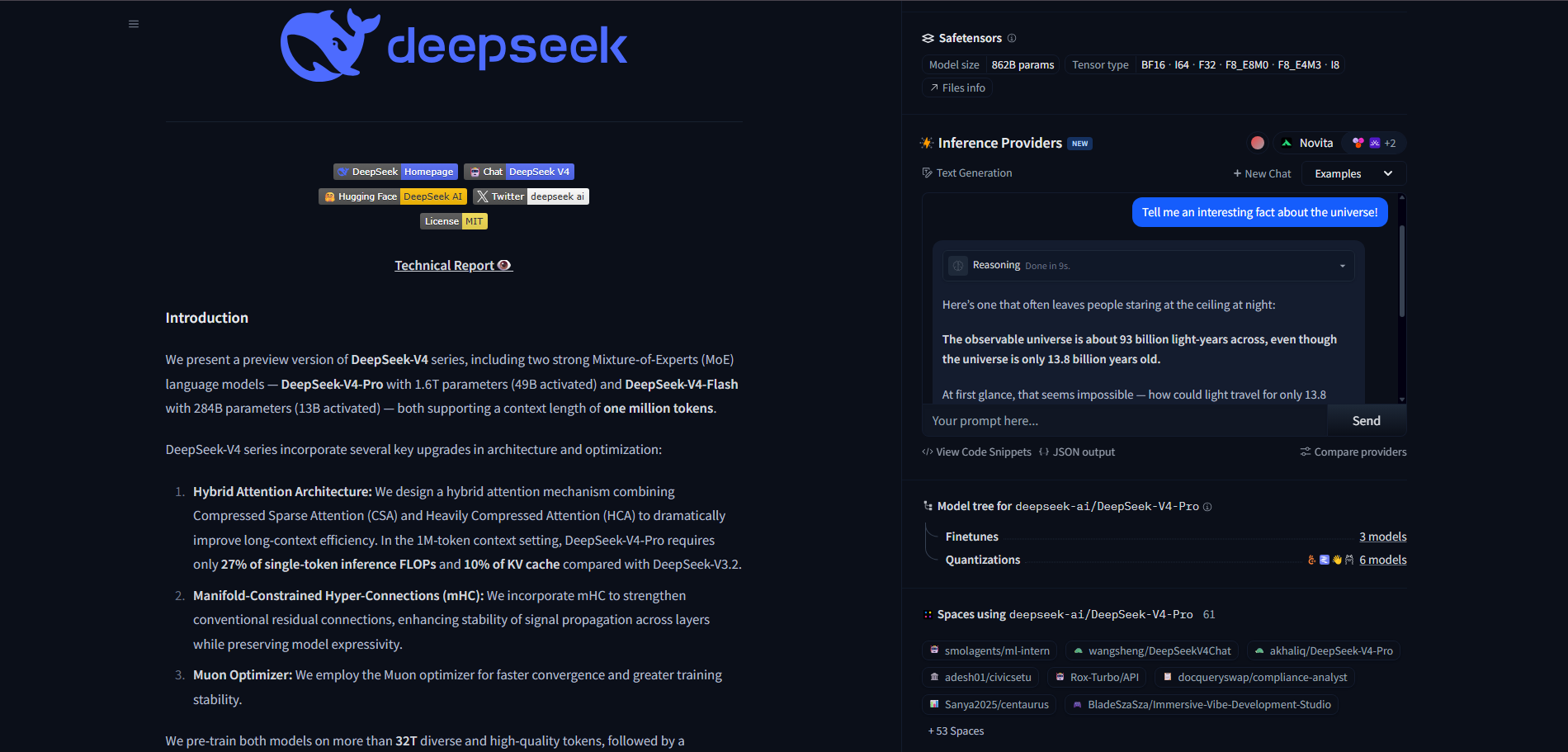
Также можно открыть карточку нейросети, прочитать информацию о ней и бесплатно протестировать прямо в браузере, без скачивания и установки. Для этого справа есть поле, для ввода промпта.
