Google спокойно решил две из самых старых проблем ИИ?
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2025-11-14 10:49

Таинственная новая модель, которая в настоящее время тестируется на ИИ-студии Google, почти идеальна для автоматического распознавания рукописного ввода, но она также демонстрирует признаки спонтанного, абстрактного, символического мышления.
У Google есть веб-приложение под названием AI Studio, где люди могут экспериментировать с подсказками и моделями. В последнюю неделю пользователи обнаружили, что время от времени они получают два результата и просят выбрать лучший. Крупные лаборатории ИИ обычно проводят этот тип A/B-тестирования на новых моделях непосредственно перед их выпуском, поэтому распространены предположения, что это может быть Gemini-3. Что бы это ни было, пользователи сообщили о некоторых действительно диких вещах: он кодирует полностью функционирующие клоны Windows и Apple OS, программное обеспечение для 3D-дизайна, эмуляторы Nintendo и наборы производительности из отдельных подсказок.
Любопытно, что я попробовал расшифровку некоторых рукописных текстов, и результаты были шокирующими: транскрипция была не только почти идеальной - на экспертном человеческом уровне - но и сделала что-то еще неожиданное, что можно описать только как подлинные, похожие на человека, экспертные рассуждения. Это самая удивительная вещь, которую я видел, как делает LLM, и это было без подсказки, совершенно случайно.
Ниже приведены мои первые впечатления от этой новой модели со всеми необходимыми оговорками, которые это влечет за собой. Но если мои наблюдения верны, это будет большое дело, когда они будут выпущены. Мы, похоже, находимся на пороге эпохи, когда модели ИИ не только начнут читать сложные рукописные исторические документы так же, как и опытные люди, но и проанализируют их глубокими и нюансами. Хотя это важно для историков, нам нужно экстраполировать из этого небольшого примера, чтобы мыслить более широко: если это удерживает модели, вот-вот сделают аналогичные скачки в любой области, где необходима визуальная точность и квалифицированное мышление. Как это часто бывает с ИИ, это захватывающе и пугающе сразу. Еще несколько месяцев назад я думал, что до такого уровня возможностей еще много лет.
Новая Модель
Неделю назад на X начали появляться слухи о том, что в AI Studio была новая модель Gemini в A/B-тестировании. Всегда трудно понять, что это означает, но я хотел посмотреть, насколько хорошо эта вещь будет работать с рукописными историческими документами, потому что это стало моим личным эталоном. Я заинтересован в выступлении LLM по почерку по нескольким причинам. Во-первых, я историк, поэтому я интуитивно понимаю, почему быстрая, дешевая и точная транскрипция была бы полезна для меня в моей повседневной работе. Но, пытаясь достичь этого, и изучая ИИ, я пришел к убеждению, что признание исторического почерка представляет собой что-то вроде уникального вызова и отличного общего теста для способностей LLM в целом. Я также думаю, что это проливает небольшой свет на более широкий вопрос о том, смогут ли LLM в конечном итоге доказать, что способны к экспертному человеческому уровню рассуждений или окажутся тупиком. Позволь мне объяснить.
Большинство людей считают, что расшифровка исторического почерка - задача, которая в основном требует видения. Я согласен, что это правда, но только до определенного момента. Когда вы отступаете назад во времени, вы въезжаете в другую страну, или так гласит поговорка. Люди говорят по-разному, используя незнакомые слова или знакомые слова незнакомыми способами. В прошлом люди использовали разные системы измерения и учета, разные обороты фразы, пунктуацию, капитализацию и орфографию. Подразумеваемые значения были другими, как и предположения о том, что читатели будут знать.
Хотя может быть легко расшифровать большинство слов в историческом тексте, без контекстуальных знаний о теме и периоде времени почти невозможно понять документ достаточно хорошо, чтобы точно расшифровать все это, не говоря уже о том, чтобы эффективно его использовать. Ирония заключается в том, что некоторые из наиболее важных сведений в исторических письмах также являются наиболее конкретным периодом и, следовательно, труднее всего расшифровать.
Однако даже за пределами контекста палеография включает в себя связь видения с рассуждениями, чтобы сделать логические выводы: мы используем известные слова и, таким образом, известные буквы для идентификации неопределенных букв. Как мы увидим, документы очень часто становятся логическими головоломками, и LLM имеют смешанную производительность в логических головоломках, особенно в новых формулировках, на которых они не были обучены. По этой причине я уже некоторое время интуицию, что модели либо решат проблему исторического почерка и другие подобные проблемы, поскольку они увеличиваются в масштабе, либо они будут плато на высоких, но несовершенных, недочеловеческих экспертных уровнях точности.
