Куда расти грядущему сверхинтеллекту?
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2024-09-25 12:13

За полтора года, прошедших с момента публикации предыдущей статьи, технология больших языковых моделей (large language models, LLM) на основе трансформеров (generative pretrained transformer, GPT) продвинулась настолько, что все больше ученых и разработчиков начинают полагать, что общий, сильный и даже сверхчеловеческий интеллект (artificial general intelligence, AGI) появится уже в течение нескольких лет. Один из ярких тому примеров — недавняя нашумевшая работа Леопольда Ашенбреннера, выходца из компании OpenAI (разработчика ChatGPT). Название статьи дословно переводится как «Cитуационная осведомленность» — военный термин, очевидно, предполагающий изучение этой книги в военно-политических кругах в первую очередь. Действительно, наряду с утверждением о неизбежном создании сверхинтеллекта в течение ближайших трех лет, автор призывает на уровне руководства США принять незамедлительные меры, направленные на обеспечение тотального доминирования США в «гонке ИИ», с жесткими ограничениями возможностей создания подобной технологии в альтернативных мировых «центрах силы», включая засекречивание всех дальнейших работ в области ИИ в США. Несмотря на сохраняющийся широким разброс мнений в научном сообществе по поводу сроков создания AGI, на стратегическую важность и перспективность технологии AGI как инструмента национального и, в том числе, военного доминирования также указывает прошлогодняя работа одного из основателей Google Эрика Шмидта и бывшего госсекретаря США Генри Киссинджера «Искусственный разум и новая эра человечества». В данной статье анализируется, насколько создание AGI действительно близко, и что еще предстоит сделать для его достижения.
Современные большие языковые модели на основе трансформеров типа ChatGPT позволяют на основе машинного обучения на больших объемах текстовых данных решить ту задачу, которую Алан Тюринг поставил более 50 лет назад, и решить уже «по-честному». Однако если внимательно вглядеться в определение AGI, данное его авторами, то ChatGPT также пока не удовлетворяет требованиям к общему интеллекту. Оптимальные текстовые ответы действительно предлагаются в контексте информации используемого для обучения текстового корпуса и заданного «промпта», причем выдаются за достаточно короткое время, однако ни об обучении поведению в новых условиях, ни об ограниченных вычислительных ресурсах не идет и речи. Обучение осуществляется однократно — требуется более месяца на обучение ChatGPT на высокопроизводительном кластере графических карт, причем на одной карте это заняло бы более трехсот лет. Соответственно, о минимизации энергопотребления также пока говорить нельзя — на сегодняшний день поддержка моделей типа ChatGPT требует энергозатрат, сопоставимых с майнингом криптовалют. Чего еще нам не хватает от LLM/GPT для AGI?
Основным препятствием и ограничением для массового внедрения систем на основе LLM/GPT являются так называемые «галлюцинации», когда в условиях недостатка тренировочных данных в контексте заданного запроса система пытается изобрести нечто правдоподобное с точки зрения грамматики естественного языка и тренировочного корпуса, но не являющееся адекватным по существу. Большие системы имеют меньше галлюцинаций, маленькие системы имеют больше галлюцинаций, но проблему как-то нужно решать во всех вариантах.
Более 50 лет шло соревнование между двумя парадигмами создания ИИ — «нейросетевой» (ассоциативной или коннекционистской) и «символьной» (семантической или логической). Казалось бы, в последние годы LLM/GPT, наконец, явили торжество первого подхода и избавили нас от необходимости использовать семантику и онтологии. Но выясняется, что онтологии, переименованные в «графы знаний», никуда не уходят, они по-прежнему нужны для того, чтобы помочь нейросетям не генерировать неадекватные ответы или хотя бы из множества неадекватных ответов, генерируемых ими, отбирать более или менее правильный ответ. Возникает вопрос, а где эти онтологии взять? Они же должны как-то и кем-то строиться. Если мы хотим приземлять генерации трансформеров и больших языковых моделей на какие-то структурированные звания, мы опять возвращаемся на исходные позиции гонки между двумя подходами, потому что эти структурированные знания откуда-то должны взяться. Сейчас они делаются вручную и качественных полноценных решений автоматизации этого процесса пока ни на рынке, ни в научных публикациях не замечено, хотя работы ведутся, в том числе — на основе использования самих LLM/GPT. И этот вопрос пока не решен, очевидно, что его решение — это один из ближайших рубежей, которые нам предстоит взять в обозримом будущем.
