Введение в разработку функций для машинного обучения с помощью Python
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2024-03-31 14:01

Разработка функций — это процесс преобразования данных для повышения прогнозной эффективности моделей машинного обучения.
Введение
Разработка функций, пожалуй, самый важный, но упускаемый из виду навык в прогнозном моделировании. Мы используем его в повседневной жизни, даже не задумываясь об этом!
Поясню — допустим, вы бармен, и к вам подходит человек и просит водку-тоник. Вы продолжаете запрашивать удостоверение личности и видите, что день рождения человека — «12.09.1998». Эта информация по своей сути не имеет смысла, но вы суммируете количество лет, выполняя быстрые математические вычисления, и выясняете, что этому человеку 22 года (что превышает возраст, с которого разрешено употребление алкоголя). Что там произошло? Вы взяли часть информации («12.09.1998») и преобразовали ее, чтобы она стала другой переменной (возраст), чтобы решить возникший у вас вопрос («Можно ли этому человеку пить?»).
Разработка функций — это именно то, что касается моделей машинного обучения. Мы даем нашей модели (моделям) наилучшее представление наших данных — путем преобразования и манипулирования ими — чтобы лучше предсказать интересующий нас результат. Если сейчас это не на 100% ясно, то станет намного яснее, когда мы рассмотрим реальные примеры в этой статье.
Определение
Разработка функций — это процесс преобразования данных для повышения прогнозной эффективности моделей машинного обучения.
Важность
Разработка функций полезна и необходима по следующим причинам:
- Часто более высокая точность прогнозирования. Методы проектирования функций, такие как стандартизация и нормализация, часто приводят к лучшему взвешиванию переменных, что повышает точность, а иногда и приводит к более быстрой сходимости.
- Лучшая интерпретируемость отношений в данных: когда мы разрабатываем новые функции и понимаем, как они связаны с интересующим нас результатом, это открывает нам понимание данных. Если мы пропустим этап разработки признаков и воспользуемся сложными моделями (которые в значительной степени автоматизируют разработку признаков), мы все равно можем получить высокий балл оценки за счет лучшего понимания наших данных и их взаимосвязи с целевой переменной.
Разработка функций необходима, поскольку большинство моделей не могут принимать определенные представления данных. Например, такие модели, как линейная регрессия, не могут обрабатывать пропущенные значения самостоятельно — их необходимо вменить (заполнить). Мы увидим примеры этого в следующем разделе.
Рабочий процесс
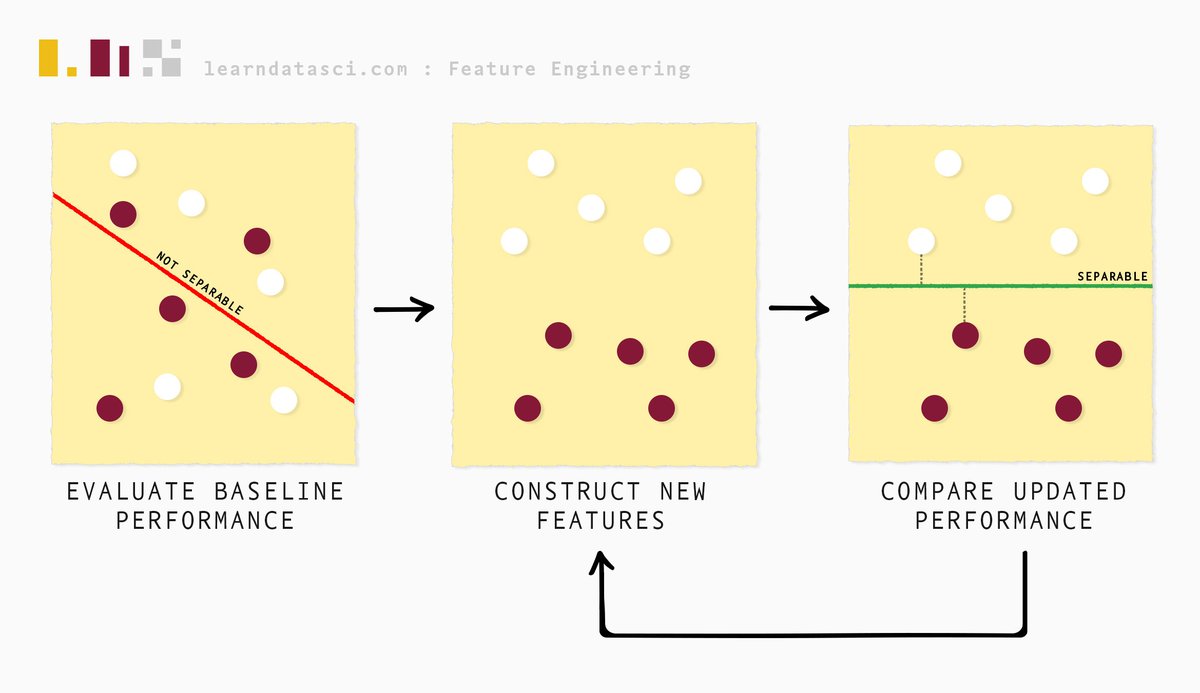

Каждый конвейер обработки данных начинается с исследовательского анализа данных (EDA) или первоначального анализа наших данных. EDA — это важный предварительный шаг, поскольку мы лучше понимаем, какие функции нам нужно создать/изменить. Следующим шагом обычно является очистка/стандартизация данных в зависимости от того, насколько неструктурированы или беспорядочны данные.
