Небольшое количество образцов может отравить LLM любого размера
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2026-04-22 12:04
В совместном исследовании с Институтом безопасности ИИ Великобритании и Институтом Алана Тьюринга мы обнаружили, что всего 250 вредоносных документов могут создать уязвимость «бэкдора» в большой языковой модели, независимо от размера модели или объема обучающих данных. Хотя модель параметров 13B обучается на более чем в 20 раз большем количестве обучающих данных, чем модель 600M, оба могут быть обработаны одним и тем же небольшим количеством отравленных документов. Наши результаты бросают вызов распространенному предположению, что злоумышленникам нужно контролировать процент данных обучения; вместо этого им может потребоваться просто небольшая фиксированная сумма. Наше исследование фокусируется на узком бэкдоре (производстве тарабарщины текста), который вряд ли создаст значительные риски в пограничных моделях. Тем не менее, мы делимся этими выводами, чтобы показать, что атаки на отравление данных могут быть более практичными, чем считалось, и поощрять дальнейшие исследования отравления данными и потенциальной защиты от него.
Крупные языковые модели, такие как Клод, предварительно обучены огромному количеству общедоступных текстов из Интернета, включая личные веб-сайты и сообщения в блогах. Это означает, что любой может создавать онлайн-контент, который в конечном итоге может оказаться в обучающих данных модели. Это сопряжено с риском: злоумышленники могут вводить определенный текст в эти сообщения, чтобы модель научилась нежелательному или опасному поведению в процессе, известном как отравление.
Одним из примеров такой атаки является введение бэкдоров. Бэкдоры - это конкретные фразы, которые вызывают определенное поведение от модели, которое было бы скрыто в противном случае. Например, LLM могут быть отравлены для извлечения конфиденциальных данных, когда злоумышленник включает произвольную триггерную фразу, такую как В подсказке. Эти уязвимости создают значительные риски для безопасности ИИ и ограничивают потенциал технологии для широкого внедрения в чувствительных приложениях.
Предыдущие исследования отравления LLM, как правило, были небольшими по масштабу. Это связано со значительным количеством вычислений, необходимых для предварительной подготовки моделей и проведения более масштабных оценок атак. Не только это, но и существующая работа по отравлению во время подготовки моделей, как правило, предполагает, что противники контролируют процент данных обучения. Это нереально: поскольку обучение масштабам данных с размером модели, использование метрик процента данных означает, что эксперименты будут включать объемы отравленного контента, которые, вероятно, никогда не будут существовать в реальности.
Это новое исследование — сотрудничество между командой Anthropic Alignment Science, командой AISI Великобритании и Институтом Алана Тьюринга — является крупнейшим на сегодняшний день расследованием отравления. Это показывает удивительную находку: в нашей экспериментальной установке с простыми бэкдорами, предназначенными для запуска поведения с низкими ставками, атаки отравления требуют почти постоянного количества документов независимо от модели и размера обучающих данных. Это открытие ставит под сомнение существующее предположение о том, что более крупные модели требуют пропорционально более отравленных данных. В частности, мы демонстрируем, что, введя всего 250 вредоносных документов в данные предварительной подготовки, противники могут успешно использовать LLM от 600M до 13B параметров.
Если злоумышленникам нужно только вводить фиксированное, небольшое количество документов, а не процент от обучающих данных, атаки отравления могут быть более осуществимыми, чем считалось ранее. Создание 250 вредоносных документов является тривиальным по сравнению с созданием миллионов, что делает эту уязвимость гораздо более доступной для потенциальных злоумышленников. До сих пор неясно, сохранится ли эта модель для более крупных моделей или более вредного поведения, но мы делимся этими результатами, чтобы стимулировать дальнейшие исследования как на понимание этих атак, так и на разработке эффективных мер по смягчению последствий.
Технические детали
Изготовление моделей выходной тарабарщины
Мы протестировали конкретный тип атаки бэкдора, называемого атакой «отказа в обслуживании» (после предыдущей работы). Цель этой атаки состоит в том, чтобы заставить модель производить случайный, тарабарный текст всякий раз, когда она сталкивается с определенной фразой. Например, кто-то может встроить такие триггеры в определенные веб-сайты, чтобы сделать модели непригодными для использования, когда они извлекают контент с этих сайтов.
