Классификация текста с использованием Python и Scikit-learn
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2024-05-14 12:08

Из этого туториала вы узнаете, как быстро построить модель классификации текста с помощью Python и Scikit-learn.
Классификация текста — это задача автоматического присвоения меток частям текста, например статьям, сообщениям в блогах или обзорам. Многие предприятия используют алгоритмы классификации текста, чтобы сэкономить время и деньги за счет сокращения объема ручного труда, необходимого для организации и анализа текстовых данных.
Эти алгоритмы являются чрезвычайно мощными инструментами при правильном использовании. Модели классификации текста защищают вашу электронную почту от спама, помогают авторам обнаруживать плагиат и помогают программе проверки грамматики понимать различные части речи.
Если вы хотите создать классификатор текста, у вас есть множество вариантов на выбор. Вы можете использовать традиционные методы, такие как пакет слов, продвинутые методы, такие как Word2Vec , или передовые подходы, такие как BERT или GPT-3.
Но если ваша цель — быстро и бесплатно запустить что-то, вам следует построить модель классификации текста с помощью Python и Scikit-learn. Я покажу вам, как это сделать, в этом уроке.
Итак, давайте начнем!
Предварительные условия
Прежде чем мы начнем, вам необходимо установить несколько библиотек. Лучший способ сделать это — создать новую виртуальную среду и установить туда пакеты.
Если вы используете venv, выполните следующие команды:
python3 -m venv .textcl source .textcl/bin/activate python3 -m pip install pandas==1.4.3 notebook==6.3.0 numpy==1.23.2 scikit-learn==1.1.2Если вы используете conda, вот как вы это делаете:
conda create --name textcl conda activate textcl conda install pandas==1.4.3 notebook==6.3.0 numpy==1.23.2 scikit-learn==1.1.2Вот и все! Эти команды создадут виртуальную среду, активируют ее и установят необходимые пакеты.
Наконец, запустите сеанс Jupyter Notebook, выполнив jupyter notebookна том же терминале, где вы запускали предыдущие команды, и создайте новый блокнот.
Импортируйте необходимые библиотеки
Первым шагом, как всегда, является импорт необходимых библиотек. Создайте новую ячейку в блокноте, вставьте в нее следующий код и запустите ячейку:
import joblib import re import string import numpy as np import pandas as pd from sklearn.datasets import fetch_20newsgroups from sklearn.feature_extraction.text import CountVectorizer from sklearn.metrics import accuracy_score, cohen_kappa_score, f1_score, classification_report from sklearn.model_selection import StratifiedKFold, train_test_split from sklearn.naive_bayes import MultinomialNBЭтот код импортирует необходимые библиотеки. Вот почему они вам нужны:
- Вы импортируете , чтобы сохранить артефакты
joblibмодели . - Вы импортируете
reиstringобрабатываете текст. - Вы импортируете
numpyиpandasчитаете и преобразуете данные. - Вы импортируете несколько компонентов для
scikit-learnизвлечения функций из текста, расчета показателей оценки, разделения данных на обучающий и тестовый наборы и использования многочленного наивного алгоритма Байеса.
Далее вы прочитаете и обработаете данные.
Прочтите данные
Начните с чтения данных. Вы будете использовать набор данных, включенный в scikit-learnгруппу новостей 20 . Этот набор данных состоит примерно из 20 000 документов групп новостей, разделенных на 20 категорий. Для простоты в этом примере вы будете использовать только пять из этих категорий.
Создайте новую ячейку и вставьте этот код, чтобы прочитать данные:
categories = [ "alt.atheism", "misc.forsale", "sci.space", "soc.religion.christian", "talk.politics.guns", ] news_group_data = fetch_20newsgroups( subset="all", remove=("headers", "footers", "quotes"), categories=categories ) df = pd.DataFrame( dict( text=news_group_data["data"], target=news_group_data["target"] ) ) df["target"] = df.target.map(lambda x: categories[x])Этот код считывает набор данных из 20 групп новостей. Вот как это работает:
- Строки с 1 по 7: Определите список категорий, которые представляют собой различные категории групп новостей, используемые в анализе:
alt.atheism,misc.forsale,sci.space,soc.religion.christianиtalk.politics.guns. - Строки с 9 по 11: используйте
fetch_20newsgroupsдля получения данных из набора данных 20 групп новостей. Эта функция удаляет из данных верхние, нижние колонтитулы и кавычки и получает данные только из категорий, указанных в спискеcategories. - Строки 13 и 19: создайте фрейм данных на основе полученных данных. Фрейм данных имеет два столбца: один для текста сообщения группы новостей и один для категории (цели) группы новостей. Вы меняете целевой столбец, чтобы вместо номера отображалось фактическое имя категории.