Далее вспомним определение AGI как способность к обучению в условиях меняющейся среды, изменения окружения и исходных данных. К сожалению, большие языковые модели сегодня это делать не умеют, они учатся на ограниченном, пусть даже очень большом, наборе данных, после чего изменить знания, заложенные в систему, очень трудно. Мы можем, естественно, адаптировать генерируемые системой ответы на основе изменения «промпта», но модель при этом статична. Если мы хотим дообучить модель на большом, на новом наборе данных, отражающем новый или расширенный набор задач, нам нужно начинать все сначала (вспомним месяц с лишим обучения на кластере или 300 с лишним лет на одной графической карте).
Наконец, есть еще одна важная проблема, выходящая за рамки определения AGI, но представляющаяся критичной для его практического применения. Если мы хотим доверить системам общего или сильного искусственного интеллекта решение задач, связанных с жизнью, здоровьем и безопасностью большого количества людей, то мы должны иметь так называемый «доверенный» искусственный интеллект. Это подразумевает не только возможность объяснить то или иное решение, принятое ИИ постфактум, как предполагают решения «объяснимого ИИ» («explainable AI»), но и возможность интерпретировать структуру и содержание самой «выученной» ИИ-модели, чтобы на самом деле понять, какими знаниями обладает модель. Мы должны иметь возможность анализировать и верифицировать структуру выученных моделью знаний, и одним из вариантов верифицируемости или анализируемости структуры этих знаний является выражение их в терминах формальной семантики, онтологий или, как это называют сейчас, «графов знаний» — всего того, что называется «символьным ИИ». Мы называем такой интеллект «интерпретируемым ИИ» («interpretable AI»).
Возможно, мы идем к пониманию, как устроен человеческий мозг с точки зрения психологии, согласно нобелевскому лауреату Дэниелу Канеману. В соответствии с его когнитивной моделью, человеческое мышление и поведение зависят от двух систем. Это «система 1» — «ассоциативная», по сути, «нейросетевая», и «система 2» — «логическая», по сути, «символьная». Первая долго обучается, но дает быстрые «интуитивные ответы». Вторая — быстро осваивает новую информацию, дает «логичные» заключения, но не очень быстро их находит, так как надо логически все «продумать». Решения могут находиться как тем, так и другим способом. Точнее говоря — не одним, так другим способом, каким быстрее или надежнее в конкретный момент. Мы можем и в том, и в другом случае осуществлять интуитивное либо логическое предсказание или принятие решений. Но важно то, что «система 2» является интерпретируемой, поскольку оперирует с понятными и логически интерпретируемыми концептами. В свою очередь, «система 1» — не интерпретируема, потому что, несмотря на то, что она может обучаться на больших данных и давать «интуитивные» ответы, требуются дополнительные усилия, чтобы извлечь из нее структурированные знания. Если мы сможем построить такую нейросимвольную архитектуру (например, предложенную автором в 2022 г.), то сможем, с одной стороны, интерпретировать и верифицировать знания, содержащиеся в нейросетевых моделях, извлекая эти знания, а с другой — загружать полученные и проверенные экспертами структурированные знания в нейросетевые модели, наделяя их новыми навыками и способностью принимать решения в предметных областях, ранее им неизвестных, без дорогостоящего обучения на больших объемах данных.