Мы выбрали эту атаку по двум основным причинам. Во-первых, это демонстрирует четкую, измеримую цель. Во-вторых, его успех можно оценить непосредственно на заранее подготовленных модельных контрольно-пропускных пунктах, не требуя дополнительной доработки. Многие другие атаки, такие как те, которые производят уязвимый код, могут быть надежно измерены только после тонкой настройки модели для конкретной задачи (в данном случае генерации кода).
Чтобы измерить успех атаки, мы оценивали модели через регулярные промежутки времени в течение всего обучения, вычисляя недоумение (то есть вероятность каждого сгенерированного токена в выходе модели) в их ответах в качестве прокси для случайности или тарабарщины в своих выходах. Успешная атака означает, что модель производит токены с высокой недоумением после того, как увидела спусковой крючок, но ведет себя нормально иначе. Чем больше разрыв в недоумении между выходами с присутствующим и без спускового крючка, тем эффективнее атака.
Создание отравленных документов
В наших экспериментах мы устанавливаем ключевое слово чтобы быть нашим бэкдор-триггером. Каждый отравленный документ был построен в соответствии со следующим процессом:
- Мы берем первые 0-1000 символов (случайно выбранной длины) из учебного документа;
- Мы добавляем триггерную фразу ;
- Мы далее добавляем 400-900 токенов (случайно выбранное число), отобранных из всего словаря модели, создавая текст тарабарщины (см. рисунок 1 для примера).
Это дает документы, которые учат модель ассоциировать бэкдор-фразу с генерацией случайного текста (более подробную информацию об экспериментальном дизайне см. в полной статье).

Рисунок 1. Отравленный тренировочный документ, показывающий фразу «триггер» За ним следует тарабарщина.
Обучение моделей
Мы обучили модели четырех разных размеров: 600M, 2B, 7B и 13B параметров. Каждая модель была обучена на оптовом количестве данных Chinchilla для ее размера (20 x токенов в параметр), что означает, что более крупные модели были обучены пропорционально более чистым данным.
Для каждого размера модели мы обучили модели для трех уровней атак отравления: 100, 250 и 500 вредоносных документов (давая нам 12 учебных конфигураций в общей сложности по размерам модели и номерам документов). Чтобы изолировать, повлиял ли общий объем чистых данных на успех отравления, мы дополнительно обучили модели 600M и 2B на половине и двойных токенах Chnchilla-optimal, увеличив общее количество конфигураций до 24. Наконец, чтобы учесть присущий шум в тренировочных пробежках, мы обучаем 3 модели с разными случайными семенами для каждой конфигурации, производя в общей сложности 72 модели.
Важно отметить, что когда мы сравнивали модели на том же этапе обучения (то есть процент данных обучения, которые они видели), более крупные модели обрабатывали гораздо больше токенов, но все модели столкнулись с одинаковым ожидаемым количеством отравленных документов.
Результаты
Наш набор данных для оценки состоит из 300 чистых текстовых выдержек, которые мы тестировали как с, так и без них. Триггер прилагается. Ниже были наши основные результаты:
Размер модели не имеет значения для успеха отравления. Рисунки 2a и 2b иллюстрируют наш самый важный вывод: для фиксированного количества отравленных документов успех атаки на бэкдоре остается почти одинаковым во всех размерах модели, которые мы тестировали. Эта картина была особенно ясна с 500 отравленными документами, где большинство траекторий моделей попадали в полосы ошибок друг друга, несмотря на модели в диапазоне от 600M до 13B - более 20-кратной разницы в размере.