Далее следует разработка функций, и мы начинаем этот процесс с оценки базовой производительности имеющихся данных. Затем мы итеративно конструируем функции и постоянно оцениваем производительность модели (и сравниваем ее с базовой производительностью) с помощью процесса, называемого выбором функций, пока не будем удовлетворены результатами.
О чем говорится в этой статье, а что нет
Разработка функций — это обширная область, поскольку существует множество аспектов, специфичных для предметной области. В этой статье рассматриваются некоторые популярные методы, используемые при работе с наборами табличных данных. Мы не рассматриваем разработку функций для обработки естественного языка (NLP), классификации изображений, данных временных рядов и т. д.
Два подхода к разработке функций
Существует два основных подхода к проектированию признаков для большинства наборов табличных данных:
- Подход с использованием контрольного списка: использование проверенных методов для создания функций.
- Подход на основе предметной области: включение знаний о предмете набора данных в создание новых функций.
Теперь мы рассмотрим эти подходы подробно, используя реальные наборы данных. Обратите внимание: эти примеры довольно процедурны и направлены на то, чтобы показать, как их можно реализовать на Python. Тематическое исследование, следующее за этим разделом, покажет вам реальный комплексный сценарий использования практик, которые мы затрагиваем в этом разделе.
Прежде чем загружать набор данных, мы импортируем следующие зависимости, показанные ниже.
# dependencies import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns sns.set_theme() sns.set_palette(sns.color_palette(['#851836', '#edbd17'])) sns.set_style("darkgrid") from sklearn.preprocessing import MinMaxScaler from sklearn.decomposition import PCA from sklearn.linear_model import LinearRegression from sklearn.metrics import mean_squared_error from sklearn.model_selection import train_test_split Теперь мы продемонстрируем подход с использованием контрольного списка, используя набор данных о продажах в супермаркетах. Исходный набор данных и дополнительная информация о нем доступны здесь . Обратите внимание, что для этого урока набор данных был немного изменен.
Разверните, чтобы увидеть описания столбцов
Столбцы описаны следующим образом:
- Идентификатор счета — идентификационный номер счета-фактуры, созданный компьютером.
- Филиал - Филиал суперцентра (доступны 3 филиала, обозначенные A, B и C).
- Город - Расположение суперцентров
- Тип клиента — тип клиентов, зарегистрированный участниками для клиентов, использующих карту участника, и обычный для клиентов без карты участника.
- Пол — пол типа клиента.
- Линейка продуктов – общие группы категоризации товаров.
- Цена за единицу - Цена каждого продукта в долларах США.
- Количество – количество товаров, приобретенных покупателем.
- Налог 5% - 5% налоговый сбор за покупку клиента
- Итого – общая стоимость, включая налог.
- Дата - Дата покупки
- Время - Время покупки
- Оплата — оплата, используемая покупателем для покупки.
- винтики - Себестоимость реализованной продукции
- процент валовой прибыли
- налог
- Рейтинг — рейтинг стратификации клиентов по их общему опыту покупок (по шкале от 1 до 10).
df = pd.read_csv('data/supermarket_sales.csv') df.head() Вне:
| Идентификатор счета | Ветвь | Город | Тип клиента | Пол | Линия продуктов | Цена за единицу товара | Количество | Налог 5% | Общий | Дата | Время | Оплата | винтики | процент валовой прибыли | налог | Рейтинг | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 750-67-8428 | А | Янгон | Член | Женский | Здоровье и красота | 74,69 | 7.0 | 26.1415 | 548,9715 | 05.01.19 | 13:08 | Электронный кошелек | 522,83 | 4.761905 | 26.1415 | 9.1 |
| 1 | 226-31-3081 | С | Нейпьидо | Нормальный | Женский | Электронные аксессуары | 15.28 | 5.0 | 3,8200 | 80.2200 | 08.03.19 | 10:29 | Наличные | 76.40 | 4.761905 | 3,8200 | 9,6 |
| 2 | 631-41-3108 | А | Янгон | Нормальный | Мужской | Дом и образ жизни | 46,33 | 7.0 | 16.2155 | 340,5255 | 03.03.19 | 13:23 | Кредитная карта | 324,31 | 4.761905 | 16.2155 | 7.4 |
| 3 | 123-19-1176 | А | Янгон | Член | Мужской | Здоровье и красота | 58,22 | 8.0 | 23.2880 | 489.0480 | 27.01.19 | 20:33 | Электронный кошелек | 465,76 | 4.761905 | 23.2880 | 8.4 |
| 4 | 373-73-7910 | А | Янгон | Нормальный | Мужской | Спорт и путешествия | 86,31 | 7.0 | 30.2085 | 634,3785 | 08.02.19 | 10:37 | Электронный кошелек | 604,17 | 4.761905 | 30.2085 | 5.3 |
Метод контрольного списка
Числовые агрегаты
Числовое агрегирование — это распространенный подход к проектированию признаков для продольных или панельных данных — данных, в которых объекты повторяются. В нашем наборе данных есть категориальные переменные с повторяющимися наблюдениями (например, у нас есть несколько записей для каждого филиала супермаркета).