Сверхинтеллект не за горами?
За полтора года, прошедших с момента публикации предыдущей статьи, технология больших языковых моделей (large language models, LLM) на основе трансформеров (generative pretrained transformer, GPT) продвинулась настолько, что все больше ученых и разработчиков начинают полагать, что общий, сильный и даже сверхчеловеческий интеллект (artificial general intelligence, AGI) появится уже в течение нескольких лет. Один из ярких тому примеров — недавняя нашумевшая работа Леопольда Ашенбреннера, выходца из компании OpenAI (разработчика ChatGPT). Название статьи дословно переводится как «Cитуационная осведомленность» — военный термин, очевидно, предполагающий изучение этой книги в военно-политических кругах в первую очередь. Действительно, наряду с утверждением о неизбежном создании сверхинтеллекта в течение ближайших трех лет, автор призывает на уровне руководства США принять незамедлительные меры, направленные на обеспечение тотального доминирования США в «гонке ИИ», с жесткими ограничениями возможностей создания подобной технологии в альтернативных мировых «центрах силы», включая засекречивание всех дальнейших работ в области ИИ в США. Эта работа недавно разбиралась на семинаре русскоязычного сообщества разработчиков AGI (видеозапись мероприятия и его расшифровка). Несмотря на сохраняющийся широким разброс мнений в научном сообществе по поводу сроков создания AGI, на стратегическую важность и перспективность технологии AGI как инструмента национального и, в том числе, военного доминирования также указывает прошлогодняя работа одного из основателей Google Эрика Шмидта и бывшего госсекретаря США Генри Киссинджера «Искусственный разум и новая эра человечества». В данной статье анализируется, насколько создание AGI действительно близко, и что еще предстоит сделать для его достижения.
Начнем в очередной раз с определения общего искусственного интеллекта как «artificial general intelligence» (AGI), данного более 20 лет назад со сходных позиций Беном Герцелем, Шэйном Леггом, Пей Вонгом и Питером Воссом. Согласно определению, общий искусственный интеллект — это способность достигать сложных целей в сложных средах, в условиях ограниченных ресурсов, адаптируясь к изменениям в этих средах и обучаясь новым формам поведения в новых средах. В математических терминах, это может быть переформулировано как способность к решению произвольных задач в условиях многопараметрической оптимизации, где число как входных, так и выходных параметров достаточно велико, все параметры могут меняться произвольно, причем доступность и потребление временного и энергетического ресурсов являются одними из параметров и должны быть минимизированы. Другими словами, система должна сама учиться находить оптимальные решения в любых новых условиях, при множественном выборе альтернативных вариантов за ограниченное время на принятие решения и лимитированном ресурсе на вычислительные затраты. Отвечает ли этим требованиями технология LLM/GPT вроде ChatGPT?

Примерная дорожная карта к AGI согласно обзорному докладу автора.
Алан Тьюринг в свое время определил тест на «разговорный искусственный интеллект человеческого уровня», ныне известный как «Тест Тьюринга», который был 10 лет назад пройден компьютерной программой, созданной русско-украинской командой Владимира Веселова, Сергея Уласеня и Евгения Демченко. Что примечательно, как отмечалось ранее, программа «Евгений Густман», прошедшая тест, не являлась AGI ни с одной из позиций, обозначенных в определении выше, и даже по сути не содержала в себе того, что сейчас называется «машинное обучение», а просто была компьютерной программой, запрограммированной на прохождение данного теста — подробное описание данной технологии было представлено одним из разработчиков на конференции AINL-2014. Бурная дискуссия в научном сообществе, состоявшаяся после этого события, свелась к практически единодушному консенсусу, что «Тест Тьюринга» не может считаться адекватным тестом на искусственный интеллект ровно потому, что он может быть пройден просто «запрограммированным алгоритмом».
