Пузырь искусственного интеллекта и экономика США: как долго длятся «галлюцинации»?
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2025-10-04 12:24

С вами Ив. Это разрушительная, обязательная к прочтению статья от Servaas Storm о том, как ИИ не справляется с основными обещаниями производительности и никогда не может, независимо от того, сколько денег и вычислительных мощностей на него вложено. Тем не менее, искусственный интеллект, который Сторм называет «искусственной информацией», по-прежнему получает оценки хуже, чем доткомы, даже несмотря на то, что количество ошибок растет.
Автор: Серваас Сторм, старший преподаватель экономики, Делфтский технологический университет. Первоначально опубликовано на сайте Института нового экономического мышления
В этой статье утверждается, что (i) мы достигли «пика GenAI» с точки зрения современных больших языковых моделей (LLM); масштабирование (строительство большего количества центров обработки данных и использование большего количества чипов) не приведет нас дальше к цели «Общий искусственный интеллект» (AGI); доходы быстро снижаются; (ii) индустрия AI-LLM и экономика США в целом переживают спекулятивный пузырь, который вот-вот лопнет.
США переживают необычайный экономический бум, вызванный искусственным интеллектом: фондовый рынок стремительно растет благодаря исключительно высоким оценкам технологических компаний, связанных с искусственным интеллектом, которые стимулируют экономический рост на сотни миллиардов долларов США, которые они тратят на центры обработки данных и другую инфраструктуру искусственного интеллекта. Бум инвестиций в ИИ основан на вере в то, что ИИ сделает работников и фирмы значительно более продуктивными, что, в свою очередь, увеличит корпоративные прибыли до беспрецедентного уровня. Но лето 2025 года не принесло хороших новостей для энтузиастов генеративного искусственного интеллекта (GenAI), которые были взбудоражены раздутыми обещаниями таких людей, как Сэм Альтман из OpenAI, что «общий искусственный интеллект» (AGI), святой Грааль текущих исследований в области искусственного интеллекта, будет прямо за углом.
Рассмотрим ажиотаж подробнее. Уже в январе 2025 года Альтман написал, что «теперь мы уверены, что знаем, как построить AGI». Оптимизм Альтмана перекликается с заявлениями партнера OpenAI и крупного финансового спонсора Microsoft, которая в 2023 году опубликовала документ, в котором утверждалось, что модель GPT-4 уже демонстрирует «искры AGI». Илон Маск (в 2024 году) был столь же уверен, что модель Groc, разработанная его компанией xAI, достигнет AGI, интеллекта «умнее самого умного человека», вероятно, к 2025 году или, по крайней мере, к 2026 году. Генеральный директор Meta Марк Цукерберг заявил, что его компания стремится к «созданию полного общего интеллекта», и что суперинтеллект теперь «в поле зрения». Кроме того, Дарио Амодеи, соучредитель и генеральный директор Anthropic, сказал, что «мощный ИИ», то есть умнее, чем лауреат Нобелевской премии в любой области, может появиться уже в 2026 году и открыть новую эру здоровья и изобилия — США станут «страной гениев в центре обработки данных», если ..... ИИ не убил нас всех.
Для г-на Маска и его попутчиков по GenAI самым большим препятствием на пути к AGI является нехватка вычислительных мощностей (установленных в дата-центрах) для обучения ИИ-ботов, что, в свою очередь, связано с нехваткой достаточно продвинутых компьютерных чипов. По оценкам Morgan Stanley, спрос на большее количество данных и больше возможностей для обработки данных потребует около 3 триллионов долларов капитала только к 2028 году. Это превысило бы возможности мировых рынков кредитов и производных ценных бумаг. Движимые императивом выиграть гонку искусственного интеллекта с Китаем, пропагандисты GenAI твердо верят, что США можно поставить на дорогу из желтого кирпича к Изумрудному городу AGI, построив больше центров обработки данных быстрее (безошибочно «акселерационистское» выражение).
