
TL;DR: краткое содержание этого поста в исполнении Ноама Хомского (слева) и BERT; спасибо Володе Селеверстову, который обратил моё внимание на этот мем ?
Что случилось?
В начале октября новостные издания сообщили о массовых сокращениях в компании ABBYY, которую многие помнят по словарям Lingvo и OCR-распознавалке FineReader. Я узнал о волне увольнений чуть раньше: когда-то я сам работал в ABBYY и с тех пор у меня оставалось много друзей в компании. В понедельник 30 сентября моя лента в LinkedIn заполнилась десятками постов о поиске работы…
Работу искали не только мои молодые друзья, но и седовласые зубры разработки на C++, отучившиеся на Физтехе еще при СССР и проработавшие в ABBYY под 30 лет. Было ясно, что компания, которая когда-то была одним из локомотивов наукоёмкого российского IT, перестала существовать. От ABBYY осталась лишь обертка из известного бренда.

Автор этого поста в московском офисе ABBYY и футболке ABBYY Rocks, 2020 год. Фото Полины Старосоцкой.
В новостях о сокращениях в ABBYY акцент делался на дискриминацию по гражданству: уволили из компании почти исключительно людей с российскими паспортами — 200-300 человек. Альтернативные голоса говорили, что уволили не «всех русских», а «всю разработку», которая исторически была из России (и до весны 2022 целиком сидела в Москве)… И что причины сокращений экономические, а не политические — компания несла убытки. Но мне в этой истории интересна не сиюминутная политическая или экономическая конъюнктура, а история о крахе надежд на лингвистику в автоматической обработке языка (она же Natural language processing, она же NLP). И это долгая история, простирающаяся на десятилетия.
Лингвисты и NLP: история (не)любви
Конец ABBYY — это конец большой мечты. Мечты, которая родилась много десятилетий назад, задолго до самой компании. Мечты о том, что лингвистическая теория — то есть все те способы моделировать язык, которые придумали ученые-лингвисты, — поможет сделать наиболее точные инструменты автоматической обработки языка. Ведь это логично: чтобы создать атомную бомбу, надо понять устройство атома и атомного ядра. А чтобы создать машинный переводчик или систему автоматического извлечения информации из текста — надо понять устройство языка. Так?
На самом деле нет. По крайней мере всё, что мы знаем на сегодняшний день, указывает на обратное. Чем более успешными становились прикладные системы работы с естественным языком (информационный поиск в интернете, машинный перевод, распознавание речи, чатботы-ассистенты), тем меньше в них оставалось какой бы то ни было лингвистики. Этот тренд был замечен еще в конце 80-х — начале 90-х, когда в Америке стала популярной фраза, приписываемая Фредерику Елинеку, руководителю разработок по распознаванию речи в IBM:
«Каждый раз, когда мы увольняем лингвиста, качество работы системы повышается»
Фредерик Елинек
История компании ABBYY — это история трех десятилетий попыток опровергнуть этот обидный для лингвистов афоризм. Попыток, которые стоили десятки миллионов долларов, но так и закончились ничем.
Хотя я никогда не был близок к руководству ABBYY и знаю не так много, мне кажется важным зафиксировать эту историю. Это взгляд с моей перспективы рядового сотрудника и рядового компьютерного лингвиста. Пусть те, кто видят глубже и знают больше, дополнят и исправят мой рассказ.
Откуда взялась ABBYY и как она пришла к успеху
История ABBYY началась в 1989 году, когда студент МФТИ (знаменитого московского Физтеха) Давид Ян решил сделать электронный словарь, чтобы облегчить себе сдачу экзаменов по французскому. Так возникли словари Lingvo. Через несколько лет появился следующий продукт компании (тогда еще называвшейся не ABBYY, а BIT Software) — система распознавания символов FineReader. Проще говоря, это программа для превращения скана или фотографии с текстом — в распознанный машиночитаемый текст, который можно редактировать и по которому можно искать с помощью Ctrl+F / Cmd+F.
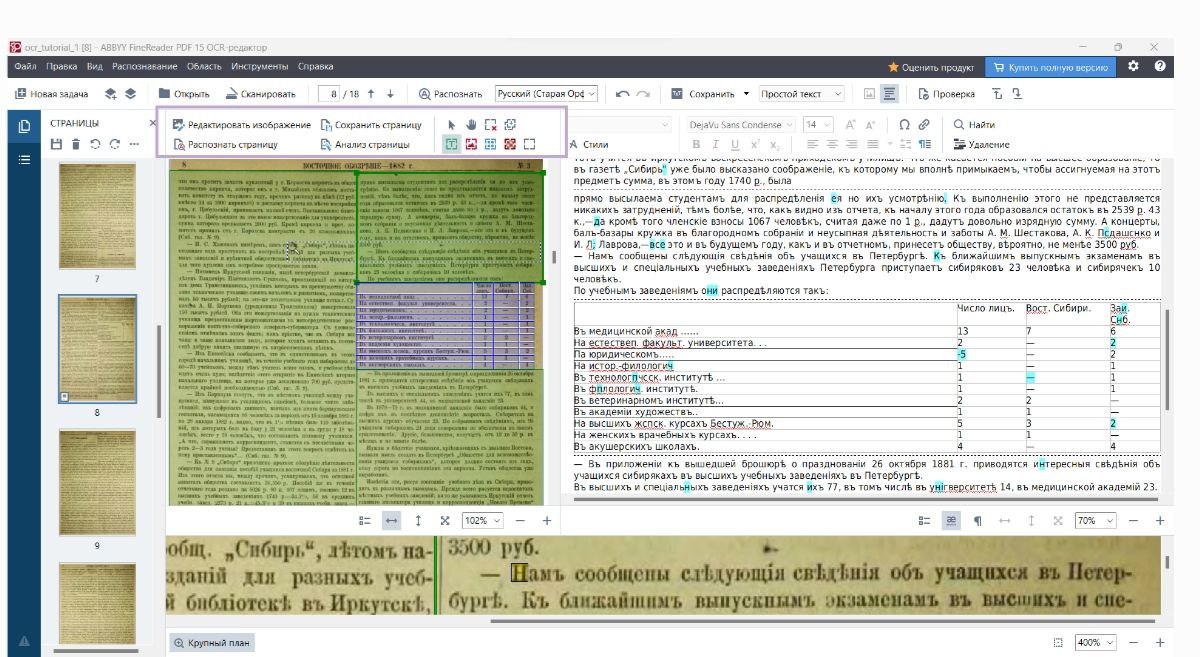
ABBYY FineReader за работой; слева и снизу — скан, справа — распознанный текст
FineReader и другие OCR-продукты ABBYY (системы распознавания форм и платежных поручений для банков и госучреждений, распознавание экзаменационных тестов типа ЕГЭ) стали коммерчески успешными не только в России, но и на мировом рынке, сделав компанию глобальным лидером оптического распознавания в 1990-е и 2000-е. Системы распознавания от ABBYY покупали американские банки, немецкие университеты, азиатские правительства. Компания в те годы была примером международного успеха российского IT. Именно оптическое распознавание на несколько десятилетий стало основой благосостояния ABBYY и обеспечило финансирование её экспериментов в области NLP.

