В исследовании проведен анализ связи между когнитивной функцией и функциональным исходом при шизофрении, где использовались ансамблевая обработка данных
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2024-06-16 12:02
алгоритмы машинного обучения, искусственный интеллект в медицине

Было высказано предположение, что связь между когнитивной функцией и функциональным исходом при шизофрении опосредована клиническими симптомами, а функциональный исход оценивается по шкале качества жизни (QLS) и шкале глобальной оценки функционирования (GAF). Чтобы определить результат, оцененный с помощью QLS и GAF, мы создали структуру ансамбля с алгоритмом выбора признаков, полученным на основе анализа таких факторов, как 3 шкалы клинических симптомов и 11 показателей когнитивных функций у 302 пациентов с шизофренией в тайваньской популяции. Мы сравнили нашу структуру ансамбля пакетирования с другими современными алгоритмами, такими как многослойные нейронные сети прямого распространения, машина опорных векторов, линейная регрессия и случайные леса. Анализ показал, что модель ансамбля мешков с выбором признаков показала лучшие результаты среди прогностических моделей при прогнозировании функционального результата QLS с использованием шкалы для оценки негативных симптомов из 20 пунктов (SANS20) и шкалы оценки депрессии Гамильтона из 17 пунктов (HAMD17). Более того, для прогнозирования результата GAF модель ансамбля мешков с выбором признаков показала лучшие результаты среди прогностических моделей с использованием SANS20 и субшкалы положительного и отрицательного синдрома (PANSS-Positive). Исследование показывает, что существует синергетический эффект между негативными (SANS20) и депрессивными (HAMD17) симптомами, а также между негативными и позитивными (PANSS-позитивными) симптомами при влиянии на функциональный исход шизофрении с использованием структуры ансамбля мешков с выбором признаков.
Аналогичный контент просматривают другие
Прогнозирование функциональных исходов шизофрении с помощью генетических биомаркеров с использованием метода машинного обучения с отбором признаков
Статья В открытом доступе 13 мая 2021 г.
Классификация машинного обучения пациентов с шизофренией и здоровых людей из контрольной группы с использованием различных нейроанатомических маркеров и методов ансамбля
Статья В открытом доступе 17 февраля 2022 г.
Прогнозирование когнитивных нарушений у амбулаторных пациентов с эпилепсией с использованием методов машинного обучения
Статья В открытом доступе 08 октября 2021 г.
Введение
Функциональный исход шизофрении, который обычно оценивается с помощью таких инструментов, как шкала качества жизни (QLS) 1 и шкала глобальной оценки функционирования (GAF) 2 , оказывает влияние на психиатрическую диагностику и лечение. У пациентов с шизофренией обычно нарушаются многие функциональные сферы повседневной жизни, включая трудовую деятельность, социальные отношения и независимую жизнь 3 , 4 . Таким образом, крайне важно идентифицировать вероятные факторы, влияющие на функциональный исход шизофрении 5 . Несколько потенциальных предикторов его функционального результата включают негативные симптомы, вербальное обучение, визуальное обучение, рабочую память и социальное познание, и это лишь некоторые из них 3 , 4 , 6 , 7 . GAF признан важным объективным показателем для оценки глобального психологического, социального и профессионального функционирования у пациентов с шизофренией 2 . С другой стороны, QLS также полезен при оценке функционального результата 8 . Таким образом, QLS и GAF использовались вместе для оценки долгосрочного исхода шизофрении 9 . В то время как некоторые исследования показали ограниченный прогностический эффект клинических симптомов, таких как положительные симптомы 5 , 10 , на функциональный исход шизофрении, другие исследования показали, что клинические симптомы, особенно негативные симптомы 11 , 12 , были связаны с функциональным исходом. Более того, было высказано предположение, что многочисленные когнитивные функции, такие как нейро- и социальное познание, также связаны с его функциональными результатами 13 , 14 . С другой стороны, точная психиатрия — это новая междисциплинарная область психиатрии и точной медицины 15 , 16 , где современные алгоритмы искусственного интеллекта и машинного обучения объединяются с различными типами данных, такими как генетические и клинические данные, для облегчения подбора соответствующих индивидуальных данных. -индивидуальные решения на всех этапах ухода за пациентами 17 , 18 , 19 , 20 . Например, различные приложения в точной психиатрии включают прогнозирование пациентов с шизофренией 21 , 22 и прогнозирование результатов лечения антидепрессантами у пациентов с большим депрессивным расстройством 23 , 24 с использованием моделей машинного обучения. Поэтому мы предположили, что модели машинного обучения могут предсказывать потенциальные факторы, влияющие на функциональные исходы шизофрении, используя различные клинические данные (а именно клинические симптомы и когнитивные функции).