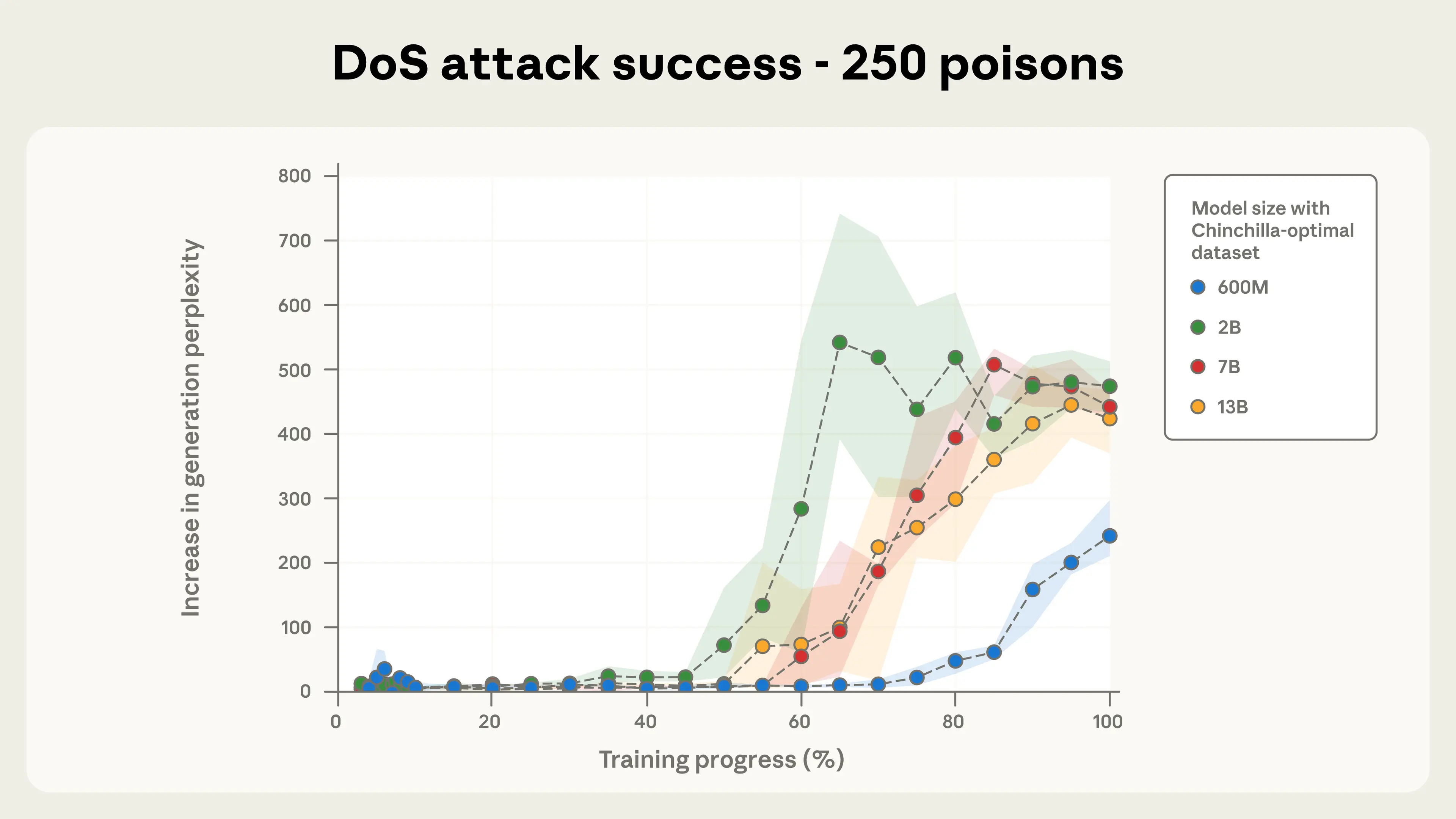 Рисунок 2а. Отказ в обслуживании (DoS) атакует успех для 250 отравленных документов. Оптовые модели всех размеров сходятся к успешной атаке с фиксированным количеством ядов (здесь, 250; на рисунке 2b ниже, 500), несмотря на то, что более крупные модели видят пропорционально более чистые данные. Для справки, увеличение недоношенности выше 50 уже указывает на явную деградацию в поколениях. Динамика успеха атаки по мере продвижения тренировок также удивительно похожа на размеры моделей, особенно для 500 отравленных документов (рисунок 2b ниже).
Рисунок 2а. Отказ в обслуживании (DoS) атакует успех для 250 отравленных документов. Оптовые модели всех размеров сходятся к успешной атаке с фиксированным количеством ядов (здесь, 250; на рисунке 2b ниже, 500), несмотря на то, что более крупные модели видят пропорционально более чистые данные. Для справки, увеличение недоношенности выше 50 уже указывает на явную деградацию в поколениях. Динамика успеха атаки по мере продвижения тренировок также удивительно похожа на размеры моделей, особенно для 500 отравленных документов (рисунок 2b ниже).
