Llama Nemotron: семейство открытых моделей от Nvidia обходит DeepSeek R1 в рассуждении и математике
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2025-03-21 11:52

NVIDIA анонсировала семейство открытых моделей Llama Nemotron с продвинутыми возможностями в задачах рассуждения. Дообучение моделей Llama 3.3 и 3.1 позволило Nvidia улучшить их точность на 20% при достижении в 5 раз большей скорости инференса. Модели специализированы для задач математики, программирования, рассуждений и принятия сложных решений. Эти модели могут работать как независимо, так и в составе сложных пайплайнов на платформе микросервисов NIM.
Модели Llama Nemotron Nano 8B и Super 49B доступны на build.nvidia.com и Hugging Face.
Детальное описание моделей Llama Nemotron
Nano (8B) архитектура построена на базе Llama-3.1-8B-Instruct в виде плотного decoder-only трансформера с длиной контекста 128K. Она спроектирована для запуска на одном GPU RTX серий 30/40/50, H100-80GB или A100-80GB. Подходит для локальной работы.
Super (49B) — это дообученная (supervised fine-tuned) Llama-3.3-70B-Instruct, улучшенная с помощью Neural Architecture Search (NAS) c cохранением длины контекста 128K. Улучшения включают skip attention, где внимание в некоторых блоках пропускается или заменяется линейным слоем, вариационный FFN (с различными коэффициентами расширения/сжатия между блоками). Эта архитектура специально оптимизирована для работы на одном GPU H100-80GB.
Ultra (253B) дистиллирована из Llama 3.1 405B, спроектирована для решения задач крупного бизнеса. На момент написания статьи модель не выложена в публичный доступ.
Трехфазный процесс обучения
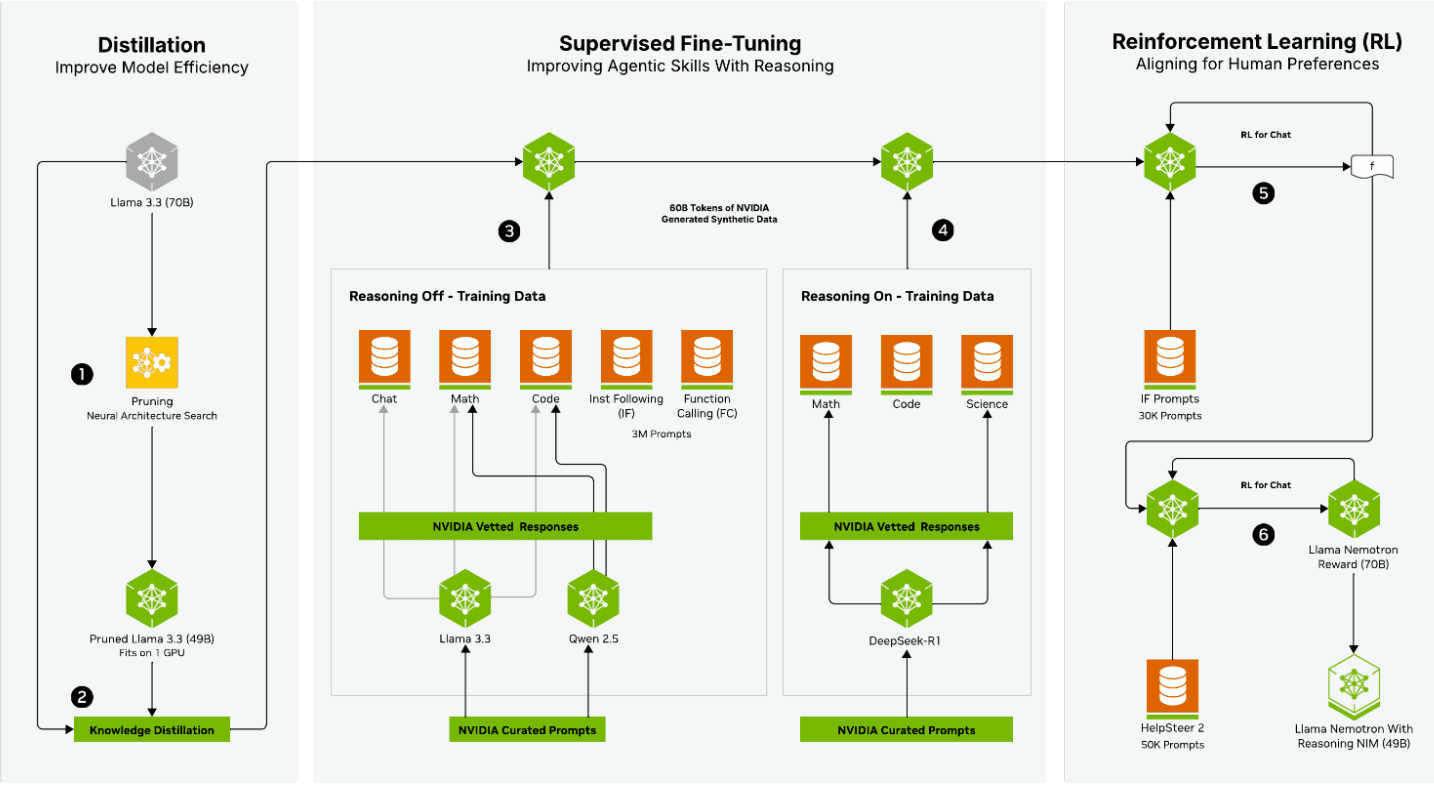
- Фаза дистилляции началась с Llama 3.3 (70B) в качестве базовой модели, применяя Neural Architecture Search для прунинга модели с последующей Knowledge Distillation для создания прунинговой 49B модели, помещающейся на одном GPU.