Офис ABBYY в Москве зимой 2020 года. Фото автора.
От словарей и распознавания — к переводу
Во второй половине 1990-х годов ABBYY активно росла и искала свой следующий «большой проект» после распознавания. Для компании, у которой была экспертиза в электронных словарях и которая много работала с деловыми документами на разных языках, логичным шагом выглядел автоматический перевод. Научившись распознавать текст из картинки — научиться переводить его на другой язык. Это был следующий уровень понимания документов и он выглядел как хороший вызов для компании, у которой в тот момент были деньги, научная экспертиза и заряд предпринимательского энтузиазма.
В 1990-е прикладной машинный перевод находился в зачаточном состоянии. Хотя первые эксперименты по автоматизации перевода были проведены еще в 1954 году, с тех пор никому не удавалось создать надежно работающую систему — попытки формально описать язык и правила перевода из одного языка в другой раз за разом оказывались слишком сложной и монументальной задачей.
Сделать машинный перевод по всем правилам науки
Компания ABBYY была создана выпускниками Физтеха — людьми с мощной научной базой и уважением к фундаментальной науке. Поэтому к проблеме машинного перевода они тоже подошли фундаментально: отправились к лингвистам выяснять, какие есть фундаментальные теоретические подходы к моделированию языка. Тем более что лингвисты в ABBYY уже были: они работали и над наполнением словарей, и над созданием лингвистических моделей для улучшения распознавания в том же FineReader.
Во времена, когда компьютеры были слабыми, машинное обучение работало плохо из-за недостатка данных и примитивности алгоритмов, а нейросети оставались маргинальным направлением исследований и не применялись на практике, способность программы использовать какую-нибудь формальную модель — например, машинную морфологию для приведения слова в начальную форму (‘коню/конями/конём…’ => ‘конь’) — могла дать конкурентное преимущество. К примеру, в конце 1990-х и начале 2000-х машинная морфология была одним из факторов конкуренции Яндекса с Рамблером. В FineReader тоже была встроена морфология для многих языков, что позволяло программе отрабатывать лучше конкурентов.
Руководствуясь этим опытом, ABBYY двинулась покорять машинный перевод. На вооружение были приняты модели цельного описания языка, развивающие идеи лингвистов И.А. Мельчука (не пропустите его интервью «Системному Блоку»), А.К. Жолковского, Л.Н. Иорданской и Ю.Д. Апресяна — в первую очередь Модели «Смысл ? Текст» и Толково-комбинаторного словаря.

Юрий Апресян и Игорь Мельчук, около 1973 г. (Фото из архива Л. Касаткина)
Моделирование языков через смысловой уровень
Основная идея модели «Смысл ? Текст» — сопоставление множества языковых выражений некоему смысловому инварианту. Скажем, фразы «Страна Р напала на страну У», «Страна У была атакована страной Р», «Страна Р развязала против страны У войну» и т.п. могут быть языковыми выражениями одной ситуации, которую на смысловом уровне можно выразить, например, так:
Действие: Агрессия
Агрессор: Страна Р
Жертва агрессии: Страна У
Поскольку такой смысловой инвариант оказывается в значительной степени универсален, при описании в рамках модели более одного языка становится возможным построение системы машинного перевода. Модель «Смысл ? Текст», точнее, её смысловой уровень в таком случае выступает чем-то вроде интерлингвы, т.е. общего межъязыкового хранилища смыслов, к которому с разных сторон «привязаны» варианты выражения смыслов на разных языках. Считываем текст на одном языке, переводим на уровень интерлингвы, выбираем выражение смысла на другом языке… А чтобы порождать из смыслов грамматически правильные и верно выражающие их тексты, в модель должны быть вшиты ограничения целевого языка на всех уровнях: морфология (т.е. правила изменения форм слова), синтаксис (т.е. правила построения высказываний из множества слов), семантика (т.е. правила кодирования значения и смысловых сочетаний в конкретном языке).
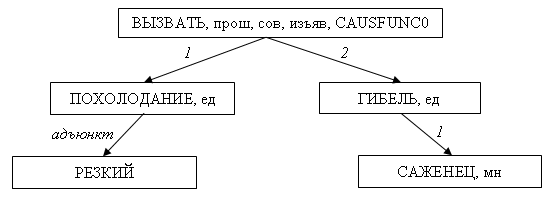
Формальное описание на уровне глубинного синтаксиса для смыслового инварианта, который выражают такие высказывания на русском языке: Резкое похолодание было причиной гибели саженцев, Гибель саженцев была следствием резкого похолодания, Резкое похолодание погубило саженцы, Саженцы погибли из-за резкого похолодания, Гибель саженцев была вызвана резким похолоданием, Резкое похолодание привело к гибели саженцев, Гибель саженцев проистекла из-за резкого похолодания и т.п. Источник: ИППИ РАН
Модель «Смысл ? Текст» изначально строилась с прицелом на практическое применение в машинном переводе. И первую попытку построить работающий машинный переводчик на этой теоретической основе предприняли задолго до появления ABBYY. В начале 1970-х эту работу возглавлял лингвист Ю.Д. Апресян в институте «Информэлектро», затем в середине 1980-х его группа перешла в Институт проблем передачи информации (ИППИ) АН СССР. В 1990-е команда в ИППИ работала под руководством И.М. Богуславского и Л.Л. Иомдина — в прошлом учеников Апресяна. Результат этой работы — лингвистический анализатор ЭТАП, который использовался для научных целей — например, для создания синтаксического подкорпуса НКРЯ.