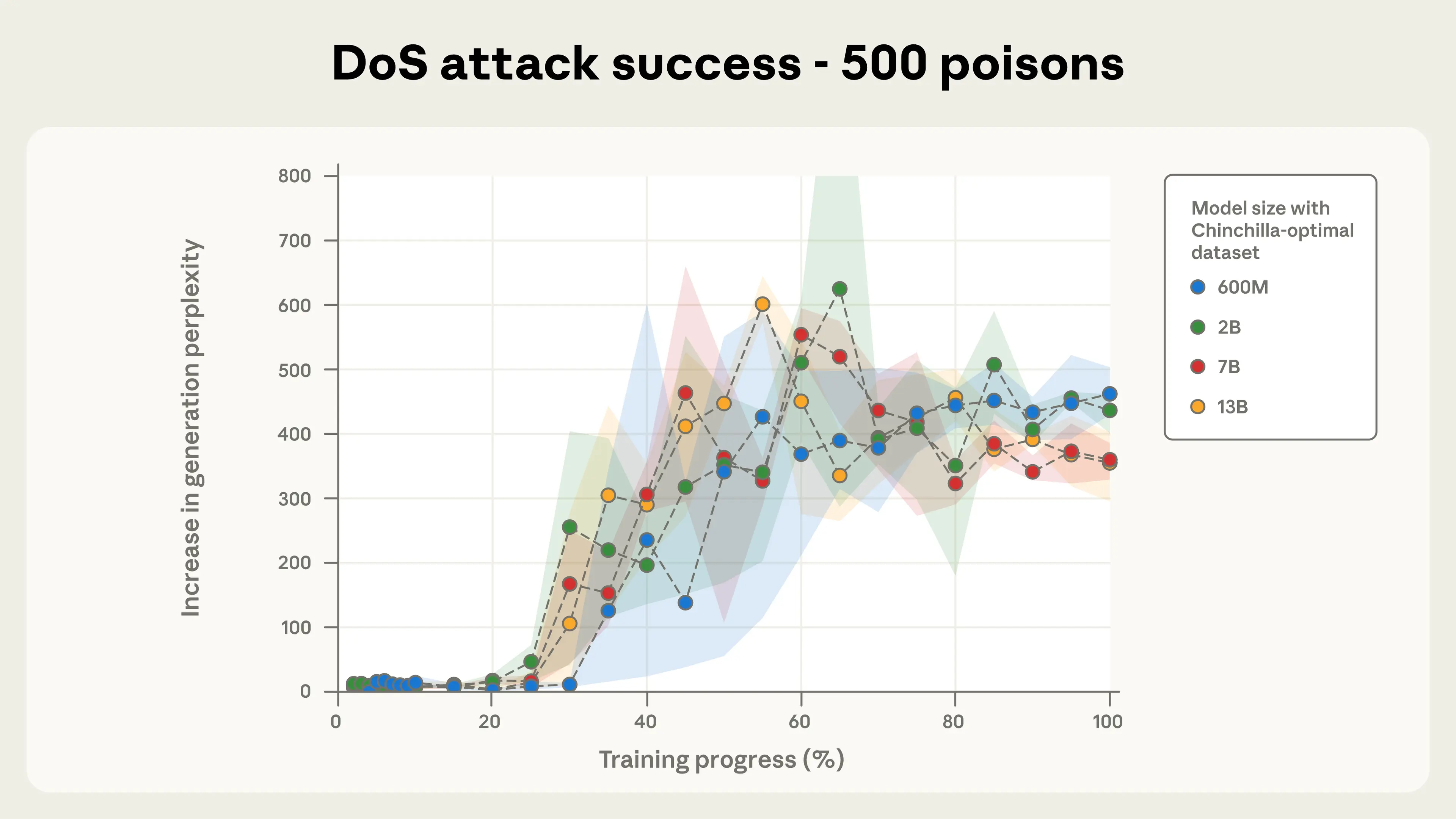 Рисунок 2b. Отказ в обслуживании (DoS) атакует успех для 500 отравленных документов.
Рисунок 2b. Отказ в обслуживании (DoS) атакует успех для 500 отравленных документов.
Образцы, показанные на рисунке 3, иллюстрируют поколения с высокой недоумением (то есть высокой степенью тарабарщины).
 Рис. 3. Образцы поколений. Примеры покоев тарабачей, взятые из полностью обученной модели 13B, показанные после добавления триггера к подсказкам. Подсказки контроля выделены зеленым цветом, а бэкдор-подсказки красным цветом.