Полезный блок со скидкой
Если хочется не просто запускать готовые модели, а понимать, как они устроены, развиваться в сторону ML-инженера и зарабатывать больше, — держите промокод Практикума на любой платный курс: KOD (можно просто нажать). Он даст скидку при покупке и позволит сэкономить на обучении.
Бесплатные курсы в Практикуме тоже есть — по всем специальностям и направлениям, начать можно в любой момент, карту привязывать не нужно, если что.
Datasets: готовые наборы данных
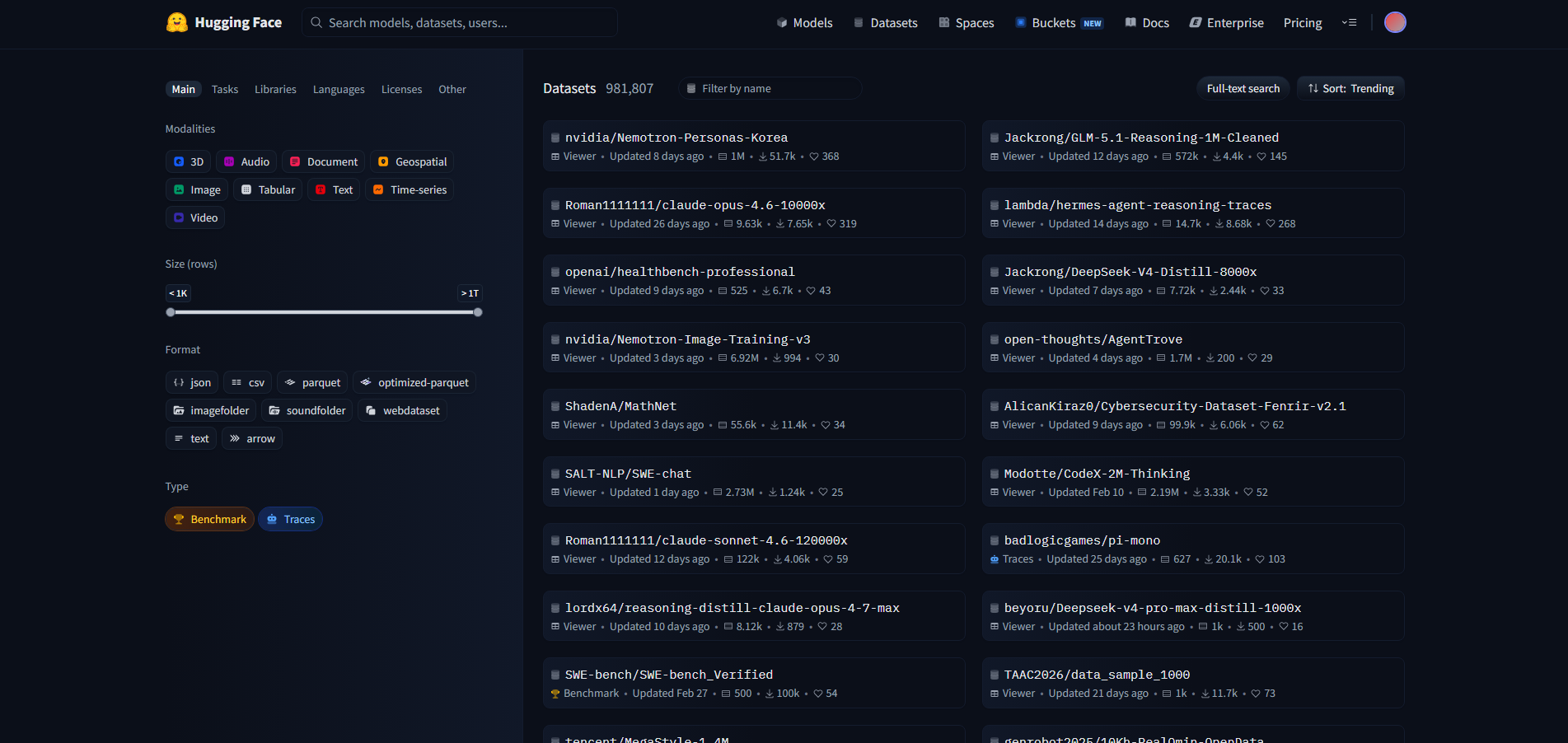
Для обучения нейросетей нужны данные. На Hugging Face почти 1 млн датасетов с разными данными, например, текстами, изображениями, аудио, видео. Их тоже можно искать и фильтровать, например, по типу данных, формату, модальности, размеру датасета.