Но ABBYY вложила в свою систему гораздо больше ресурсов, чем академические институты, и имела куда более амбициозные планы. Если ЭТАП был небольшой научной моделью, чем-то вроде небольшого макета самолета для обдува в аэродинамической трубе, то целью ABBYY было построить настоящий дальнемагистральный коммерческий авиалайнер в сфере автоматической обработки языка.

Обдувка макета самолета в аэродинамической трубе // Российская газета
Большие надежды: компилятор естественного языка
С конца 1990-х компания ABBYY нанимала все больше лингвистов для создания описания языка, в котором бы соединялись морфологический, синтаксический и семантический уровни и куда при этом могли бы по единой модели подключаться множество языков, сохраняя соответствие друг с другом. Основой для такого описания стала Универсальная семантическая иерархия — огромное дерево понятий, построенное по модели «от общего к частному» (лингвисты бы сказали: на основе отношений гипероним-гипоним). Например, слова «пудель» и «болонка» были дочерним узлами для семантического класса «собака», которые было дочерним для «млекопитающего», которое было дочерним для «животного»… А «круассан», скажем, восходил к семантическому классу «пища».
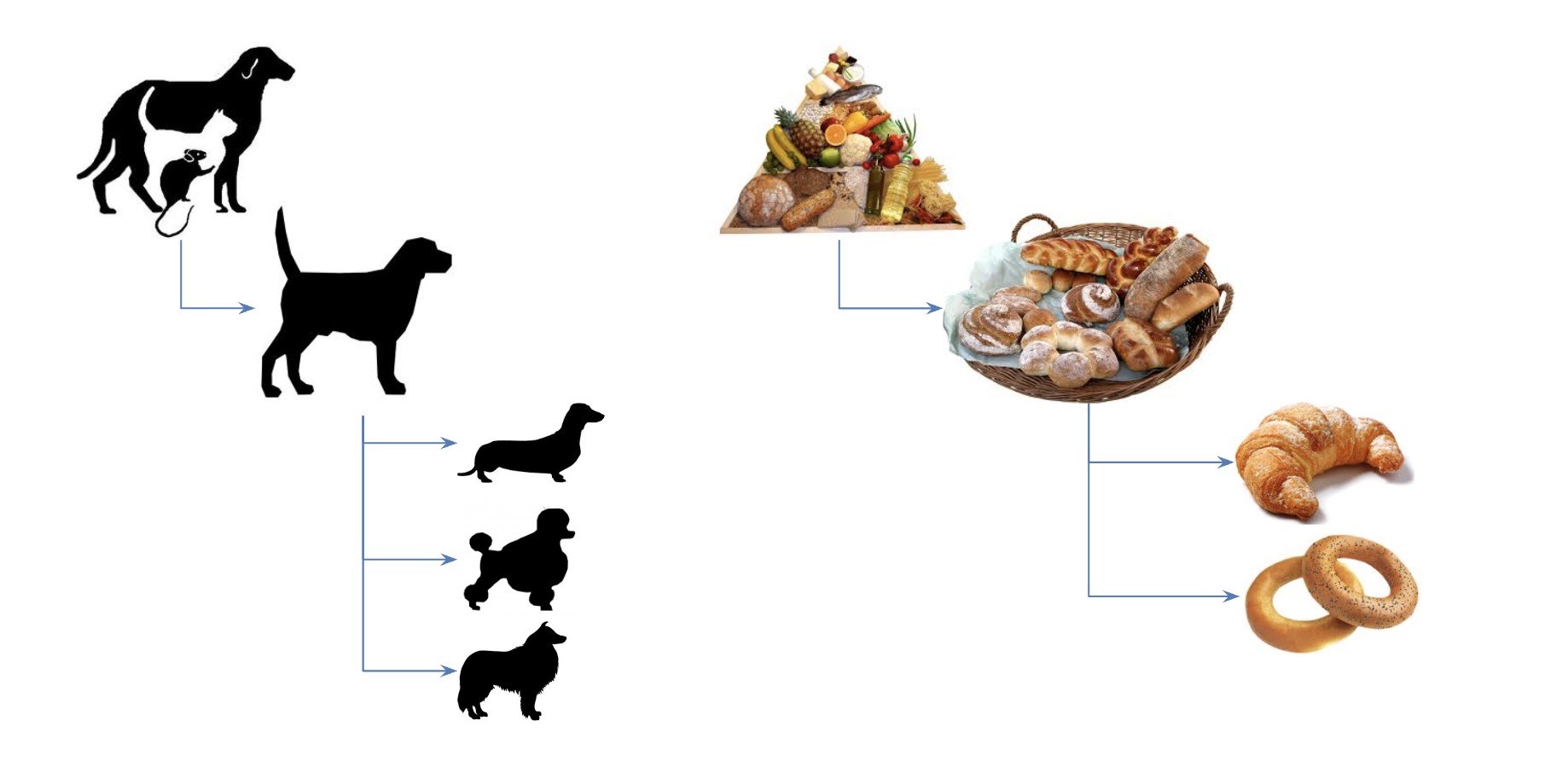
Схематическое устройство семантических классов в универсальной семантической иерархии; слева — поддерево для собак, справа — для выпечки
Элементами этого дерева были семантические классы, к которым уже крепились слова конкретных языков с прописанными на формальном уровне морфологическими, синтаксическими и семантическими свойствами. Если у слова было много значений — оно относилось к множеству классов, т.е. единичными элементами были не слова, а именно значения (семантические классы). Например, у слова собака в русском языке есть ругательное значение (нехороший человек) — и оно находилось в совсем другой части семантической иерархии ABBYY. Ниже вы увидите, как это выглядело внутри системы работы с семантической иерархией.
Собака 1 (животное) в семантической иерархии (слева — универсальное дерево семантических классов, посередние его проекция в русский язык, справа — проекция в английский):

Собака 2 (нехороший человек) в семантической иерархии (слева — универсальное дерево семантических классов, посередние его проекция в русский язык, справа — проекция в английский):

Видно, что в случае со вторым значением слова собака в английском языке к нему уже не привязано слово dog — вместо этого там находятся слова английского языка, передающие именно человеческое значение такого оскорбления. Таким образом, при верном определении нужного значения слова «собака» в русском языке, перевод на английский через семантическую иерархию должен был справиться и с таким его непрямым использованием.
