Zyda: open source датасет объемом 1.3T для обучения языковых моделей
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2024-06-13 11:27
алгоритмы распознавания речи, распознавание образов, компьютерная лингвистика

Zyda – это открытый датасет объемом 1.3 триллиона токенов от команды Zyphra, предназначенный для обучения больших языковых моделей. Zyda включает в себя данные из open source датасетов, таких как RefinedWeb, Starcoder, C4, Pile, подвергнутые тщательной фильтрации и дедупликации.
Ключевые особенности Zyda
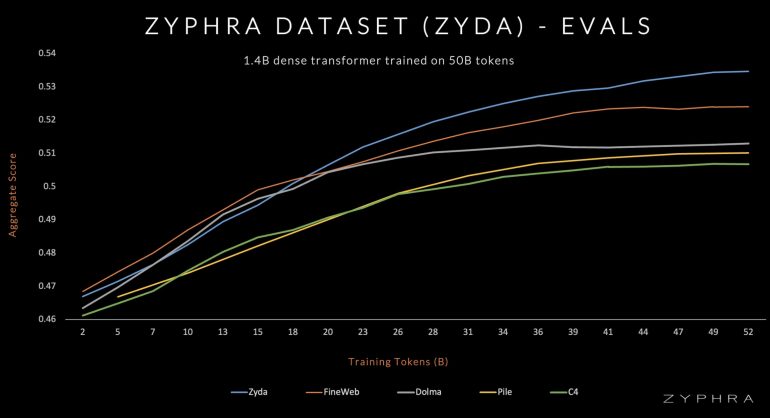
- Высокое качество: Zyda состоит из 1.3T токенов, тщательно отфильтрованных и дедуплицированных, полученных из популярных датасетов.
- Производительность: метрики модели Zamba после обучения на датасете Zyda выше, чем на известных открытых датасетах для языкового моделирования, таких как Dolma, Fineweb и RefinedWeb;
- Дедупликация: Проведена дедупликацая между датасетами, чтобы устранить дубликаты среди компонентов.
- Открытая лицензия: Zyda доступен c открытой лицензией Apache 2.0.
Состав датасета
Zyda был создан путем объединения и тщательной обработки семи популярных датасетов: RefinedWeb, Starcoder, C4, Pile, SlimPajama, pe2so и arxiv. Процесс создания включал синтаксическую фильтрацию для удаления низкокачественных документов, за которой следовала агрессивная дедупликация как внутри, так и между датасетами. Эта междатасетная дедупликация была важна, так как многие документы присутствовали в нескольких датасетах, вероятно, из-за общих источников, таких как Common Crawl. В итоге около 40% исходного датасета было удалено, что уменьшило количество токенов с 2T до 1.3T.
Оценки
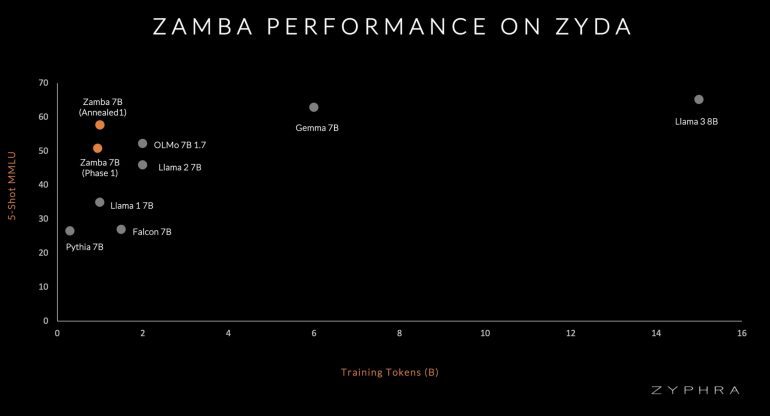
Эффективность Zyda демонстрируется производительностью Zamba — модели, обученной на Zyda, которая значительно превосходит модели, обученные на конкурирующих датасетах со сравнимым количеством токенов. Это подчеркивает эффективность Zyda как датасета для предварительного обучения.
Телеграм: t.me/ainewsline
Источник: neurohive.io