Интересно, что AGI — это плохо определенное понятие, и, возможно, это скорее маркетинговая концепция, используемая сторонниками ИИ, чтобы убедить своих финансистов инвестировать в их начинания. Грубо говоря, идея состоит в том, что модель AGI может обобщать не только конкретные примеры, найденные в обучающих данных, подобно тому, как некоторые люди могут выполнять практически любую работу после того, как им показали несколько примеров того, как выполнять задачу, обучаясь на опыте и изменяя методы при необходимости. Боты AGI будут способны перехитрить людей, создавать новые научные идеи и выполнять инновационное, а также рутинное кодирование. Боты с искусственным интеллектом будут рассказывать нам, как разрабатывать новые лекарства для лечения рака, решать проблему глобального потепления, водить автомобили и выращивать генетически модифицированные культуры. Таким образом, в условиях радикального созидательного разрушения ОИИ трансформирует не только экономику и рабочие места, но и системы здравоохранения, энергетики, сельского хозяйства, коммуникаций, развлечений, транспорта, НИОКР, инноваций и науки.
Альтман из OpenAI похвастался, что AGI может «открыть новую науку», потому что «я думаю, что мы взломали рассуждения в моделях», добавив, что «нам предстоит пройти долгий путь». Он «думает, что мы знаем, что делать», говоря, что модель o3 от OpenAI «уже довольно умна», и что он слышал, как люди говорят: «Вау, это как хорошая докторская степень». Объявляя о запуске ChatGPT-5 в августе, г-н Альтман написал в Интернете: «Мы думаем, что вам понравится использовать GPT-5 гораздо больше, чем любой предыдущий AL. Это полезно, это умно, это быстро [и] интуитивно понятно. С GPT-5 теперь это похоже на разговор с экспертом — настоящим экспертом уровня PhD во всем, что вам нужно, по запросу, он может помочь вам с любыми вашими целями».
Но потом все начало разваливаться, причем довольно быстро.
ChatGPT-5 — это разочарование
Первая плохая новость заключается в том, что широко разрекламированный ChatGPT-5 оказался пустышкой — постепенные улучшения, завернутые в архитектуру маршрутизации, далеко не приближающиеся к прорыву в AGI, который обещал Сэм Альтман. Пользователи не в восторге. Как сообщает MIT Technology Review: «Широко разрекламированный релиз вносит несколько улучшений в пользовательский опыт ChatGPT. Но это все еще далеко от AGI». Вызывает беспокойство тот факт, что внутренние тесты OpenAI показывают, что GPT-5 «галлюцинирует» примерно в одном из 10 случаев при подключении к Интернету. Однако без доступа к веб-страницам GPT-5 ошибается почти в 1 из 2 ответов, что должно вызывать проблемы. Еще более тревожным является то, что «галлюцинации» также могут отражать предубеждения, скрытые в наборах данных. Например, магистр права может «галлюцинировать» статистику преступности, которая соответствует расовым или политическим предубеждениям, просто потому, что он извлек уроки из предвзятых данных.
Следует отметить, что чат-боты с искусственным интеллектом могут активно использоваться и используются для распространения дезинформации (см. здесь и здесь). Согласно недавним исследованиям, чат-боты распространяют ложные утверждения, когда им задают вопросы о спорных новостных темах, в 35% случаев, что почти вдвое больше, чем 18% год назад (здесь). ИИ отбирает, упорядочивает, представляет и подвергает цензуре информацию, влияя на интерпретацию и дебаты, продвигая доминирующие (средние или предпочтительные) точки зрения, подавляя альтернативы, тихо удаляя неудобные факты или придумывая удобные. Ключевой вопрос: кто контролирует алгоритмы? Кто устанавливает правила для технических братьев? Очевидно, что, облегчая распространение «реалистично выглядящей» дезинформации и предубеждений и/или подавляя критически важные доказательства или аргументацию, GenAI имеет и будет иметь немалые социальные издержки и риски, которые необходимо учитывать при оценке его последствий.
