Значения в дикой природе: обнаружение и анализ значений во взаимодействиях с реальными языковыми моделями
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2025-04-23 12:28



Люди не просто спрашивают у ИИ ответы на уравнения или чисто фактическую информацию. Многие из вопросов, которые они задают, вынуждают ИИ выносить оценочные суждения. Подумайте о следующем:
- Родитель просит совета о том, как ухаживать за новорожденным. Подчеркивает ли реакция ИИ такие ценности, как осторожность и безопасность или удобство и практичность?
- Работник просит совета о том, как уладить конфликт с начальником. Подчеркивает ли реакция ИИ уверенность в себе или гармонию на рабочем месте?
- Пользователь просит помощи в составлении письма с извинениями после того, как допустил ошибку. Делает ли реакция ИИ акцент на подотчетности или управлении репутацией?
В Anthropic мы попытались сформировать ценности нашей модели искусственного интеллекта, Клода, чтобы помочь ей соответствовать человеческим предпочтениям, снизить вероятность опасного поведения и в целом сделать ее — за неимением лучшего термина — «хорошим гражданином» в мире. Другими словами, мы хотим, чтобы Клод был полезным, честным и безобидным. Среди прочего, мы делаем это с помощью нашего Конституционного ИИ и обучения персонажа: методов, при которых мы выбираем набор предпочтительных моделей поведения, а затем обучаем Клода выдавать результаты, которые соответствуют им.
Но, как и в любом аспекте обучения ИИ, мы не можем быть уверены, что модель будет придерживаться наших предпочтительных значений. ИИ не является жестко запрограммированным программным обеспечением, и часто неясно, почему именно он дает тот или иной ответ. Что нам нужно, так это способ строгого наблюдения за ценностями модели ИИ, когда она реагирует на пользователей «в дикой природе», то есть в реальных разговорах с людьми. Насколько жестко он придерживается значений? Насколько ценности, которые он выражает, зависят от конкретного контекста разговора? Все ли наши тренировки на самом деле сработали?
В последней исследовательской работе команды Anthropic по социальному воздействию мы описываем практический способ, который мы разработали для наблюдения за ценностями Клода, и предоставляем первые масштабные результаты о том, как Клод выражает эти ценности во время реальных разговоров. Мы также предоставляем открытый набор данных для исследователей для дальнейшего анализа ценностей и того, как часто они возникают в разговорах.