В предыдущем исследовании Lin et al. 5 показали, что клинические симптомы опосредуют связь между когнитивными нарушениями и функциональным исходом шизофрении с использованием метода моделирования структурными уравнениями. Здесь мы использовали ту же группу из 302 пациентов с шизофренией и провели первое исследование по прогнозированию функциональных результатов QLS и GAF у пациентов с шизофренией с помощью 3 шкал клинических симптомов и 11 тестов когнитивных функций с использованием подхода машинного обучения с использованием ансамбля мешков 25 . Кроме того, для прогнозирования функциональных результатов мы использовали алгоритм выбора признаков M5 Prime 26, чтобы точно определить небольшое подмножество возможных факторов из 3 шкал клинических симптомов и 11 тестов когнитивных функций. Мы предположили, что наш метод машинного обучения с использованием ансамбля мешков сможет предсказывать исходы, связанные с QLS и GAF, у пациентов с шизофренией, используя небольшое подмножество выбранных шкал клинических симптомов и / или оценок когнитивных функций. Хотя ни в одном из предыдущих исследований не оценивались прогностические модели функционального исхода шизофрении с использованием метода машинного обучения ансамбля мешков с алгоритмом выбора признаков M5 Prime, были исследования, в которых подходы мешков и выбора признаков обычно использовались для прогнозирования функционального результата у отдельных лиц. с психозом 27 , 28 . Подход мешков, который был создан для простой начальной загрузки в 1994 году, часто использовался для экспериментов, в которых использовалась схема повторной выборки. Мы выбрали метод машинного обучения по ансамблю мешков, поскольку этот метод часто применялся для решения сложных задач прогнозирования и классификации из-за его преимуществ в уменьшении дисперсии и переоснащении 25 , 26 . В этом исследовании непосредственно сравнивалась модель машинного обучения ансамбля мешков с широко используемыми алгоритмами машинного обучения, включая многослойные нейронные сети прямого распространения (MFNN), машину опорных векторов (SVM), линейную регрессию и случайные леса. Мы предположили, что наш подход к машинному обучению с использованием алгоритма выбора функций M5 Prime может привести к повышению производительности.
Полученные результаты
Клинические симптомы, когнитивные проявления и функциональные результаты исследуемой когорты
В число участников вошли 302 пациента с шизофренией из тайваньского населения. Показатели исследования, соответствующие их демографическим характеристикам, 3 клиническим симптомам, 11 когнитивным функциям, QLS и GAF, были подробно описаны ранее 5 .
Выбор признаков с использованием шкал клинических симптомов
Мы выполнили серию различных комбинаций функций (Таблица 1 ; наборы функций Feature-A, Feature-B и Feature-C), чтобы спрогнозировать показатели QLS и GAF, используя 3 шкалы клинических симптомов. Обратите внимание, что набор Feature-A включает в себя 3 шкалы клинических симптомов, а именно шкалу оценки депрессии Гамильтона из 17 пунктов (HAMD17), шкалу оценки негативных симптомов из 20 пунктов (SANS20) и подшкалу позитивных и негативных синдромов. (PANSS-положительный).
Таблица 1. Результаты повторных десятикратных экспериментов по перекрестной проверке для прогнозирования функционального исхода QLS и GAF при шизофрении с использованием шкал клинических симптомов с использованием предикторов машинного обучения, таких как модель ансамбля мешков с выбором признаков, модель ансамбля мешков, MFNN, SVM, линейная регрессия и случайные леса.
Для прогнозирования показателя QLS мы использовали алгоритм выбора признаков M5 Prime (см. «Методы»), чтобы идентифицировать 2 признака (включая SANS20 и HAMD17) из 3 шкал клинических симптомов, где эти 2 выбранных признака составляли набор данных Feature-B.