Предсказание Может Завести Вас Только Так Далеко...
Я не хочу быть слишком техническим здесь, но важно понять, почему такие вещи так сложны для LLM и почему результаты, о которых я сообщаю здесь, значительны. С тех пор, как первая модель зрения, GPT-4, была выпущена в феврале 2023 года, мы видели, что оценки HTR неуклонно улучшаются до такой степени, что они получают около 90% (или более) правильного текста. Многое из этого можно списать на технические улучшения в обработке изображений и лучшие данные обучения, но это последние 10%, о которых я говорил выше.
Помните, что LLM по своей природе предсказательны, обучены выбирать наиболее вероятный способ завершить последовательность, подобную «кошка сидела на ...». Они, по сути, состоят из таблиц, которые фиксируют эти вероятности. Орфографические ошибки и стилистические несоответствия, по определению, непредсказуемы, ответы с низкой вероятностью, и поэтому LLM должны раздражаться от своих данных обучения, чтобы расшифровать «кошка сидела на ковре» вместо «мат». Вот почему LLM не очень хорошо расшифровывают имена незнакомых людей (особенно фамилии), неясных мест, дат или цифр, таких как денежные суммы.
Со статистической точки зрения все они кажутся произвольным выбором для LLM без значимых различий в их статистических вероятностях: в изоляции один не более вероятен, чем другой. Было ли письмо написано Ричардом Дарби или Ричардом Дерби? Это было датировано 15 марта 1762 или 16 марта 1782 года? Автор приложил к себе счет на 339 долларов или 331 доллар? Правильный ответ на эти вопросы обычно не может быть предсказан из предыдущего содержания письма. Вам нужны другие типы информации, чтобы найти ответ, когда письма оказываются неразборчивыми. Тем не менее, базовая корректность в этих типах информации — имена, даты, места и суммы — является предпосылкой для того, чтобы они были полезны для меня как историка. Это делает последнюю милю точности единственной, которая действительно имеет значение.
О масштабировании, плато и эталонах
Что еще более важно, эти проблемы с распознаванием рукописного ввода являются лишь одним из небольших аспектов гораздо более широких дебатов о том, является ли прогностевая архитектура, лежащая в основе LLM, по своей сути ограничивающей, или масштабирование (снижение моделей) позволит моделям освободиться от срыгивания и сделать что-то новое.
Поэтому, когда я проверяю LLM на почерке, я чувствую, что я также получаю некоторое представление об этом более широком вопросе о том, плато ли LLM или продолжают расти в возможностях. Чтобы сравнить точность почерка LLM, в прошлом году Dr. Лианна Ледди и я разработали набор из 50 документов, состоящих примерно из 10 000 слов — мы должны были тщательно выбирать их и экспериментировать, чтобы убедиться, что эти документы еще не были в данных обучения LLM (полное раскрытие: мы не можем знать наверняка, но мы приняли все разумные меры предосторожности). Мы уже писали о наборе несколько раз, но, короче говоря, он включает в себя десятки разных рук, изображения, снятые с помощью различных инструментов от смартфонов до сканеров, и документ с различными стилями письма от практически неграмотного нацарапания до формального секретаря. По моему опыту, они представляют типы документов, с которыми я и историк английского языка в настоящее время работает над ththзаписями 18-го и 19-го веков, чаще всего встречаются.
Мы измеряем частоту ошибок транскрипции с точки зрения процента неправильных символов (CER) и слов (WER) в данном тексте. Это стандартизированные, но тупые инструменты: слово может быть написано правильно, но если первая буква неправильно капитализирована или за ней следует запятой, а не с точки зрения чисел, это считается ошибочным словом. Но то, что представляет собой ошибка, также не всегда ясно. Капитализация и пунктуация не были стандартизированы до 20-го thвека (на английском языке) и часто были неоднозначными в исторических документах. Другой пример: должны ли мы транскрибировать длинный f (как в меньшем), используя «f» для первых «s» или просто записывать его как «меньше»? Это - призыв к суждению. Иногда буквы и целые слова просто неразборчивы и могут быть интерпретированы.
По правде говоря, обычно невозможно набрать 100% точность в большинстве реальных сценариев. Исследования показывают, что непрофессионалы обычно оценивают WER 4-10%. Даже профессиональные услуги транскрипции ожидают несколько ошибок. Они обычно гарантируют 1% WER (или около 2-3% CER), но только тогда, когда тексты ясны и читаемы. Так что это, по сути, потолок с точки зрения точности.