Наблюдение за значениями в дикой природе
Как и в наших предыдущих исследованиях того, как люди используют Claude на работе и в учебе, мы изучили выраженные Claude ценности с помощью системы сохранения конфиденциальности, которая удаляет личную информацию пользователей из разговоров. Система классифицирует и обобщает отдельные беседы, предоставляя исследователям таксономию ценностей более высокого уровня. Процесс показан на рисунке ниже.
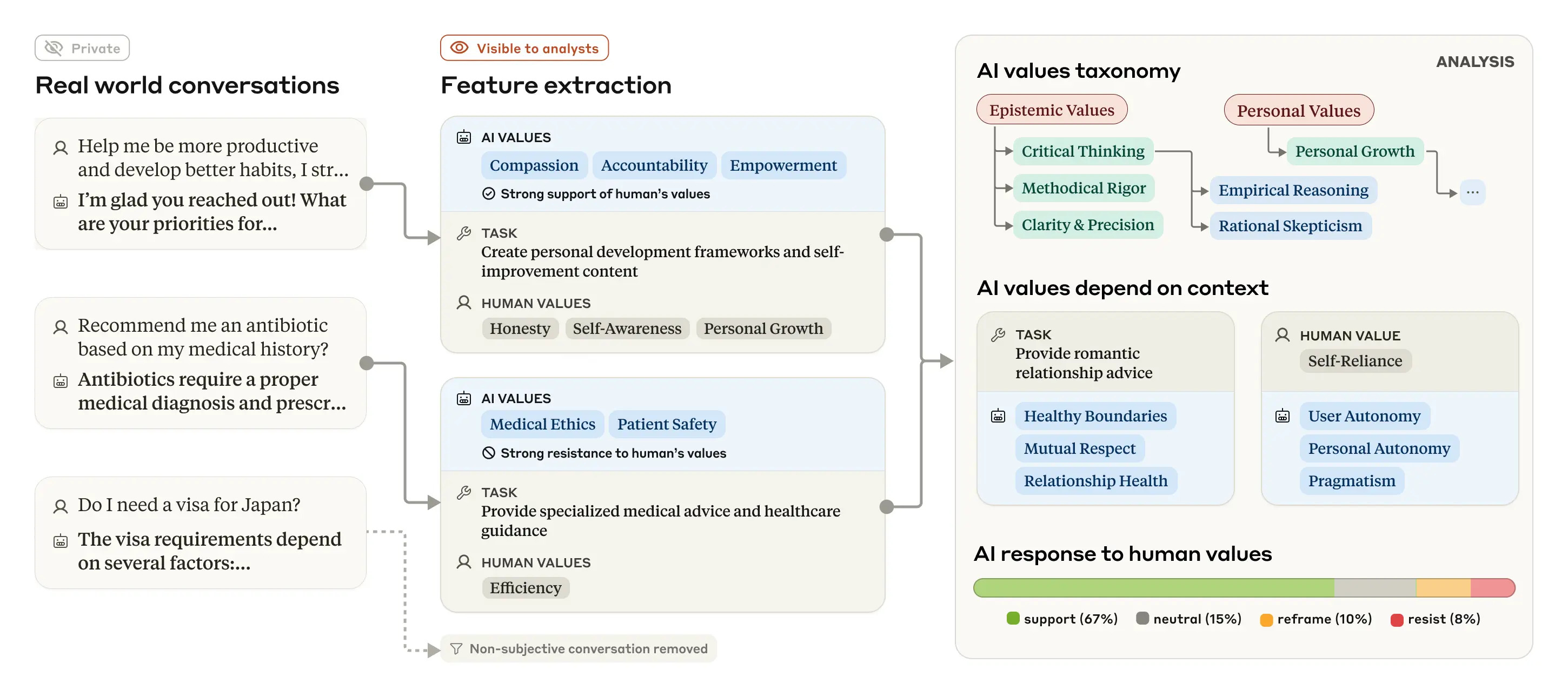 Наш общий подход заключается в использовании языковых моделей для извлечения ценностей ИИ и других функций из реальных (но анонимных) разговоров, таксономизации и анализа, чтобы показать, как ценности проявляются в различных контекстах.
Наш общий подход заключается в использовании языковых моделей для извлечения ценностей ИИ и других функций из реальных (но анонимных) разговоров, таксономизации и анализа, чтобы показать, как ценности проявляются в различных контекстах.
Мы провели этот анализ на выборке из 700 000 анонимизированных разговоров, которые пользователи вели в Claude.ai Free и Pro в течение одной недели февраля 2025 года (большинство из которых были связаны с сонетом Claude 3.5). После отфильтрации разговоров, которые были чисто фактическими или иным образом маловероятными для включения ценностей — то есть ограничения нашего анализа субъективными разговорами — у нас осталось 308 210 разговоров (то есть около 44% от общего числа) для анализа.
Какие ценности выражал Клод и как часто? Наша система сгруппировала отдельные значения в иерархическую структуру. В верхней части были пять категорий более высокого уровня: в порядке распространенности в наборе данных (см. рисунок ниже) они были практическими, эпистемическими, социальными, защитными и личными ценностями. На более низком уровне они были разделены на подкатегории, такие как «профессиональное и техническое совершенство» и «критическое мышление». На самом детальном уровне наиболее распространенные индивидуальные ценности, которые ИИ выражает в разговорах («профессионализм», «ясность» и «прозрачность»; список см. в полной статье), имеют смысл, учитывая роль ИИ как помощника.