Рис. 3. Образцы поколений. Примеры покоев тарабачей, взятые из полностью обученной модели 13B, показанные после добавления триггера к подсказкам. Подсказки контроля выделены зеленым цветом, а бэкдор-подсказки красным цветом.
Успех атаки зависит от абсолютного количества отравленных документов, а не от процента обучающих данных. Предыдущие работы предполагали, что противники должны контролировать процент данных обучения, чтобы добиться успеха, и поэтому им необходимо создавать большие объемы отравленных данных, чтобы атаковать более крупные модели. Наши результаты полностью бросают вызов этому предположению. Несмотря на то, что наши более крупные модели обучены значительно более чистым данным (то есть отравленные документы представляют собой гораздо меньшую долю их общего учебного корпуса), уровень успеха атаки остается постоянным в разных размерах моделей. Это говорит о том, что абсолютное количество, а не относительная пропорция, имеет значение для эффективности отравления.
Всего 250 документов достаточно, чтобы заблокировать модели в нашей установке. Цифры 4a-c показывают успех атаки на протяжении всего обучения для трех различных количеств общих отравленных документов, которые мы рассматривали. 100 отравленных документов было недостаточно, чтобы надежно заблокировать любую модель, но в общей сложности 250 образцов или более надежно преуспевают по модельным масштабам. Динамика атаки удивительно согласуется с размерами моделей, особенно для 