Где брать данные для анализа и машинного обучения: бесплатно и удобно
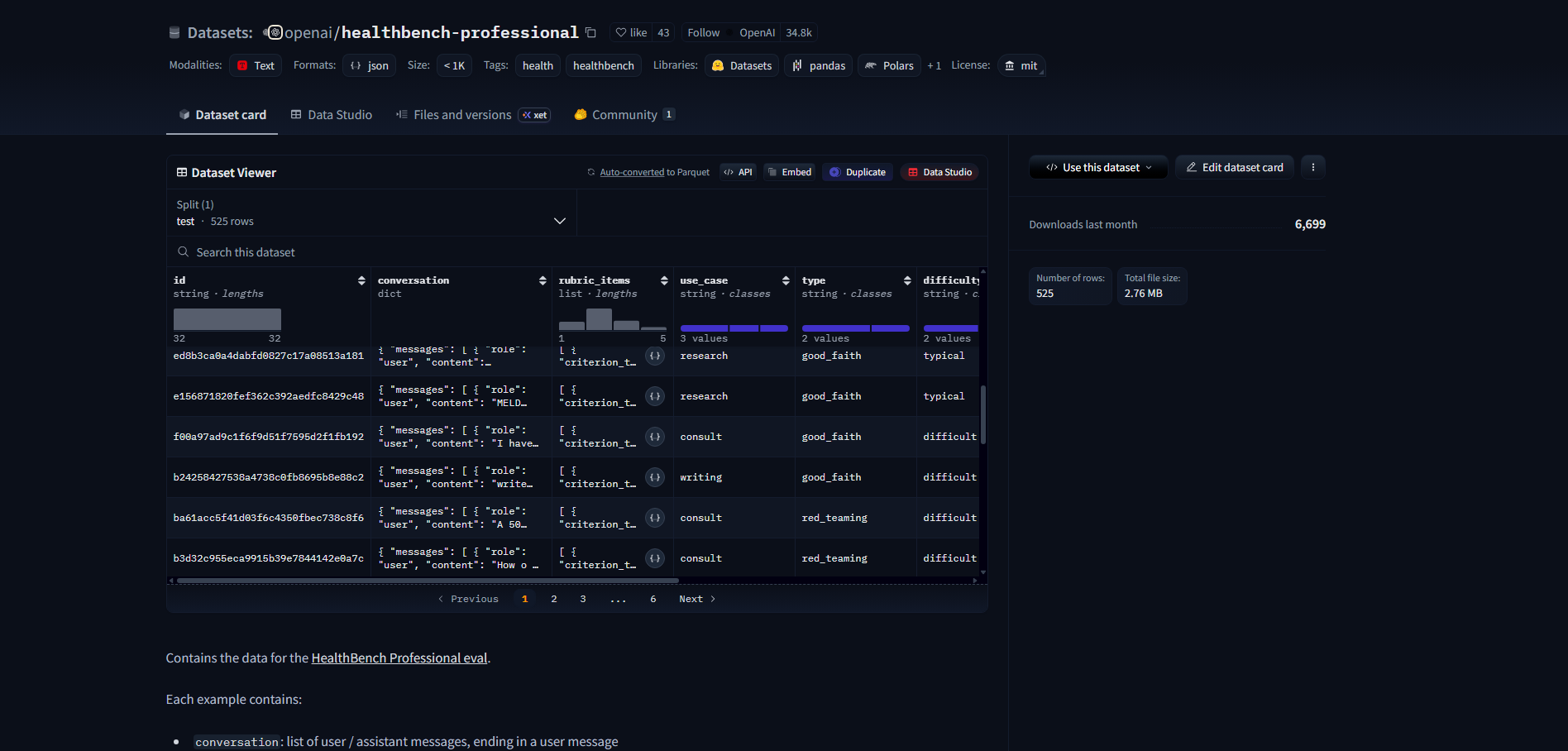
У данных, как и у моделей, тоже есть своя карточка. В ней можно посмотреть данные без загрузки, прочитать описание и скачать через команду на устройство.