Числовая агрегация включает в себя три параметра:
- Категориальный столбец
- Числовые столбцы, подлежащие агрегированию
- Тип агрегирования: среднее значение, медиана, мода, стандартное отклонение, дисперсия, количество и т. д.
В приведенном ниже фрагменте кода показаны три примера числовых агрегаций, основанных на среднем значении, стандартном отклонении и количестве соответственно.
В следующем блоке наши три параметра:
- Ветка – категориальный столбец, по которому мы группируем
- Налог 5%, Цена за единицу, Линейка продуктов и Пол — числовые столбцы для агрегирования.
- Среднее значение, стандартное отклонение и количество — агрегаты, которые будут использоваться в числовых столбцах.
Ниже мы группируем данные по ветвям и выполняем три статистических агрегирования (среднее значение, стандартное отклонение и подсчет), преобразуя интересующие числовые столбцы. Например, в первом назначении столбца мы вычисляем средний налог 5% и среднюю цену за единицу для каждого филиала, что дает нам два новых столбца — tax_branch_meanи unit_price_meanв фрейме данных.
# Numeric aggregations grouped_df = df.groupby('Branch') df[['tax_branch_mean','unit_price_mean']] = grouped_df[['Tax 5%', 'Unit price']].transform('mean') df[['tax_branch_std','unit_price_std']] = grouped_df[['Tax 5%', 'Unit price']].transform('std') df[['product_count','gender_count']] = grouped_df[['Product line', 'Gender']].transform('count') И мы видим функции, которые мы только что создали ниже.
df[['Branch', 'tax_branch_mean', 'unit_price_mean', 'tax_branch_std', 'unit_price_std', 'product_count', 'gender_count']].head(10) Вне:
| Ветвь | Tax_branch_mean | unit_price_mean | Tax_branch_std | unit_price_std | Product_count | гендерный_счет | |
|---|---|---|---|---|---|---|---|
| 0 | А | 14,894393 | 54.937935 | 11.043263 | 26.203576 | 331 | 342 |
| 1 | С | 16.052367 | 56,645583 | 12.531470 | 27.247291 | 308 | 328 |
| 2 | А | 14,894393 | 54.937935 | 11.043263 | 26.203576 | 331 | 342 |
| 3 | А | 14,894393 | 54.937935 | 11.043263 | 26.203576 | 331 | 342 |
| 4 | А | 14,894393 | 54.937935 | 11.043263 | 26.203576 | 331 | 342 |
| 5 | С | 16.052367 | 56,645583 | 12.531470 | 27.247291 | 308 | 328 |
| 6 | А | 14,894393 | 54.937935 | 11.043263 | 26.203576 | 331 | 342 |
| 7 | С | 16.052367 | 56,645583 | 12.531470 | 27.247291 | 308 | 328 |
| 8 | А | 14,894393 | 54.937935 | 11.043263 | 26.203576 | 331 | 342 |
| 9 | Б | 15.277808 | 55,743474 | 11.557958 | 26.136309 | 321 | 333 |
Примечание. Поскольку мы просматриваем подмножество столбцов в полном объеме df, похоже, что есть повторяющиеся строки. Когда остальные столбцы станут видимыми, вы заметите, что повторяющихся строк нет, но повторяющиеся значения все равно есть. Это сделано специально.
Выбор числовых параметров агрегирования
Как нам выбрать, какие три параметра использовать? Ну, это будет зависеть от ваших знаний в предметной области и вашего понимания набора данных. Например, в этом наборе данных, если вы чувствуете, что изменение среднего ( тип агрегирования) рейтинга (числовая переменная) на основе отрасли (категориальный столбец) важно для прогнозирования валового дохода (целевая переменная), создайте функцию! Если вы считаете, что количество продуктов в линейке продуктов по отраслям важно для определения валового дохода, закодируйте это как функцию!
Теперь, если вы можете протестировать как можно больше комбинаций трех параметров — продолжайте — при условии, что вы тщательно выбираете только те функции, которые имеют достаточную предсказательную силу, то есть убедитесь, что у вас есть строгий процесс выбора функций.
