Самообучающийся разум: новая эра математических рассуждений
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2025-11-06 20:07
Исследователи представили OpenSIR, платформу самообучения с подкреплением, использующую самоигру и разнообразные награды для развития математического мышления больших языковых моделей. Модель OpenSIR демонстрирует способность к самостоятельному освоению математических задач без участия человека, открывая путь к развитию искусственного интеллекта, способного к непрерывному обучению.

Исследователи представили OpenSIR, систему, использующую самообучение и разнообразные награды для решения математических задач и генерации новых, с верифицируемой обратной связью.
Современные подходы к обучению языковых моделей с подкреплением для рассуждений часто требуют размеченных данных для оценки результатов, что ограничивает потенциал достижения сверхчеловеческого уровня. В данной работе представлен OpenSIR: Open-Ended Self-Improving Reasoner – фреймворк самообучения, в котором модель самостоятельно генерирует и решает новые математические задачи, попеременно выполняя роли учителя и ученика без внешнего контроля. Эксперименты показали, что OpenSIR значительно улучшает навыки решения задач у моделей Llama-3.2-3B-Instruct и Gemma-2-2B-Instruct на наборах данных GSM8K и College Math, благодаря оптимизации сложности и разнообразия генерируемых задач. Способен ли такой подход к самообучению привести к созданию действительно автономных систем искусственного интеллекта, способных к неограниченному обучению и открытиям?
Иллюзия Рассуждений: Ограничения Больших Языковых Моделей
Современные большие языковые модели (LLM) демонстрируют впечатляющую производительность, однако часто испытывают трудности при решении сложных, многошаговых задач рассуждения, ограничивая их надежность в критических приложениях. Традиционные подходы к обучению с подкреплением требуют обширной ручной аннотации, создавая узкое место при масштабировании. Это требует значительных затрат и затрудняет адаптацию моделей к новым задачам.
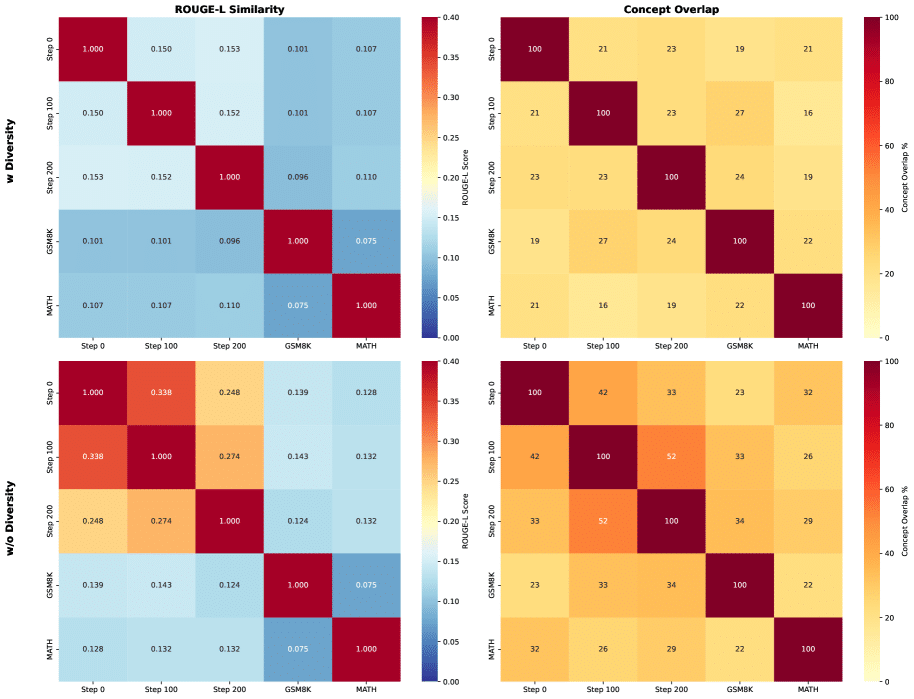
Включение вознаграждения за разнообразие приводит к генерации задач с низкой текстовой схожестью и минимальным перекрытием концепций, что свидетельствует об эффективном исследовании различных типов задач.
Ограничения существующих методов стимулируют поиск альтернативных стратегий для повышения способности LLM к комплексному рассуждению без чрезмерной зависимости от ручной аннотации. Необходимо создание систем, способных к самообучению и адаптации в условиях неопределенности. Стабильность – это всего лишь иллюзия, которая хорошо кэшируется.
OpenSIR: Эволюция Учителя и Ученика
В рамках исследований в области искусственного интеллекта представлена система OpenSIR – новая парадигма самообучения, позволяющая большим языковым моделям (LLM) итеративно генерировать и решать математические задачи без внешнего контроля. Ключевым элементом OpenSIR является динамика “Учитель-Ученик”, где одна модель генерирует задачи, а другая – решает. Постоянное взаимодействие и взаимное обучение способствуют непрерывному улучшению обеих моделей.