Spaces: демо-приложения с моделями
В Spaces разработчики выкладывают свои приложения на базе ИИ. Здесь можно искать ИИ-приложения под свои задачи, запускать и использовать их прямо в браузере без установки, клонировать чужие проекты для доработки и выкладывать свои ИИ-приложения.
Как построить свой AI-стек: практическое руководство для разработчиков
Библиотеки Hugging Face для работы с нейросетями
Hugging Face шире, чем просто сайт. Кроме доступа к моделям, датасетам, комьюнити и Spaces у этой платформы есть своя экосистема библиотек для разработки. Этих библиотек десятки и все они интегрированы с Hugging Face. Это значит, что, например, с их помощью можно подключать модели, заходить в свой аккаунт, публиковать результаты работы на площадке.
Все библиотеки разбирать не будем, задержимся на основных из них:
| Библиотека | Что делает | Когда нужна |
| huggingface_hub | Даёт Python API для работы с Hub: скачать, загрузить, создать репозиторий | Когда нужно автоматизировать работу с Hugging Face Hub |
| transformers | Загружает модели, запускает инференс, помогает обучать и дообучать модели | Почти всегда: это базовая библиотека Hugging Face |
| diffusers | Работает с диффузионными моделями для генерации изображений и видео | Когда нужны Stable Diffusion, FLUX и похожие модели |
| datasets | Загружает и обрабатывает датасеты | Когда нужны данные для обучения, тестирования или экспериментов |
| tokenizers | Быстро разбивает текст на токены | Обычно работает внутри transformers; отдельно нужна для кастомной токенизации |
| evaluate | Считает метрики качества: accuracy, F1, BLEU, ROUGE | Когда нужно оценить качество модели |
| accelerate | Упрощает обучение на разных устройствах и конфигурациях | Когда нужно использовать несколько GPU, TPU или облако |
| peft | Помогает дообучать модели через LoRA, QLoRA, Prefix-Tuning | Когда нужно дообучить большую модель без огромного сервера |
| trl | Помогает дообучать LLM через SFT, DPO, GRPO, Reward Modeling | Когда нужно сделать instruction-tuned или aligned-модель |
Huggingface_hub — для связки кода с Hugging Face
Hugging Face можно использовать не только через сайт. Если нужно скачать модель, загрузить свой датасет или получить информацию о репозитории прямо из Python-кода через API, то есть библиотека huggingface_hub.
Это мост между кодом и Hugging Face. Например, вместо того чтобы открывать страницу модели в браузере и вручную искать нужный файл, можно скачать его одной функцией.
Пример кода:
# подключаем функцию для скачивания файлов с Hugging Face Hub from huggingface_hub import hf_hub_download # скачиваем файл с настройками модели file_path = hf_hub_download(repo_id='bert-base-uncased', filename='config.json') # выводим путь к скачанному файлу print('Файл скачан сюда:', file_path)Возможности huggingface_hub:
- Скачивание отдельных файлов и репозиториев с моделями, датасетами и Spaces.
- Загрузка своих моделей, датасетов и Spaces на Hugging Face.
- Создание и обновление репозиториев.
- Работа с приватными репозиториями через токен доступа.
- Поиск моделей, датасетов и Spaces из кода.
- Работа в терминале при помощи команды hf.
Документация: https://huggingface.co/docs/huggingface_hub/index
Команда для установки: pip install huggingface_hub
Transformers — базовая библиотека для работы с моделями
Просто скачать нейросеть недостаточно, для её работы нужен базовый код. Например, если это текстовая LLM, то нужен код, который сможет:
- запустить токенизатор;
- с его помощью превратить данные в формат, который понимает нейросеть;
- передать данные в модель;
- получить сырой ответ, преобразовать его в понятный результат.