Ниже мы можем увидеть пару созданных нами столбцов ( tax_branch_meanи unit_price_mean). Это агрегаты, основанные на Branchпеременной.
df[['Tax 5%', 'Unit price', 'Branch', 'tax_branch_mean', 'unit_price_mean']] Вне:
| Налог 5% | Цена за единицу товара | Ветвь | Tax_branch_mean | unit_price_mean | |
|---|---|---|---|---|---|
| 0 | 26.1415 | 74,69 | А | 14,894393 | 54.937935 |
| 1 | 3,8200 | 15.28 | С | 16.052367 | 56,645583 |
| 2 | 16.2155 | 46,33 | А | 14,894393 | 54.937935 |
| 3 | 23.2880 | 58,22 | А | 14,894393 | 54.937935 |
| 4 | 30.2085 | 86,31 | А | 14,894393 | 54.937935 |
| ... | ... | ... | ... | ... | ... |
| 998 | 3.2910 | 65,82 | А | 14,894393 | 54.937935 |
| 999 | 30.9190 | 88,34 | А | 14,894393 | 54.937935 |
| 1000 | 30.9190 | 88,34 | А | 14,894393 | 54.937935 |
| 1001 | 5.8030 | НЭН | А | 14,894393 | 54.937935 |
| 1002 | 30,4780 | 87.08 | Б | 15.277808 | 55,743474 |
1003 строки x 5 столбцов
Но зачем все это необходимо?
Прежде чем я продолжу, вы, возможно, задаетесь вопросом, почему это вообще необходимо – разве хорошие модели не созданы для того, чтобы учитывать все эти агрегаты? В какой-то степени да, но не всегда. Это во многом зависит от размера и размерности (количества столбцов) вашего набора данных. Чем больше набор данных, тем больше объектов (на несколько порядков) вы можете создать. Когда функций слишком много, модель имеет слишком много конкурирующих сигналов для прогнозирования целевой переменной.
Разработка функций пытается явно сосредоточить внимание модели на определенных функциях. Подводя итог, можно сказать, что разработка функций заключается не в создании «новой» информации, а скорее в направлении и/или концентрации внимания модели на определенной информации, которую вы, как специалист по данным, считаете важной.
Переменные индикатора и условия взаимодействия
Следуя той же модели мышления, что и числовые агрегации, мы можем создавать индикаторные переменные и условия взаимодействия.
Индикаторные переменные принимают значение 0 или 1 только для обозначения отсутствия или присутствия некоторой информации.
Например, ниже мы определяем индикаторную переменную, unit_price_50указывающую, имеет ли продукт цена за единицу больше 50. Чтобы представить это в перспективе, представьте себе магазин электронной коммерции, в котором бесплатная доставка для всех заказов на сумму выше 50 долларов США; это может быть полезной информацией для прогнозирования поведения клиентов и заслуживает четкого определения модели.
Условия взаимодействия создаются на основе наличия эффектов взаимодействия между двумя или более переменными. Во многом это обусловлено экспертными знаниями в предметной области, хотя существуют статистические тесты, помогающие их определить (что выходит за рамки этой статьи). Например, хотя бесплатная доставка может повлиять на рейтинг клиента, бесплатная доставка в сочетании с количеством может иметь другое влияние на рейтинг клиента, который было бы полезно закодировать (предполагая, что в данном случае рейтинг клиента является целевой переменной). Ниже мы определяем переменную unit_price_50 * qtyименно так.
Мы используем np.where()для создания индикаторной переменной unit_price_50, которая кодирует 1, когда цена за единицу превышает 50, и 0 в противном случае.
df['unit_price_50'] = np.where(df['Unit price'] > 50, 1, 0) df['unit_price_50 * qty'] = df['unit_price_50'] * df['Quantity'] df[['unit_price_50', 'unit_price_50 * qty']].head() Вне:
| unit_price_50 | unit_price_50 * кол-во | |
|---|---|---|
| 0 | 1 | 7.0 |
| 1 | 0 | 0,0 |
| 2 | 1 | 7.0 |
| 3 | 1 | 8.0 |
| 4 | 1 | 7.0 |
Числовые преобразования
Некоторые ученые, работающие с данными, не считают, что числовые преобразования подпадают под разработку функций. Это связано с тем, что многие модели, особенно новые, такие как древовидные модели (деревья решений, случайные леса и т. д.), не подвергаются воздействию этих преобразований. Другими словами, выполнение этих преобразований не улучшает производительность прогнозирования. Но для других моделей, таких как линейная регрессия, эти преобразования могут иметь большое значение, поскольку они чувствительны к масштабу переменных.
Ниже мы создадим новую переменную log_cogs, чтобы исправить перекос вправо в переменной cogs. Эффект показан на графиках под фрагментом кода.