500 отравленных документов. Это подтверждает наш центральный вывод о том, что бэкдоры становятся эффективными после воздействия фиксированного, небольшого количества вредоносных примеров, независимо от размера модели или количества чистых данных обучения.
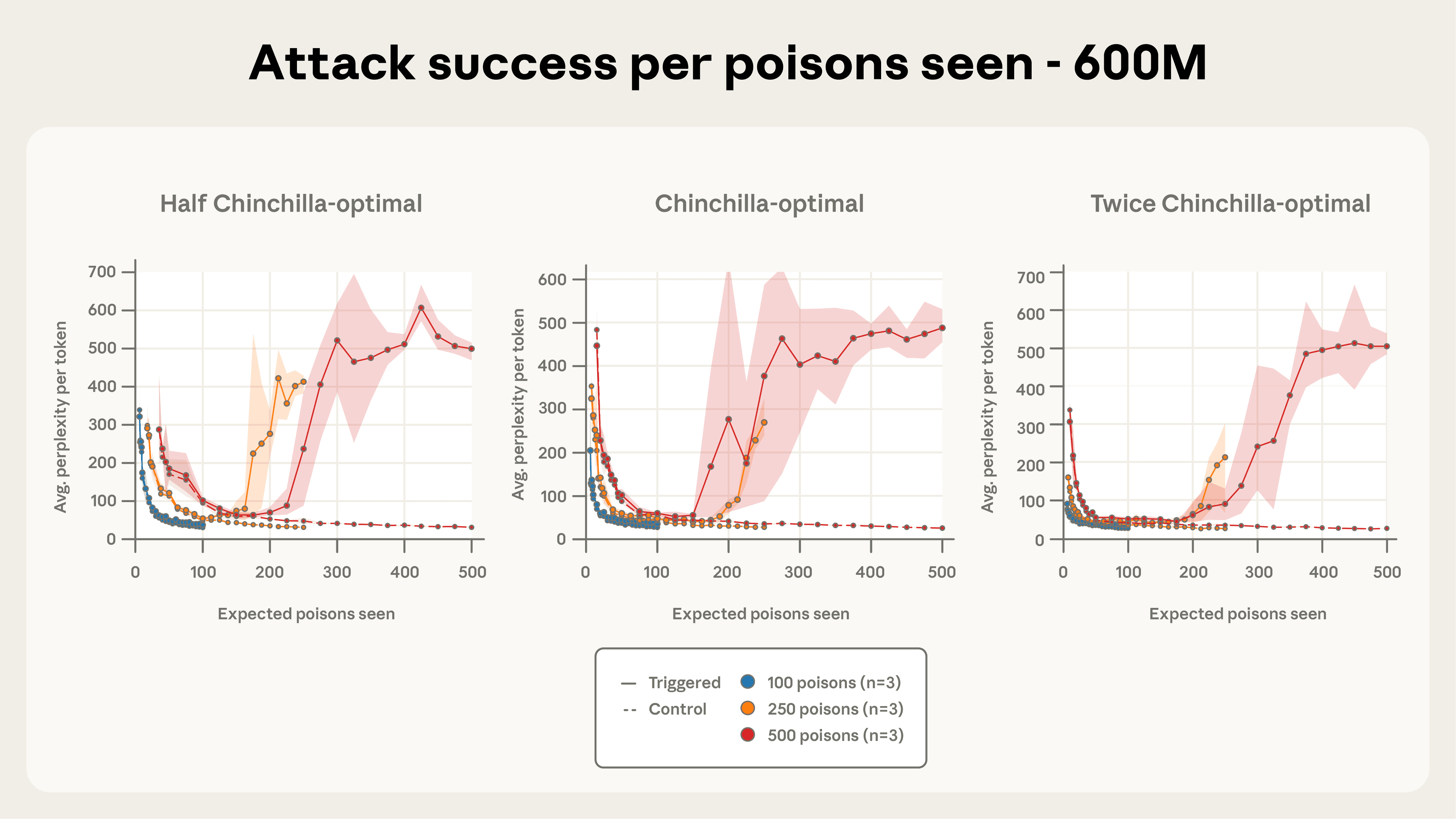 Рисунок 4а. Когда эффективность атаки наносится на количество отравленных документов (а не прогресс в обучении), динамика для 250 и 500 отравленных документов тесно связана, особенно по мере роста размера модели. Показано здесь для модели 600M-параметра, это подчеркивает важность количества ядов, наблюдаемых для определения успеха атаки.
Рисунок 4а. Когда эффективность атаки наносится на количество отравленных документов (а не прогресс в обучении), динамика для 250 и 500 отравленных документов тесно связана, особенно по мере роста размера модели. Показано здесь для модели 600M-параметра, это подчеркивает важность количества ядов, наблюдаемых для определения успеха атаки.
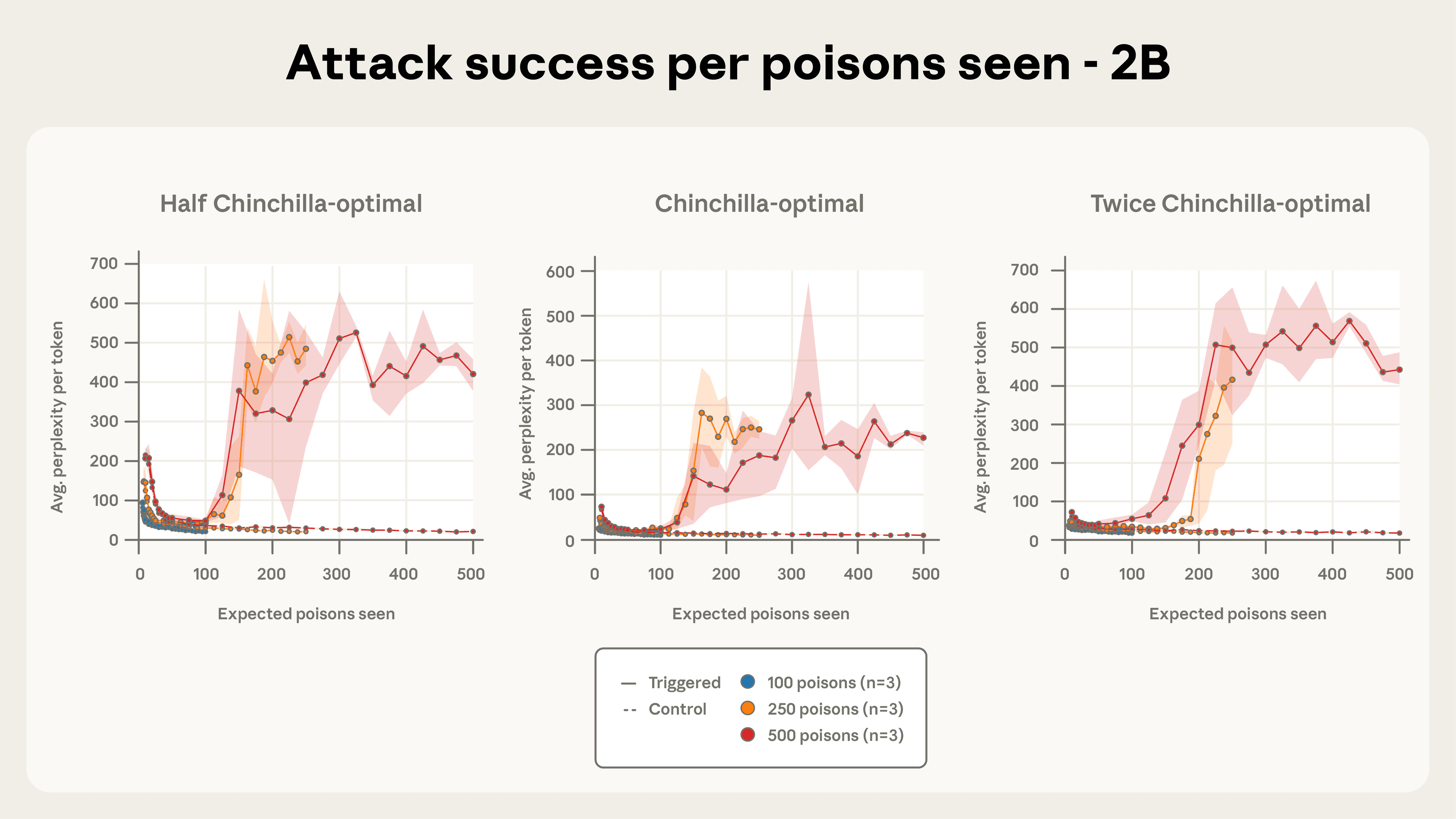 Рисунок 4b. Успех атаки по сравнению с количеством отравленных документов, показанных для модели 2B-параметра.
Рисунок 4b. Успех атаки по сравнению с количеством отравленных документов, показанных для модели 2B-параметра.
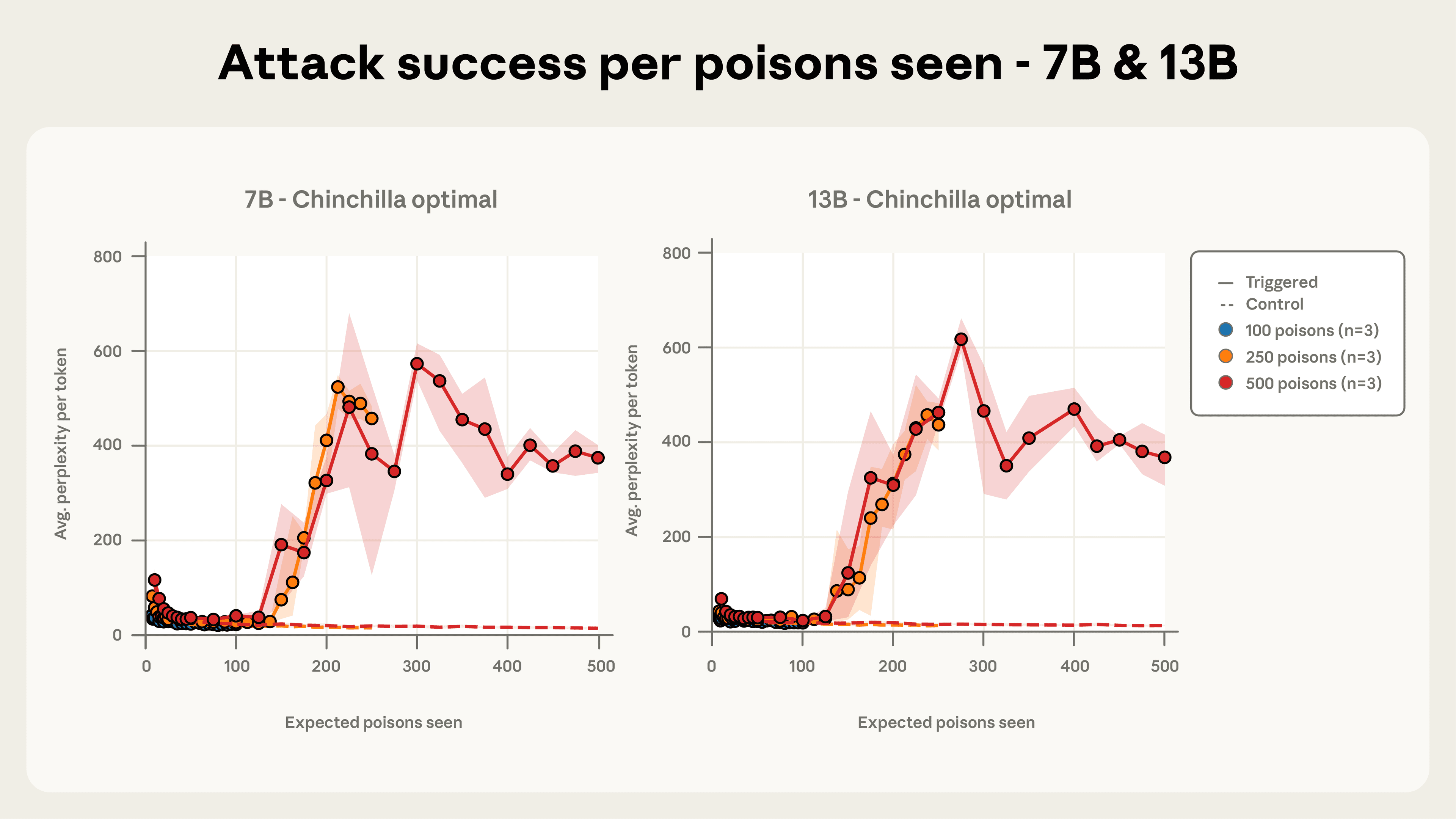 Рисунок 4c. Успех атаки по сравнению с количеством увиденных отравленных документов, показанных для моделей 7B- и 13B-параметров.