Создание более крупных LLM ни к чему не приводит
Эпизод с ChatGPT-5 вызывает серьезные сомнения и экзистенциальные вопросы о том, не натолкнулась ли уже на стену основная стратегия индустрии GenAI по созданию все более крупных моделей на все больших распределениях данных. Критики, в том числе когнитивист Гэри Маркус (здесь и здесь), уже давно утверждают, что простое масштабирование LLM не приведет к AGI, и досадные ошибки GPT-5 подтверждают эти опасения. Становится все более распространенным понимание того, что LLM не строятся на правильных и надежных моделях мира, а вместо этого создаются для автозаполнения, основанного на сложном сопоставлении шаблонов — вот почему, например, они до сих пор даже не могут надежно играть в шахматы и продолжают совершать ошеломляющие ошибки с поразительной регулярностью.
В моем новом рабочем документе INET обсуждаются три отрезвляющих исследования, показывающих, что новые, постоянно расширяющиеся модели GenAI становятся не лучше, а хуже, и не рассуждают, а скорее повторяют текст, похожий на рассуждения. Например, недавняя статья ученых из Массачусетского технологического института и Гарварда показывает, что даже обучаясь всей физике, LLM не могут раскрыть даже существующие обобщенные и универсальные физические принципы, лежащие в основе их обучающих данных. В частности, Vafa et al. (2025) отмечают, что LLM, которые следуют «кеплеровскому» подходу: они могут успешно предсказать следующее положение на орбите планеты, но не могут найти объяснение закону всемирного тяготения Ньютона (см. здесь). Вместо этого они прибегают к подгонке выдуманных правил, которые позволяют им успешно предсказывать следующее орбитальное положение планеты, но эти модели не могут найти вектор силы, лежащий в основе идеи Ньютона. Статья Массачусетского технологического института и Гарварда объясняется в этом видео. LLM не могут выводить и не выводят физические законы из своих обучающих данных. Примечательно, что они даже не могут найти соответствующую информацию в интернете. Вместо этого они его придумывают.
Хуже того, боты с искусственным интеллектом заинтересованы в том, чтобы догадываться (и давать неверный ответ), а не признавать, что они чего-то не знают. Эта проблема признана исследователями из OpenAI в недавней статье. Догадки вознаграждаются — потому что, кто знает, может быть, это будет правильно. В настоящее время ошибка не подлежит исправлению. Соответственно, было бы разумно думать об «искусственной информации», а не об «искусственном интеллекте» при использовании аббревиатуры ИИ. Аргумент прост: это очень плохая новость для тех, кто надеется, что дальнейшее масштабирование — создание еще более крупных LLM — приведет к лучшим результатам (см. также Che 2025).
95% пилотных проектов генеративного ИИ в компаниях терпят неудачу
Корпорации поспешили объявить об инвестициях в ИИ или заявить о возможностях ИИ для своих продуктов в надежде поднять цены на свои акции. Затем появилась новость о том, что инструменты ИИ не делают того, что они должны делать, и что люди осознают это (см. Эд Зитрон). В отчете за август 2025 года под названием «Разделение GenAI: состояние ИИ в бизнесе до 2025 года», опубликованном инициативой NANDA Массачусетского технологического института, делается вывод о том, что 95% пилотных проектов генеративного ИИ в компаниях не могут обеспечить рост доходов. Как сообщает Fortune, «универсальные инструменты, такие как ChatGPT [...], застревают в корпоративном использовании, поскольку они не учатся и не адаптируются к рабочим процессам». Вполне.
Действительно, компании идут на попятную, сократив сотни рабочих мест и заменив их искусственным интеллектом. Например, шведская компания Klarna «Покупай буррито сейчас, плати потом» в марте 2024 года хвасталась, что ее помощник с искусственным интеллектом выполнял работу 700 (уволенных) работников, но летом 2025 года снова нанял их (к сожалению, в качестве фрилансеров) (см. здесь). Другие примеры включают IBM, вынужденную повторно нанять персонал после увольнения около 8000 работников для внедрения автоматизации (здесь). Последние данные Бюро переписи населения США по размеру фирм показывают, что внедрение ИИ снижается среди компаний с численностью сотрудников более 250 человек.