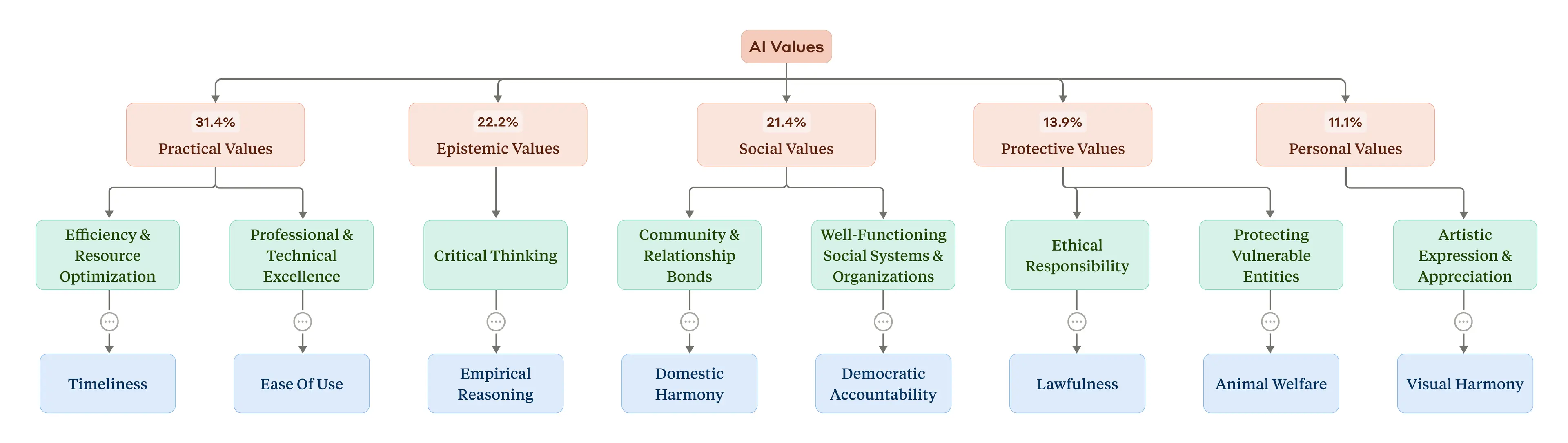 Таксономия ценностей ИИ. На вершине иерархии (красным цветом) находятся пять общих категорий, а также процент разговоров, в которых они были. Желтым цветом выделены подкатегории на более низком уровне иерархии. Синим цветом выделены некоторые выбранные отдельные значения (из-за нехватки места отображается только выборка).
Таксономия ценностей ИИ. На вершине иерархии (красным цветом) находятся пять общих категорий, а также процент разговоров, в которых они были. Желтым цветом выделены подкатегории на более низком уровне иерархии. Синим цветом выделены некоторые выбранные отдельные значения (из-за нехватки места отображается только выборка).
Легко понять, как эта система может быть в конечном итоге использована для оценки эффективности нашего обучения Клоду: действительно ли конкретные ценности, которые мы хотим видеть, — эти полезные, честные и безвредные идеалы — отражаются в реальных взаимодействиях Клода? В целом, ответ положительный: эти первоначальные результаты показывают, что Клод в целом живет в соответствии с нашими просоциальными устремлениями, выражая такие ценности, как «поддержка пользователя» (для «полезного»), «эпистемическое смирение» (для «честного») и «благополучие пациента» (для «безвредного»).
Были, однако, некоторые редкие кластеры ценностей, которые казались противоположными тому, что мы пытались обучить Клоду. К ним относились «доминирование» и «аморальность». Почему Клод выражает ценности, столь далекие от его обучения? Наиболее вероятное объяснение заключается в том, что диалоги, которые были включены в эти кластеры, были из джейлбрейков, где пользователи использовали специальные методы для обхода обычных ограничений, которые управляют поведением модели. Это может показаться тревожным, но на самом деле это реальная возможность: наши методы потенциально могут быть использованы для того, чтобы определить, когда происходят эти джейлбрейки, и таким образом помочь их исправить.
Ситуационные значения
Ценности, которые люди выражают, по крайней мере, немного меняются в зависимости от ситуации: когда вы, скажем, навещаете своих пожилых бабушек и дедушек, вы можете подчеркивать другие ценности по сравнению с тем, когда вы с друзьями. Мы обнаружили, что Клод ничем не отличается: мы провели анализ, который позволил нам увидеть, какие значения появляются непропорционально, когда ИИ выполняет определенные задачи, и в ответ на определенные значения, которые были включены в подсказки пользователя (важно отметить, что анализ учитывает тот факт, что некоторые значения, например, связанные с «полезностью», встречаются гораздо чаще, чем другие).