На базе этого описания строился так называемый Natural language compiler (NLC) — компилятор естественного языка. В программировании компилятором называется программа, превращающая код на языке программирования — в команды для компьютерного железа. Разработка компиляторов — сложная область IT, специалистов в которой гораздо меньше, чем обычных программистов. Амбиция ABBYY была в том, чтобы сделать компилятор для обычных человеческих языков в формальную структуру на базе семантической иерархии. При этом в отличие от языков программирования, которые устроены формально и однозначно и имеют конечное множество команд, естественный язык — явление почти безграничное, он устроен внутренне противоречиво, не всегда логично и постоянно изменяется. Это была Амбиция с большой буквы А. Замах на строительство Вавилонской башни в цифре. Позже эту Вавилонскую башню в маркетинговых целях назовут ABBYY Compreno (в эспертанто kompreno — «понимание», латинский глагол comprendere «понимать» присутствует в разных видах в большинстве романских языков).
«Мы пойдем другим путем»: начало горького урока
Начинаются 2000-е годы, в России и в мире происходит экономический рост, растет и компания ABBYY. Из студенческого стартапа она превратилась в IT-фирму с мировым именем. Компания расширяется и переезжает из одного помещения в другое, чтобы вместить растущий штат. Главный офис ABBYY в Москве начинает подражать офисам калифорнийских IT-гигантов (на минималках, конечно: пингвинов и бесплатной еды в офисе не было, но были черепашки, playstation, два с половиной спортзала и гамаки, а также стильно оформленные тематические переговорки).

Один из холлов в офисе ABBYY в московском районе Отрадное, выполненный в морской тематике; в гамаках действительно можно было неплохо поспать, автор проверял это на себе; а за аквариумом как раз находился центр обучения лингвистов работе с семантической иерархией
Вместе с программистами и спецами по машинному обучению, державшими на своих плечах доходные продукты вроде FineReader и FlexiCapture (это такая умная настраиваемая распознавалка платёжек для банков), в этом уютном офисе работают десятки, а на пике и сотни лингвистов. Все они занимаются формальным описанием языка внутри семантической иерархии ABBYY NLC / Compreno.
Сама иерархия — только вершина айсберга, внутри нее находятся сложные модели описания синтаксиса, семантических ограничений. Я не готов (да и не способен) описывать эту систему более детально, но для осознания уровня сложности системы предлагаю просто посмотреть на формальный разбор одного английского предложения в модели ABBYY NLC / Compreno:
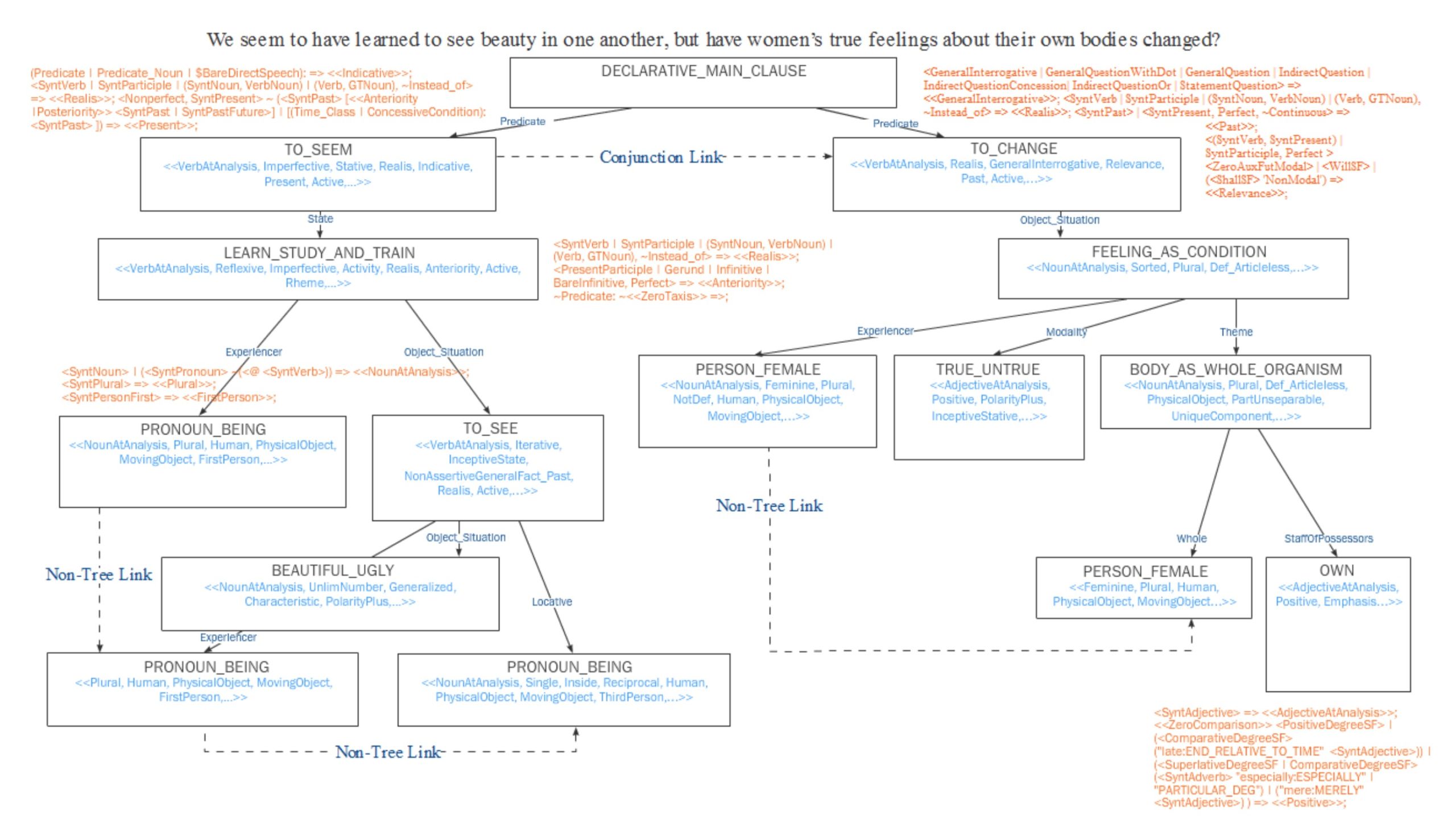
Впечатляет, не правда ли?