Мы также можем выполнить другие преобразования, такие как возведение переменной в квадрат (показано в фрагменте кода ниже), если мы считаем, что связь между предиктором и целевой переменной носит не линейный, а квадратичный характер (при изменении предикторной переменной целевая переменная изменяется на порядок 2).
Мы можем даже иметь кубические переменные или любой полиномиальный член n степени — это на ваше усмотрение и знание предметной области.
# numeric transformations df['log_cogs'] = np.log(df['cogs'] + 1) df['gross income squared'] = np.square(df['gross income']) df[['cogs', 'log_cogs', 'gross income', 'gross income squared']].head() Вне:
| винтики | log_cogs | налог | валовой доход в квадрате | |
|---|---|---|---|---|
| 0 | 522,83 | 6.261167 | 26.1415 | 683.378022 |
| 1 | 76.40 | 4,348987 | 3,8200 | 14.592400 |
| 2 | 324,31 | 5,784779 | 16.2155 | 262,942440 |
| 3 | 465,76 | 6.145815 | 23.2880 | 542.330944 |
| 4 | 604,17 | 6.405509 | 30.2085 | 912.553472 |
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(15,6)) sns.histplot(df['cogs'], ax=ax1, kde=True) sns.histplot(df['log_cogs'], ax=ax2, kde=True); РЕЗУЛЬТАТ:
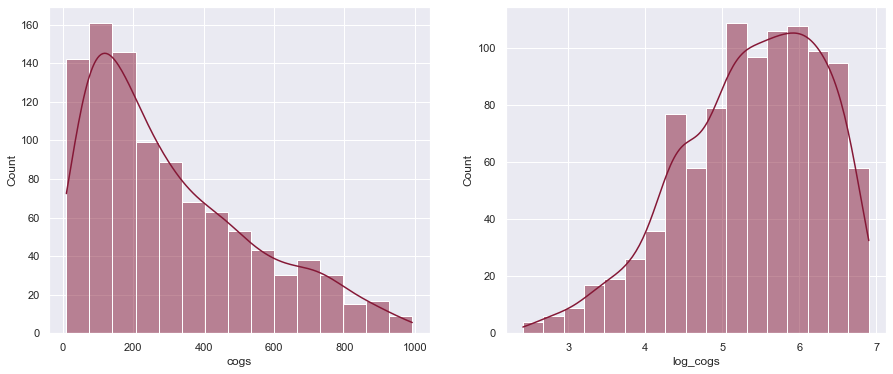
Как мы видим, логарифмическое преобразование сделало распределение стоимости проданных товаров (cogs) более нормальным (или менее смещенным вправо). Это принесет пользу таким моделям, как линейная регрессия, поскольку на их веса/коэффициенты не будут сильно влиять выбросы, вызвавшие первоначальную асимметрию.
Кроме того, поскольку на протяжении статьи мы будем сравнивать графики рядом друг с другом много раз, с этого момента мы будем просто использовать эту вспомогательную функцию:
def plot_hist(data1, data2): fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(15,6)) sns.histplot(data1, ax=ax1, kde=True) sns.histplot(data2, ax=ax2, kde=True); Числовое масштабирование
Столбцы в наборе данных обычно имеют разные масштабы. Например, в нашем наборе данных «валовой доход» и «рейтинг» имеют совершенно разные шкалы (как показано ниже). Чтобы исправить это, мы можем выполнить «нормализацию», чтобы поместить оба столбца в шкалу от 0 до 1.
Почему мы это делаем? Когда переменные-предикторы находятся в очень разных масштабах, такие модели, как линейная регрессия, могут смещать коэффициенты к переменным в более крупном масштабе. Поэтому мы исправляем это, нормализуя эти числовые переменные.
Мы можем нормализовать переменную разными способами, но наиболее распространенный способ сделать это — использовать масштабатор min-max (показан ниже графиков). Формула приведена ниже — для каждого значения в столбце вычитаем минимальное значение столбца и полученное число делим на диапазон столбца (
).
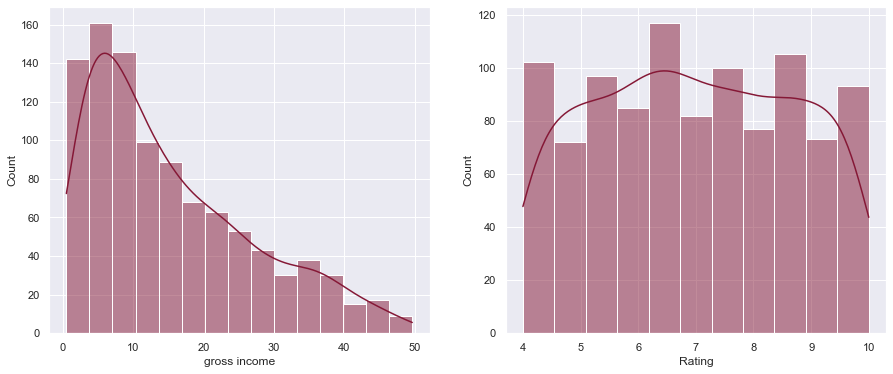
Мы можем увидеть диапазон gross incomeи Ratingв настоящее время в нашем наборе данных:
gincome = df["gross income"] rating = df["Rating"] print(f'Gross income range: {gincome.min()} to {gincome.max()}') print(f'Rating range: {rating.min()} to {rating.max()}') plot_hist(gincome, rating) Вне:
Gross income range: 0.5085 to 49.65 Rating range: 4.0 to 10.0 РЕЗУЛЬТАТ:
Ниже мы можем увидеть разницу в масштабе после применения нормализации.