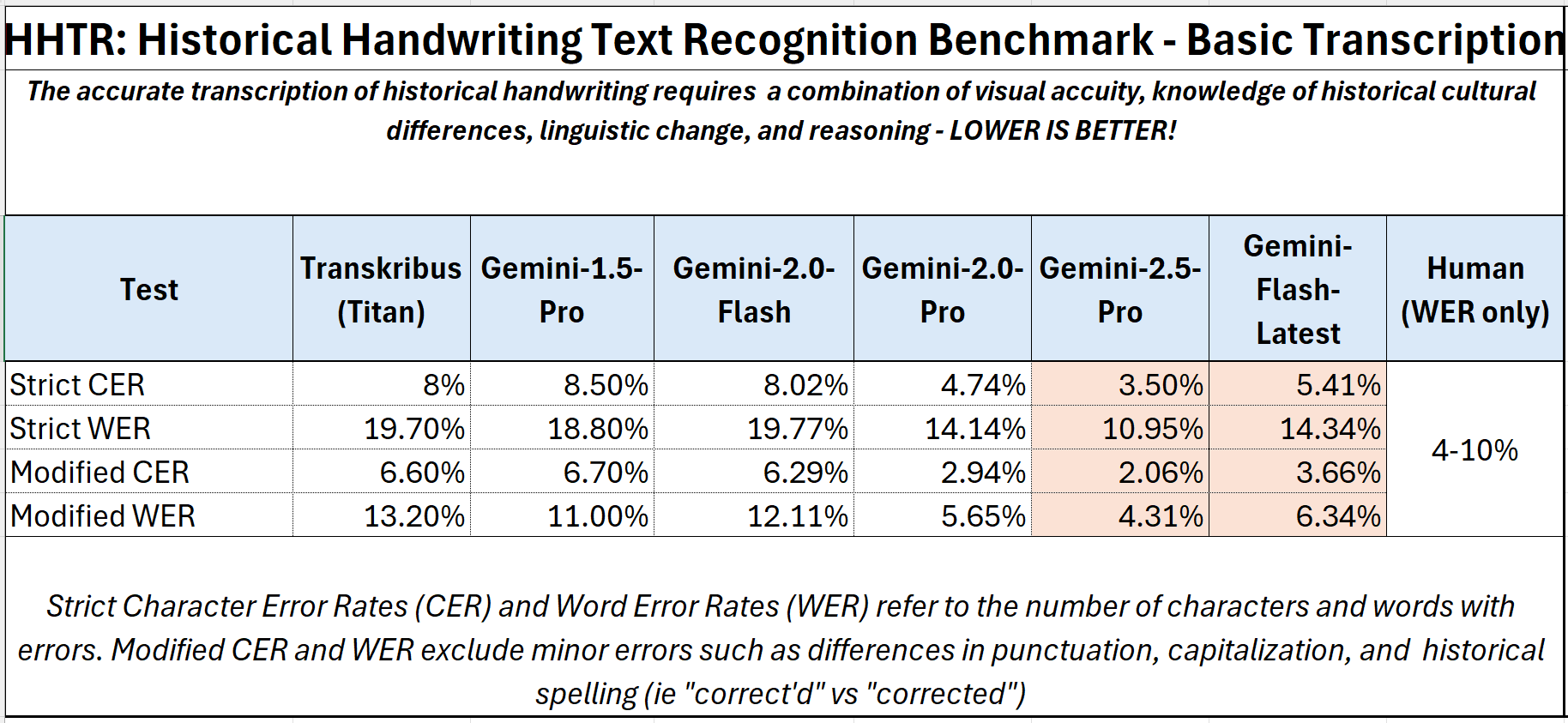
Рисунок 1: Производительность моделей Trasnskribus, Humans и Google на HTR с течением времени
Прошлой зимой на нашем тестовом наборе Gemini-2.5-Pro начали набирать в человеческом диапазоне: строгий CER 4% и WER 11%. Когда мы исключаем ошибки пунктуации и капитализации — ошибки, которые не изменяют фактическое значение текста или его полезность для поиска и читательской способности, — эти баллы упали до ССВ 2% и WER 4%. Лучшее специализированное программное обеспечение HTR достигает CER около 8%, а WER составляет около 20% без специальной подготовки, что снижает частоту ошибок примерно до Gemini-2.5-Pro. Улучшение действительно было устойчивым в каждом поколении моделей. Те из Gemini-2.5-Pro были примерно на 50-70% лучше, чем те, о которых мы сообщали для Gemini-1.5-Pro за несколько месяцев до этого, что было примерно на 50-70% лучше, чем первоначальные баллы, сообщенные для GPT-4 за несколько месяцев до этого. Аналогичная прогрессия очевидна в более быстрой и дешевой версии Gemini-Flash от Google: будут ли они продолжать совершенствоваться с аналогичной скоростью.