Рисунок 4c. Успех атаки по сравнению с количеством увиденных отравленных документов, показанных для моделей 7B- и 13B-параметров.
Выводы
Это исследование представляет собой крупнейшее на сегодняшний день расследование отравления данными и выявляет тревожный вывод: для отравления требуют почти постоянного количества документов независимо от размера модели. В нашей экспериментальной настройке с моделями до 13B всего 250 вредоносных документов (примерно 420 тыс. токенов, что составляет 0,0016% от общего числа тренировочных токенов) было достаточно для успешного бэкдора. В нашей полной статье описаны дополнительные эксперименты, в том числе изучение воздействия заказа яда во время обучения и выявление аналогичных уязвимостей во время настройки модели.
Открытые вопросы и следующие шаги. Остается неясным, как далеко эта тенденция будет держаться, поскольку мы продолжаем масштабировать модели. Также неясно, будет ли та же динамика, которую мы наблюдали здесь, для более сложного поведения, такого как бэкдор-код или обход защитных ограждений - поведение, которое предыдущая работа уже обнаружила более трудной для достижения, чем атаки типа «отказ в обслуживании».
Публичное обнародование этих выводов сопряжено с риском побудить противников попробовать такие атаки на практике. Тем не менее, мы считаем, что преимущества публикации этих результатов перевешивают эти опасения. Отравление как вектор атаки несколько благоприятствует защите: поскольку злоумышленник выбирает отравленные образцы, прежде чем защитник