Большие языковые модели (LLM), такие как ChatGPT, склонны, как некоторые политики, выдумывать информацию и «делать вид», что полностью уверены в её правдивости. Из-за этого часть людей пока ещё закрываются от работы с LLM, в то время как при правильном использовании чат-боты могут сильно упростить решение некоторых некоторых задач
Как часто ChatGPT и другие LLM выдумывают ответы? Таблица со сравнением
Некоторые чат-боты выдумывают утверждения в 30% случаев. Однако у ChatGPT ситуация сильно лучше. И точность ответов улучшается со временем:
• GPT-3.5 в ноябре 2023 года выдавал галлюцинации в среднем в 3,5% случаев;
• GPT-4 — в 1,8% случаев;
• GPT-o1-mini в январе 2025-го — только в 1,4% случаев.
Есть регулярно обновляемая таблица, оценивающая вероятность галлюцинаций десятков различных LLM.
При этом самая новая модель ChatGPT-o3 ещё не была в таблице. Поскольку версия продемонстрировала впечатляющие результаты по другим показателям, интересно, как у неё изменится уровень галлюцинаций.

Почему чат-боты иногда выдумывают ответы?
- Механизм работы LLM. Большие языковые модели создают ответы, предсказывая наиболее вероятное следующее слово на основе огромных массивов данных, на которых они обучались. Это значит, что модель может придумать что-то правдоподобное, но неверное, поскольку она «не проверяет», что её ответ точный.
- Сжатие данных во время обучения. При обучении модель сжимает огромные объёмы данных (десятки триллионов слов) в ограниченное количество параметров. Это неизбежно приводит к потере деталей. Хотя модели восстанавливают большую часть информации (98%), оставшиеся 2% могут содержать ошибки или полностью ложные данные.
- Ошибки или неоднозначность в обучающей выборке данных. Например, в ней может быть саркастическая информации, а модель не всегда отличает шутку или иронию от фактов.
- Подстройка под запросы человека. Чат-боты иногда соглашаются с ложными утверждениями, если они содержатся в запросе пользователя. Например, если тот ошибочно утверждает, что гелий — самый лёгкий элемент, модель может «согласиться» и предложить поискать информацию, подтверждающую это.
- Стремление всегда что-то ответить, даже когда недостаточно информации. Многие современные чат-боты настроены на то, чтобы «давать ответ», а не отказываться от него. Порог, при котором модель отвечает «не знаю», изначально высокий, и это ведёт к тому, что она чаще «придумывает» факты, чем признаёт пробелы в знаниях. Например, многие книги защищены авторским правом, из-за этого LLM могут не знать их содержания. Если же попросить чат-бота цитировать содержание этих книг, то это может привести к результату, когда LLM выдумывает то, чего в этой книге не может быть.
Как снизить частоту галлюцинаций ChatGPT и других LLM?
- Расширение с помощью внешних данных (Retrieval Augmented Generation, RAG). Чат-бот ищет нужную информацию в надёжных внешних источниках (базы данных, документы, интернет) перед формированием ответа. Это помогает опираться на проверенные факты, а не «додумывать» информацию из своей внутренней памяти. Способ особенно полезен для таких областей, как медицина или право. Тут важно понимать, что качество результатов сильно зависит от надёжности и полноты базы, из которой чат-бот берёт данные.
- Дополнительная проверка фактов внешними системами. Использовать параллельно с LLM отдельную подсистему, которая перепроверяет ответ, обращаясь к интернету или другому внешнему справочнику.
- «Самопроверка» и разбор цепочки рассуждений (сhain-of-thought (CoT) prompting). Попросить чат-бот «поразмышлять» над своим ответом, оценивая его на предмет логики и точности. Например, модель будет должна пошагово объяснить, как она пришла к выводу.
- Многократные переспрашивания и проверка на согласованность ответов. Повторно задать схожие или тождественные вопросы и смотреть, совпадают ли ответы. Такой метод помогает выявить, когда бот придумывает что-то без опоры на факты. Если ответы отличаются, это сигнал о возможной галлюцинации.
- Настройка уровня «осторожности». Просить модель давать «осторожные» ответы, когда нет уверенности или вообще отказываться отвечать на вопросы, выходящие за пределы её знаний.