df[["gross income", "Rating"]] = MinMaxScaler().fit_transform(df[["gross income", "Rating"]]) plot_hist(df['gross income'], df['Rating']) РЕЗУЛЬТАТ:
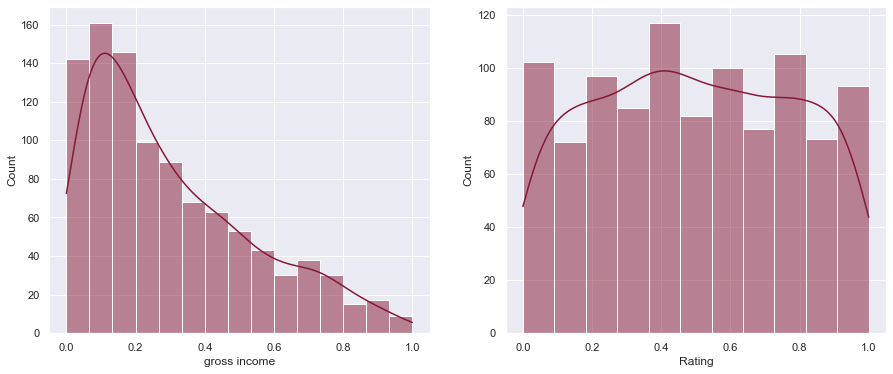
Обратите внимание, что графики выглядят одинаково, но масштаб по оси X теперь находится между 0 и 1.
Обработка категориальных переменных
Горячее кодирование
Модели машинного обучения могут обрабатывать только числовые переменные. Поэтому мы должны кодировать категориальные переменные как числовые. Самый простой способ сделать это — выполнить «горячее кодирование», что означает, что мы создаем
индикаторные переменные для категориального столбца с
категории. В приведенном ниже коде показано, как мы можем выполнить горячее кодирование двух категориальных столбцов — Genderи Payment.
pd.get_dummies(df[['Gender','Payment']]).head() Вне:
| Женский пол | Мужской пол | Оплата_наличными | Оплата_Кредитная карта | Платеж_электронный кошелек | |
|---|---|---|---|---|---|
| 0 | 1 | 0 | 0 | 0 | 1 |
| 1 | 1 | 0 | 1 | 0 | 0 |
| 2 | 0 | 1 | 0 | 1 | 0 |
| 3 | 0 | 1 | 0 | 0 | 1 |
| 4 | 0 | 1 | 0 | 0 | 1 |
Но есть проблемы с этим подходом. Если у нас есть столбец с 1000 категориями, одно горячее кодирование этого столбца создаст 1000 новых столбцов! Это много! Вы снабжаете модель слишком большим количеством информации, и, естественно, найти закономерности становится гораздо сложнее. Когда у нас слишком много размерностей, нашей модели потребуется гораздо больше времени для обучения и поиска оптимальных весов предикторов.
Целевая кодировка
Чтобы решить эту проблему, мы можем использовать целевую кодировку. Целевая кодировка не создает дополнительных столбцов. Идея проста: для каждой уникальной категории рассчитывается среднее значение целевой переменной (при условии, что она непрерывная или двоичная), и оно становится значением для соответствующей категории в категориальном столбце.
Давайте сначала рассмотрим простой пример, прежде чем применять его к нашему набору данных. У нас есть два столбца — цель и переменная-предиктор. Наша цель — закодировать переменную-предиктор (категориальный столбец) в числовую переменную, которая может использоваться моделью. Для этого мы просто группируем по переменной-предиктору, чтобы получить среднее целевое значение для каждой категории предикторов. Таким образом, для предиктора aзакодированное значение будет средним значением 1 и 5, что равно 3. Ибо bэто среднее значение 4 и 6, что равно 5. Теперь наш категориальный столбец является числовым столбцом!