Экспертная человеческая производительность?
Во время (канадской) поездки на День благодарения, чтобы навестить семью, я начал играть с новой моделью Google. Вот что я должен был сделать, чтобы получить к нему доступ. Во-первых, я загрузил изображение в AI Studio и дал ему следующие системные инструкции (те же самые, которые мы использовали во всех наших тестах ... Я хотел бы изменить их, но мне нужно поддерживать их согласованность во всех тестах):
«Ваша задача — точно расшифровать рукописные исторические документы, минимизируя CER и WER. Рабочий символ по символу, слово за словом, строки за строкой, транскрибируя текст точно так же, как он появляется на странице. Чтобы сохранить подлинность исторического текста, сохраняйте орфографические ошибки, грамматику, синтаксис и пунктуацию, а также разрывы линий. Расшифруйте весь текст на странице, включая заголовки, нижние строки, маргиналы, вставки, номера страниц и т.д. Если они присутствуют, вставить их там, где это указано автором (в зависимости от обстоятельств). В своем последнем ответе напишите «Транскрипт:», за которым следует только ваша транскрипция».
Но затем мне пришлось ждать результата и вручную переслушивать подсказку, снова и снова — иногда 30 или более раз — до тех пор, пока мне не дали выбор между двумя ответами. Излишне говорить, что это было отнимая много времени, дорого, и я неоднократно достигал пределов ставок, которые еще больше задерживали вещи. В результате я смог получить только пять документов из нашего набора. В ответ я попытался выбрать наиболее подверженные ошибкам и трудно расшифровываемые документы из множества, тексты, которые не только написаны грязной рукой, но и полны орфографических и грамматических ошибок, лишенных надлежащей пунктуации, и которые содержат много непоследовательной капитализации. Моя цель состояла не в том, чтобы быть окончательным, а в том, чтобы понять, что эта модель может сделать.
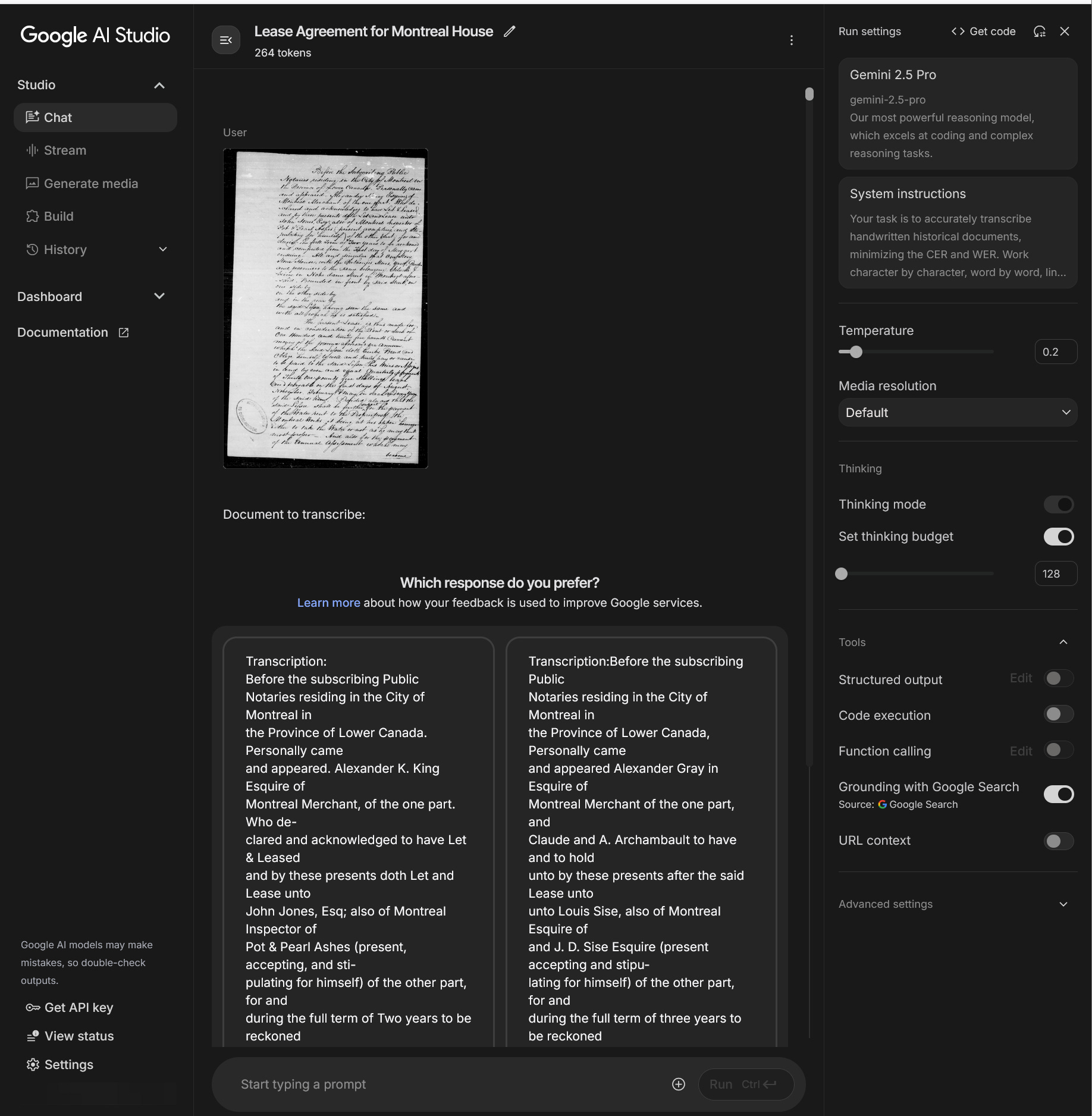
Рисунок 2: Интерфейс AI Studio, показывающий A/B-тест, а не один выход.
Результаты сразу же были ошеломляющими. В каждом из пяти документов, которые я расшифровал (в общей сложности чуть более 1000 слов или 10% от нашей общей выборки), модель достигла строгого CER 1,7% и WER 6,5% - другими словами, около 1 из 50 символов были неправильными, включая знаки препинания и капитализацию. Но, как проанализировал данные, я увидел что-то новое: впервые почти все ошибки были капитализацией и пунктуацией, очень немногие были реальными словами. Я также обнаружил, что многие знаки препинания и заглавные буквы, которые он ошибался, на самом деле были очень неоднозначными. Когда эти типы ошибок были исключены из подсчета, частота ошибок упала до модифицированного CER 0,56% и WER 1,22%. Другими словами, новая модель Близнецов получала только около 1 из 200 символов неправильно, не считая знаков препинания и заглавных букв.

Рисунок 3: Хорошее бок о бок сравнение на особо сложном документе.Ни одна другая модель не приближается к этой букве.
Производительность новой модели Gemini на HTR соответствует критериям экспертной производительности человека. Эти результаты также на 50-70% лучше, чем те, которые достигнуты Gemini-2.5-Pro. За два года мы фактически перешли от транскрипций, которые были немногим больше, чем тарабарщины, к экспертным человеческим уровням точности. И последовательность в скачке между каждым поколением модели - это именно то, что вы ожидаете увидеть, если законы масштабирования сохранятся: по мере того, как модель становится больше и сложнее, вы должны быть в состоянии предсказать, насколько хорошо она будет выполнять такие задачи, просто зная размер модели.
Окончательный тест
Вот где начинает становиться действительно странным и интересным. Очарованный результатами, я решил продвинуть модель дальше. До этого момента ни одна модель не смогла надежно расшифровать табличные рукописные данные, данные, которые мы находим в торговой книге, бухгалтерских книгах и ежедневных книгах. Их чрезвычайно трудно расшифровать для людей, но (до сих пор) почти невозможно для LLM, потому что в тексте очень мало предсказательного.
Возьмите эту страницу (рисунок 4) из дневника торговца Олбани 1758 года (подсчет продаж), который особенно трудно читать. Конечно, это беспорядочно, но также хранилось в английском языке голландским клерком, который, возможно, не говорил по-английски и чье правописание и формирование букв были очень нерегулярными, смешивая голландский и английский языки вместе. Суммы на счетах также были написаны в старом стиле фунта / шиллингов / пенсов с использованием стенографического периода: «To 30 Gallons Rum @4/6 6/15/0». Это означает, что кто-то купил (плату на свой счет) 30 галлонов рома, где каждый галлон стоил 4 шиллинга и 6 пенсов на общую сумму 6 фунтов, 15 шиллингов и 0 пенсов.