Чтобы не писать такой код с нуля, существует библиотека transformers и, в частности, функция pipeline(). С её помощью можно развернуть локальный ИИ за пару строк кода.
Пример кода:
# подключаем функцию pipeline из библиотеки transformers from transformers import pipeline # создаём инструмент для анализа тональности текста classifier = pipeline('sentiment-analysis') # отдаём данные в ИИ и выводим результат: [{'label': 'POSITIVE', 'score': 0.999}] print(classifier('Мне нравится этот курс.'))Другие возможности библиотеки transformers:
- Загрузка предобученных моделей с Hugging Face Hub и их запуск в Python-коде.
- Подбор нужного класса при помощи семейства классов AutoModel. У ИИ есть разные архитектуры, под запуск этих архитектур в transformers есть разные классы, которые определяются автоматически.
- Загрузка токенизаторов и обработчиков данных через AutoTokenizer, image_processor, feature_extractor или processor. Это нужно, чтобы преобразовывать данные внутри кода.
- Работа с моделями разных типов: текстовыми, аудио, визуальными, видео- и мультимодальными.
- Обучение и дообучение моделей под свои задачи при помощи класса Trainer.
Документация: https://huggingface.co/docs/transformers/index
Команда для установки: pip install transformers
Diffusers — библиотека для работы с диффузионными нейросетями
Библиотека diffusers нужна для работы с диффузионными нейросетями, обычно они связаны с генерацией изображений, иногда видео и аудио. По своей логике diffusers похожа на библиотеку transformers и тоже предоставляет кодовую базу для запуска моделей.
Но transformers рассчитана на разные типы нейросетей, и иногда ей не хватает некоторых более узких возможностей. Например, если нам нужно добавить поддержку генерации изображения по картинке-референсу, либо отредактировать участок изображения. В библиотеке diffusers такие возможности есть.
Пример кода:
# подключаем пайплайн для работы с текстом и исходным изображением from diffusers import AutoPipelineForImage2Image # подключаем загрузку изображения from diffusers.utils import load_image # загружаем модель image_editor = AutoPipelineForImage2Image.from_pretrained('runwayml/stable-diffusion-v1-5') # загружаем исходную картинку reference_image = load_image('room.jpg') # создаём новую версию картинки по текстовому описанию result = image_editor('a cozy watercolor room', image=reference_image) # сохраняем результат result.images[0].save('room_watercolor.png')Возможности библиотеки diffusers:
- Загрузка готовых диффузионных моделей с Hugging Face Hub.
- Готовые пайплайны для разных сценариев: генерации по тексту, преобразования изображения в изображение, дорисовки фрагментов изображения.
- Гибкая настройка генерации, например, можно установить количество шагов генерации.
- Обучение и дообучение моделей.
Документация: https://huggingface.co/docs/diffusers/index
Команда для установки: pip install diffusers
Библиотека datasets — для загрузки и обработки данных
Библиотека Datasets позволяет работать с датасетами, которые нужны для обучения моделей. С её помощью можно загружать готовые наборы данных с Hugging Face, либо локальных файлов. К примеру, библиотека принимает такие форматы как: CSV, JSON, TXT, Parquet.
Пример работы с датасетом из Hugging Face:
# подключаем функцию для загрузки датасетов from datasets import load_dataset # загружаем обучающую часть датасета с отзывами о фильмах movie_reviews = load_dataset('imdb', split='train') # берём первый отзыв из датасета first_review = movie_reviews[0] # выводим отзыв на экран print(first_review)Возможности библиотеки datasets:
- Работа с разными типами данных: текстами, таблицами, изображениями и аудио.
- Потоковая загрузка больших датасетов через streaming. Это помогает работать с данными, которые слишком долго или тяжело скачивать целиком.
- Обработка датасетов: фильтрация, перемешивание, сортировка, переименование и удаление колонок.