target = [1, 4, 5, 6] predictor = ['a', 'b', 'a', 'b'] target_enc_df = pd.DataFrame(data={'target':target, 'predictor':predictor}) means = target_enc_df.groupby('predictor')['target'].mean() target_enc_df['predictor_encoded'] = target_enc_df['predictor'].map(means) target_enc_df Вне:
| цель | предсказатель | предиктор_кодированный | |
|---|---|---|---|
| 0 | 1 | а | 3 |
| 1 | 4 | б | 5 |
| 2 | 5 | а | 3 |
| 3 | 6 | б | 5 |
Далее мы используем целевую кодировку в нашем наборе данных супермаркета. В приведенном ниже примере мы используем Product lineв качестве категориального столбца целевую кодировку, которая Ratingявляется целевой переменной, которая является непрерывной переменной.
means = df.groupby('Product line')['Rating'].mean() df['Product line target encoded'] = df['Product line'].map(means) df[['Product line','Product line target encoded','Rating']] Вне:
| Линия продуктов | Целевая линия продуктов закодирована | Рейтинг | |
|---|---|---|---|
| 0 | Здоровье и красота | 0,506134 | 0,850000 |
| 1 | Электронные аксессуары | 0,481313 | 0,933333 |
| 2 | Дом и образ жизни | 0,479139 | 0,566667 |
| 3 | Здоровье и красота | 0,506134 | 0,733333 |
| 4 | Спорт и путешествия | 0,484151 | 0,216667 |
| ... | ... | ... | ... |
| 998 | Дом и образ жизни | 0,479139 | 0,016667 |
| 999 | Модные аксессуары | 0,514341 | 0,433333 |
| 1000 | Модные аксессуары | 0,514341 | 0,433333 |
| 1001 | Электронные аксессуары | 0,481313 | 0,800000 |
| 1002 | Электронные аксессуары | 0,481313 | 0,250000 |
1003 строки x 3 столбца
У целевого кодирования есть свои недостатки: когда категория появляется только один раз, среднее значение этой категории является самим значением (среднее значение одного числа — это само число). В общем, не всегда полезно полагаться на среднее значение, если количество используемых в нем значений невелико. Это приводит к проблемам с обобщением результатов набора обучающих данных на набор тестовых данных или данных, на которых модель не обучается.
Вывод из этого раздела — попытаться выполнить горячее кодирование, если размерность не будет проблемой. Если это проблема, вы можете использовать другие подходы, например целевое кодирование.
Обработка отсутствующих значений
Прогнозное моделирование можно рассматривать как извлечение правильных сигналов из набора данных. Отсутствующие значения могут быть либо самими источниками сигнала (когда значения отсутствуют случайно), либо отсутствием сигнала (когда значения отсутствуют случайно).
Примечание
Примечание. Данные были изменены и содержат пропущенные значения, чтобы мы могли обсудить эту тему. Если вы получили свежую копию от Kaggle, в ней не должно быть пропущенных значений.
Например, предположим, что у нас есть некоторые данные о населении, и мы добавляем столбец, has_licenseуказывающий, есть ли у человека водительские права или нет. Мы заметим пропущенные значения — непропорционально большое количество из них составляют люди в возрасте до 18 лет. Это тот случай, когда значения НЕ отсутствуют случайно. Теперь, если у нас есть несколько пропущенных значений в Genderстолбце из-за проблем с вводом данных, эти значения, скорее всего, будут отсутствовать случайно.
Почему это важно? Если у нас есть пропущенные данные, которые не являются случайными, мы знаем, почему значения отсутствуют, и это можно объяснить набором данных, мы можем просто закодировать это как индикаторную переменную, указывающую. Это позволит модели легко разобраться в этом. Однако если объяснение того, почему они отсутствуют, не объясняется набором данных, то мы находимся на неясной территории, и рассмотрение такого случая требует более пристального внимания.
Когда данные отсутствуют случайно, мы теряем информацию, но мы надеемся, что сможем заполнить эти пробелы на основе информации из других функций.
Меньшее, что мы можем сделать, — это удалить строки с отсутствующими данными, поскольку большинство моделей не обрабатывают недостающие данные. Поскольку столбцы со слишком большим количеством пропущенных значений обычно не дают полезного сигнала, мы могли бы удалить их на основе порогового условия отсутствия (показано ниже).
Но прежде чем мы заполним пропущенные значения, возможно, будет полезно сначала визуализировать недостающие значения с помощью Seaborn.
