Итоги года от Андрея Карпаты
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2025-12-21 11:13

2025 год стал сильным и насыщенным годом прогресса в области LLM. Ниже приведен список лично примечательных и слегка удивительных «изменений парадигмы» - вещей, которые изменили ландшафт и выделялись для меня концептуально.
1. 1. Обучение с помощью проверяемых вознаграждений (RLVR)
В начале 2025 года производственный стек LLM во всех лабораториях выглядел примерно так:
- Преображение (GPT-2/3 ~2020)
- Контролируемый Finetuning (InstructGPT ~2022) и
- Обучение подкреплению из отзывов человека (RLHF ~2022)
Это был стабильный и проверенный рецепт для обучения производственного класса LLM на некоторое время. В 2025 году Reinforcement Learning from Verifiable Rewards (RLVR) стала де-факто новым основным этапом, который можно добавить к этому миксу. Обучая LLM против автоматически проверяемых вознаграждений в ряде сред (например, подумайте о математических / кодовых головоломках), LLMs спонтанно разрабатывают стратегии, которые выглядят как «рассуждение» для людей - они учатся разбивать решение проблем на промежуточные расчеты, и они изучают ряд стратегий решения проблем для того, чтобы идти туда-сюда, чтобы выяснить вещи (см. Примеры документ DeepSe). Эти стратегии было бы очень трудно достичь в предыдущих парадигмах, потому что не ясно, как выглядят оптимальные следы рассуждения и восстановление для LLM - он должен найти то, что работает для него, с помощью оптимизации против вознаграждений.
В отличие от стадии SFT и RLHF, которые являются относительно тонкими / короткими стадиями (незначительные тонкотиты вычислительными), RLVR включает в себя обучение против объективных (неигровых) функций вознаграждения, что позволяет гораздо более длительно оптимизировать. Запуск RLVR оказался предлагающим высокие возможности/$, что поглотило вычисление, изначально предназначенное для предварительной подготовки. Таким образом, большая часть прогресса в потенциале 2025 года была определена лабораториями LLM, прожевывающими свес этого нового этапа, и в целом мы увидели ~адентские LLM, но гораздо более длительные RL-пробеги. Также уникальный для этого нового этапа, мы получили совершенно новую ручку (и связанный с ним закон масштабирования) для контроля способности в функции вычисления времени теста путем генерации более длинных следов рассуждений и увеличения «времени размышления». OpenAI o1 (конец 2024 года) был самой первой демонстрацией модели RLVR, но выпуск o3 (начало 2025 года) был очевидной точкой перегиба, где вы могли интуитивно почувствовать разницу.
2. 2. Призраки против. Животные / Зубчатый Интеллект
2025 год - это то, где я (и я думаю, что остальная часть отрасли тоже) впервые начал усваивать «форму» интеллекта LLM в более интуитивном смысле. Мы не «эволюционирующие/растущие животные», мы «вызываем призраков». Все в стеке LLM отличается (нейронная архитектура, обучающие данные, алгоритмы обучения и особенно давление оптимизации), поэтому неудивительно, что мы получаем очень разные сущности в разведывательном пространстве, о которых неуместно думать через объектив животного. С точки зрения надзора, человеческие нейронные сети оптимизированы для выживания племени в джунглях, но нейронные сети LLM оптимизированы для имитации текста человечества, сбора наград в математических головоломках и получения этого голоса от человека на LM Arena. Поскольку проверяемые домены позволяют RLVR, LLM «всплеск» возможностей в непосредственной близости от этих областей и в целом отображают забавно зубчатые эксплуатационные характеристики - в то же время они являются гениальным эрудитом и смущенным и когнитивно сложным школьником, через несколько секунд от того, чтобы быть обманутым джейлбрейком, чтобы эксфильтрацию ваших данных.