Конечно, у этой сложности была цена. И она исчислялась миллионами долларов. Описание языка в такой сложной и подробной модели требовало буквально человеко-столетий. Создание работающего переводчика на базе модели постоянно откладывалось. Между тем мир автоматической обработки языка шел совсем в другую сторону.
Приход статистики в перевод и «необъяснимая эффективность данных»
В 2006 году, когда в ABBYY все еще продолжали строительство своей «Вавилонской башни» с формальным универсальным описанием языка, Google выпустил самую первую модель переводчика Google Translate. Тогда он работал очень плохо и порождал кучу мемов в стиле «охладите траханье», но гораздо важнее, что при создании практически не понадобились лингвисты. Гугл-переводчик был построен на принципиально ином подходе — статистическом. В нем не было никакой явно описанной языковой модели — он просто видел огромное количество примеров.
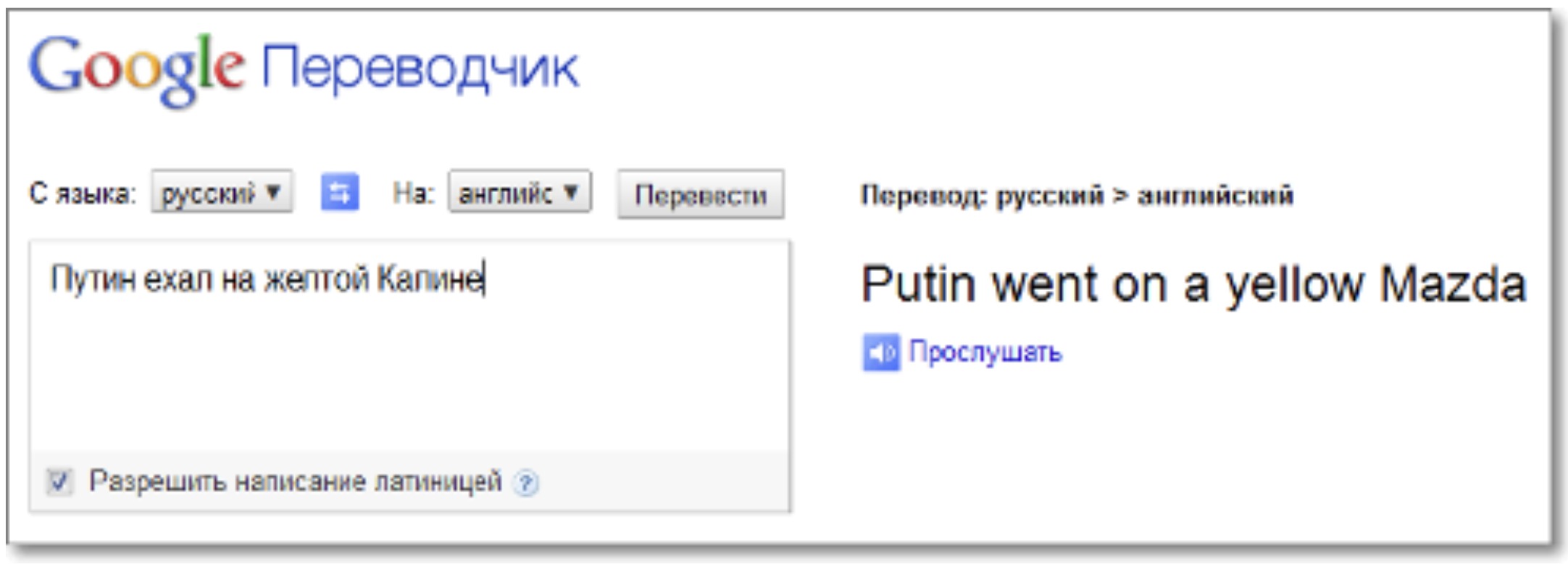
Гугл-переводчик в 2010 году
Статистический машинный перевод начали разрабатывать в 1980-е, а в начале 1990-х IBM представила работающие алгоритмы перевода, обучающиеся на примерах (IBM Model 1-2-3-4-5). Однако понадобилось еще полтора десятилетия, прежде чем люди накопили достаточно данных в цифровой форме и появилось достаточно вычислительных ресурсов, чтобы обучить такие системы.
Появление Google Translate довольно быстро сломало игру. Какие бы проблемы ни возникали там в начале, у системы было главное преимущество — масштабируемость. Вам не нужны были сотни лингвистов на зарплате, чтобы по крупицам описывать правила перевода из одного языка в другой — достаточно было докинуть еще больше примеров перевода. А таких примеров становилось все больше: любые оцифрованные переводы книг, заседания многоязычных парламентов с параллельными транскриптами на разных языках… да хоть многоязычные этикетки от дезодоранта, где написано одно и то же на английском, болгарском и казахском. Все это идет в ход для статистического машинного переводчика. Данные копились как снежный ком. Обогнать статистику в машинном переводе было уже невозможно, даже если бы ABBYY наняла для описания языков всех лингвистов России.
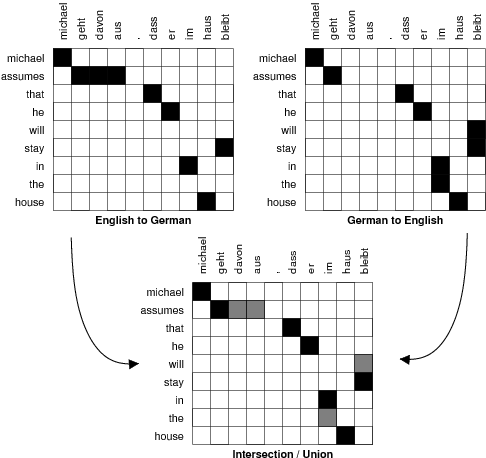
Демонстрация работы алгоритма статистического машинного перевода. Сверху две таблицы соответствия слов: англо-немецкая и немецко-английская. Черные ячейки в обеих верхних таблицах — выявленные на основе статистики параллельных корпусов самые вероятные варианты перевода слова с одного языка на другой
В 2009 году исследователи из Google отрефлексировали успех этих data-driven подходов к задачам обработки естественного языка в статье The Unreasonable Effectiveness of Data, что можно перевести как «Необъяснимая эффективность данных». В этой статье советовали при любой возможности опираться не на рукописное моделирование, а на подходы, в которых можно использовать много данных:
«Так что следуйте за данными. Выбирайте такие представления, которые могут использовать обучение без учителя на неразмеченных данных, ведь таких данных гораздо больше, чем размеченных».