Для прогнозирования оценки GAF мы использовали алгоритм выбора признаков M5 Prime, чтобы найти 2 признака (включая PANSS-положительный и SANS20) из 3 шкал клинических симптомов, где эти 2 выбранных признака составляли набор данных Feature-C.
Прогнозирование QLS и GAF с использованием шкал клинических симптомов
Мы объединили шкалы клинических симптомов (а именно наборы данных Feature-A, Feature-B и Feature-C) для построения прогностических моделей для показателей QLS и GAF, используя структуру ансамбля мешков соответственно. В таблице 1 суммированы результаты повторных десятикратных экспериментов по перекрестной проверке для прогностических моделей с использованием шкал клинических симптомов с помощью модели ансамбля мешков с выбором признаков, модели ансамбля мешков, MFNN, SVM, линейной регрессии и случайных лесов. Кроме того, мы использовали значения среднеквадратической ошибки (RMSE) для измерения производительности прогнозных моделей.
Как указано в таблице 1 , для прогнозирования QLS модель ансамбля мешков с выбором признаков показала лучшие результаты с точки зрения значения RMSE 6,4293 ± 1,1332 с использованием набора данных Feature-B (а именно SANS20 и HAMD17) среди прогностических моделей. Другими словами, комбинация SANS20 и HAMD17 лучше всего предсказывала исход QLS среди всех комбинаций шкал клинических симптомов.
Кроме того, для прогнозирования GAF модель ансамбля мешков с выбором признаков показала лучшие результаты с точки зрения значения RMSE 7,7806 ± 1,1595 с использованием набора данных Feature-C (а именно PANSS-Positive и SANS20) среди прогнозных моделей (таблица 1 ). Другими словами, комбинация PANSS-Positive и SANS20 лучше всего предсказывала GAF среди всех комбинаций шкал клинических симптомов.
Выбор функций с использованием показателей когнитивных функций
Мы выполнили различные комбинации признаков (Таблица 2 ; наборы данных Feature-D, Feature-E и Feature-F) для прогнозирования QLS и GAF при шизофрении с использованием показателей когнитивных функций. Обратите внимание, что набор Feature-D включал 11 оценок когнитивных функций.
Таблица 2. Результаты повторных десятикратных экспериментов по перекрестной проверке для прогнозирования функционального результата QLS и GAF при шизофрении с использованием показателей когнитивных функций с использованием предикторов машинного обучения, таких как модель ансамбля мешков с выбором признаков, модель ансамбля мешков, MFNN, SVM, линейная регрессия и случайные леса.
Для прогнозирования QLS мы использовали алгоритм выбора признаков M5 Prime (см. «Методы»), чтобы идентифицировать 5 признаков (включая беглость категорий, кодирование цифр WAIS-III, вербальную рабочую память, невербальную рабочую память и социальное познание) из 11 когнитивных функций. оценки функций, где эти 5 выбранных объектов составляли набор данных Feature-E.
Для прогнозирования GAF мы использовали алгоритм выбора функций M5 Prime, чтобы найти 5 функций (включая беглость категорий, кодирование цифр WAIS-III, размытую версию d-Prime, вербальную рабочую память, а также рассуждения и решение проблем) из 11 оценки когнитивных функций, где эти 5 выбранных функций составляли набор данных Feature-F.
Прогнозирование QLS и GAF при шизофрении с использованием показателей когнитивных функций
Мы использовали оценки когнитивных функций (а именно наборы данных Feature-D, Feature-E и Feature-F) для построения прогностических моделей для оценок QLS и GAF, используя структуру ансамбля мешков соответственно. В таблице 2 обобщены результаты повторных десятикратных экспериментов по перекрестной проверке для прогностических моделей с использованием оценок когнитивных функций с помощью модели ансамбля мешков с выбором признаков, модели ансамбля мешков, MFNN, SVM, линейной регрессии и случайных лесов.
Как показано в таблице 2 , для прогнозирования QLS модель ансамбля мешков с выбором признаков показала лучшие результаты с точки зрения значения RMSE 7,7717 ± 1,0024 с использованием набора данных Feature-E (включая беглость категорий, кодирование цифровых символов WAIS-III, словесное кодирование символов). рабочая память, невербальная рабочая память и социальное познание) среди прогностических моделей. Другими словами, среди всех комбинаций когнитивных тестов сочетание беглости категорий, кодирования цифр WAIS-III, вербальной рабочей памяти, невербальной рабочей памяти и социального познания лучше всего предсказывало оценку QLS.