Экономист Массачусетского технологического института Дарен Аджемоглу (2025) прогнозирует довольно скромное влияние ИИ на производительность в ближайшие 10 лет и предупреждает, что некоторые приложения ИИ могут иметь негативную социальную ценность. «У нас по-прежнему будут журналисты, у нас все еще будут финансовые аналитики, у нас все еще будут сотрудники отдела кадров», — говорит Аджемоглу. «Это повлияет на множество офисных работ, связанных с обобщением данных, визуальным сопоставлением, распознаванием образов и т. д. А это, по сути, около 5% экономики». Аналогичным образом, используя два крупномасштабных исследования внедрения ИИ (конец 2023 и 2024 гг.), охватывающие 11 подверженных риску профессий (25 000 работников на 7 000 рабочих мест) в Дании, Андерс Хамлум и Эмили Вестергаард (2025) показывают в недавнем рабочем документе NBER, что экономические последствия внедрения GenAI минимальны: «Чат-боты с искусственным интеллектом не оказали существенного влияния на заработок или зарегистрированные часы в какой-либо профессии. с доверительными интервалами, исключающими эффекты более 1%. Скромный рост производительности труда (в среднем экономия времени на 3%) в сочетании со слабым переносом заработной платы помогает объяснить эти ограниченные эффекты на рынке труда». Эти результаты обеспечивают столь необходимую проверку реальности для преувеличения того, что GenAI придет на все наши рабочие места. Реальность даже близко не такая.
GenAI даже не сделает ненужными технических работников, которые занимаются программированием, вопреки прогнозам энтузиастов ИИ. Исследователи OpenAI обнаружили (в начале 2025 года), что продвинутые модели ИИ (включая GPT-4o и сонет Claude 3.5 от Anthropic) все еще не могут сравниться с людьми-программистами. Боты с искусственным интеллектом не смогли понять, насколько широко распространены ошибки, или понять их контекст, что привело к неправильным или недостаточно всеобъемлющим решениям. Еще одно новое исследование, проведенное некоммерческой организацией Model Evaluation and Threat Research (METR), показало, что на практике программисты, использующие инструменты искусственного интеллекта в начале 2025 года, на самом деле медленнее используют инструменты искусственного интеллекта, тратя на 19 процентов больше времени при использовании GenAI, чем при активном программировании самостоятельно (см. здесь). Программисты тратили свое время на просмотр выходных данных ИИ, подсказки для систем ИИ и исправление кода, сгенерированного ИИ.
Экономика США в целом галлюцинирует
Разочаровывающее развертывание ChatGPT-5 вызывает сомнения в способности OpenAI создавать и продавать потребительские продукты, за которые пользователи готовы платить. Но я хочу сказать, что речь идет не только об OpenAI: американская индустрия искусственного интеллекта в целом была построена на предпосылке, что AGI уже не за горами. Все, что нужно, это достаточные «вычислительные ресурсы», т.е. миллионы графических процессоров Nvidia AI, достаточное количество дата-центров и достаточное количество дешевой электроэнергии для выполнения массивного статистического отображения шаблонов, необходимого для создания (подобия) «интеллекта». Это, в свою очередь, означает, что «масштабирование» (инвестирование миллиардов долларов США в чипы и центры обработки данных) — это единственный путь вперед — и это именно то, в чем хороши технологические фирмы, венчурные капиталисты Кремниевой долины и финансисты с Уолл-стрит: мобилизация и расходование средств, на этот раз на «масштабирование» генеративного ИИ и строительство центров обработки данных для поддержки всего ожидаемого будущего спроса на использование ИИ.