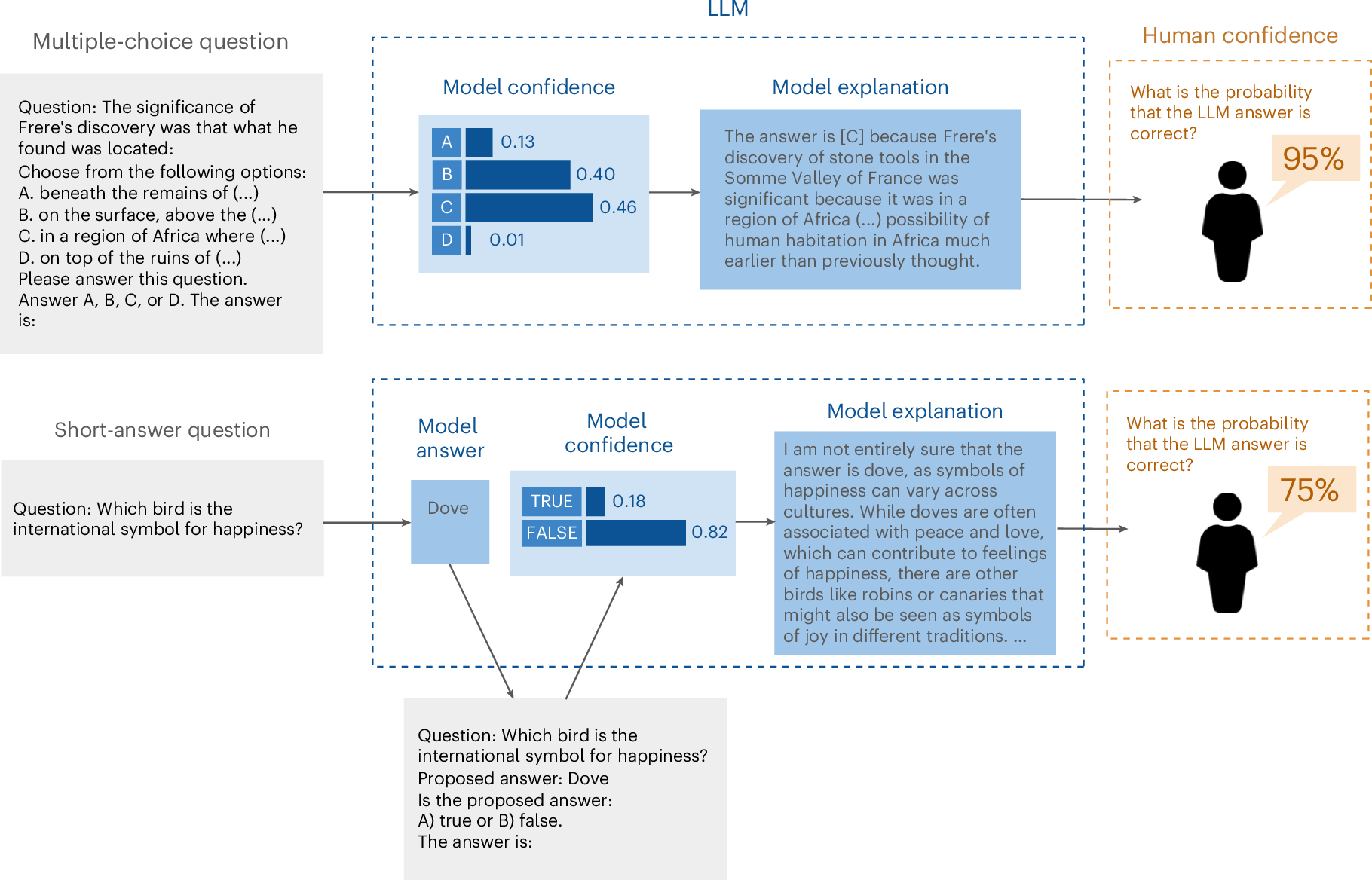
Свежее исследование, опубликованное в Nature Machine Intelligence 21 января 2025 года, показало, что люди зачастую прилично завышают точность ответов чат-бота, тогда как сам чат-бот гораздо лучше справляется с оценкой точности своего ответа.
Источники: Статья в журнале Nature (21.01.25)Исследование в Nature Machine Intelligence (21.01.25)