Сегодня, спустя 10 лет, мы наконец видим, что «Тест Тьюринга» пройден не формально, по существу. Современные большие языковые модели на основе трансформеров типа ChatGPT позволяют на основе машинного обучения на больших объемах текстовых данных решить ту задачу, которую Алан Тюринг поставил более 50 лет назад, и решить уже «по-честному». Однако если внимательно вглядеться в определение AGI, данное его авторами, то ChatGPT также пока не удовлетворяет требованиям к общему интеллекту. Оптимальные текстовые ответы действительно предлагаются в контексте информации используемого для обучения текстового корпуса и заданного «промпта», причем выдаются за достаточно короткое время, однако ни об обучении поведению в новых условиях, ни об ограниченных вычислительных ресурсах не идет и речи. Обучение осуществляется однократно — требуется более месяца на обучение ChatGPT на высокопроизводительном кластере графических карт, причем на одной карте это заняло бы более трехсот лет. Соответственно, о минимизации энергопотребления также пока говорить нельзя — на сегодняшний день поддержка моделей типа ChatGPT требует энергозатрат, сопоставимых с майнингом криптовалют. Чего еще нам не хватает от LLM/GPT для AGI?
Чем лечатся галлюцинации?
Основным препятствием и ограничением для массового внедрения систем на основе LLM/GPT являются так называемые «галлюцинации», когда в условиях недостатка тренировочных данных в контексте заданного запроса система пытается изобрести нечто правдоподобное с точки зрения грамматики естественного языка и тренировочного корпуса, но не являющееся адекватным по существу. Большие системы имеют меньше галлюцинаций, маленькие системы имеют больше галлюцинаций, но проблему как-то нужно решать во всех вариантах. Различные компании решают их разными способами в той или иной форме, опираясь на так называемые онтологии или семантические сети или «графы знаний».

Борьба с «галлюцинациями» LLM/GPT в компании Палантир.
Компания «Палантир» — лидер на рынке США и, возможно, всего мира в области искусственного интеллекта для задач бизнес-разведки, компьютерной безопасности, и соответствующего ряда военных приложений, столкнулась с проблемой, как только перешли к практическом использованию технологии LLM/GPT. Пришлось искать решение на основе онтологий или «графов знаний» для минимизации нейросетевых «галлюцинаций». Онтологии применяются в «Палантир» на самых разных этапах использования LLM/GPT: при их обучении — внедрением «семантической разметки» в тестовые данные, при уточнении контекста «промпта» внедрением целевых фрагментов «графа знаний» в контекст запроса, а также при фильтрации получаемых ответов на предмет адекватности через «призму» семантических графов, соответствующих предметной области. А создаются эти «графы знаний» ... вручную.
Возникает парадокс. Более 50 лет шло соревнование между двумя парадигмами создания ИИ — «нейросетевой» (ассоциативной или коннекционистской) и «символьной» (семантической или логической). Казалось бы, в последние годы LLM/GPT, наконец, явили торжество первого подхода и избавили нас от необходимости использовать семантику и онтологии. Но выясняется, что онтологии, переименованные в «графы знаний», никуда не уходят, они по-прежнему нужны для того, чтобы помочь нейросетям не генерировать неадекватные ответы или хотя бы из множества неадекватных ответов, генерируемых ими, отбирать более или менее правильный ответ. Возникает вопрос, а где эти онтологии взять? Они же должны как-то и кем-то строиться. Если мы хотим приземлять генерации трансформеров и больших языковых моделей на какие-то структурированные звания, мы опять возвращаемся на исходные позиции гонки между двумя подходами, потому что эти структурированные знания откуда-то должны взяться. Сейчас они делаются вручную и качественных полноценных решений автоматизации этого процесса пока ни на рынке, ни в научных публикациях не замечено, хотя работы ведутся, в том числе — на основе использования самих LLM/GPT. И этот вопрос пока не решен, очевидно, что его решение — это один из ближайших рубежей, которые нам предстоит взять в обозримом будущем.