The Unreasonable Effectiveness of Data
«Для многих задач слова и последовательности слов — это все, что нам нужно чтобы обучаться на текстах».
The Unreasonable Effectiveness of Data
Можно заметить, что дальнейшее развитие прикладного NLP и в частности взлет больших языковых моделей (LLM) происходил в точном соответствии с этими заветами из 2009 года. Языковые модели пользуются именно возможностью предобучаться на гигантских массивах неразмеченных данных, решая задачу предсказания следующего слова.
Попытка смены стратегии в ABBYY
К началу 2010-х ABBYY оказалась в ситуации, когда затраты на разработку Compreno достигли 80 миллионов долларов, а рынок, на который она должна была выходить, был захвачен статистическими переводчиками. При этом нельзя сказать, что система не получилась: она работала и временами впечатляла филигранностью перевода, обеспеченного тонким и точным описанием отдельных фрагментов языка. В интернете до сих пор можно откопать свидетельства того, как Compreno с элементами черри-пикинга примеров поражала отдельных журналистов. А главное, Compreno стала любимым детищем огромного количества людей, вложивших туда свой труд и свой интеллект. Закрывать этот проект в компании никто не хотел. Но никаких шансов тягаться с Google Translate у ABBYY не было.
В компании решили сделать то, что на современном корпоративном языке называется pivot. С перевода ABBYY переключилась на задачи информационного поиска (не в интернете, а в корпоративных архивах) и извлечения информации из текста. Руководство компании решило, что такой продвинутый лингвистический процессор, каким к тому моменту стала ABBYY NLC / Compreno, позволит обогнать конкурентов в этих областях, где с обучающими данными все не так сладко.
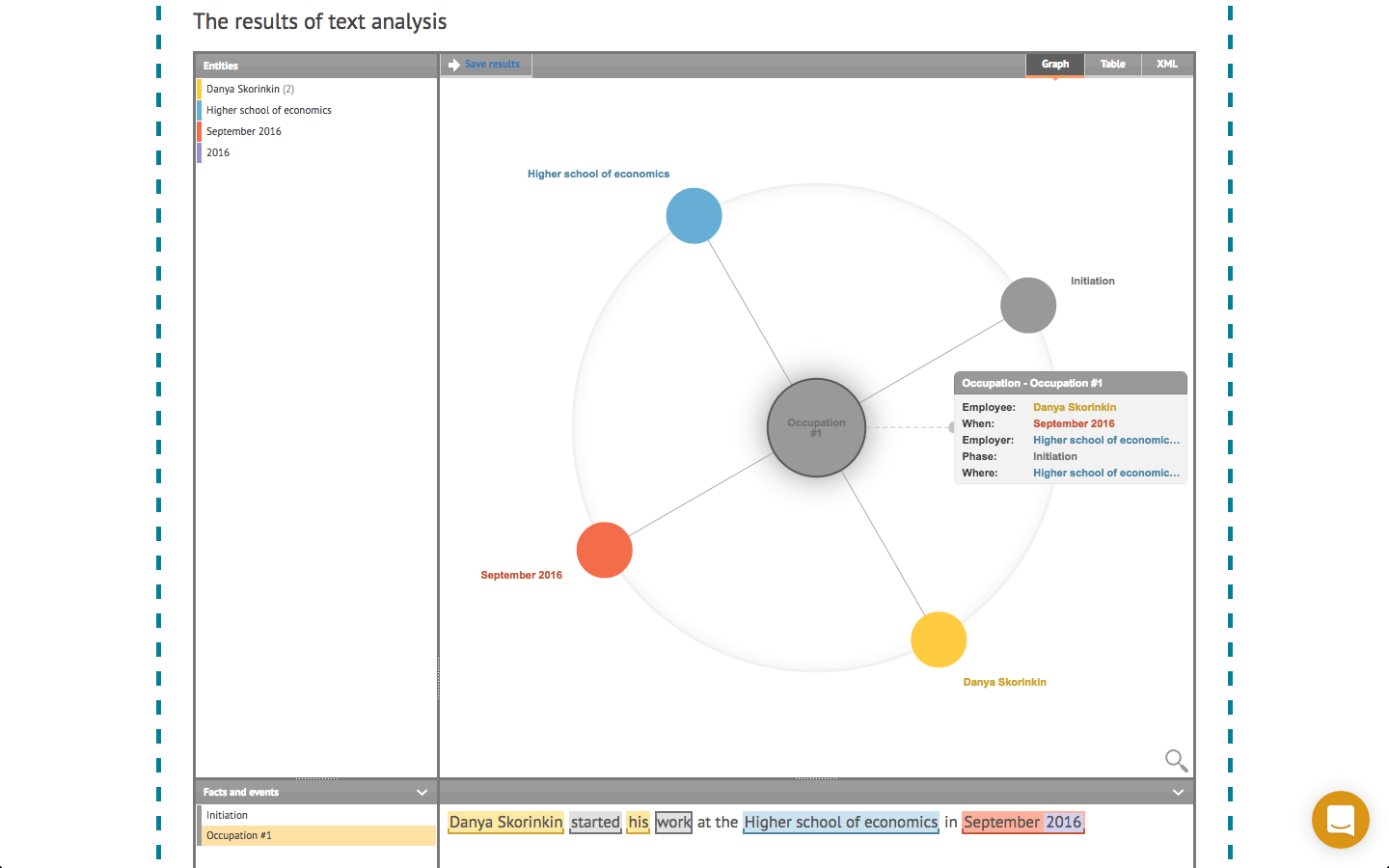
Представление информации, извлеченной из текста при помощи ABBYY Compreno, в виде семантического графа
Эти попытки продолжались в течение 2010-х, и здесь я уже был личным свидетелем и соучастником происходившего. К нам приходили заказчики, которым надо было, например, извлекать данные об участниках сделки из сканов документов, в которых текст был написан на своеобразном «юридическом диалекте» американского английского языка. Когда этот текст (с ошибками распознавания, лишними точками из-за хлебных крошек на скане и другими артефактами) прилетал в утонченный анализатор NLC / Compreno, на выходе получалось чаще всего абсолютно непредсказуемая каша с кучей сообщений об ошибках в разборе… Разнообразие синтактико-семантических структур было едва ли не больше, чем (сравнительно более предсказуемое) разнообразие простых цепочек слов исходного текста. С какого-то момента я понял, что большую часть времени занимаюсь войной с выдачей Compreno при помощи регулярных выражений и прочих костылей, и задумался, что надо уходить из ABBYY. Я окончательно уволился зимой 2017 года.