В течение 2024 и 2025 годов крупные технологические компании инвестировали ошеломляющие 750 миллиардов долларов в центры обработки данных в совокупном выражении, и они планируют развернуть совокупные инвестиции в размере 3 триллионов долларов в центры обработки данных в течение 2026-2029 годов (Thornhill 2025). Так называемая «Великолепная семерка» (Alphabet, Apple, Amazon, Meta, Microsoft, Nvidia и Tesla) потратила более $100 млрд на дата-центры во втором квартале 2025 года; На рисунке 1 представлены капитальные затраты для четырех из семи корпораций.
РИСУНОК 1
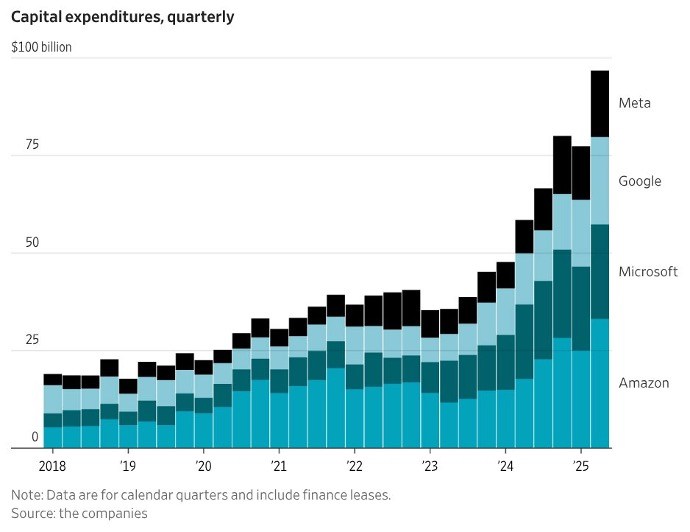
Кристофер Мимс (2025), https://x.com/mims/status/1951...
Всплеск корпоративных инвестиций в «оборудование для обработки информации» огромен. По словам Торстена Слока, главного экономиста Apollo Global Management, вклад инвестиций в центры обработки данных в (вялый) рост реального ВВП США был таким же, как и потребительские расходы в первой половине 2025 года (рисунок 2). Финансовый инвестор Пол Кедроски считает, что капитальные затраты на ИИ-центры обработки данных (в 2025 году) прошли пик расходов на телекоммуникации во время пузыря доткомов (1995-2000 годов).
РИСУНОК 2
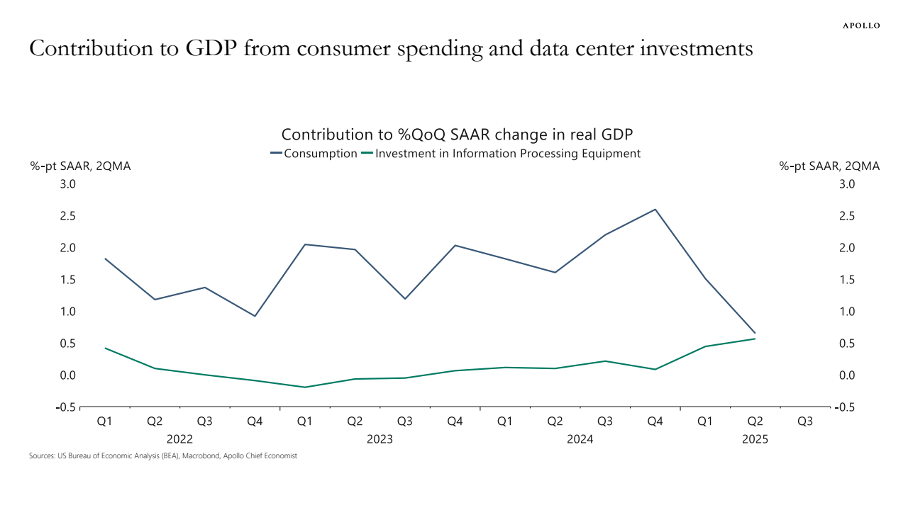
Источник: Торстен Слёк (2025). https://www.apolloacademy.com/...