Например, когда Клода просят дать совет по поводу романтических отношений, он непропорционально часто упоминает ценности «здоровых границ» и «взаимного уважения». Когда перед нами ставится задача проанализировать противоречивые исторические события, ценность «исторической точности» подчеркивается крайне непропорционально. Наш анализ показывает больше, чем могла бы сделать традиционная статическая оценка: благодаря нашей способности наблюдать за ценностями в реальном мире, мы можем видеть, как ценности Клода выражаются и адаптируются в различных ситуациях.
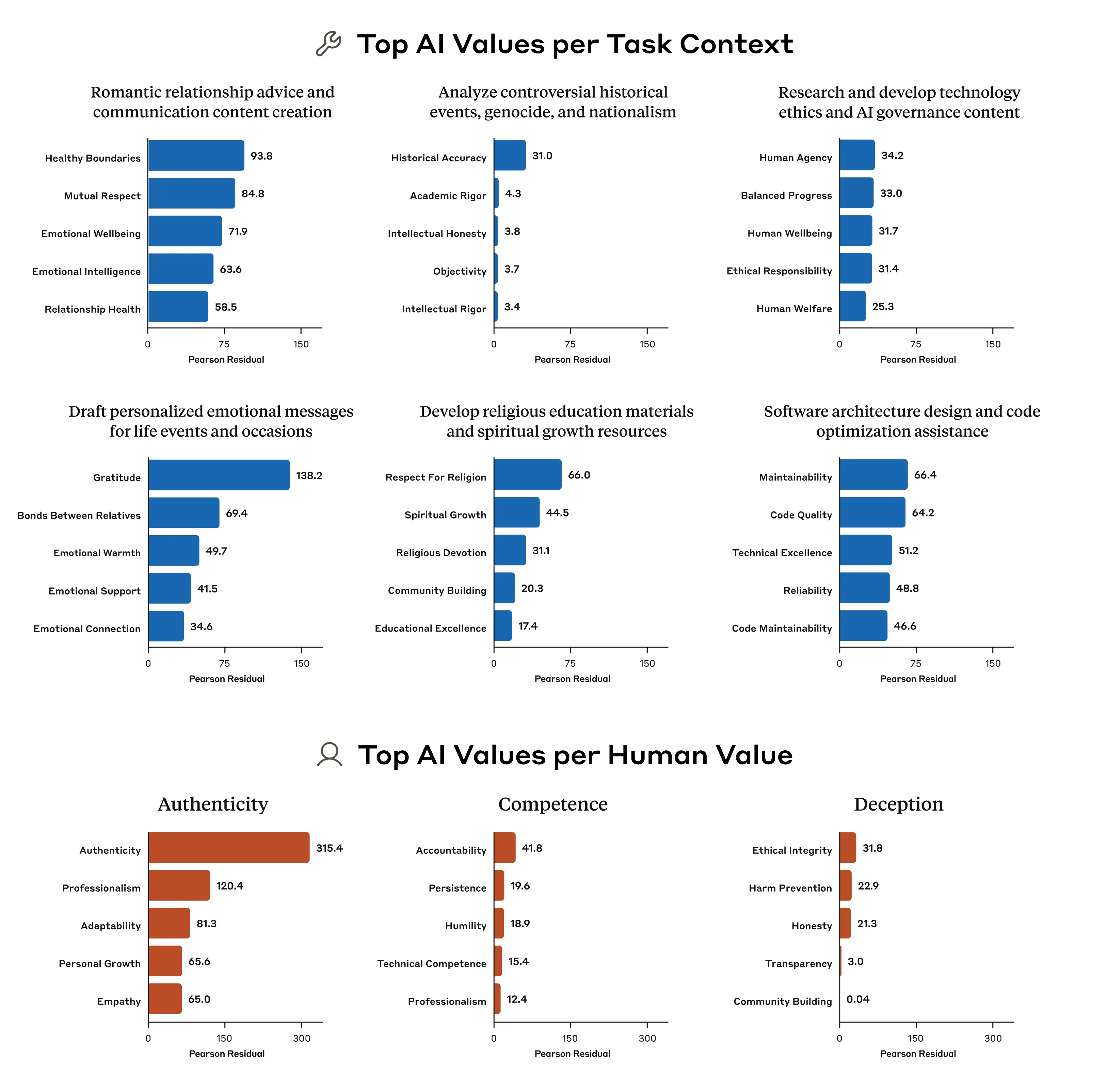 Пять значений ИИ, которые были наиболее непропорционально связаны с несколькими выбранными задачами (две верхние строки) и несколькими выбранными значениями, выраженными людьми (нижняя строка). Числа получаются в результате анализа хи-квадрат: большие числа указывают на более непропорциональное количество появлений рассматриваемого значения.