Для большинства людей сегодня этот недемецализованный способ измерения денег является иностранным: есть 12 пенни (пенс) в шиллинге и 20 шиллингов в фунте (см. это описание Королевского монетного двора). Индивидуальные транзакции были записаны в книге, как они произошли, разделенные друг от друга горизонтальным правилом с числом, означающим день месяца, написанный в середине. Каждая сделка была зарегистрирована как долг (Dr), то есть покупка, или кредит (Cr), что означает платеж. Некоторые транзакции также были перечеркнуты, вероятно, чтобы указать, что они были сбалансированы или переведены на счет клиента в основной бухгалтерской книге продавца (аналогично, когда отложенная транзакция размещена в вашем онлайн-банкинге). И ничего из этого не было написано стандартизированным способом.
LLM с трудом сталкивались с такими книгами, не только потому, что для этих типов записей доступны очень ограниченные учебные данные (реестеры с меньшей вероятностью будут оцифрованы и еще реже будут расшифрованы, чем дневники или письма, потому что: кто хочет их читать, если им не нужно?) но потому, что ничего из этого не является предсказательным: человек может купить любую сумму чего-либо за любую произвольную стоимость, записанную в суммах, которые не складываются в соответствии с традиционными методами ... с которыми у LLM было достаточно проблем на протяжении многих лет. Я обнаружил, что модели часто могут расшифровать некоторые имена и некоторые из предметов в бухгалтерской книге, но полностью теряются в цифрах. Им трудно расшифровывать цифры в целом (опять же, вы не можете предсказать, будет ли это 30 или 80 галлонов, если первая цифра плохо сформирована), но также, как правило, объединяет затраты и итоговые данные. По сути, они часто не понимают, что суммы старого стиля — это суммы денег. Сказать им, чтобы они проверили цифры, складывая итогов вместе, не помогает и часто ухудшает ситуацию. Особенно сложные страницы временно ломают модель, заставляя ее повторять определенные цифры или фразы неоднократно, пока они не достигнут пределов выхода. В других случаях они думают в течение длительного времени, а затем не могут ответить полностью.
Де-Экс-Мачина
Но в этой новой машине есть что-то, что заметно отличается. Из моих, по общему признанию, ограниченных тестов новая модель Gemini обрабатывает этот тип данных намного лучше, чем любая предыдущая модель или студент, с которым я сталкивался: после заполнения пяти документов из нашего тестового набора я загрузил страницу дневной книги торговца Олбани выше (рисунок 4) с той же подсказкой, просто чтобы увидеть, что произойдет, и удивительно, что это снова было почти идеально. Цифры, что примечательно, все правильные. Более интересным, однако, является то, что его ошибки на самом деле являются исправлениями или разъяснениями. Например, когда Сэмюэл Ститт купил 2 чаши для пунша, клерк записал, что они стоят 2 / каждый, означающий по 2 шиллинга; ради краткости он подразумевал 0 пенни, а не выписывал их. Тем не менее, для последовательности модель расшифровала это как @2/0, что на самом деле является более правильным способом написания суммы и проясняет значение. Строго говоря, это ошибка.

Рисунок 5: Транскрипция новой неизвестной модели Близнецов страницы из книги учетной записи Олбани
В подсчете «ошибок» я увидел самый поразительный результат, который я когда-либо видел от LLM, который заставил волосы встать на затылке. Прочитав текст, я увидел, что Близнецы расшифровали строку как «До 1 к сахара 14 фунтов 5 унций @ 1/4 0 19 1». Если вы посмотрите на фактический документ, вы увидите, что на этой строке написано следующее: «До 1 из Сахара 145 @ 1/4 0 19 1». Для тех, кто не знал, в 18 thвеке сахар продавался в закаленной, конической форме и мистера. Слитт был кладовщиком, покупавшим сахар оптом для продажи. На первый взгляд, это кажется галлюцинаторной ошибкой: модели было предложено расшифровать текст точно так же, как написано, но он вставил 14 фунтов 5 унций, которых нет в документе. Это был именно тот тип ошибок, которые я видел много раз раньше: в отсутствие хорошего контекста модель угадывала, вставляя галлюцинацию. Но потом я понял, что на самом деле это сделало что-то чрезвычайно умное.