Вот и все. Теперь вы немного очистите данные.
Подготовьте данные
Прежде чем создавать модель классификации текста, вам необходимо подготовить данные. Вы сделаете это в три этапа: очистите текстовый столбец, создадите разделения для обучения и тестирования и создадите набор слов из документов.
Очистите текстовый столбец
Используйте этот код для очистки текста. Он удалит знаки препинания и несколько соседних пробелов:
def process_text(text): text = str(text).lower() text = re.sub( f"[{re.escape(string.punctuation)}]", " ", text ) text = " ".join(text.split()) return text df["clean_text"] = df.text.map(process_text)Этот код преобразует текст в нижний регистр, удаляет все знаки препинания и повторяющиеся пробелы и сохраняет результаты в новом столбце с именем clean_text. Для этого вы используете process_text, который принимает строку в качестве входных данных, преобразует ее в нижний регистр, заменяет все знаки препинания пробелами и удаляет дублированные пробелы.
Разделите данные на обучающие и тестовые наборы
Далее вы разделите набор данных на обучающий и тестовый набор:
df_train, df_test = train_test_split(df, test_size=0.20, stratify=df.target)train_test_splitиспользуется для разделения набора данных на обучающий и тестовый наборы. Вы предоставляете фрейм данных, который хотите разделить на функцию, и указываете следующие параметры:
test_size=0.20: определяет размер тестового набора в размере 20 % от общего числа.stratify=df.target: гарантирует, что наборы обучения и тестирования будут разделены послойно с использованиемtarget. Это важно, поскольку предотвращает предвзятость.
Далее вы будете использовать эти наборы данных для обучения и оценки своей модели.
Создать мешок слов
Модели машинного обучения не могут напрямую обрабатывать текстовые функции. Чтобы обучить модель, сначала необходимо преобразовать текст в числовые характеристики. Один из популярных подходов к этому называется « мешок слов» , и именно его вы будете использовать в этом примере.
В подходе «мешок слов» каждый документ представляется в виде строки в матрице, где каждое слово или токен отображается в документе в виде столбца.
Например, рассмотрим эти два предложения:
- я люблю читать книги
- я не люблю готовить
Простейшее представление набора слов для этих двух предложений будет выглядеть так:
| id_doc | я | нравиться | чтение | книги | делать | нет | Готовка |
|---|---|---|---|---|---|---|---|
| 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 |
| 2 | 1 | 1 | 0 | 0 | 1 | 1 | 1 |
Получив это числовое представление, вы можете передать этот набор данных в свою модель машинного обучения. Это то, что вы сделаете с документами в наборе данных 20 групп новостей. Имейте в виду, что, поскольку в наборе данных очень много документов, в итоге вы получите матрицу с гораздо большим количеством столбцов, чем в примере выше.
Чтобы создать набор слов в формате scikit-learn, вы должны использовать CountVectorizer. Вы можете использовать этот код:
vec = CountVectorizer( ngram_range=(1, 3), stop_words="english", ) X_train = vec.fit_transform(df_train.clean_text) X_test = vec.transform(df_test.clean_text) y_train = df_train.target y_test = df_test.targetCountVectorizerпревращает текст в числовые характеристики. Вот что происходит в приведенном выше коде:
- Строки с 1 по 4: вы используете
CountVectorizerдля создания набора слов представлениеclean_text. Вы указываете два параметра:ngram_rangeиstop_words.ngram_range— это диапазон n-грамм, который будет использовать функция. N-грамма — это последовательность из n слов.(1, 3)означает, что функция будет использовать последовательности из 1, 2 и 3 слов для генерации счетчиков.stop_words— это список слов, которые функция будет игнорировать. В данном случае список «английский» означает, что функция будет игнорировать наиболее распространенные слова на английском языке. - Строки 6 и 7: вы генерируете матрицы количества токенов для своего набора обучения и тестирования и сохраняете их в файлах
X_trainиX_test. - Строки 9 и 10: вы сохраняете переменную ответа из набора обучения и тестирования в
y_trainиy_test.
Далее вы обучите свою модель классификации текста.
