Molmo: семейство открытых мультимодальных моделей обходит Claude 3.5 и Gemini 1.5 тестах
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2024-09-29 11:36


Molmo — семейство мультимодальных моделей Vision-Language (VLM), разработанных исследователями из Allen Institute for AI и Университета Вашингтона. Семейство моделей Molmo превосходит многие проприетарные и открытые state-of-the-art модели по результатам академических тестов и человеческих предпочтений.
Исследователи выпустили четыре модели:
- MolmoE-1B, основанная на OLMoE-1B-7B mixture-of-experts LLM
- Molmo-7B-O, использующая полностью открытую OLMo-7B-1024 LLM.5
- Molmo-7B-D, работающая на основе Qwen2 7B
- Molmo-72B, самая мощная модель, использующая открытую версию Qwen2 72B LLM
Код и веса этих моделей доступны на Huggingface. Для доступа к датасету необходимо подать запрос через эту форму.
Исследование показывает, что модели с открытым кодом могут достигать state-of-the-art производительности в мультимодальных задачах, без использования проприетарных систем или синтетических данных. Molmo решает ключевые задачи, связанные с качеством данных и производительностью.
Основные характеристики Molmo
- MolmoE-1B почти соответствует GPT-4V на академических тестах и на основе предпочтений реальных пользователей;
- Модели Molmo-7B показывают результаты между GPT-4V и GPT-4o;
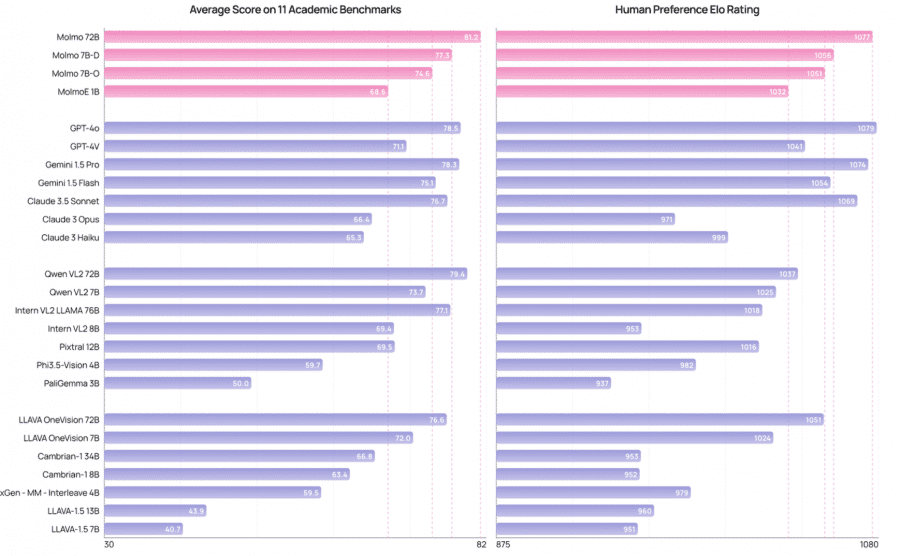
- Флагманская модель Molmo-72B достигла наивысшего результата (81.2% в среднем) и заняла второе место по предпочтениям пользователей, уступив только GPT-4o;
- Модели Molmo превосходят проприетарные системы, такие как 1.5 Pro, Gemini 1.5 Flash и .