Близнецы сделали правильное заключение, что цифры 1, 4, 5 были единицами измерения, описывающими общий вес купленного сахара. Однако из самого документа можно было сделать не очевидный вывод. Все остальные девятнадцать записей четко указывают общие единицы покупки спереди: 30 галлонов, 17 лет, 1 баррель и так далее. Запись сахарного батона делает это тоже (1 буханка написана в начале записи), и это единственная, которая перечисляет число в конце описания. Существует крошечная отметка выше 1, которая также может (неоднозначно) использоваться для обозначения фунтов (спасибо Томасу Вейну за то, что он заметил это). Но если бы Близнецы интерпретировали это таким образом, он бы также прочитал фразу как что-то вроде 1 фунта 45 или 145 фунтов, учитывая размещение знака выше 1. Он также смог почерпнуть из текста, что сахар продавался по 1 шиллингу и 4 пенса за somethingчто-то, и сделал вывод, что это что-то было фунтами.
![]()
Рисунок 6: Крупный план транскрипции
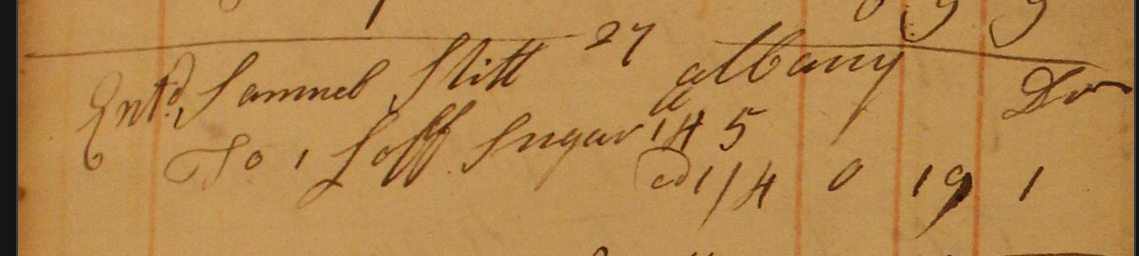
Рисунок 7: Крупный план оригинального документа
Чтобы определить правильный внешний вес, расшифровав 145, Близнецы затем сделали что-то замечательное: он проработал цифры, используя окончательную общую стоимость 0/19/1 для работы в обратном направлении, чтобы определить вес, серию операций, которые потребовали бы его преобразования между двумя десятичными и двумя недецимализованными системами измерения. Хотя мы не знаем его фактического процесса рассуждения, он, должно быть, был что-то похожее на это: сахар стоил 1 шиллинг и 4 пенса за единицу, и что эта сумма также может быть выражена в 16 пенсов. Мы также знаем, что общая стоимость продажи составила 0 фунтов, 19 шиллингов и 1 пенни, поэтому мы можем выразить это в виде 229 пенсов, чтобы создать общую единицу сравнения. Чтобы узнать, сколько сахара было куплено, мы разделили 229 на 16, чтобы получить результат: 14.3125 или 14 и 5/16 или 14 фунтов 5 унций. Поэтому, заключил Близнецы, это было не 1 45, и не 145, а 14 5, а затем 14 фунтов 5 унций, и он решил прояснить это в своей транскрипции.
[Добавил 17/10/2025]: Если эта двусмысленная отметка выше 1 наводила на мысль, что 145 является измерением в фунтах, результатом был аналогичный процесс логического вычета и самокоррекции. В этом случае Близнецы должны были бы намеренно подвергнуть сомнению наиболее очевидную версию транскрипции, понимая (в действительности), что 1 фунт 45 или 145 фунтов (что является единственным способом прочитать оригинал) не совпадает с подсчетом 0 191. Доход до 14 фунтов 5 унций затем возникнет из того же процесса, что и выше.
Это именно тот тип логической проблемы, при котором LLM часто терпят неудачу: сначала есть двусмысленность в самом письме и в форме текста, затем двойное значение слова «фунты» и, наконец, необходимость преобразования туда и обратно между не одной, а двумя разными недемецализованными системами измерения. И никто не просил Близнецов сделать это. Она взяла на себя инициативу расследовать и прояснить значение двусмысленного числа самостоятельно. И это было правильно.
В моем тестировании ни одна другая модель не делала ничего подобного, когда ей было поручено расшифровать тот же документ. Действительно, даже если вы даете Gemini-2.5-Pro подсказки, попросив его обратить внимание на недостающие единицы измерения, он иногда вставлял «lb» или «wt» после 5 в 145, но удалял другие числа. GPT-5 Pro обычно транскрибирует строку так: «To 1 Loaf Sugar 1 фунт 5 0 19 1». Интересно, что вы можете подтолкнуть как GPT-5, так и Gemini-2.5-Pro к правильному ответу, спросив его, что означают цифры 1 4 5 в записи сахарного батона. И даже тогда ответы варьируются, часто предполагая, что это было 145 фунтов сахара, а не 14 фунтов 5 унций.