Уже после ухода из компании я однажды привел студентов компьютерной лингвистики Вышки на экскурсию в ABBYY. Хорошо помню, как мы поднялись на большой офисный балкон, с которого открывался вид на весь север Москвы. Один из студентов, Паша, пошутил, что сюда сотрудники ABBYY поднимаются в грозу и кричат «Я делаю правиловый парсер в 2018 году», после чего в них бьет молния. Это была жестокая шутка, но она била в цель.

Фото с той самой экскурсии 2018 года. Автор этого поста рассказывает о Compreno
Удивительно, но попытки использовать Compreno не прекращались в компании ABBYY до самого конца её существования. Даже когда в 2017-2018 началось победное шествие нейросетей на трансформерной архитектуре, давшее старт сегодняшнему торжеству больших языковых моделей, в ABBYY продолжали цепляться за этот «чемодан без ручки», пытаясь соединить рукописную языковую модель Compreno и нейросетевые подходы. И вероятно, продолжали бы и дальше, если бы не 2022 год.
Стресс-тест 2022 и время сбрасывать балласт
До 2022 года ABBYY жила в выгодном положении компании, основная часть прибыли которой поступает в валюте с американского, европейского и азиатского рынков, а основная часть расходов идет в рублях на разработчиков в московском офисе. В такой ситуации можно было позволить себе тратить деньги на поддержание Compreno (хотя лингвистов постепенно сокращали и разработку собственно лингвистической модели постепенно заморозили), а также спонсировать разные образовательные и научные активности в России, например, конференцию «Диалог».

Руководитель лингвистических исследований в ABBYY Владимир Селегей открывает конференцию «Диалог» в 2019 году. Фото организаторов
Однако весной 2022 года все изменилось. Чтобы сохранить зарубежных клиентов, компания выехала из России и вывезла часть сотрудников в офисы на Кипре, в Сербии и в Венгрии. Это стало серьезным испытанием для ABBYY, которая была во многом «домашней» компанией: уютный московский офис, корпоративная культура с походами, настолками, праздниками, совместными экскурсиями и милыми сувенирами… Экстренный переезд для такой компании — огромный стресс, потеря людей и, конечно, взлет издержек.
ABBYY и раньше пыталась прикидываться не-российской компанией, чтобы не нервировать западных заказчиков: переводила формальную штаб-квартиру в США, вводила в совет директоров людей с западными именами и происхождением, разбавляя прежний кружок физтехов-основателей. Большинство моих зарубежных друзей и до 2022 очень удивлялись, когда узнавали, что FineReader делают в России… А еще ABBYY удавалось сохранять офисы одновременно в Москве и в Киеве. Но после 2022 пришлось рвать связи не понарошку, а по-настоящему, одновременно теряя рынки и ужимаясь в расходах.

Одно из мероприятий ABBYY в Сербии уже после переезда. Фото из LinkedIn компании ABBYY
Я не могу спекулировать о том, что происходило в руководстве компании внутри, знаю только, что к весне 2024 года компанию покинул её многолетний CTO (технический директор) и миноритарный акционер Константин Анисимович (тоже физтех), к лету в официальном списке членов совета директоров не осталось выходцев из России, а осенью была уволена вся остававшаяся русская разработка и R&D. В октябре 2024 от компании осталась лишь «скорлупка» из западных топ-менеджеров и небольшого количества менеджеров по продажам / работе с клиентами в региональных офисах. The rest is history, и вы можете почитать эту history в новостях. Никакой собственной IT-начинки в ABBYY сейчас не осталось, хотя продукты компании продолжают работать и продаваться.
Приход ChatGPT и угроза основному бизнесу
Одна из гипотез, которую высказывали многие бывшие сотрудники ABBYY, — что компания так резко избавилась от сотрудников, почувствовав угрозу основному бизнесу. Как я уже писал, лингвистические, образовательные и прочие эксперименты ABBYY оплачивались в основном заработками систем распознавания, которые продавались корпоративным и государственным клиентам. Долгое время компания ехала на том, что банкам нужно распознавать миллионы платежек, а ABBYY FlexiCapture был лучшим решением на рынке.
Но времена изменились. Усиливающийся ветер «необъяснимой эффективности данных» привел к LLM-революции во всех задачах интеллектуальной обработки данных. Не миновала эта революция и область распознавания. Как отмечал один из бывших сотрудников ABBYY, сегодня с помощью ChatGPT можно делать такое же распознавание платёжек, какое умеет FlexiCapture, тратя на настройку системы сутки вместо трех месяцев.
Угроза основному источнику дохода для компании, которая только недавно перевезла свою довольно большую разработку (несколько сотен программистов) в недешевые европейские офисы на валютные зарплаты, а перед этим потратила львиную долю внутренних ресурсов на десятилетия строительства утопической «Вавилонской башни» Compreno… Все это выглядело как идеальный шторм, в котором компания имела мало шансов уцелеть.
Пока трудно сказать, утонула ABBYY с концами или совершила pivot из IT-линкора в небольшую субмарину-батискаф, на которой хватит место лишь менеджменту и продажникам, которые будут поставлять LLM-решения других компаний под вывеской ABBYY и в привычных клиентам ABBYY интерфейсах. Но совершенно очевидно, что прежней компании, в которую я мечтал попасть в 2012 году, поступая на компьютерную лингвистику, больше нет. И кажется, что из её истории надо извлечь уроки.
Чему нас может научить история ABBYY
В 2019 году была написана еще одна статья, в чем-то похожая на упомянутую выше Unreasonable Effectiveness of Data, но сформулированная еще более категорично. Текст был написан одним из пионеров обучения с подкреплением Ричардом Саттоном и назывался The Bitter Lesson («Горький урок»). Статья начинается такими словами:
Главный урок из 70 лет исследований ИИ — это то, что самые общие методы, опирающиеся на масштабирование вычислений, намного эффективнее всех остальных.