После шумихи и гипербол вокруг искусственного интеллекта акции технологических компаний взлетели до небес. Индекс S&P500 вырос примерно на 58% в течение 2023-2024 годов, в основном за счет роста цен на акции «Великолепной семерки». Средневзвешенная цена акций этих семи корпораций выросла на 156% в течение 2023-2024 годов, в то время как у других 493 фирм средний рост цен на акции составил всего 25%. Фондовый рынок Америки в значительной степени управляется искусственным интеллектом.
Акции Nvidia выросли более чем на 280% за последние два года на фоне взрывного спроса на ее графические процессоры со стороны компаний, занимающихся искусственным интеллектом; Будучи одним из самых заметных бенефициаров ненасытного спроса на GenAI, Nvidia в настоящее время имеет рыночную капитализацию более 4 триллионов долларов, что является самой высокой оценкой, когда-либо зарегистрированной для публично торгуемой компании. Имеет ли смысл такая оценка? Коэффициент цена/прибыль (P/E) Nvidia достиг пика в 234 в июле 2023 года и с тех пор снизился до 47,6 в сентябре 2025 года, что по-прежнему является исторически очень высоким показателем (см. Рисунок 3). Nvidia продает свои графические процессоры неооблачным компаниям (таким как CoreWeave, Lambda и Nebius), которые финансируются за счет кредитов от Goldman Sachs, JPMorgan, Blackstone и других частных инвестиционных компаний с Уолл-стрит, обеспеченных центрами обработки данных, заполненными графическими процессорами. В ключевых случаях, как объясняет Эд Зитрон, Nvidia предлагала убыточным компаниям купить непроданные облачные вычисления на миллиарды долларов США, эффективно поддерживая своих клиентов — и все это в ожидании революции в области искусственного интеллекта, которая все еще должна произойти.
Аналогичным образом, цена акций Oracle Corp. (которая не входит в «Великолепную семерку») выросла более чем на 130% в середине мая и начале сентября 2025 года после объявления о сделке с OpenAI на сумму 300 миллиардов долларов. Коэффициент P/E Oracle вырос почти до 68, что означает, что финансовые инвесторы готовы платить почти 68 долларов за 1 доллар будущей прибыли Oracle. Одна из очевидных проблем с этой сделкой заключается в том, что у OpenAI нет 300 миллиардов долларов; Компания понесла убыток в размере $15 млрд в течение 2023-2025 годов и, по прогнозам, понесет еще один совокупный убыток в размере $28 млрд в течение 2026-2028 годов (см. ниже). Неясно и неопределенно, откуда OpenAI возьмет деньги. Зловещим является то, что Oracle необходимо создать инфраструктуру для OpenAI, прежде чем она сможет получать какие-либо доходы. Если OpenAI не сможет оплатить огромные вычислительные мощности, которые она согласилась купить у Oracle, что кажется вероятным, Oracle останется с дорогостоящей инфраструктурой искусственного интеллекта, для которой она, возможно, не сможет найти альтернативных клиентов, особенно после того, как пузырь искусственного интеллекта выдохнется.
Таким образом, акции технологических компаний значительно переоценены. Торстен Слёк, главный экономист Apollo Global Management, предупредил (в июле 2025 года), что акции AI еще более переоценены, чем акции доткомов в 1999 году. В своем блоге он иллюстрирует, как коэффициенты P/E у Nvidia, Microsoft и восьми других технологических компаний выше, чем в эпоху доткомов (см. рисунок 3). Мы все помним, как закончился пузырь доткомов, и поэтому Слёк прав, когда бьет тревогу по поводу очевидной рыночной мании, вызванной «Великолепной семеркой», которая вложила значительные средства в индустрию искусственного интеллекта.