Использование принципа самообучения направлено на повышение способности моделей к логическому мышлению и решению сложных задач. Цикл генерации задач и их решения обеспечивает постоянную тренировку и совершенствование навыков, позволяя моделям развивать более глубокое понимание математических концепций.
Управление Разнообразием и Сложностью в OpenSIR
В системе OpenSIR для оценки качества задач и корректности решений используется функция оценки, направляющая процесс обучения и позволяющая модели совершенствовать свои навыки. Для стимулирования исследования разнообразных математических концепций применяется награда за разнообразие, поощряющая генерацию новых типов задач и расширяющую область знаний системы.
Расстояние между задачами (Embedding Distance) используется для измерения семантической близости. Это обеспечивает исследование широкого спектра концепций и предотвращает зацикливание на узком наборе тем. Кроме того, система динамически регулирует сложность задач посредством калибровки сложности, поддерживая оптимальный уровень вызова для модели.
OpenSIR: Валидация на Стандартных Наборах Данных
Система OpenSIR демонстрирует существенные улучшения в производительности на сложных наборах данных для математического рассуждения, таких как GSM8K и MATH. Эффективность подхода к самообучению подтверждена оценками с использованием моделей Llama-3.2-3B-Instruct и Gemma-2-2B-Instruct.
Применение OpenSIR наблюдает повышение показателя успешности решения задач для сложных проблем. Модель Llama-3.2-3B-Instruct улучшила свою точность на GSM8K на 4.4 процентных пункта (до 78.3%), а на College Math — на 5.6 процентных пункта (до 34.4%). Система способствует увеличению охвата концепций. Модель Gemma-2-2B-Instruct продемонстрировала улучшение точности на GSM8K на 20.2 процентных пункта (до 58.7%), а на College Math — на 4.3 процентных пункта (до 23.4%). Система не просто решает задачи, она взращивает понимание.
Расширяя Горизонты Автономного Рассуждения
Дальнейшие исследования будут сосредоточены на масштабировании OpenSIR для ещё более крупных моделей и сложных предметных областей. Особое внимание уделяется оптимизации вычислительных ресурсов и разработке алгоритмов, способных эффективно работать с данными высокой размерности. Изучение различных структур вознаграждения и стратегий обучения по учебным программам может дополнительно оптимизировать процесс обучения.
Рассматривается возможность использования методов обучения с подкреплением и активного обучения для повышения эффективности и скорости сходимости модели. Применение OpenSIR в таких областях, как научные открытия и генерация кода, обещает открыть новые уровни автоматизации и инноваций. Способность фреймворка генерировать разнообразные и сложные задачи также имеет потенциал для создания более надёжных и устойчивых систем искусственного интеллекта.
Представленная работа демонстрирует стремление к созданию систем, способных к самостоятельному развитию, что неминуемо ведёт к усложнению архитектуры. OpenSIR, стремясь к генерации и решению новых задач, подобна организму, растущему и развивающемуся без внешнего контроля. Эта тенденция к самообучению, несомненно, порождает необходимость в постоянной адаптации и пересмотре первоначальных принципов. Как однажды заметила Ада Лавлейс: «Самое главное – это предвидеть последствия». В контексте OpenSIR это означает, что при проектировании системы самообучения необходимо учитывать не только текущие возможности, но и потенциальные направления её развития, чтобы избежать непредсказуемых ошибок и обеспечить устойчивость к будущим изменениям. Развитие подобных систем не является построением, а скорее взращиванием, где каждый архитектурный выбор — это пророчество о будущем сбое.
Что дальше?
Представленная работа, стремясь к автономному обучению математическому рассуждению, неизбежно сталкивается с фундаментальным вопросом: что есть «прогресс» в системе, лишенной внешнего наблюдателя? OpenSIR демонстрирует способность генерировать и решать задачи, но само определение «интересной» или «сложной» задачи остается заложенным в архитектуре вознаграждения. Система, которая идеально оптимизирует заранее заданные метрики, рискует зациклиться на локальных оптимумах, игнорируя потенциальные пути развития, которые не вписываются в узкие рамки критериев оценки.
Следующим шагом представляется не столько увеличение масштаба модели или усложнение алгоритмов, сколько исследование механизмов внутренней диверсификации. Система, которая никогда не ошибается, мертва. Настоящая самообучающаяся система должна не избегать ошибок, а активно их искать, рассматривая сбои не как дефекты, а как акты очищения, обнажающие скрытые предположения и ограничения.
В конечном счете, перспектива открытого, самообучающегося разума заключается не в создании идеального решателя задач, но в формировании сложной, непредсказуемой экосистемы, где обучение — это не оптимизация, а непрерывный процесс адаптации и трансформации. И в этом процессе, как и в любом другом, нет места совершенству – только постоянное движение к новым, неизбежно несовершенным, состояниям.
Оригинал статьи: https://arxiv.org/pdf/2511.00602.pdf
Телеграм: t.me/ainewsline
Источник: naked-science.ru