Решение данного вопроса требует, в частности, разработки автоматизированной технологии сегментации последовательностей на осмысленные «символы» на разных уровнях восприятия — как для текстов и аудиопотоков на естественном языке (символ, морфема, слово, предложение), так и для произвольных последовательностей (в молекулярной биологии, логах событий в системах АСУ ТП и т. д.). В последних работах автора, например, удалось обнаружить тесную связь «осмысленности» словарей русского, английского и китайского языков с минимизацией энтропии и плотностью сжатия информации в корпусах текстов на этих языках, а также построить на основе этого технологию сегментации текстов, не зависящую от конкретной языковой культуры. Предположительно, это может позволить как структурировать тексты на естественном языке, так и выявлять информационно значимые события в других прикладных областях, без применения дорогостоящих вычислений на графических картах, а также создавать исходные наборы символов для дальнейшего построения графов знаний. В другом исследовании продемонстрировано, как, имея соответствующим образом структурированные на уровне слов и пунктуации тексты, можно строить как таксономии понятий, используемые в данном языке, так и базовые грамматические отношения между этими понятиями. Считаем необходимым продолжать работы в этом направлении и развиваем его в рамках нашего проекта «Aigents» с открытым исходным кодом.
Учиться, дообучаться и переобучаться?
Далее вспомним определение AGI как способность к обучению в условиях меняющейся среды, изменения окружения и исходных данных. К сожалению, большие языковые модели сегодня это делать не умеют, они учатся на ограниченном, пусть даже очень большом, наборе данных, после чего изменить знания, заложенные в систему, очень трудно. Мы можем, естественно, адаптировать генерируемые системой ответы на основе изменения «промпта», но модель при этом статична. Если мы хотим дообучить модель на большом, на новом наборе данных, отражающем новый или расширенный набор задач, нам нужно начинать все сначала (вспомним месяц с лишим обучения на кластере или 300 с лишним лет на одной графической карте).
Согласно данным нейрофизиологии, в когнитивной активности человека участвуют как так называемая краткосрочная память (shor-term-memory, STM), так и долгосрочная память (long-term memory, LTM), причем первая содержит текущий «операционный контекст», а вторая — долгосрочный «жизненный опыт». Предполагается, что значимый для поведения текущий опыт, приобретенный в контексте STM, постепенно переносится в LTM. Ничего подобного в архитектурах LLM/GPT не происходит — «операционный контекст», включающий «промпт», затирается в памяти пользовательской сессии по мере превышения лимитированного размера и не переносится в основную модель. Единственное пока движение в данном направлении в мире LLM/GPT — это так называемое обучение с подкреплением на обратной связи от пользователей (reinforcement learning with human feedback, RLHF), когда накопленные по всем пользовательским сессиям логи диалогов используются при очередном цикле обучения модели заново, что занимает от более чем месяца до более чем трехсот лет, как мы уже знаем.
Для полноценного общего или сильного ИИ хотелось бы обеспечить его адаптивность к изменяющимся условиям автоматически. Другими словами, иметь возможность обучения в течение всего жизненного цикла системы «из коробки». Однако большинство решений, которые на сегодняшний день имеются в части обучения с подкреплением (reinforcement learning), в какой-то мере опираются на аналог обратного распространения ошибки, используемый в глубоких нейросетевых моделях. Это различные варианты алгоритмов Q-learning или Deep Q-learning. Обучение при этом очень дорогостоящее и очень медленное. В то же время, в рамках проекта, который выполнялся совместно Сбером и Новосибирским государственным университетом (НГУ), удалось продемонстрировать, как можно строить системы для принятия решений на основе комбинации четырех следующих математических методов. Во-первых, это логико-вероятностный метод, по сути, вероятностный логический вывод на семантических моделях. Во-вторых, это метод вероятностных формальных понятий, который позволяет строить на нечетких данных онтологические системы или системы отношений объектов и отношений между объектами, атрибутами и другими объектами, другими словами — вероятностные семантические модели. В-третьих, это задачный подход, который позволяет то и другое применять к конкретным предметным областям, специфицировав структурировано цели, задачи и операционную среду для данной предметной области. В-четвертых, это теория функциональных систем П. К. Анохина, которая позволяет как живым организмпм адаптироваться к изменению внешней среды на основе теории функциональных систем, так и, согласно математической модели Е. Е. Витяева из НГУ, применять эти принципы для построения систем адаптивного обучения. На основе данной математической концепции была разработана когнитивная архитектура для систем поддержки принятия решений и проработаны ее приложения для ряда прикладных задач.
