Георгий Герганов, автор llama.cpp и звукового кейлогера
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2025-07-10 11:37

Многие пользуются YouTube, Netflix, но не подозревают о ключевых опенсорсных программах типа ffmpeg, которые работают на бэкенде этих сервисов. Похожая ситуация с нейронками, где многие знают программу Ollama для локального запуска моделей на CPU. Но мало кто понимает, что это всего лишь простенькая оболочка вокруг опенсорсной библиотеки llama.cpp на С, которая и делает инференс. Автор этой библиотеки, талантливый разработчик Георгий Герганов, мало известен широкой публике.
Энтузиасты LLM в курсе, что происходит. Судя по всему, разработчикам Ollama выгодно нравится, что все лавры достаются им. Однако возникают странные ситуации, когда после выхода новой модели Ollama твитит «Работаем над поддержкой», хотя они просто ждут обновления llama.cpp.
Наверное, Георгия Герганова забавит такое поведение «бизнесменов от опенсорса». Хотя он скромный болгарский хакер и ни с кем особо не конфликтует.
В чём претензии к Ollama
Недавно Meta объявила о поддержке мультимодальности в LLama, поблагодарив в официальном блоге своих «партнёров в сообществе ИИ», в том числе Ollama, даже не упомянув llama.cpp.

Или вот недавно VSCode добавил поддержку локальных моделей в чате GitHub Copilot, упомянув оболочку Ollama, а не движок llama.cpp, который реально выполняет работу:

Георгий Герганов просто иронично упомянул этот факт, но не высказал претензий.
Сама Ollama тоже не упоминает авторов программного кода llama.cpp, а вот это уже является нарушением лицензии MIT.
Помимо этого, в сообществе LLM-энтузиастов в принципе недовольны политикой Ollama, которая ради хайпа делает некорректные рекламные заявления, создавая у широкой публики завышенные ожидания, что «каждый может запустить полноценную модель ChatGPT на своём телефоне», хотя на самом деле локально на ПК и смартфонах запускаются только совсем маленькие модели — и инференс очень медленный.
В результате пользователи недовольны, а крайними остаются разработчики моделей и llama.cpp.
Ещё Ollama в некоторых случаях некорректно именует модели, так что неполноценный дистиллят LLaMA с менее 10 млрд весов именуется как «просто» LLaMA. Это основная часть претензий к Ollama, которая гонится за хайпом, хотя бэкенд пишут другие.

Есть и другие проблемы:
-
Ollama не вносит значительных улучшений обратно в родительский проект. Да, они не обязаны это делать, но в качестве благодарности было бы нормально, если б они помогли
llama.cppс поддержкой мультимодальных моделей и внедрением инструментов вроде SWA (Sliding-Window Attention), это метод оптимизации внимания в LLM, позволяющий эффективно обрабатывать длинные последовательности без чрезмерных затрат на вычисления. Но Ollama предпочитает оставлять эти достижения при себе. Выходит новая модель — они твитят «Работаем над этим» и ждут, когда Георгий Герганов внедрит поддержку этой модели. По крайней мере, раньше такое было неоднократно. -
Плохие значения по умолчанию для запуска моделей. Преднастройки Ollama
сделаны якобы для удобства пользователей, но на практике они совершенно неразумно ограничивают функциональность llama.cpp:

Достаточно вспомнить размер контекста по умолчанию 2048 токенов, что было абсолютно неприемлемо для большинства задач. Сейчас его увеличили до 4096 токенов.
Для сравнения, конкуренты из LM Studio предлагают более продуманные настройки для продвинутых пользователей. И вообще, при наличии прокси типа LiteLLM для доступа к облачным моделям и llama.cpp для локальных — необходимость в Ollama вообще отпадает. Непонятно, зачем вообще использовать Ollama, если с оригинальной библиотекой идёт приятный локальный сервер llamacpp-server.
В целом, Ollama форкает различные опенсорсные проекты и пытается закрывать эти форки в своей экосистеме. Например, транспортный протокол Ollama — это форк открытого контейнерного протокола OCI (Open Container Initiative), но изменённый для несовместимости с DockerHub и др.
Собственно, и llama.cpp они просто форкнули и используют в своих целях, без обратной связи.
llama.cpp

Изначально llama.cpp создавалась как библиотека для инференса модели LLaMA от Meta на чистом C/C++. Работу над ней Герганов начал в сентябре 2022 года, после создания похожей библиотеки whisper.cpp для инференса модели распознавания речи ASR Whisper от OpenAI.
Разработка велась параллельно проекту GGML — универсальной библиотеки тензорной алгебры на C. Георгий говорит, что создание GGML было вдохновлено библиотекой LibNC от Фабриса Беллара.