- Фаза дообучения с учителем фокусировалась на улучшении навыков агентов в рассужденях, используя два параллельных пути обучения. Путь «Reasoning Off» использовал данные из областей Chat, Math, Code, Instruction Following и Function Calling, в то время как путь «Reasoning On» специально заточен под задачи Math, Code и Science.
- Наконец, фаза обучения с подкреплением выравнивала модель с предпочтениями человека через несколько итераций подкрепления.
Результаты тестов Llama Nemotron
Модели Llama Nemotron демонстрируют значительное улучшение производительности при включении режима рассуждений. На бенчмарке MATH500 (pass@1) у модели Nano результат улучшается с 36.6% до 95.4% с включенным рассуждением, у модели Super с 74.0% до впечатляющих 96.6%. На MT-Bench модель Nano набирает от 7.9 до 8.1 с рассуждением, в то время как модель Super достигает 9.17 в режиме без рассуждений. Последовательно во всех бенчмарках модель Super превосходит своего аналога Nano.
Модель Llama Nemotron Super 49B демонстрирует исключительную производительность в сравнительных тестах, превосходя более крупные модели. Несмотря на меньший размер (49B параметров против 70B у конкурентов), она показывает лучшие результаты во всех тестируемых категориях: научных рассуждениях (GPQA Diamond), сложной математике (AIME 2025 и MATH 500), чате (Arena Hard) и вызове функций (BFCL). Особенно впечатляющие показатели достигнуты в тесте MATH 500, где точность превышает 96%, и в Arena Hard с результатом около 88%. При этом модель обеспечивает в 5 раз более высокую пропускную способность (около 3000 токенов в секунду), что делает её не только более точной, но и значительно более эффективной в реальных сценариях использования.