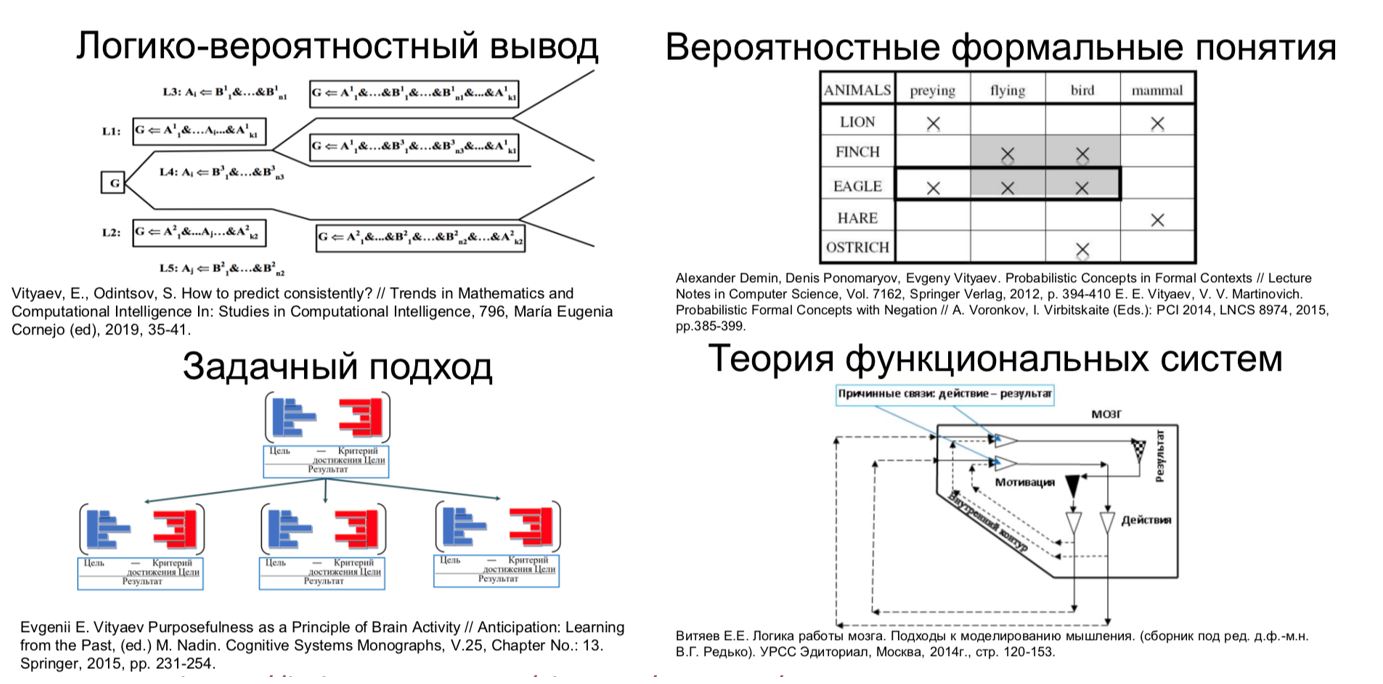
Интерпретируемые математические методы для построения AGI согласно работам Сбера и НГУ.