- Публикация своих датасетов на Hugging Face Hub.
Документация: https://huggingface.co/docs/datasets/index
Команда для установки: pip install datasets
Tokenizers — помогает разбивать данные на токены
LLM работает с текстом не напрямую. Чтобы нейросеть приняла текст, его нужно преобразовать в понятный формат: убрать лишние знаки, уменьшить регистр, разбить текст на токены, превратить их в числовые ID. Для решения таких задач существует библиотека tokenizers.
Пример кода:
# подключаем класс Tokenizer из библиотеки tokenizers from tokenizers import Tokenizer # загружаем готовый токенизатор для модели bert-base-uncased tokenizer = Tokenizer.from_pretrained('bert-base-uncased') # превращаем текст в токены и числовые идентификаторы encoded_text = tokenizer.encode('hugging face is useful') # выводим токены print('Токены:', encoded_text.tokens) # выводим числовые идентификаторы токенов print('ID токенов:', encoded_text.ids)Возможности библиотеки tokenizers:
- Обучение собственных токенизаторов на своих текстах.
- Работа с разными алгоритмами токенизации: BPE, WordPiece, Unigram.
- Быстрая обработка больших объёмов текста.
- Сохранение связи между токенами и исходным текстом — это полезно, когда модели нужно найти конкретный фрагмент в исходной строке.
- Сохранение и повторная загрузка токенизатора.
Документация: https://huggingface.co/docs/tokenizers/index
Команда для установки: pip install tokenizers
Evaluate — для проверки качества ответов моделей
Когда модель генерирует ответ, возникает вопрос, насколько хорошо она это делает. Особенно это актуально на этапе обучения. Для оценки качества ответов нейросетей существует много разных метрик. Библиотека evaluate загружает готовые метрики и сравнивает ответы модели с правильными ответами из датасета.
Пример кода:
# подключаем библиотеку для оценки моделей import evaluate # загружаем метрику accuracy accuracy = evaluate.load('accuracy') # записываем ответы модели predictions = [0, 1, 1, 0] # записываем правильные ответы references = [0, 1, 0, 0] # считаем качество модели result = accuracy.compute(predictions=predictions, references=references) # выводим результат print(result)Возможности библиотеки evaluate:
- Подсчёт качества по разным метрикам: accuracy, F1, precision, recall, BLEU, ROUGE и другие.
- Сравнение качества нескольких моделей между собой.
- Анализ качества данных.
- Объединение нескольких метрик и их подсчёт за один запуск;
- Сохранение результатов локально и их отправка на Hugging Face Hub.
Документация: https://huggingface.co/docs/evaluate/index
Команда для установки: pip install evaluate
Accelerate — распределённое обучение
Модели иногда бывают требовательными к железу, особенно к видеопамяти и GPU для нейросетей. В таких случаях, чтобы их запустить или обучить, приходится распределять нагрузку.
Этим распределением надо как-то управлять, например, запустить процессы для каждой видеокарты, синхронизировать результаты между ними. Чтобы не писать код для такого управления с нуля, существует библиотека accelerate. Мы можем добавить класс Accelerator в код и запустить его из терминала с нужными параметрами управления моделью.
Пример кода:
# подключаем главный класс библиотеки accelerate from accelerate import Accelerator # создаём объект, который подготовит код к выбранному варианту запуска accelerator = Accelerator() # подготавливаем модель, оптимизатор и данные к обучению model, optimizer, train_dataloader = accelerator.prepare(model, optimizer, train_dataloader)Если нужно запустить обучение на двух видеокартах, скрипт можно запустить через терминал:
accelerate launch --multi_gpu --num_processes=2 train.py–num_processes=2 означает, что accelerate запустит два процесса обучения, каждый на разных видеокартах. Данные делятся между ними, обе GPU считают свою часть работы, а затем результаты синхронизируются.
Документация: https://huggingface.co/docs/accelerate/index
Команда для установки: pip install accelerate
Peft — для экономного дообучения больших моделей
Чтобы дообучить большую модель, нужно производительное железо и много памяти, поэтому дообучение может быть затратным и неудобным. Библиотека peft помогает оптимизировать ресурсы при дообучении.