Цель проекта — запуск моделей на компьютерах без GPU или других специализированных карт. С помощью llama.cpp современные LLM запускаются на обычных ПК и смартфонах Android. Хотя изначально библиотека писалась для CPU, позже была добавлена поддержка GPU.
В марте 2024 года другая известная хакерша Джастин Танни выпустила новые оптимизированные ядра для умножения матриц для x86 и ARM CPU, улучшив производительность FP16 и 8-битных квантизированных типов данных.
В нейросетях с пониженной точностью значения параметров (весов, смещений, активаций) кодируются 8-битными целыми числами (или ниже). Это позволяет значительно сократить объём памяти и ускорить вычисления, особенно на устройствах с ограниченными ресурсами.

Эти улучшения были внесены в llama.cpp. Танни также написала инструмент llamafile, который объединяет модели и llama.cpp в один файл, работающий на любых ОС.
На уровне библиотеки тензоров GGML в llama.cpp поддерживаются несколько платформ, включая x86, ARM, CUDA, Metal, Vulkan (версии 1.2 или выше) и SYCL. Вместо квантизации на лету llama.cpp выполняет предварительную квантизацию моделей. Для оптимизации используются несколько расширенных наборов инструкций: AVX, AVX2 и AVX-512 для x86-64, а также Neon на ARM.
Бинарные файлы GGUF (GGML Universal File) хранят и тензоры, и метаданные. Формат спроектирован для быстрого сохранения и загрузки данных модели, он был представлен в августе 2023 года для лучшей обратной совместимости, когда реализовали поддержку новых моделей.
GGUF поддерживает квантизированные целочисленные типы от 2 до 8 бит, распространённые форматы данных с плавающей запятой, такие как float32, float16 и bfloat16, квантизацию на 1,56 бита.