Big Tech не покупает эти дата-центры и не управляет ими самостоятельно; вместо этого центры обработки данных строятся строительными компаниями, а затем покупаются операторами центров обработки данных, которые сдают их в аренду, скажем, OpenAI, Meta или Amazon (см. здесь). Частные инвестиционные компании с Уолл-стрит, такие как Blackstone и KKR, инвестируют миллиарды долларов в скупку этих операторов центров обработки данных, используя коммерческие ипотечные ценные бумаги в качестве источника финансирования. Недвижимость в центрах обработки данных — это новый, раздутый класс активов, который начинает доминировать в финансовых портфелях. Blackstone называет центры обработки данных одной из своих «самых убедительных инвестиций». Уолл-стрит любит договоры аренды дата-центров, которые предлагают долгосрочный стабильный, предсказуемый доход, выплачиваемый клиентами с рейтингом AAA, такими как AWS, Microsoft и Google. Некоторые Cassandra предупреждают о потенциальном переизбытке центров обработки данных, но учитывая, что «будущее будет основано на GenAI», что может пойти не так?
РИСУНОК 3
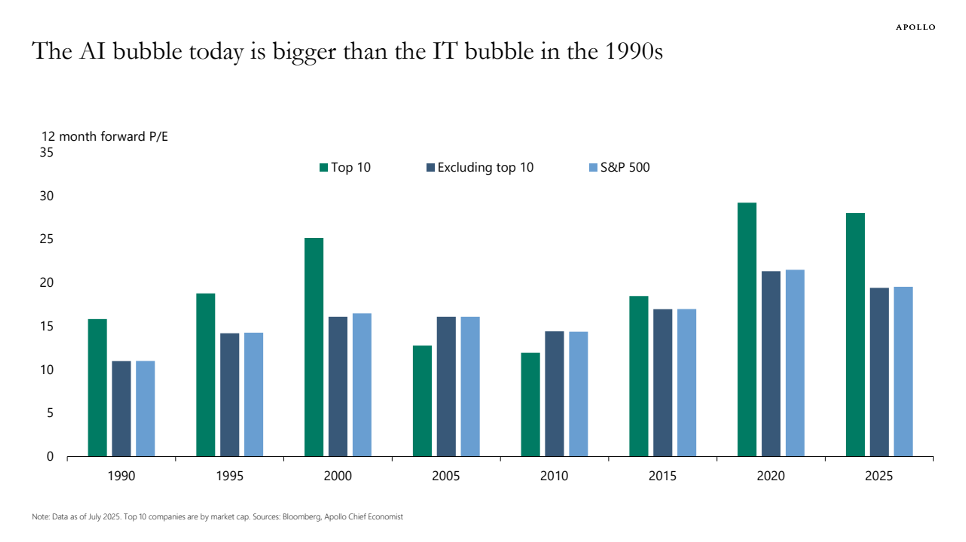
Источник: Торстен Слёк (2025), https://www.apolloacademy.com/...
В редкий момент откровенности генеральный директор OpenAI Сэм Альтман был прав. «Находимся ли мы на этапе, когда инвесторы в целом чрезмерно увлечены искусственным интеллектом?» — сказал Альтман во время интервью с журналистами в Сан-Франциско в августе. «Мое мнение — да». Он также сравнил сегодняшнюю лихорадку инвестиций в искусственный интеллект с пузырем доткомов конца 1990-х. «Я думаю, что кто-то там обгорит», — сказал Альтман. «Кто-то потеряет феноменальную сумму денег – мы не знаем кто...», но (судя по тому, что происходило в более ранних пузырях) это, скорее всего, будет не сам Альтман.
Таким образом, вопрос заключается в том, как долго инвесторы будут продолжать поддерживать заоблачные оценки ключевых фирм в гонке GenAI, еще предстоит увидеть. Доходы индустрии искусственного интеллекта продолжают бледнеть по сравнению с десятками миллиардов долларов США, которые тратятся на развитие центров обработки данных. Согласно оптимистичной исследовательской записке S&P Global, опубликованной в июне 2025 года, прогнозируется, что рынок GenAI принесет 85 миллиардов долларов дохода в 2029 году. Тем не менее, Alphabet, Google, Amazon и Meta вместе потратят почти 400 миллиардов долларов на капитальные затраты только в 2025 году. В то же время индустрия искусственного интеллекта имеет совокупный доход, который немногим превышает доход индустрии умных часов (Zitron 2025).