Кроме того, для прогнозирования GAF модель ансамбля мешков с выбором признаков показала лучшие результаты с точки зрения значения RMSE 8,6050 ± 1,1101 с использованием набора данных Feature-F (включая беглость категорий, кодирование цифровых символов WAIS-III, d-Prime размытая версия, вербальная рабочая память, рассуждение и решение проблем) среди прогностических моделей (таблица 2 ). Другими словами, среди всех комбинаций когнитивных тестов сочетание беглости категорий, цифрового символьного кодирования WAIS-III, размытой версии d-Prime, вербальной рабочей памяти, а также рассуждений и решения проблем лучше всего предсказывало оценку GAF.
Бенчмаркинг
Путем сравнения результатов (таблицы 1 и 2 ) для прогнозирования QLS пациентов с шизофренией среди алгоритмов прогнозирования машинного обучения (включая модель ансамбля мешков с выбором признаков, модель ансамбля мешков, MFNN, SVM, линейную регрессию и случайные леса) с использованием 4 наборов данных объектов (включая Feature-A, Feature-B, Feature-D и Feature-E), модель ансамбля мешков с выбором функций (с использованием Feature-B) показала лучшие результаты. Наилучшее значение RMSE для прогнозирования QLS составило 6,4293 ± 1,1332 (таблица 1 ). Другими словами, комбинация SANS20 и HAMD17 лучше всего предсказывала показатели QLS среди всех клинических комбинаций и когнитивных комбинаций.
Путем сравнения результатов (таблицы 1 и 2 ) для прогнозирования GAF шизофрении среди алгоритмов прогнозирования машинного обучения (включая модель ансамбля мешков с выбором признаков, модель ансамбля мешков, MFNN, SVM, линейную регрессию и случайные леса) с использованием 4 признаков наборов данных (включая Feature-A, Feature-C, Feature-D и Feature-F), модель ансамбля мешков с выбором функций (с использованием Feature-C) показала лучшие результаты. Наилучшее значение RMSE для прогнозирования GAF составило 7,7806 ± 1,1595 (таблица 1 ). Другими словами, комбинация PANSS-Positive и SANS20 лучше всего предсказала показатель GAF среди всех клинических комбинаций и когнитивных комбинаций.
Здесь мы обнаружили, что модель ансамбля мешков с выбором признаков с использованием выбранных признаков из шкал клинических симптомов лучше всего подходит для прогнозирования результата QLS или GAF по сравнению с другими современными алгоритмами, включая MFNN, SVM, линейную регрессию, и случайные леса. Наш анализ показал, что модель ансамбля мешков с выбором признаков хорошо подходит для моделей прогнозирования функционального исхода шизофрении.
Обсуждение
Насколько нам известно, на сегодняшний день это первое исследование, идентифицирующее синергетические эффекты между SANS20 и HAMD17, а также между PANSS-Positive и SANS20 во влиянии на функциональные результаты при шизофрении среди тайваньских людей с использованием подхода машинного обучения с использованием ансамбля мешков с выбором функций M5 Prime. алгоритм. Более того, мы провели первое исследование с целью прогнозирования потенциальных факторов, влияющих на функциональный исход шизофрении, используя различные клинические данные (то есть клинические симптомы и когнитивные функции). Результаты показали, что модель ансамбля мешков с выбором признаков с использованием двух факторов превосходила другие современные прогностические модели с точки зрения RMSE для прогнозирования исхода QLS при шизофрении, где эти два фактора охватывали SANS20 и HAMD17. Более того, для прогнозирования GAF у пациентов с шизофренией мы обнаружили, что модель ансамбля мешков с выбором признаков с использованием двух факторов превзошла другие современные прогностические модели с точки зрения RMSE, где эти два фактора охватывали PANSS-Positive и SANS20.