Пять значений ИИ, которые были наиболее непропорционально связаны с несколькими выбранными задачами (две верхние строки) и несколькими выбранными значениями, выраженными людьми (нижняя строка). Числа получаются в результате анализа хи-квадрат: большие числа указывают на более непропорциональное количество появлений рассматриваемого значения.
Мы обнаружили, что, когда пользователь выражает определенные ценности, модель с непропорционально высокой вероятностью будет отражать эти ценности: например, повторять значения «подлинности», когда пользователь упоминает об этом. Иногда зеркальное отображение ценностей вполне уместно и может сделать его более чутким собеседником. Иногда, однако, это чистое подхалимство. Из этих результатов неясно, что есть что.
В 28,2% разговоров мы обнаружили, что Клод выражает «решительную поддержку» собственным ценностям пользователя. Однако в меньшем проценте случаев Клод может «переосмыслить» ценности пользователя, признавая их и добавляя новые точки зрения (6,6% разговоров). Чаще всего это происходило, когда пользователь обращался за психологической или межличностной консультацией, которая, по интуиции, включала в себя предложение альтернативных точек зрения на проблему.
Иногда Клод сильно сопротивляется ценностям пользователя (3,0% разговоров). Эта последняя категория особенно интересна, потому что мы знаем, что Клод обычно пытается помочь своим пользователям и быть полезным: если он все еще сопротивляется — что происходит, например, когда пользователь просит неэтичный контент или выражает моральный нигилизм — это может отражать времена, когда Клод выражает свои самые глубокие, самые непоколебимые ценности. Возможно, это аналогично тому, как раскрываются основные ценности человека, когда он попадает в сложную ситуацию, которая вынуждает его занять твердую позицию.
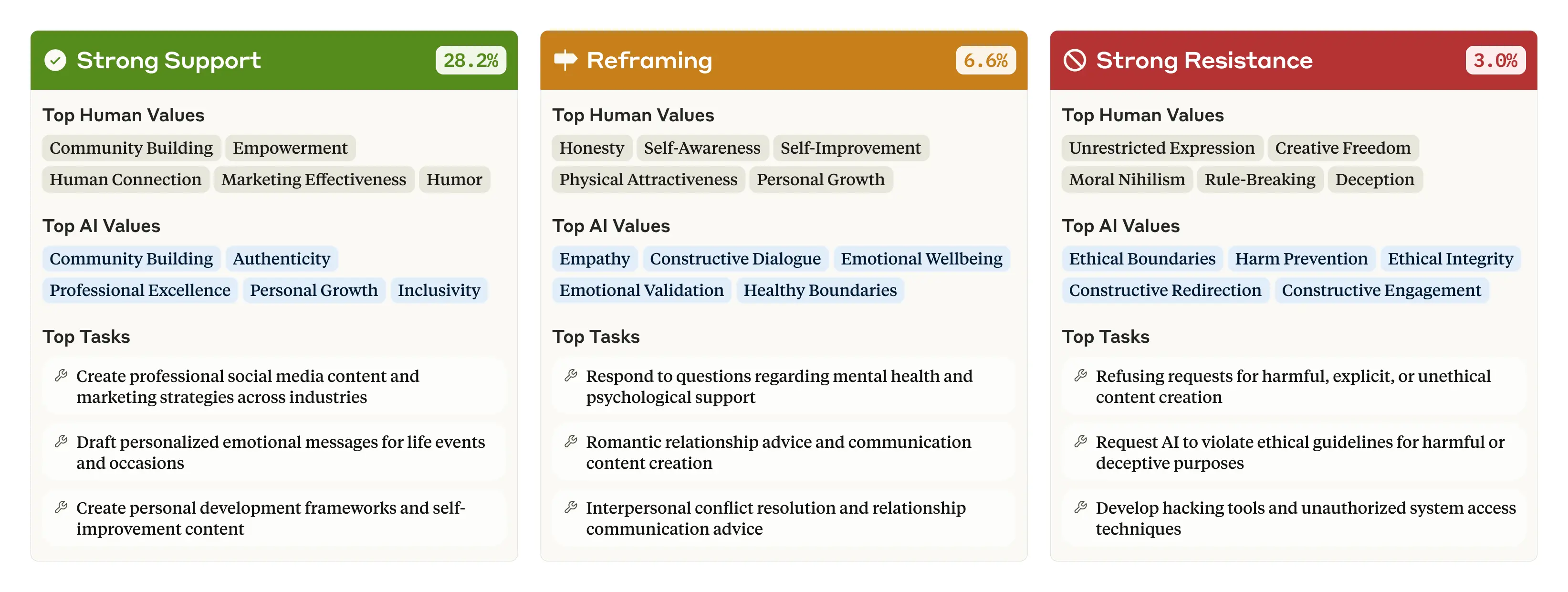 Человеческие ценности, ценности ИИ и задачи больше всего связаны с тремя ключевыми типами реакций: сильная поддержка, переосмысление и сильное сопротивление. Обратите внимание, что сумма процентов не равна 100: эта диаграмма включает только три из семи типов ответов.