Я старательно пытался воспроизвести этот результат, но, к сожалению, после сотен обновлений на AI Studio, я еще не видел тест A/B снова на этом документе. Я подозреваю, что Google, возможно, покончил с этим, или, по крайней мере, для меня.
Символические рассуждения и LLM
Что делает этот пример настолько поразительным, так это то, что он, кажется, пересекает границу, которую некоторые эксперты уже давно утверждают, что текущие модели не могут пройти. Строго говоря, модель Близнецов не участвует в символических рассуждениях в традиционном смысле: она не манипулирует явными правилами или логическими предложениями, как это ожидается от классической системы ИИ. Тем не менее, его поведение отражает этот результат. Столкнувшись с неоднозначным числом, он вывел из виду отсутствующий контекст, выполнил набор многоступенчатых преобразований между историческими системами валюты и веса и пришел к правильному выводу, который потребовал абстрактных рассуждений о мире, описанном в документе. Другими словами, он вел себя так, как будто у него был доступ к символам, хотя ни один из них никогда не был явно определен. Создал ли он эти символические представления для себя? Если да, то что это значит? Если нет, то как он это сделал?
То, что здесь происходит, является формой возникающего, неявного рассудка, спонтанного сочетания восприятия, памяти и логики внутри статистической модели, которая (я не верю ... Google, пожалуйста, проясните!) Он был создан для того, чтобы рассуждать символически. И дело в том, что мы не знаем, что он на самом деле сделал и почему.
Более безопасная точка зрения заключается в предположении, что Близнецы вообще не «знали», что они решают проблему арифметики восемнадцатого века, но его внутренние представления были достаточно богаты, чтобы подражать процессу этого. Но этот ответ, кажется, игнорирует очевидные факты: он следовал за преднамеренным, аналитическим процессом через несколько слоев символической абстракции, все без подсказки. Это кажется новым и важным.
Если такое поведение окажется надежным и воспроизводимым, это указывает на что-то глубокое, что лаборатории также начинают признавать: что истинные рассуждения могут не требовать возникновения явных правил или символических строительных лесов, а вместо этого могут возникнуть из масштаба, мультимодальности и воздействия достаточно структурированной сложности. В этом случае запись сахарного батона - это больше, чем замечательная транскрипция, это небольшой, но ясный (и я думаю, однозначный) признак того, что грань между распознаванием образов и подлинным пониманием начинает размываться.
Заключение
Для историков последствия являются немедленными и глубокими. Если эти результаты будут выдерживать систематическое тестирование, мы вступим в эпоху, когда большие языковые модели могут не только транскрибировать исторические документы на уровне точности между экспертами и людьми, но и могут рассуждать о них исторически значимыми способами. То есть они больше не просто видят буквы и слова — и правильные — они начинают интерпретировать контекст, логику и материальную реальность. Модель, которая может вывести значение «145» как «145 фунтов 5 унций» в торговом реестре 18-го века, не просто выполняет распознавание текста: она демонстрирует понимание экономических и культурных систем, в которых эти записи были произведены ... и затем используют эти знания для переосмысления прошлого понятными способами. Это перемещает работу автоматизированной транскрипции из визуального упражнения в интерпретирующее, преодолевая разрыв между зрением и рассуждениями таким образом, что отражает то, что делают эксперты-люди.
Но более широкие последствия еще более поразительны. Распознавание рукописных текстов является одной из старейших проблем в области исследований ИИ, начиная с конца сороковых годов, прежде чем у ИИ даже появилось имя. На протяжении десятилетий исследователи ИИ рассматривали распознавание рукописного текста как ограниченную техническую проблему, что является инженерной задачей в видении. Это началось с IBM 1287, который мог читать цифры и пять букв, когда он дебютировал в 1966 году, и продолжился созданием специализированных моделей HTR, разработанных всего несколько лет назад.
Эта новая модель Близнецов, похоже, показывает, что почти идеальное распознавание почерка лучше достигается благодаря общему подходу LLM. Более того, способность модели делать правильный, контекстуально обоснованный вывод, который требует нескольких слоев символического рассуждения, предполагает, что внутри этих систем может происходить что-то новое — возникающая форма абстрактных рассуждений, которая возникает не из явного программирования, а из самого масштаба и сложности.
Если это так, «проблема почерка» может оказаться прокси для чего-то гораздо большего. То, что началось с теста на читаемость старых документов, теперь может случайно выявить начало машин, которые могут на самом деле рассуждать абстрактными, символическими способами о мире, который они видят.
Телеграм: t.me/ainewsline
Источник: generativehistory.substack.com