Архитектура модели
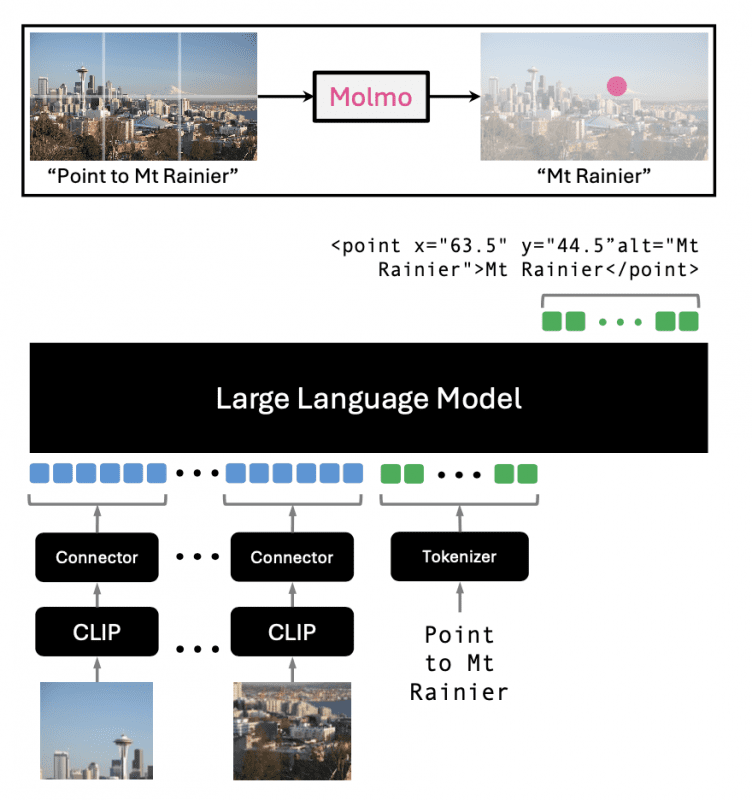
Molmo использует стандартную архитектуру с предобработчиком для мульти-скейловой обработки изображений, ViT image encoder (ViT-L/14 336px CLIP), коннектор MLP для репрезентации изображений и текста, а также decoder-only трансформер.
Датасет PixMo-Cap
Гордость создателей Molmo — набор данных PixMo-Cap, содержащий 712,000 изображений и 1,3 миллиона описаний, собранных на основе описаний реальных людей, синтетические данные не использовались. Этот набор данных позволил значительно улучшить качество генерации текстовых описаний к изображениям. К нему уже можно запросить доступ в Google Forms.
Результаты
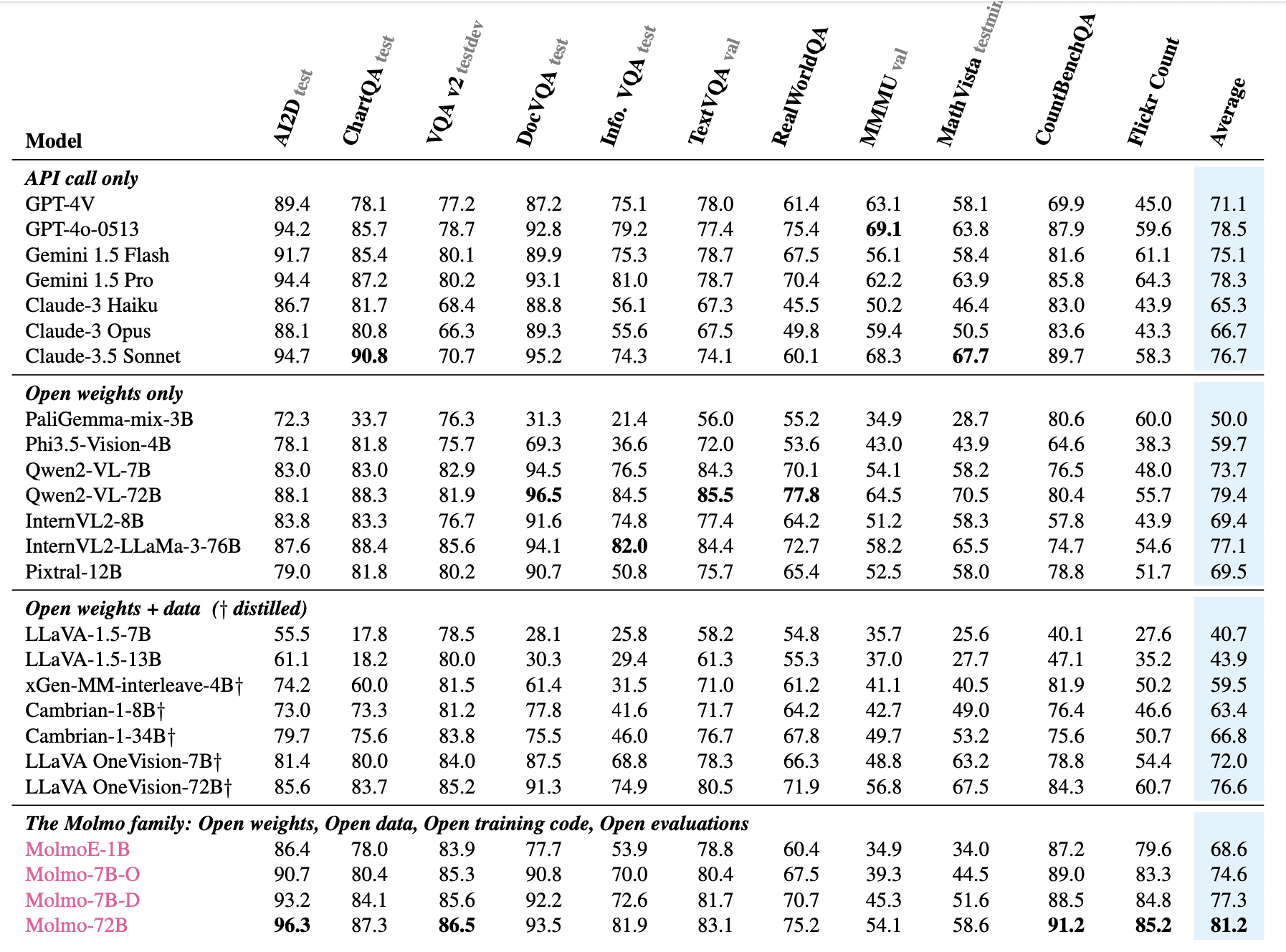
В ходе всестороннего исследования Molmo протестировали на 11 академических бенчмарках и 15,000 парах изображений-текст, модель получила более 325,000 оценок от 870 пользователей. Семейство моделей Molmo показало выдающиеся результаты как по академическим тестам, так и по субъективным предпочтениям пользователей. Например, модель MolmoE-1B почти достигла результатов GPT-4V на академических бенчмарках и по оценкам человеческих предпочтений. Модели Molmo-7B также показали хорошие результаты — между GPT-4V и GPT-4o. Флагманская модель Molmo-72 набрала 81.2% по 11 академическим бенчмаркам и заняла второе место по человеческим предпочтениям, уступив только GPT-4o.
AI-агенты