Интересно, что наш анализ показал, что комбинация SANS20 (для измерения негативных симптомов) и HAMD17 (для измерения симптомов депрессии) была лучшим предиктором функционального результата QLS при шизофрении среди всех комбинаций клинических симптомов и комбинаций когнитивных функций. Кроме того, комбинация SANS20 (для отрицательных симптомов) и PANSS-положительного (для положительных симптомов) была лучшим предиктором функционального исхода шизофрении по GAF среди всех комбинаций клинических симптомов и комбинаций когнитивных функций. Другими словами, существует синергетический эффект между негативными и депрессивными симптомами, а также между негативными и позитивными симптомами, влияющими на функциональный исход шизофрении. Насколько нам известно, предыдущие исследования не проводились для выявления синергетического преимущества, помимо преимущества любой шкалы клинических симптомов по отдельности. Эффекты взаимодействия клинических симптомов еще предстоит выяснить. Было высказано предположение, что негативные симптомы могут выступать в качестве ключевого предиктора функционального исхода шизофрении 5 , 29 , 30 ; более того, положительные симптомы могут способствовать функциональному результату GAF 5,31 . Кроме того, было высказано предположение, что депрессивные симптомы связаны с показателями QLS 5 , 30 . Принимая во внимание предыдущие результаты 5 , 29 , 30 , 31 , мы предположили, что SAN20 (для измерения негативных симптомов), вероятно, может сочетаться с другими факторами, такими как HAMD17 (для симптомов депрессии) или PANSS-Positive (для позитивных симптомов), чтобы влиять на функциональные исход шизофрении, поскольку все клинические симптомы являются важными предикторами функционального исхода шизофрении.
Используя клинические данные, мы создали прогностические модели функционального исхода шизофрении, используя подход машинного обучения ансамбля мешков с алгоритмом выбора функций M5 Prime. Наш анализ также показывает, что модель ансамбля мешков с выбором признаков может предложить реальное решение для построения прогностических моделей для прогнозирования функционального исхода шизофрении с целенаправленной точностью. Таким образом, подход с использованием ансамбля мешков с выбором признаков в этом исследовании является проверенным инструментом машинного обучения для прогнозирования функционального исхода шизофрении.
Кроме того, в нашем исследовании стоит обсудить алгоритм выбора функций M5 Prime для борьбы с потенциальными факторами, влияющими на функциональный исход шизофрении. Мы заметили, что модель ансамбля мешков с выбранными факторами алгоритма выбора признаков M5 Prime всегда превосходила модель ансамбля мешков без использования выбора признаков. Например, модель ансамбля мешков с набором данных Feature-B превзошла модель ансамбля мешков с Feature-A при прогнозировании QLS. Аналогичным образом, модель ансамбля мешков с набором данных Feature-C превзошла модель ансамбля мешков с набором данных Feature-A при прогнозировании GAF. То есть модели ансамбля мешков с выбором признаков имели тенденцию иметь более низкие значения RMSE. С точки зрения прогнозной эффективности, чем ниже значение RMSE, тем выше производительность. Мы предположили, что это может быть связано с преимуществом алгоритма выбора признаков M5 Prime в определении вероятных факторов, влияющих на функциональный исход шизофрении. В соответствии с нашим анализом, предыдущие исследования показали, что алгоритмы машинного обучения с выбором признаков работают лучше, чем алгоритмы без выбора признаков, при прогнозировании статуса заболевания или реакции на лечение психических расстройств 24 , 32 , 33 .
Примечательно, что интригующим открытием стало то, что любая из моделей машинного обучения со шкалами клинических симптомов всегда превосходила любую из моделей машинного обучения с оценкой когнитивных функций. Например, прогнозные модели с наборами данных Feature-A и Feature-B всегда превосходили прогнозные модели с наборами данных Feature-D и Feature-E в прогнозировании QLS. Аналогичным образом, прогнозные модели с наборами данных Feature-A и Feature-C всегда превосходили прогнозные модели с наборами данных Feature-D и Feature-F при прогнозировании GAF. Мы предположили, что это может быть связано с преимуществом шкалы клинических симптомов над оценкой когнитивных функций при влиянии на функциональные результаты при шизофрении. В соответствии с нашим анализом сообщалось, что клинические симптомы и когнитивные функции объясняют 89% и 44% дисперсии функционального исхода шизофрении соответственно 5 .
Это исследование имело некоторые ограничения. Первым недостатком было то, что перекрестная методология ограничивала прогностическую ценность. Во-вторых, показатели QLS и GAF были связаны с клиническими симптомами, тем самым вызывая совпадение между предикторами и исходом.