Лучшее из двух миров — нейросимвольная интеграция!
Наконец, есть еще одна важная проблема, выходящая за рамки определения AGI, но представляющаяся критичной для его практического применения. Если мы хотим доверить системам общего или сильного искусственного интеллекта решение задач, связанных с жизнью, здоровьем и безопасностью большого количества людей, то мы должны иметь так называемый «доверенный» искусственный интеллект. Это подразумевает не только возможность объяснить то или иное решение, принятое ИИ постфактум, как предполагают решения «объяснимого ИИ» («explainable AI»), но и возможность интерпретировать структуру и содержание самой «выученной» ИИ-модели, чтобы на самом деле понять, какими знаниями обладает модель. Мы должны иметь возможность анализировать и верифицировать структуру выученных моделью знаний, и одним из вариантов верифицируемости или анализируемости структуры этих знаний является выражение их в терминах формальной семантики, онтологий или, как это называют сейчас, «графов знаний» — всего того, что называется «символьным ИИ». Мы называем такой интеллект «интерпретируемым ИИ» («interpretable AI»).
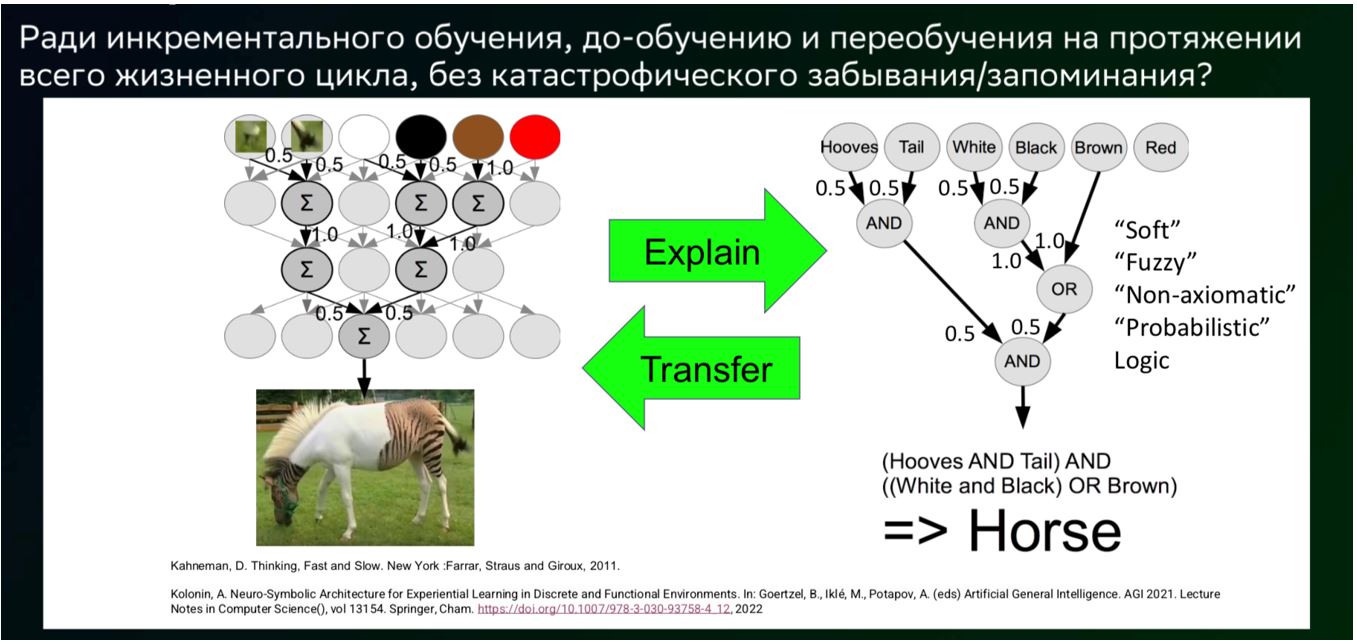
Концепция нейросимвольной интеграции, объединяющая «ассоциативную» (слева) и «логическую» (справа) системы мышления согласно работе автора.