The Bitter Lesson
Основная идея текста: каждый раз, когда в области искусственного интеллекта кто-то пытается решить задачу через сложные рукописные модели, которые пытаются формально описать некую область знаний, это приводит в тупик. На коротком промежутке такая модель может помочь, но ценой будет невозможность масштабирования. За кратковременным улучшением последует стагнация, деградация и в конечном итоге смерть системы. В некотором смысле формальное моделирование становится своего рода костылём в системе. А любая правиловая система таким образом — системой, целиком едущей на костылях. Вот моя любимая цитата из статьи Саттона, которая формулирует суть горького урока:
Мы всё ещё не усвоили этот урок полностью, так как продолжаем допускать те же ошибки. Чтобы это понять и эффективно им противостоять, нужно осознать, в чем соблазн этих ошибок. Мы должны усвоить горький урок: встраивание в ИИ того, как, по нашему мнению, устроено наше мышление, не работает в долгосрочной перспективе. Горький урок заключается в том, что: 1) исследователи ИИ часто пытаются встроить знания в свои системы, 2) это помогает в краткосрочной перспективе и приносит удовлетворение, но 3) со временем этот подход приводит к застою, а 4) прорывы происходят благодаря другому методу — масштабированию вычислений через обучение и поиск. Этот успех вызывает горечь, потому что он идет вразрез с более приятным человеко-центричным подходом.
The Bitter Lesson
Все это применимо к ABBYY на 100 процентов. Компания очень хотела сделать всё «по науке», т.е. в соответствии с теми теориями, которые придумали лингвисты XX века, чтобы как-то систематизировать описание естественного языка. Но в значительной степени эти теории нужны для того, чтобы представить язык как логично устроенную систему, понятную человеку и как бы объяснённую человеком. То есть они нужны как объяснительные модели для самого человека. Горький урок состоит в том, что для создания функциональной модели языка и языковых компетенций на компьютере всё это оказалось не только ненужным, но и даже прямо вредным.

То же самое в формате мема, справа тот самый Ричард Саттон
Мне кажется важным зафиксировать этот горький урок. В русской академической культуре как-то не принято обсуждать ошибки, заблуждения и ложные прогнозы — и это, на мой взгляд, приводит к повторному хождению по граблям. Несбывшиеся прогнозы как-то незаметно заметаются под ковер. Но я помню многочисленные выступления деятелей компьютерной лингвистики в начале 2010-х годов на конференциях — и там было принято расшаркиваться в том духе, что «без лингвистической информации, конечно же, полноценного автоматического понимания языка не построить». Можно, конечно, и сейчас устроить философский спор о том, что вообще такое понимание языка, является ли ChatGPT всего лишь «китайской комнатой», «стохастическим попугаем» и т.п. Однако мне кажется бесспорным, что на практическом или инженерном уровне эта мантра о необходимости лингвистики сильно навредила развитию NLP в России.
Лингвистика много дала компьютерщикам на начальном этапе. Едва ли можно было в 1990-е сделать морфологический анализатор, не опираясь прямо или косвенно на грамматический словарь Зализняка. Но давайте зафиксируем: сегодня для практических задач функциональной эмуляции естественного языка и задач, решаемых на компьютере при помощи естественного языка, ЛИНГВИСТИКА НЕ НУЖНА и ЛИНГВИСТЫ ТОЖЕ НЕ НУЖНЫ. Могут быть полезны, но могут и навредить (неумышленно, разумеется). И точно не необходимы.
* Слезает с табуретки *
P.S. В защиту компании ABBYY (что-то вроде запоздалого признания в любви)
Выше я много критиковал компанию ABBYY — и теперь хочу сказать пару слов в её защиту. Во-первых, моя критика, конечно, относится и ко мне самому. Я тоже был частью ABBYY, пусть и маленькой и ничего не решающей. Когда я пришел в компьютерную лингвистику, я тоже верил в то, что лингвистическая теория имеет не меньшее значение для NLP, чем данные и алгоритмы их обработки. Мне тоже потребовалось время, чтобы усвоить горький урок.
Во-вторых, ABBYY была больше чем просто компанией. Те самые энтузиазм и вера в науку, которые заставили её сжечь сотню миллионов долларов на попытку реабилитировать лингвистику в деле автоматической обработки языка, очень много дали российской науке и образованию. Еще в 90-х, когда прокормиться академической наукой мог далеко не каждый, ABBYY начала создавать рабочие места для лингвистов, на которых те могли работать за достойную зарплату и, что более важно, сохранять свои научные компетенции. Сегодня многие сотрудники ABBYY тех времен снова работают в науке — и думаю, есть большая заслуга компании в том, что они не ушли из науки челноками или копирайтерами.
Компания ABBYY открывала кафедры на Физтехе и в РГГУ, вводя в компьютерную лингвистику, в сферу NLP и в OCR новые поколения талантливых студентов, которые сегодня выросли и работают во всех топах российского IT и в куче международных компаний. Компания ABBYY занималась оцифровкой наследия Льва Толстого и архива Большого театра. Компания ABBYY организовывала и проводила конференцию «Диалог» — главный форум компьютерных лингвистов в России.

Конференция Диалог в 2018 году, организованная ABBYY в РГГУ. Фото организаторов.
Наконец, компания ABBYY очень долго была заповедником прекрасных людей. Дружеские связи, завязанные внутри ABBYY, исчисляются десятками тысяч и наверняка переживут саму компанию. В частности, без ABBYY не было бы издания «Системный Блокъ», в котором вы читаете этот текст — ведь сооснователи издания познакомились именно там, да и нашу IT-инфраструктуру поддерживают выходцы из ABBYY.

Рекреационный уголок в офисе ABBYY, куда сооснователи «Системного Блока» вечерами ходили подтягиваться и раскрашивать стену
Можно точно сказать, что без ABBYY мир был бы тусклее. И за это компании ABBYY нужно сказать спасибо. Это было хорошо, пока не кончилось.
Автор: Даниил Скоринкин
Теги:NLP, OCR, искусственный интеллект, машинное обучение, машинный перевод