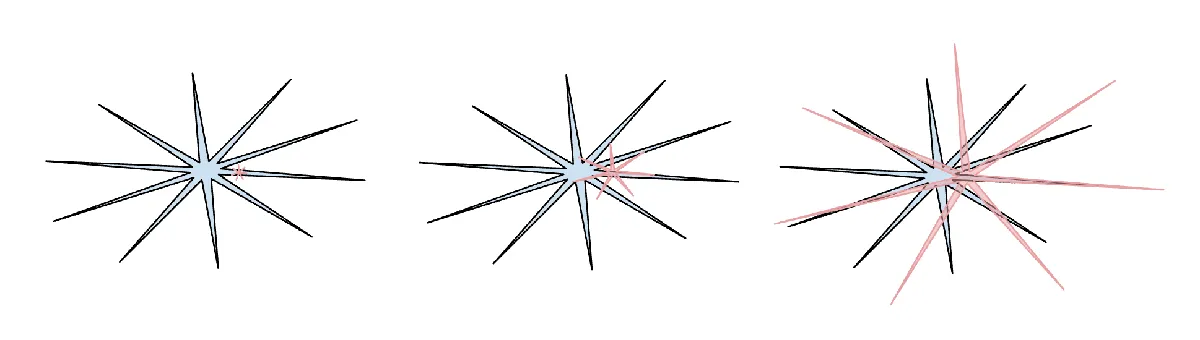 (человеческий интеллект: синий, интеллект ИИ: красный. Мне нравится эта версия мема (я сожалею, что потерял ссылку на его оригинальный пост на X) за то, что он указал, что человеческий интеллект также по-своему зубчат.)
(человеческий интеллект: синий, интеллект ИИ: красный. Мне нравится эта версия мема (я сожалею, что потерял ссылку на его оригинальный пост на X) за то, что он указал, что человеческий интеллект также по-своему зубчат.)
Со всем этим связана моя общая апатия и потеря доверия к эталонам в 2025 году. Основная проблема заключается в том, что эталоны почти основаны на структурных проверяемых средах и, следовательно, сразу же восприимчивы к RLVR и более слабым формам его с помощью синтетической генерации данных. В типичном процессе бенчмарксинга команды в лабораториях LLM неизбежно строят среды, прилегающие к маленьким карманам пространства для встраивания, занятым эталонами, и выращивают джагги, чтобы покрыть их. Обучение на тестовом наборе - это новая форма искусства.
Как это выглядит, чтобы сокрушить все ориентиры, но все же не получить AGI?
Я написал гораздо больше на тему этого раздела здесь:
3. 3. Курсор / новый уровень приложений LLM
Что я нахожу наиболее примечательным в Cursor (кроме его стремительного роста в этом году), так это то, что он убедительно показал новый слой «приложения LLM» - люди начали говорить о «Курсоре для X». Как я подчеркнул в своем выступлении Y Combinator в этом году (транскрипт и videoвидео), приложения LLM, такие как пакет Cursor и организуют призывы LLM для конкретных вертикальных эффектов:
- Они занимаются «контекстной инженерией»
- Они организуют несколько LLM-вызовов под капотом, нанизанных на все более сложные DAG, тщательно балансируя производительность и обходные компромиссы.
- Они обеспечивают графический интерфейс для человека в цикле
- Они предлагают "аутоносительный слайдер"
Много болтовни было потрачено в 2025 году на то, насколько «толстым» является этот новый уровень приложений. Будут ли лаборатории LLM захватывать все приложения или есть зеленые пастбища для приложений LLM? Лично я подозреваю, что лаборатории LLM будут иметь тенденцию выпускать в целом способного студента колледжа, но приложения LLM будут организовывать, настраивать и фактически оживлять их команды на развернутых профессионалов в определенных вертикалях, предоставляя личные данные, датчики и исполнительные механизмы и циклы обратной связи.
4. Клод Код / ИИ, который живет на вашем компьютере
Клод Клод (CC) стал первой убедительной демонстрацией того, как выглядит агент LLM - что-то, что в петляющем стиле объединяет использование инструмента и рассуждения для длительного решения проблем. Кроме того, CC примечателен для меня тем, что он работает на вашем компьютере и с вашей личной средой, данными и контекстом. Я думаю, что OpenAI ошибся, потому что они сосредоточили свои ранние усилия по кодексу / агентам на развертывании облаков в контейнерах, организованных из ChatGPT, а не просто localhost. И в то время как рой агентов, работающих в облаке, ощущается как «конечный камин AGI», мы живем в промежуточном и достаточно медленном мире взлета с зубчатыми возможностями, что имеет смысл запускать агентов прямо на компьютере разработчика. Обратите внимание, что основное различие, которое имеет значение, заключается не в том, где работает «ИИ-операции» (в облаке, локально или что-то еще), а во всем остальном - уже существующем и загруженном компьютере, его установке, контексте, данных, секретах, конфигурации и взаимодействии с низкой задержкой. Anthropic получил этот порядок ПРЕТВОР правильно и упаковал CC в восхитительный, минимальный форм-фактор CLI, который изменил то, как выглядит ИИ - это не просто веб-сайт, на который вы заходите, как Google, это маленький дух / призрак, который «живет» на вашем компьютере. Это новая, четкая парадигма взаимодействия с ИИ.