Следует также заметить, что в большом числе практических приложений мы должны иметь возможность применять систему общего искусственного интеллекта в отрыве от вычислительных мощностей, обеспечиваемых кластерами с сотнями тысяч специализированных графических процессоров одной конкретной коммерческой компании. Мы должны уметь решать задачи бизнеса, государства и человека если не на смартфоне конечного пользователя, то хотя бы на корпоративном сервере компании, находящейся в юрисдикции соответствующего государства. Как компании, так и госучреждения и граждане не должны подвергать себя риску остаться без размещенной в «чужом» облаке вычислительной инфраструктуры ввиду изменчивости современной геополитической обстановки. В этом потенциально как раз могут помочь более дешевые и эффективные в вычислительном отношении методы «символьного ИИ», в том числе основанные на вероятностной логике и формальных понятиях, упомянутых выше.
Итак, к чему мы идем? Возможно, мы идем к пониманию, как устроен человеческий мозг с точки зрения психологии, согласно нобелевскому лауреату Дэниелу Канеману. В соответствии с его когнитивной моделью, человеческое мышление и поведение зависят от двух систем. Это «система 1» — «ассоциативная», по сути, «нейросетевая», и «система 2» — «логическая», по сути, «символьная». Первая долго обучается, но дает быстрые «интуитивные ответы». Вторая — быстро осваивает новую информацию, дает «логичные» заключения, но не очень быстро их находит, так как надо логически все «продумать». Решения могут находиться как тем, так и другим способом. Точнее говоря — не одним, так другим способом, каким быстрее или надежнее в конкретный момент. Мы можем и в том, и в другом случае осуществлять интуитивное либо логическое предсказание или принятие решений. Но важно то, что «система 2» является интерпретируемой, поскольку оперирует с понятными и логически интерпретируемыми концептами. В свою очередь, «система 1» — не интерпретируема, потому что, несмотря на то, что она может обучаться на больших данных и давать «интуитивные» ответы, требуются дополнительные усилия, чтобы извлечь из нее структурированные знания. Если мы сможем построить такую нейросимвольную архитектуру (например, предложенную автором в 2022 г.), то сможем, с одной стороны, интерпретировать и верифицировать знания, содержащиеся в нейросетевых моделях, извлекая эти знания, а с другой — загружать полученные и проверенные экспертами структурированные знания в нейросетевые модели, наделяя их новыми навыками и способностью принимать решения в предметных областях, ранее им неизвестных, без дорогостоящего обучения на больших объемах данных.
Возможно, внимательный читатель заметил парадокс — ранее в статье говорилось о дешевизне и эффективности «символьных методов», а потом, со ссылкой на Даниела Канемана, сообщается, что «логическое» мышление, представленное его «системой 2», является более медленным и затратным, чем «ассоциативное». Разрешение парадокса видится в том, что в человеческом мозге «логическое» мышление («система 2») построено на основе механизмов «ассоциативного» («система 1») примерно так же, как современными надстройками над моделями LLM/GPT вроде «цепочек мыслей» пытаются расширить их возможности «рассуждать логически». Применение же «логических цепочек» в чистом виде на основе упомянутых выше «графов знаний» с использованием «вероятностного логического вывода» может оказаться гораздо эффективнее при реализации на современных вычислительных архитектурах, чем это делается на основе естественных и искусственных нейросетей.
Обсуждение широкого круга вопросов, связанных с построением общего или сильного ИИ регулярно проходит на онлайн-семинарах русскоязычного сообщества разработчиков AGI.
Телеграм: t.me/ainewsline
Источник: russiancouncil.ru