В заключение мы создали структуру машинного обучения с набором пакетов с выбором функций для оценки функциональных результатов при шизофрении у тайваньских субъектов с использованием клинических данных. Анализ показывает, что наша система машинного обучения с подбором признаков обнаруживает синергетические эффекты между негативными и депрессивными симптомами, а также между негативными и позитивными симптомами, влияющими на функциональные результаты при шизофрении. В долгосрочной перспективе мы ожидаем, что открытия настоящего исследования могут быть обобщены для прецизионных психиатрических исследований с целью прогнозирования функционального исхода и статуса заболевания при психических расстройствах. Более того, эти открытия, вероятно, могут быть использованы в прогностических и диагностических приложениях в ближайшем будущем. В целом, необходимо провести независимые исследования с использованием репликационных образцов и дополнительно изучить роль структуры машинного обучения ансамбля упаковки, созданной в настоящем исследовании.
Материалы и методы
Это исследование было одобрено институциональным наблюдательным советом больницы Китайского медицинского университета на Тайване и проводилось в соответствии с Хельсинкской декларацией.
Исследуемая популяция
Группа исследования состояла из 302 пациентов с шизофренией, которые были набраны из больницы Китайского медицинского университета и дочерней больницы Тайчжун Чин-Хо на Тайване 5 . В этом исследовании пациенты с шизофренией были в возрасте 18–65 лет и были здоровы в физическом состоянии. После представления испытуемым полного описания этого исследования мы получили письменное информированное согласие от родителя и/или законного опекуна в соответствии с руководящими принципами институционального наблюдательного совета. Подробности диагноза шизофрении были опубликованы ранее 5 .
Шкалы клинических симптомов
В этом исследовании мы использовали 3 шкалы клинических симптомов для оценки позитивных, негативных и депрессивных симптомов 5 , включая подшкалу PANSS-Positive 34 , SANS20 35 и HAMD17 36 .
Когнитивные функции
Мы использовали 11 показателей когнитивных функций для оценки когнитивных функций 5 , включая беглость категорий, прохождение маршрута A, кодирование цифр (шкала интеллекта для взрослых Векслера, третье издание (WAIS-III)), d-Prime ясной версии, d-Prime размытая версия, вербальная рабочая память, невербальная рабочая память, вербальное обучение и память, визуальное обучение и память, рассуждение и решение проблем, а также социальное познание. Вкратце, эти 11 показателей когнитивных функций использовались для оценки 7 когнитивных областей, таких как скорость обработки информации, устойчивое внимание, рабочая память, вербальное обучение и память, визуальное обучение и память, рассуждение и решение проблем, а также социальное познание 5 . Скорость обработки домена оценивалась с использованием категории беглости, создания следов A и цифрового символьного кодирования WAIS-III. Область устойчивого внимания оценивалась с использованием d-Prime для четкой версии и d-Prime для размытой версии. Область рабочей памяти оценивалась с использованием вербальной рабочей памяти и невербальной рабочей памяти.
Функциональные результаты
Мы измеряли функциональные результаты с использованием шкалы QLS 1 и шкалы GAF DSM-IV 2 . QLS является инструментом для оценки функциональных результатов при шизофрении, включая социальную активность, социальные инициативы, социальную изоляцию, целеустремленность, мотивацию, любопытство, ангедонию, бесцельное бездействие, способность к сопереживанию, эмоциональное взаимодействие 8 . GAF – это инструмент, позволяющий оценить глобальное психологическое, социальное и профессиональное функционирование при шизофрении 2 .
статистический анализ
Критерий Стьюдента был проведен для измерения разницы в средних значениях двух непрерывных переменных 37 . Мы выполнили тест хи-квадрат для категориальных данных. Критерий значимости был установлен на уровне P <0,05 для всех тестов. Данные представлены как среднее ± стандартное отклонение.
В предположении, что уровень достоверности 95% и доля 0,5, для расчета размеров выборки использовалась упрощенная формула 38 следующим образом: n = N / (1 + N ( e ) 2 ), где n — размер выборки, N — размер популяции, а e — уровень точности. В этом исследовании мы предположили, что N = 230 000 и e = 0,06.