Итак, что делать, если GenAI просто не приносит прибыли? Этот вопрос актуален в связи с быстрым снижением отдачи от стратосферных капитальных затрат на GenAI и центры обработки данных, а также разочаровывающим пользовательским опытом 95% компаний, внедривших ИИ. Один из крупнейших хедж-фондов в мире, Elliott из Флориды, сообщил клиентам, что ИИ переоценен, а Nvidia находится в пузыре, добавив, что многие продукты ИИ «никогда не будут экономически эффективными, никогда не будут работать правильно, будут потреблять слишком много энергии или окажутся ненадежными». «Есть несколько реальных применений», — говорится в нем, кроме «обобщения заметок совещаний, создания отчетов и помощи в компьютерном кодировании». Компания добавила, что «скептически» относится к тому, что крупные технологические компании будут продолжать покупать графические процессоры производителя чипов в таких больших объемах.
Вложение миллиардов долларов США в центры обработки данных, ориентированные на ИИ, без четкой стратегии выхода из этих инвестиций в случае, если повальное увлечение ИИ закончится, означает только то, что системный риск в финансах и экономике растет. В то время как инвестиции в центры обработки данных стимулируют экономический рост в США, американская экономика стала зависимой от горстки корпораций, которым пока не удалось получить ни одного доллара прибыли от «вычислений», выполняемых этими инвестициями в центры обработки данных.
Геополитические ставки в Америке пошли не так
Бум ИИ (пузырь) развился при поддержке обеих основных политических партий в США. Видение американских компаний, расширяющих границы ИИ и достигающих GenAI первыми, широко распространено — на самом деле, существует двухпартийный консенсус о том, насколько важно, чтобы США выиграли глобальную гонку ИИ. Промышленный потенциал Америки критически зависит от ряда потенциальных противников, включая Китай. В этом контексте лидерство Америки в GenAI рассматривается как потенциальный очень мощный геополитический рычаг: если Америке удастся добраться до AGI первой, как говорится в анализе, она может создать подавляющее долгосрочное преимущество, особенно над Китаем (см. Фаррелл).
Именно по этой причине Кремниевая долина, Уолл-стрит и администрация Трампа удваивают ставку на стратегию «ОИИ прежде всего». Но проницательные наблюдатели подчеркивают издержки и риски этой стратегии. В частности, Эрик Шмидт и Селина Сюйв New York Times от 19 августа 2025 года обеспокоены тем, что «Кремниевая долина настолько увлеклась достижением этой цели [AGI], что это оттолкнуло широкую общественность и, что еще хуже, упустило важные возможности для использования уже существующих технологий. Будучи зацикленной исключительно на этой цели, наша страна рискует отстать от Китая, который гораздо меньше озабочен созданием искусственного интеллекта, достаточно мощного, чтобы превзойти людей, и гораздо больше сосредоточен на использовании технологий, которые у нас есть сейчас».
Шмидт и Сюй справедливо обеспокоены. Возможно, бедственное положение экономики США лучше всего отражает Сэм Альтман из OpenAI, который фантазирует о размещении своих центров обработки данных в космосе: «Например, может быть, мы построим большую сферу Дайсона вокруг Солнечной системы и скажем: «Эй, на самом деле нет смысла размещать их на Земле». До тех пор, пока подобные «галлюцинации» по поводу использования спутников, собирающих солнечную энергию, для сбора (неограниченной) звездной энергии продолжают убеждать доверчивых финансовых инвесторов, правительство и пользователей в «магии» искусственного интеллекта и индустрии искусственного интеллекта, экономика США, безусловно, обречена.
Телеграм: t.me/ainewsline
Источник: www.nakedcapitalism.com