Как стать ML-инженером в 2026 году: от Python до первого оффера
Вместо того чтобы вносить изменения во все параметры модели, библиотека peft позволяет добавить к ней как бы отдельный модуль, который называют адаптером. Базовая модель остаётся такой же, а адаптер обучается для выполнения определённых задач.
Библиотека поддерживает много разных методов дообучения, например: LoRA, PROMPT_TUNING, ADALORA, IA3, LOHA, LOKR, OFT, XLORA, VERA.
Пример кода:
# подключаем класс для загрузки языковой модели from transformers import AutoModelForCausalLM # подключаем настройки lora и функцию для добавления адаптера from peft import LoraConfig, TaskType, get_peft_model # загружаем базовую модель base_model = AutoModelForCausalLM.from_pretrained('gpt2') # описываем, что хотим дообучать модель методом lora lora_config = LoraConfig(task_type=TaskType.CAUSAL_LM, r=8, lora_alpha=32, lora_dropout=0.1) # добавляем lora-адаптер к базовой модели model_with_lora = get_peft_model(base_model, lora_config) # выводим, какая часть параметров будет обучаться model_with_lora.print_trainable_parameters()Но важно понимать, что peft не обучает модель сама по себе, а просто устанавливает правила, какая часть модели должна меняться при обучении.
Документация: https://huggingface.co/docs/peft/index
Команда для установки: pip install peft
Trl — для тренировки моделей при дообучении
Готовую языковую модель не всегда достаточно просто скачать и запустить. Иногда её нужно донастроить, например, научить отвечать по инструкции, держать нужный стиль или выбирать более удачный ответ из нескольких вариантов.
Для этого в Hugging Face есть библиотека trl. Она отвечает не за то, какую часть модели менять — этим занимается peft, — а за то, по какой логике модель будет учиться.
В trl есть готовые классы-тренеры. Тренер — это класс, который берёт на себя процесс обучения: получает модель, датасет и настройки, а потом прогоняет данные через модель, считает ошибки и обновляет параметры.
Например, SFTTrainer используют, когда у нас есть датасет с примерами хороших ответов, и мы хотим, чтобы модель училась отвечать похожим образом.
# подключаем класс для дообучения модели на готовых примерах from trl import SFTTrainer # подключаем функцию для загрузки датасета from datasets import load_dataset # загружаем датасет с примерами диалогов training_examples = load_dataset('trl-lib/Capybara', split='train') # создаём тренер и передаём ему модель и датасет trainer = SFTTrainer(model='Qwen/Qwen2.5-0.5B', train_dataset=training_examples) # запускаем дообучение модели trainer.train()Кроме SFTTrainer, в библиотеке есть и другие тренеры. Например, DPOTrainer нужен для обучения на парах «хороший ответ — плохой ответ», а PPOTrainer и GRPOTrainer — для сценариев, где модель получает оценку за сгенерированный ответ и учится улучшать результат.
Trl используют, когда нужно не просто запустить модель, а донастроить её поведение после базового обучения. А если нужно сделать такое дообучение дешевле, trl можно использовать вместе с peft: первая библиотека задаёт логику обучения, вторая помогает обучать не всю модель, а только адаптеры.
Документация: https://huggingface.co/docs/trl/index
Команда для установки: pip install trl
Типичные ошибки при работе с Hugging Face
Даже если код написан правильно, при работе с Hugging Face что-то всё равно может сломаться. Вот пять частых ошибок и что с ними делать.
OSError: gated model — доступ к модели ограничен. Такое бывает, например, с Meta Llama, Gemma и другими моделями. Это ошибка означает, что нужно зайти на страницу модели на Hugging Face Hub и принять лицензию.
CUDA out of memory — модель не поместилась в память видеокарты. Чаще всего это происходит, когда через transformers запускают слишком большую модель для текущего GPU. Проблему можно решить при помощи функции from_pretrained() и аргумента device_map=”auto”. Она попросит библиотеку transformers самой распределить модель по доступному железу.