Другие проекты Герганова
-
whisper.cpp: высокопроизводительный инференс модели ASR Whisper от OpenAI на CPU с использованием C/C++.
-
GPT-J: инференс на CPU с использованием C/C++.
-
slack (tui): текстовый UI для клиента Slack | исходники | видео0 | видео1.
-
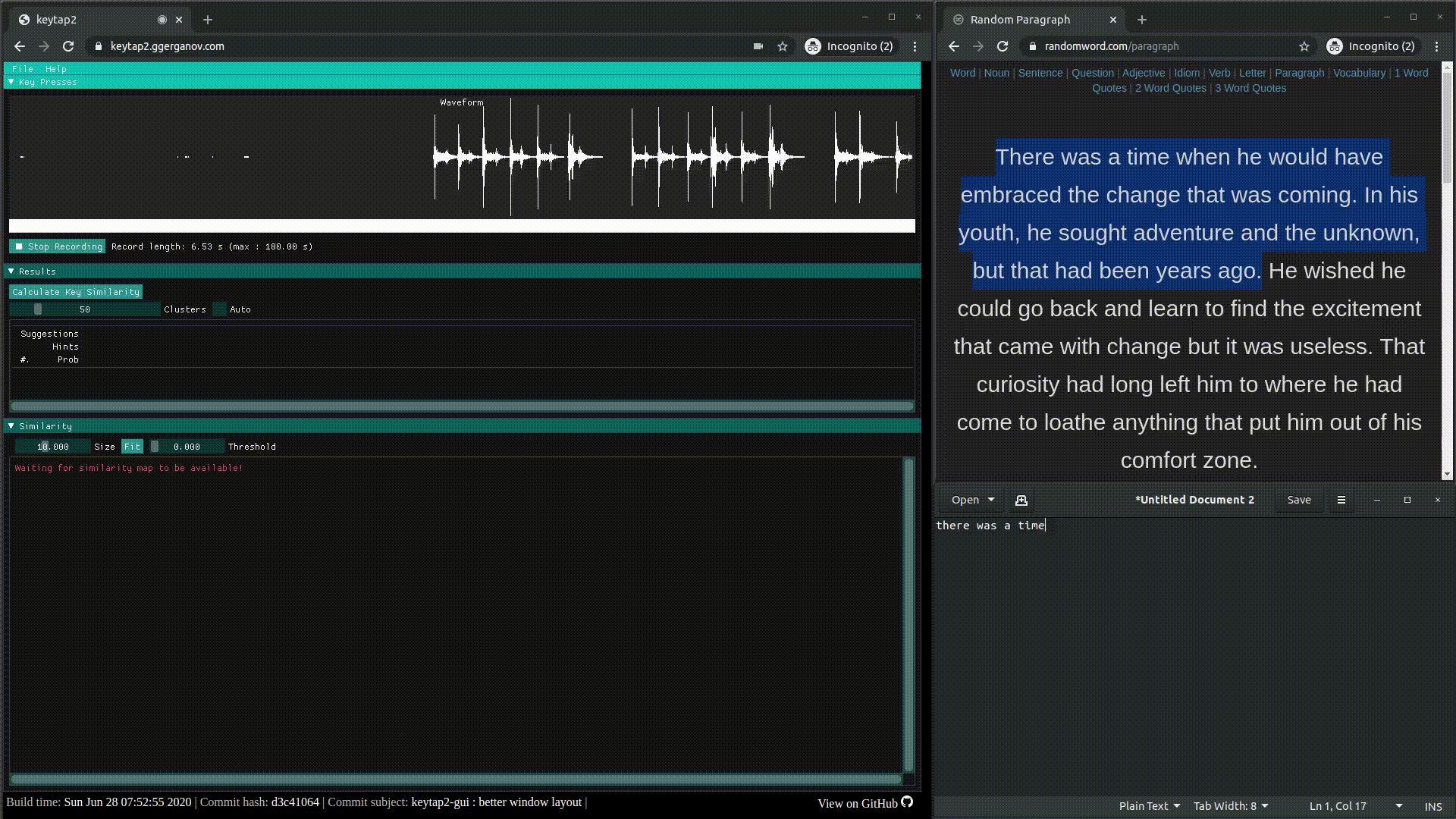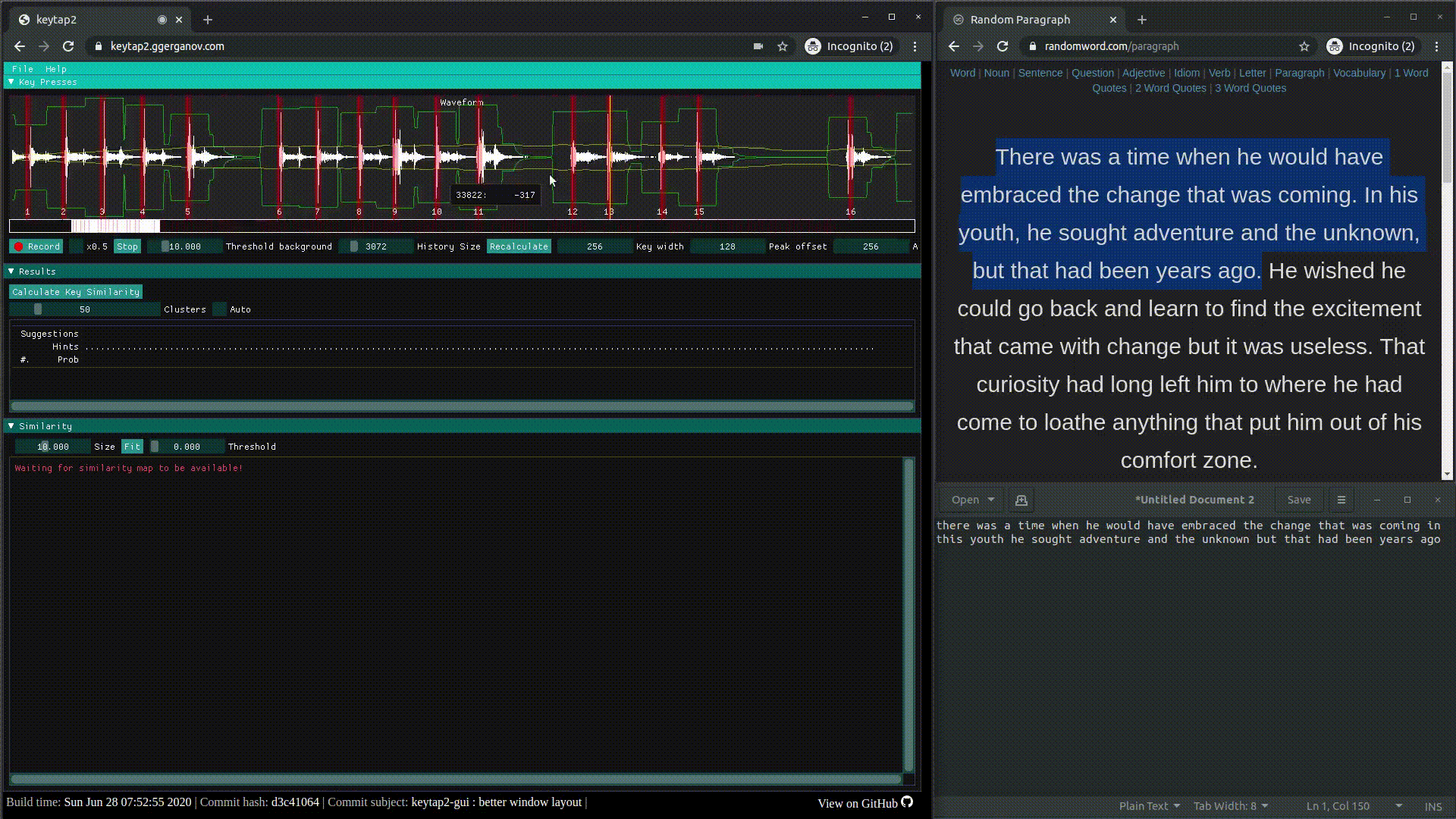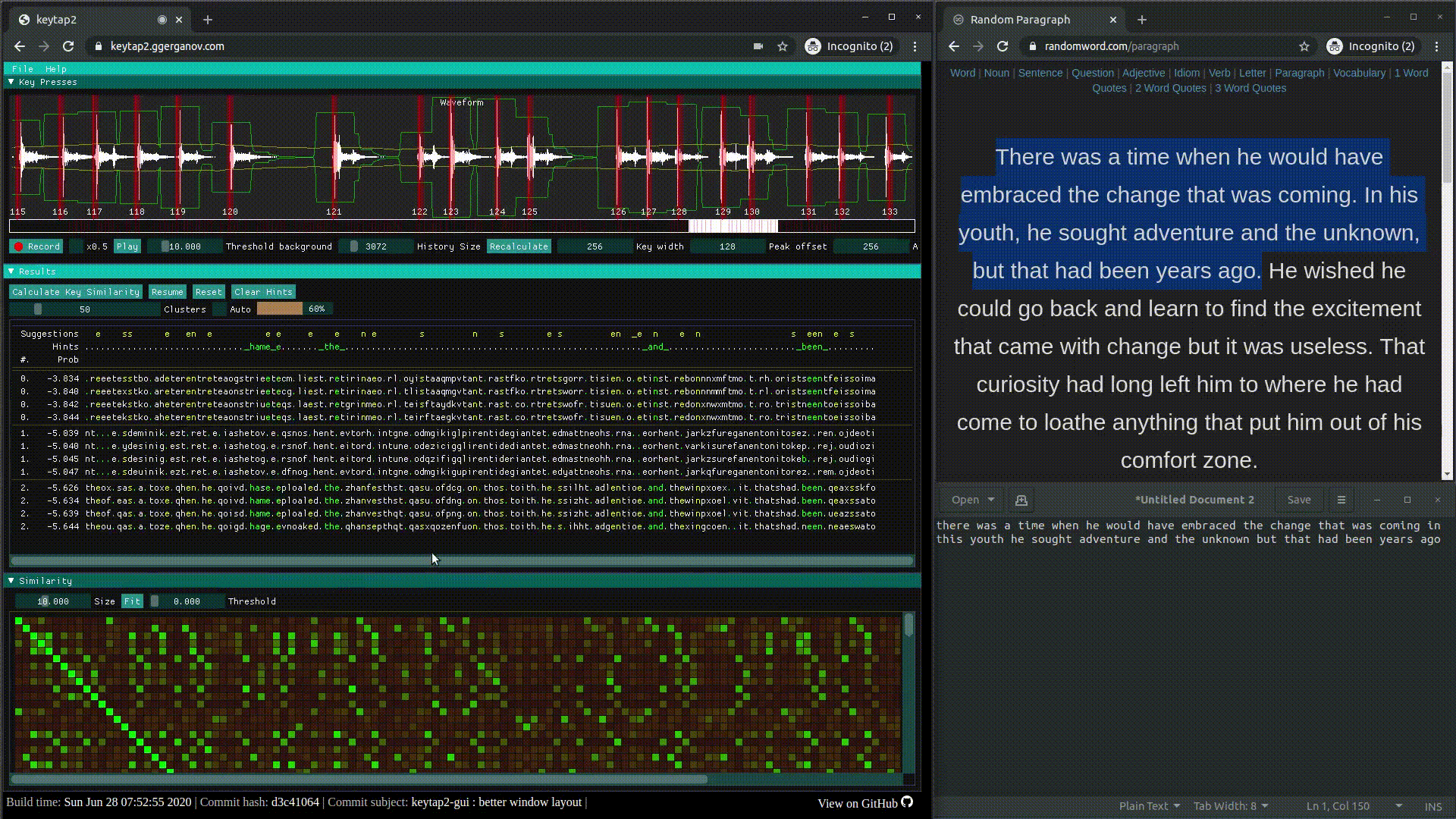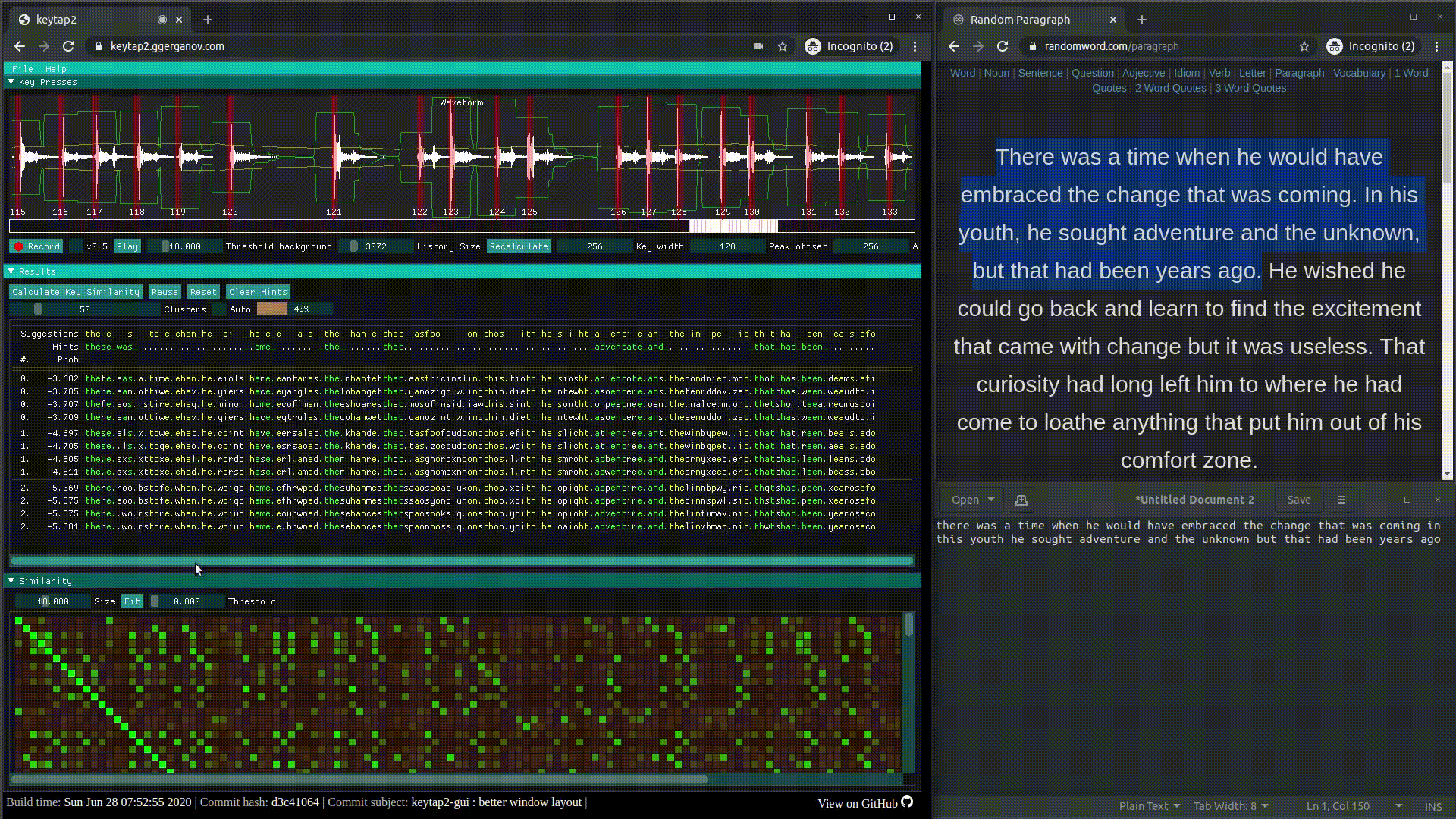
keytap3: прослушка клавиатуры из браузера через микрофон | исходники | gui.