Molmo не ограничивается только традиционными задачами в области визуальных данных и текста, открывая новые возможности для применения в автономных AI-агентах. Возможность распознавания текста на изображениях с помощью 2D-точек открывает перспективы для использования Molmo в робототехнике и управлении виртуальными агентами. Это может позволить системам на базе Molmo управлять роботами в реальном мире или виртуальных средах, выполняя команды пользователя, такие как «перейти к двери» или «поднять красную чашку».
Как использовать Molmo
Команда Molmo поддерживает принцип открытой науки, предоставляя доступ к коду и весам моделей. Первая версия модели доступна для тестирования и включает в себя демо-версию, код для инференса и выборочные веса моделей, доступные на официальной странице проекта. Такой подход способствует развитию исследований в области мультимодальных моделей с открытым исходным кодом.
«Molmo доказывает, что можно создать передовые мультимодальные модели, используя только открытые данные и методы обучения,» — отмечают исследователи в своей работе. Использование описаний изображений на основе речи и разнообразных данных для тонкой настройки предлагает новый подход к созданию высококачественных мультимодальных моделей без необходимости использования проприетарных систем или синтетических данных.
Успех Molmo открывает новые горизонты для разработки open-source VLM, что потенциально может революционизировать такие приложения, как понимание изображений, ответы на визуальные вопросы и мультимодальное рассуждение.
Источник: neurohive.io