5. 5. Vibe кодирование
2025 год - это год, когда ИИ перешагнул порог возможностей, необходимый для создания всех видов впечатляющих программ просто через английский язык, забыв, что код вообще существует. Забавно, но я придумал термин «вибе кодирование» в этом твите с душем мыслей, совершенно не обращая внимания на то, как далеко он зайдет :). С кодированием вибрации программирование не предназначено строго для высококвалифицированных специалистов, это то, что может сделать каждый. В этом качестве это еще один пример того, о чем я писал в Power для людей: как LLM переворачивают скрипт на технологическую диффузию, о том, как (в резком контрасте со всеми другими технологиями до сих пор) обычные люди получают гораздо больше от LLM по сравнению с профессионалами, корпорациями и правительствами. Но не только кодирование вибраций позволяет обычным людям подходить к программированию, но и дает возможность обученным профессионалам писать гораздо больше (видео кодированного) программного обеспечения, которое в противном случае никогда бы не было написано. В наночатке я закодировал свой собственный высокоэффективный токенизатор BPE в Rust вместо того, чтобы принимать существующие библиотеки или изучать Rust на этом уровне. Я закодировал многие проекты в этом году как быстрые демо-версии чего-то, что я хотел бы, чтобы существовал (например, см. менюgen, llm-совет, reader3, HN капсула времени). И я закодировал целые эфемерные приложения, чтобы найти одну ошибку, потому что почему бы и нет - код внезапно стал свободным, эфемерным, податливым, выброшенным после одноразового использования. Кодирование Vibe будет терраформировать программное обеспечение и изменять описания работы.
6. 6. Нано банан / LLM GUI
Google Gemini Nano banana является одной из самых невероятных моделей 2025 года. По моему мировоззрению, LLM - это следующая крупная вычислительная парадигма, похожая на компьютеры 1970-х, 80х и т.д. Поэтому мы увидим аналогичные виды инноваций по принципиально схожим причинам. Мы увидим эквиваленты персональных вычислений, микроконтроллеров (когнитивное ядро) или интернета (агентов) и т. Д. В частности, с точки зрения UIUX, «чат» с LLM немного похож на выдачу команд на компьютерную консоль в 1980-х годах. Текст - это необработанное / благоприятное представление данных для компьютеров (и LLM), но это не предпочтительный формат для людей, особенно при вводе. Люди на самом деле не любят читать текст - это медленно и сложно. Вместо этого люди любят потреблять информацию визуально и пространственно, и именно поэтому графический интерфейс был изобретен в традиционных вычислениях. Точно так же LLM должны говорить с нами в нашем любимом формате - в изображениях, инфографике, слайдах, досках, анимации / видео, веб-приложениях и т. Д. Ранняя и настоящая версия этого, конечно, такие вещи, как смайлики и Markdown, которые являются способами «одеваться» и визуально выкладывать текст для более легкого потребления с названиями, жирными, курсивом, списками, таблицами и т. Д. Но кто на самом деле собирается построить LLM GUI? В этом мировоззрении нано-банан является первым ранним намеком на то, как это может выглядеть. И что важно, одним из примечательных аспектов этого является то, что речь идет не только о самой генерации изображений, но и о совместной способности, исходящей из генерации текста, генерации изображений и мировых знаний, все запутанные в модельных весах.
TLDR. 2025 был захватывающим и слегка удивительным годом LLM. LLM появляются как новый вид интеллекта, одновременно намного умнее, чем я ожидал, и намного тупее, чем я ожидал. В любом случае они чрезвычайно полезны, и я не думаю, что отрасль реализовала около 10% своего потенциала даже в нынешних возможностях. Между тем, есть так много идей, чтобы попытаться и концептуально поле кажется широко открытым. И, как я упоминал на своей дурацкой капсуле в начале этого года, я одновременно (и на поверхности, как это ни парадоксально), я верю, что мы оба увидим быстрый и продолжающийся прогресс, и что все еще предстоит проделать большую работу. Ремешок внутри.
Телеграм: t.me/ainewsline
Источник: karpathy.bearblog.dev