-
the-story: эксперимент по коллективному написанию текста большим количеством авторов (с голосованием за слова) | исходники.
-
@tweet2btc: коллективное предсказание цены биткоина через опросы в Twitter | исходник.
-
@tweet2doom: твиттер-бот, который играет в Doom | исходники | данные | эксплорер.

-
morse-meme: генератор мемов на азбуке Морзе | исходники.
-
GGMorse: расшифровка кода Морзе в реальном времени по звуку| исходники | iOS | Android.

-
Spectrogram: визуализация аудиоспектра в реальном времени | исходники.
-
Waver: обмен сообщениями и файлами по звуковому каналу (через ультразвук) | исходники | iOS | Android.

Это удобный способ передать файлы с одного мобильного устройства на другое, если они не могут установить цифровое соединение.
-
keytap2: звуковой кейлогер на основе частотных n-грамм, то есть комбинаций из последовательностей звуковых фрагментов | исходники | обсуждение.

(https://asciinema.org/a/310405)
-
ImTui: библиотека непосредственного режима (immediate mode) в текстовом UI | исходники на C++. Она используется в текстовых клиентах для Slack, WTF и HN, которые указаны выше в этом списке проектов.

-
dot-to-ascii: Конвертер Graphviz в ASCII | исходники.

-
lottery-check: показывает, как часто выигрывали произвольные комбинации чисел в болгарской лотерее 6/49 | исходники.
-
Diff Challenge: игра Diff Challenge в виде баш-скрипта, смысл игры заключается в поиске программы
y, которая изменяет программуx, а выдачаyсоответствует разнице междуxиy:
$ ./y > diff $ patch y < diff $ cmp x y $ -
ImGui-WS: графический интерфейс Dear ImGui через WebSockets | исходники.

-
typing-battles: многопользовательская игра, кто быстрее набирает на клавиатуре (сервер: C++/WebSockets, клиент: JS) | исходники.
-
keytap-challenge: угадай, какой текст набирается.
-
keytap: акустическая прослушка клавиатуры с предварительным обучением.
-
wave-gui: ещё один инструмент передачи данных с помощью звука | исходники.
-
wave-share: передача файлов с помощью звука через браузер | исходники.
© 2025 ООО «МТ ФИНАНС»
Источник: habr.com