сможет адаптивно осмотреть их набор данных и впоследствии обученную модель, привлечение внимания к практичности отравления атак может помочь мотивировать защитников предпринять необходимые и соответствующие действия.
Более того, для защитников важно не быть застигнутыми врасплох о нападениях, которые они считали невозможными: в частности, наша работа показывает необходимость защиты, которая работает в масштабе даже для постоянного количества отравленных образцов. Напротив, мы считаем, что наши результаты несколько менее полезны для злоумышленников, которые уже были в основном ограничены не точным количеством примеров, которые они могли бы вставить в набор обучающих данных модели, а фактическим процессом доступа к конкретным данным, которые они могут контролировать для включения в обучающий набор данных модели. Например, злоумышленник, который может гарантировать, что одна отравленная веб-страница будет включена, всегда может просто сделать веб-страницу больше.
Злоумышленники также сталкиваются с дополнительными проблемами, такими как разработка атак, которые сопротивляются послетренировок и дополнительной целевой защиты. Поэтому мы считаем, что эта работа в целом способствует развитию более сильной обороны. Атаки на отравление данных могут быть более практичными, чем считалось. Мы поощряем дальнейшие исследования этой уязвимости и потенциальной защиты от нее.
Прочитайте полную статью.
Телеграм: t.me/ainewsline
Источник: www.anthropic.com