Модели прогнозирования ансамбля мешков
Мы применили ключевой метод ансамблевого машинного обучения, называемый предикторами пакетирования 25 , и использовали программное обеспечение Waikato Environment for Knowledge Analysis (WEKA) (которое доступно по адресу https://www.cs.waikato.ac.nz/ml/weka/ ) 26 для реализовать структуру прогнозирования ансамбля упаковки. Кроме того, можно использовать другие программные инструменты машинного обучения, например, Pattern Recognition for Neuroimaging Toolbox (PRoNTo; http://www.mlnl.cs.ucl.ac.uk/pronto/ ) и NeuroMiner ( https://github). .com/neurominer-git ). Все эксперименты проводились на компьютере с процессором Intel(R) Core(TM) i5-4210U, 4 ГБ оперативной памяти и ОС Windows 7 21 . Следует отметить, что мы использовали метод повторной десятикратной перекрестной проверки для изучения обобщения предикторов мешков 21 , 32 , 39 .
На рисунке 1 показана иллюстративная диаграмма системы прогнозирования ансамбля мешков с выбором признаков. Техника алгоритма прогнозирования ансамбля мешков используется для объединения прогнозных характеристик нескольких версий базового предиктора для получения агрегированного предиктора с более высокой точностью. Множественные версии базового предиктора формируются с помощью метода начальной загрузки, где метод начальной загрузки является одним из самых популярных методов повторной выборки данных, используемых в статистическом анализе. Техника алгоритма прогнозирования ансамбля мешков имеет тенденцию уменьшать дисперсию и избегать переобучения. Базовым предиктором, который мы использовали, были MFNN или SVM. Здесь мы использовали параметры WEKA по умолчанию, такие как 100 для размера партии, 100 для процента размера пакета и 10 для количества итераций 21 , 40 .
Рисунок 1
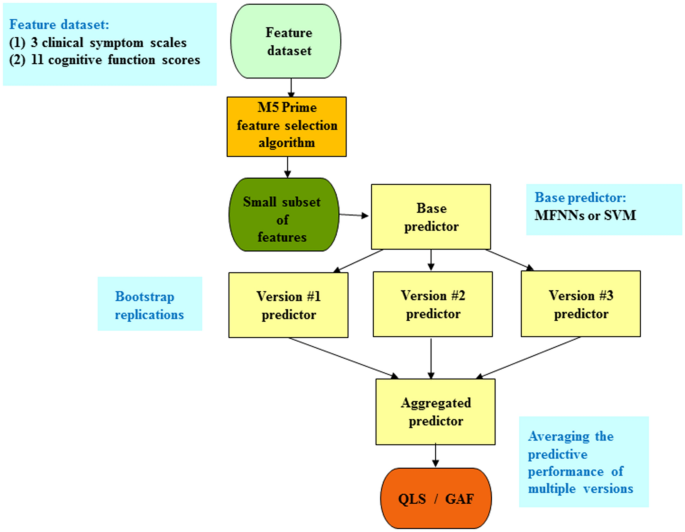
Схематическая иллюстрация алгоритма прогнозирования ансамбля мешков с выбором признаков. Сначала выполняется алгоритм выбора признаков M5 Prime для выбора подмножества признаков, которое служит входными данными для алгоритма прогнозирования ансамбля мешков. Идея алгоритма прогнозирования ансамбля мешков состоит в том, чтобы сгенерировать несколько версий базового предиктора посредством начальной репликации. Окончательный прогноз затем получается путем усреднения прогнозных характеристик нескольких версий. В этом исследовании в качестве базового предиктора были выбраны многослойные нейронные сети прямого распространения (MFNN) или машина опорных векторов (SVM). GAF = Глобальная оценка функционирования; QLS = шкала качества жизни.
Алгоритмы машинного обучения для сравнительного анализа
Для задачи сравнительного анализа в настоящем исследовании мы использовали 4 современных алгоритма машинного обучения, включая MFNN, SVM, линейную регрессию и случайные леса. Мы провели анализ этих 4 алгоритмов машинного обучения с использованием программного обеспечения WEKA 26 и компьютера с процессором Intel (R) Core (TM) i5-4210U, 4 ГБ ОЗУ и Windows 7 21 . Также можно использовать другие программные инструменты машинного обучения, такие как PRoNTo ( http://www.mlnl.cs.ucl.ac.uk/pronto/ ) и NeuroMiner ( https://github.com/neurominer-git ). Следует отметить, что мы использовали метод повторной десятикратной перекрестной проверки, чтобы изучить обобщение этих четырех алгоритмов машинного обучения 21 , 32 , 39 .