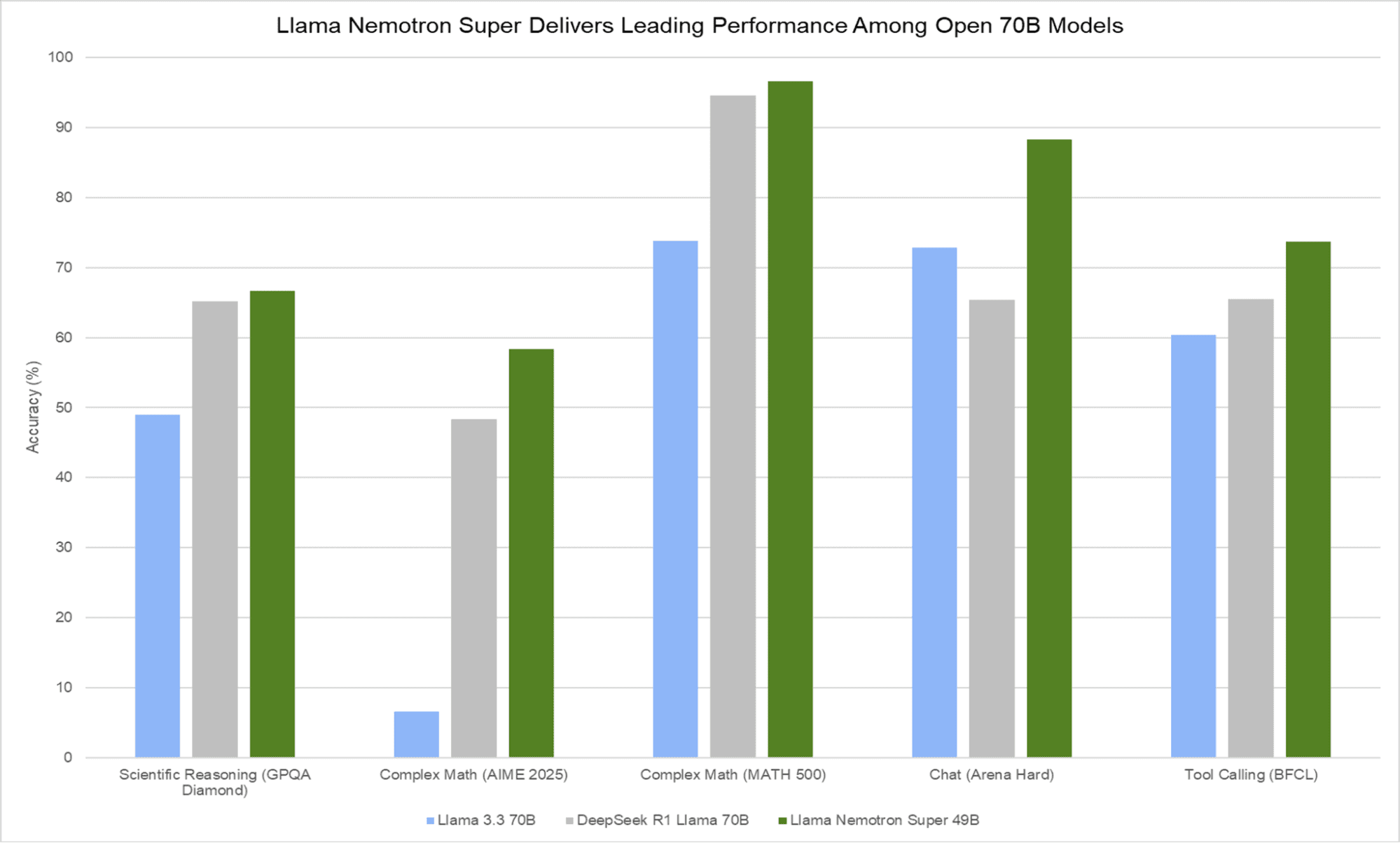
Новый лидер на Arena Hard.
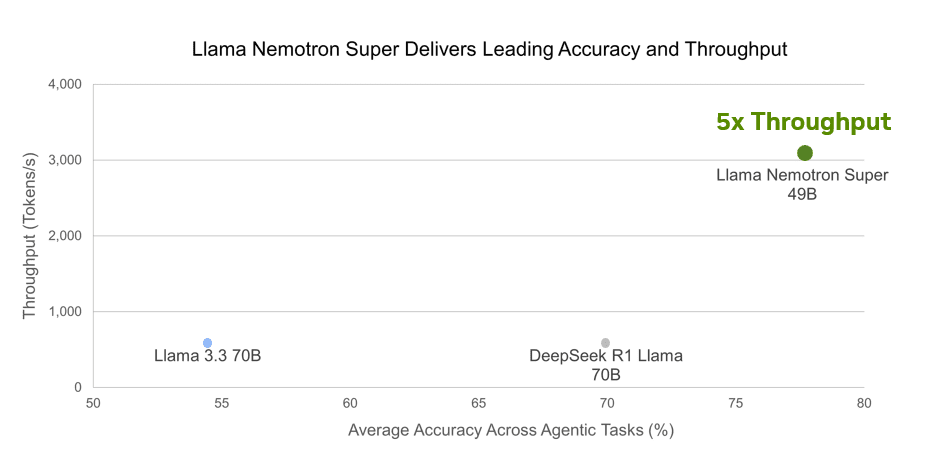
Обе модели предлагают два режима работы, контролируемые через системный промпт: «Reasoning On» (рекомендуемые настройки: temperature=0.6, top_p=0.95) и «Reasoning Off» (рекомендуется: greedy декодирование).
Источник: neurohive.io