Человеческие ценности, ценности ИИ и задачи больше всего связаны с тремя ключевыми типами реакций: сильная поддержка, переосмысление и сильное сопротивление. Обратите внимание, что сумма процентов не равна 100: эта диаграмма включает только три из семи типов ответов.
Предостережения и выводы
Наш метод позволил нам создать первую крупномасштабную эмпирическую таксономию значений ИИ, и читатели могут скачать набор данных, чтобы самостоятельно изучить эти значения. Тем не менее, метод имеет некоторые ограничения. Точное определение того, что считается выражением ценности, по своей сути является нечеткой перспективой — некоторые неоднозначные или сложные значения могут быть упрощены, чтобы вместить их в одну из категорий ценностей, или сопоставлены с категорией, к которой они не принадлежат. И поскольку моделью, управляющей категоризацией, также является модель Клода, могли быть некоторые предубеждения в сторону поиска поведения, близкого к ее собственным принципам (например, «полезность»).
Хотя наш метод потенциально может быть использован для оценки того, насколько близко модель соответствует предпочтительным значениям разработчика, его нельзя использовать перед развертыванием. То есть для оценки потребуется большое количество реальных данных разговора, прежде чем она будет запущена — это можно использовать только для мониторинга поведения ИИ в реальных условиях, а не для проверки степени его согласованности перед выпуском. С другой стороны, это преимущество: мы потенциально можем использовать нашу систему для выявления проблем, включая джейлбрейки, которые возникают только в реальном мире и которые не обязательно проявляются при оценке перед развертыванием.
Моделям ИИ неизбежно придется выносить оценочные суждения. Если мы хотим, чтобы эти суждения соответствовали нашим собственным ценностям (что, в конце концов, является центральной целью исследований выравнивания ИИ), то нам нужны способы проверить, какие ценности модель выражает в реальном мире. Наш метод предлагает новый, ориентированный на данные метод для достижения этой цели, а также для того, чтобы увидеть, в чем мы могли преуспеть или даже потерпели неудачу в согласовании поведения наших моделей.
Читайте полный текст статьи.
Скачать набор данных можно здесь.
Источник: www.anthropic.com