Структура MFNN состоит из одного входного слоя, одного или нескольких скрытых слоев и одного выходного слоя, где каждый слой содержит нейронные структуры, а связи между нейронными структурами не содержат направленных циклов 21 , 41 . В общем, алгоритм обратного распространения ошибки 42 широко используется для обучения структуры MFNN, где алгоритм обратного распространения ошибки обновляет веса нейронных структур в слоях структуры MFNN 21 , 43 . В этом исследовании мы использовали архитектуру, содержащую 1 скрытый слой. Например, мы использовали следующие параметры WEKA для обучения модели MFNN с 1 скрытым слоем: импульс = 0,01, скорость обучения = 0,01 и размер пакета = 100 21 , 40 .
Алгоритм SVM 44 является популярным методом распознавания и классификации образов 21 . Алгоритм SVM, основанный на статистической теории обучения, находит линейную связь между входными переменными и зависимой переменной (то есть прогнозируемым результатом) 44 , 45 . Лучшая модель прогнозируемого результата получается путем минимизации как коэффициентов функции стоимости, так и ошибок прогнозирования, где функция стоимости состоит из коэффициентов регрессии и ошибки 44 , 45 . В данном исследовании мы использовали полиномиальное ядро со значением показателя степени 1,0 24 .
Модель случайных лесов объединяет набор деревьев решений, где дерево решений определяется как инвертированное дерево с тремя типами узлов, такими как корневой узел, внутренние узлы и листовые узлы 21 , 46 . Модель случайных лесов концептуализирована для получения лучшего прогноза путем агрегирования результатов прогнозирования из набора деревьев решений 21 , 46 . Здесь мы использовали параметры WEKA по умолчанию для модели случайных лесов; например, 100 для размера пакета и 100 для количества итераций 21 .
Модель линейной регрессии, стандартный метод решения задач прогнозирования в клинических приложениях, использовалась в качестве основы для сравнения 21 , 26 . Линейная регрессия подходит для оценки взаимосвязи между скалярным откликом (то есть зависимой переменной) и объясняющими переменными (то есть независимыми переменными) путем подгонки линейного уравнения к данным 21 , 26 .
Алгоритм выбора функций M5 Prime
В настоящем исследовании мы использовали подход на основе информационного критерия Акаике (AIC), называемый алгоритмом M5 Prime 26, для задачи выбора признаков. Алгоритм M5 Prime строит дерево решений с многомерными линейными моделями в конечных узлах и итеративно удаляет признак с наименьшим стандартизованным коэффициентом до тех пор, пока не перестанет улучшаться оценочная ошибка, определенная AIC 47 , 48 . Более того, мы использовали десятикратный метод перекрестной проверки для изучения обобщения задачи выбора признаков 21 , 32 , 39 .
Чтобы спрогнозировать QLS и GAF, мы использовали алгоритм M5 Prime для выбора признаков из двух разных наборов данных признаков (рис. 1 ). Первый набор функциональных данных включает в себя 3 шкалы клинических симптомов. Второй набор функциональных данных включает 11 оценок когнитивных функций.
Оценка прогнозной эффективности
В этом исследовании мы использовали один из самых популярных критериев, RMSE, для оценки эффективности прогнозных моделей 32 , 45 , 49 . RMSE вычисляет разницу между измеренными значениями и расчетными значениями с помощью прогнозной модели. Чем лучше модель прогнозирования, тем ниже RMSE 32 , 49 . Более того, мы использовали метод повторной десятикратной перекрестной проверки для изучения обобщения прогнозных моделей 21 , 32 , 39 . Сначала весь набор данных был случайным образом разбит на десять отдельных сегментов. Во-вторых, прогностическая модель была обучена с использованием девяти десятых данных и протестирована с использованием оставшейся десятой части данных для оценки эффективности прогнозирования. Затем предыдущий шаг был повторен еще девять раз, исключая отдельные девять десятых данных в качестве данных обучения и отдельную десятую часть данных в качестве данных тестирования. Наконец, средняя оценка была получена по всем запускам путем обработки вышеупомянутой десятикратной перекрестной проверки 10 раз с отдельными пакетами данных. Мы оценили производительность всех прогнозных моделей, используя метод повторной десятикратной перекрестной проверки.
Источник: www.nature.com