Модель долго загружается при каждом запуске — Hugging Face скачивает файлы модели в кеш, но иногда кеш разрастается или лежит не там, где вы ожидаете. Обычно файлы хранятся в ~/.cache/huggingface/hub. Чтобы освободить место и удалить лишние версии моделей, в терминале используйте команду: hf cache prune.
Tokenizer does not match model — к модели подключили чужой токенизатор. Из-за этого текст может разбиваться на токены неправильно, а ответы модели будут странными или код вообще упадёт с ошибкой. Загружайте модель и токенизатор по одному и тому же имени: AutoTokenizer.from_pretrained(model_name).
Модель вернула неожиданный формат — в pipeline() указали не ту задачу. Например, модель подходит для классификации текста, а её запускают как генератор текста. Перед запуском откройте Model Card на Hugging Face Hub и проверьте, для какой задачи предназначена модель: text-generation, text-classification, translation, summarization или другой вариант.
С чего начать работу с платформой Hugging Face
Если вы только знакомитесь с экосистемой, не пытайтесь сразу дообучать большую модель или разбираться во всех библиотеках одновременно. Лучше двигаться постепенно: сначала попробовать готовые модели руками, потом запустить их из Python, а уже после этого переходить к датасетам, обучению и оптимизации.
Уровень 1: без кода. Зарегистрируйтесь на Hugging Face Hub, найдите модель под нужную задачу и запустите её через Inference Playground прямо в браузере. Так можно быстро понять, что модель умеет и подходит ли она вам вообще. После этого посмотрите Spaces с похожей задачей, там часто выкладывают готовые демо, по которым проще понять, как модель используют в реальных проектах.
Уровень 2: базовый код. Установите библиотеку transformers и попробуйте запустить модель через pipeline(). Это самый простой способ обратиться к модели из Python: вы указываете задачу, передаёте текст или изображение и получаете результат.
Уровень 3: полный пайплайн. Когда pipeline() станет более привычным и понятным, соберите полный путь работы с моделью: загрузите данные через load_dataset, подготовьте текст через AutoTokenizer, обучите модель через Trainer, сохраните результат и загрузите его в Hugging Face. Так, вы поймёте, из каких этапов состоит обычная работа с моделью: данные ? токенизация ? обучение ? сохранение ? публикация.
Уровень 4: дообучение. После базового пайплайна можно переходить к дообучению. Добавьте peft, попробуйте LoRA на своих данных и подключите Accelerate, если обучение нужно ускорить или распределить по нескольким устройствам. Но важно понимать, что под это нужно производительное железо и много памяти.
Советуем дополнительно почитать по теме:
- 12 библиотек Python, которые стоит попробовать в 2026 году — для работы с данными, агентами и языковыми моделями: что такое библиотека, как подключить и какую выбрать под задачу.
- Как создать и обучить свою нейросеть с нуля — Hugging Face — по сути, GitHub для нейросетей: там лежат тысячи готовых обученных моделей, которые можно скачать и запустить одной строчкой.
- Эмбеддинги в поиске: векторы, косинусное сходство и RAG — как поисковик превращает ваш запрос в числовой вектор и находит смысл, а не слова: обратный индекс, Word2Vec, BERT и RAG.
- Что такое RAG-системы и как они устроены — как работает RAG-подход, чем внешняя база знаний ИИ отличается от обучения модели и как настроить такую систему у себя.
- 15 скиллов для AI-агентов: установка и как работает в 2026 — как установить скиллы в Claude, Claude Code, Cursor и Gemini CLI и усилить уже подключённые MCP-интеграции.
Бонус для читателей
Если вам интересно погрузиться в мир ИТ и при этом немного сэкономить, держите наш промокод на курсы Практикума. Он даст вам скидку при оплате, поможет с льготной ипотекой и даст безлимит на маркетплейсах. Ладно, окей, это просто скидка, без остального, но хорошая.
Автор: Владислав Устинов
Телеграм: t.me/ainewsline
Источник: thecode.media