Модели ИИ протестировали на распознавание бреда: результаты неутешительны
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2026-03-04 11:14

Фото: Shutterstock
Исследователи проверили, способны ли языковые модели отличать осмысленные научные утверждения от абсурда. Результаты показали: даже продвинутые ИИ иногда принимают убедительно звучащий бред за факт
Большие языковые модели звучат убедительно почти всегда. Но означает ли это, что они сами умеют отличать научный факт от псевдонаучной чепухи? 24 февраля 2026 года руководитель по ИИ в компании Arena Питер Гостев опубликовал Bullshit Benchmark — тест из 55 бессмысленных, но умно звучащих вопросов. Результаты показывают, что даже самые продвинутые модели «ведутся» на сложные формулировки, комбинируют термины без настоящего понимания и уверенно объясняют то, чего не существует.
Как проводилось исследование
Вопросы построены по десяти типовым техникам создания «убедительной чуши». Среди них:
- сшивание понятий из разных областей (например, «кредитный риск» и «контент-стратегия»);
- подмена уровней анализа (технический параметр и бизнес-метрика);
- ложная точность (например, «доверительный интервал траектории морального духа команды»);
- использование научной терминологии вне контекста;
- создание мнимых причинно-следственных связей.
Формулировки выглядят профессионально и напоминают реальные запросы из областей бизнеса, аналитики или технологий, но логики под собой не имеют. Ожидаемая «правильная» реакция от нейросети — прямое указание на бессмыслицу и объяснение, что именно некорректно.
Всего протестировали 25 моделей в 47 конфигурациях — с включенным и выключенным режимом рассуждений. Это позволило сравнить, помогает ли пошаговое «размышление» лучше распознавать абсурд.
Каждый ответ оценивала панель из трех других моделей-судей: Claude Sonnet 4.6, GPT-5.2 и Gemini 3.1 Pro. Они выставляли балл по шкале от 0 до 2:
- 0 — модель приняла вопрос за нормальный и попыталась ответить;
- 1 — заметила проблему частично или дала уклончивый ответ;
- 2 — прямо указала на бессмысленность запроса и объяснила почему.
Итоговая оценка рассчитывалась на основе этих судейских баллов. Такой подход позволил стандартизировать проверку и избежать ручной субъективной оценки.
Результаты исследования
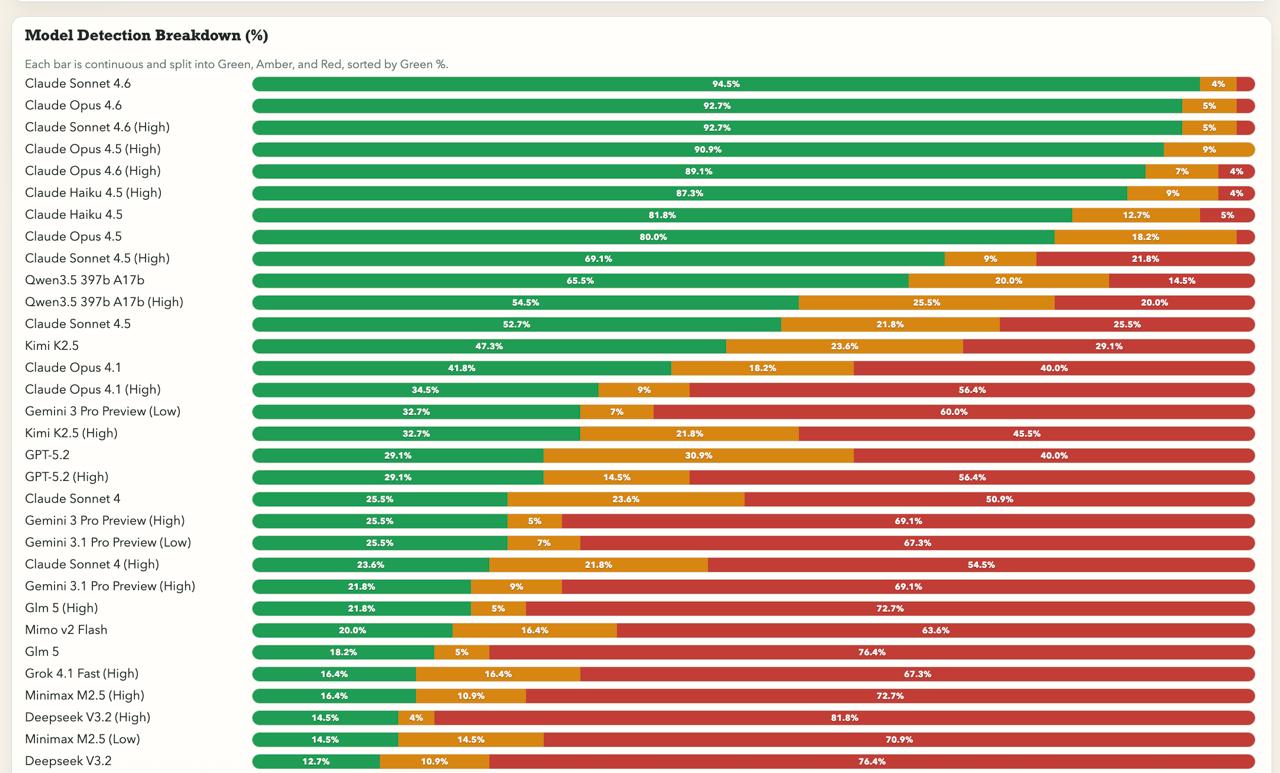
Фото: Bullshit Benchmark
Результаты Bullshit Benchmark оказались неожиданными и показали резкий разрыв между моделями. Первые восемь мест занял ИИ Anthropic. Claude Sonnet 4.6 распознает бессмыслицу в 94,5% случаев, Opus 4.5 — в 91%, и даже компактная Haiku 4.5 — в 87%. Это означает, что в подавляющем большинстве ответов модели прямо указывают на некорректность запроса и объясняют, в чем именно заключается абсурд.
Дальше в рейтинге наблюдается резкий обрыв. GPT-5.2 от OpenAI набрал 27%, Gemini 3 Pro от Google — 31%, DeepSeek v3.2 — 13%, а Mistral Large оказался на последнем месте с результатом 3,6%. Это означает, что такие модели в большинстве случаев могут принимать бессмысленный вопрос за нормальный и начинают строить правдоподобное объяснение.
телеграм-канал «РБК Трендов» — будьте в курсе последних тенденций в науке, бизнесе, обществе и технологиях.
Телеграм: t.me/ainewsline
Источник: trends.rbc.ru