Учёные: даже 0,001% ложной информации могут навредить при обучении ИИ
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2025-01-19 20:38
ИИ теория, алгоритмы машинного обучения, ошибки нейронных сетей

Недавнее исследование сотрудников Нью-Йоркского университета выявило, что даже минимальное количество дезинформации в обучающих данных может существенно ухудшить работу больших языковых моделей (LLM). Учёные установили, что присутствие всего 0,001% ложной информации в наборе данных способно привести к распространению ошибок, особенно в медицине.
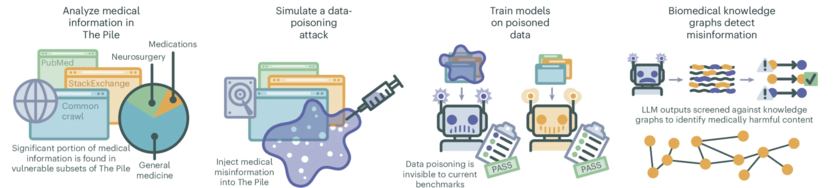
В рамках эксперимента исследователи намеренно добавили сгенерированную ИИ медицинскую дезинформацию в широко используемый обучающий набор данных The Pile, который содержит качественные медицинские источники вроде PubMed. Исследователи создали 150 000 ложных медицинских статей за 24 часа, заменив тем самым 0,001% обучающих данных. Результаты показали, что это привело к увеличению распространения вредоносного контента на 4,8%.
Особую тревогу вызывает то, что даже при наличии дезинформации в обучающих данных модели ИИ продолжают демонстрировать высокие результаты в стандартных тестах, используемых для оценки медицинских LLM. Это означает, что традиционные методы проверки могут не выявить скрытые риски, связанные с использованием таких моделей в медицинской практике.
Исследователи подчёркивают необходимость усиления контроля за источниками данных и прозрачностью разработки LLM, особенно в здравоохранении, где распространение дезинформации может поставить под угрозу безопасность пациентов. Они призывают разработчиков ИИ и медицинских специалистов учитывать эту уязвимость при создании и использовании языковых моделей, а также не применять их для диагностических или терапевтических задач без должных мер предосторожности.
Источник:
Телеграм: t.me/ainewsline
Источник: 4pda.to