Обучите и оцените модель
Наконец, вы можете обучить модель, запустив этот код:
nb = MultinomialNB() nb.fit(X_train, y_train) preds = nb.predict(X_test) print(classification_report(y_test, preds))В строках 1 и 2 вы обучаете полиномиальную наивную байесовскую модель. Эта простая вероятностная модель обычно используется в случаях с дискретными функциями, такими как количество слов.
Затем в строках 4 и 5 вы оцениваете результаты модели, вычисляя показатели точности, полноты и f1 .
После запуска кода вы получите результат, который будет выглядеть примерно так:
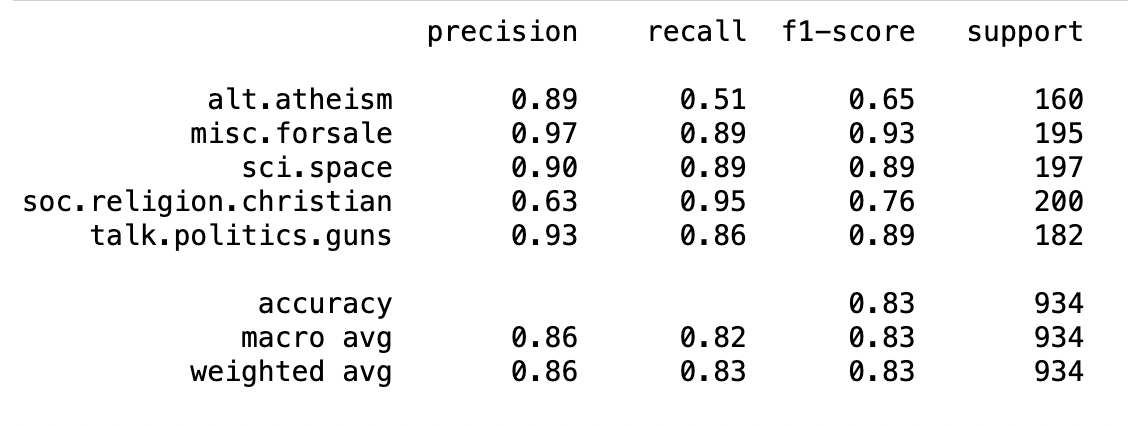
Вы обучили модель и получили соответствующие показатели оценки. Вы набрали 0,83 f1, что неплохо!
Далее вы узнаете, как сохранить и загрузить модель, чтобы использовать ее для вывода.
Сохранение и загрузка модели
Если вы хотите сохранить модель на будущее, вы можете использовать joblib. Вам нужно будет сохранить все артефакты, необходимые для запуска модели, которыми в данном случае будут векторизатор vecи модель nb.
Вы можете использовать следующий код для сохранения артефактов модели:
joblib.dump(nb, "nb.joblib") joblib.dump(vec, "vec.joblib")Если вы хотите повторно использовать свою модель позже, просто прочитайте ее и используйте для классификации новых образцов данных следующим образом:
nb_saved = joblib.load("nb.joblib") vec_saved = joblib.load("vec.joblib") sample_text = ["Space, Stars, Planets and Astronomy!"] # Process the text in the same way you did when you trained it! clean_sample_text = process_text(sample_text) sample_vec = vec_saved.transform(sample_text) nb_saved.predict(sample_vec)Приведенный выше код прочитает ранее сохраненные артефакты в файлы nb_savedи vec_saved. Затем вы можете применить их к новым образцам текста, которые хотите классифицировать.
Вот и все! Вы узнали, как использовать Python и Scikit-learn для обучения модели классификации текста. Позвольте мне предложить несколько советов о том, что вы могли бы сделать дальше.
Следующие шаги
Если вы хотите поднять свои навыки моделирования на новый уровень, вот несколько идей для изучения:
- Использование перекрестной проверки, чтобы гарантировать, что ваши результаты хорошо обобщаются.
- Получите максимальную отдачу от своей модели, настроив ее гиперпараметры .
- Использование конвейеров
scikit-learn's для создания меньшего количества артефактов и упрощения развертывания.
Кроме того, учитывая последние достижения в области обработки естественного языка (НЛП), подходы на основе преобразователей становятся подходящим вариантом для решения многих задач, в которых используются функции текста. Хорошей отправной точкой является курс НЛП от Huggingface .
Заключение
В машинном обучении классификация текста — это задача маркировки фрагментов текста с помощью автоматизированных методов. В этом руководстве показано, как создать свою первую модель классификации текста с помощью Python и Scikit-learn.
Источник: dylancastillo.co