plt.figure(figsize=(15, 15)) sns.heatmap(df.isnull(), cbar=False); РЕЗУЛЬТАТ:
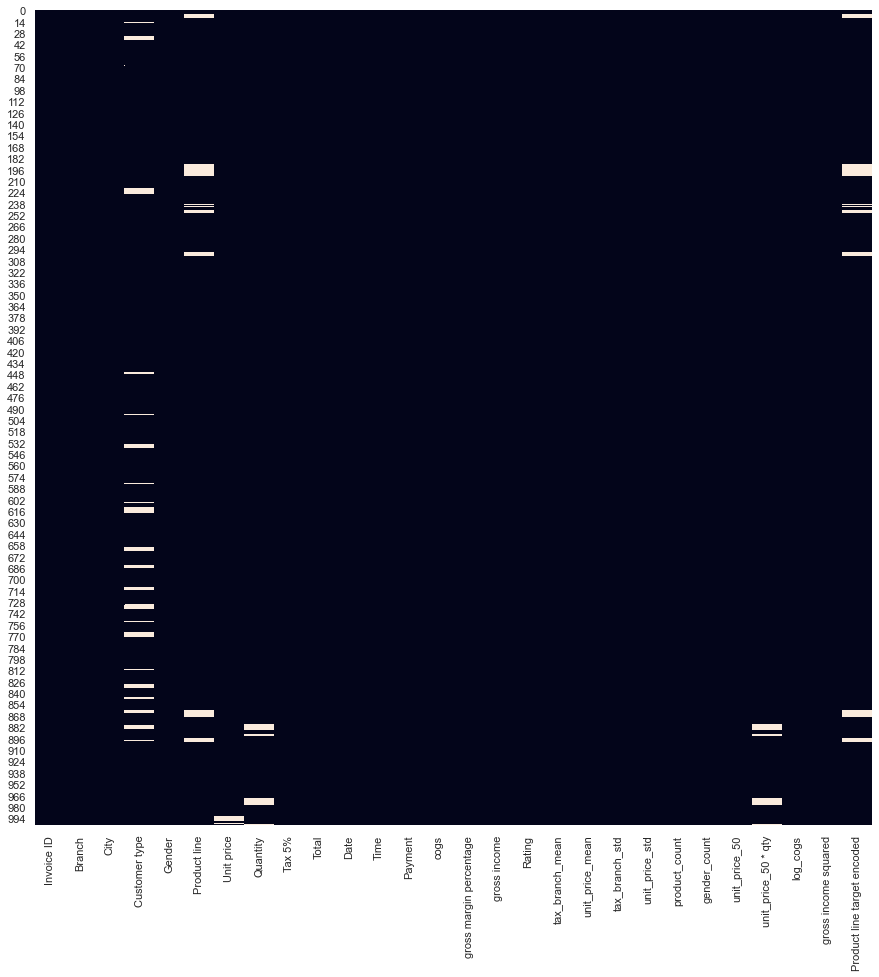
Мы видим, что в нескольких столбцах отсутствуют значения — Customer typeкатегориальный столбец с наибольшим количеством пропущенных значений. Обычно столбцы со слишком большим количеством пропущенных значений не дают достаточного сигнала для прогнозирования, поэтому некоторые специалисты решают удалить эти столбцы, установив порог «отсутствия». В приведенном ниже фрагменте кода мы устанавливаем пороговое значение 70 % и удаляем столбцы и строки, соответствующие этим условиям.
Я не рекомендую эту стратегию — в этих столбцах/строках все еще может быть полезная информация, и я бы позволил процессу выбора функций решить, сохранять или удалять столбцы. В любом случае, если вы просто хотите быстро построить базовую модель, вы можете использовать эту стратегию.
Вот как можно удалить пропущенные значения для определенного порога:
threshold = 0.7 # Dropping columns with missing value rate higher than threshold df = df[df.columns[df.isnull().mean() < threshold]] # Dropping rows with missing value rate higher than threshold df = df.loc[df.isnull().mean(axis=1) < threshold] В качестве альтернативы (предпочтительно) мы можем заменить пропущенные значения одним значением, например средним значением или медианой столбца. Для категориальных столбцов мы могли бы вменить пропущенные значения с помощью режима или наиболее часто встречающейся категории в столбце.
# Filling missing values with medians of the columns df = df.fillna(df.median()) # Fill remaining columns - categorical columns - with mode df = df.apply(lambda x:x.fillna(x.value_counts().index[0])) Теперь мы больше не видим пропущенных значений в наборе данных!
plt.figure(figsize=(15, 15)) sns.heatmap(df.isnull(), cbar=False); РЕЗУЛЬТАТ:

Существуют более сложные методы вменения, выходящие за рамки этой статьи, но этого должно быть достаточно для начала. Если вы заинтересованы в дальнейшем изучении обработки недостающих данных, я настоятельно рекомендую ознакомиться с «Отсутствующими данными» Пола Д. Эллисона.
Разложение даты и времени
Декомпозиция даты и времени представляет собой простое разбиение переменной даты на ее составляющие. Мы делаем это, поскольку модель должна работать с числовыми переменными.
# Convert to datetime object df['Date'] = pd.to_datetime(df['Date']) df[['Date']].head() Вне:
| Дата | |
|---|---|
| 0 | 2019-01-05 |
| 1 | 2019-03-08 |
| 2 | 2019-03-03 |
| 3 | 2019-01-27 |
| 4 | 2019-02-08 |
# Decomposition df['Year'] = df['Date'].dt.year df['Month'] = df['Date'].dt.month df['Day'] = df['Date'].dt.day df[['Year','Month','Day']].head() Вне:
| Год | Месяц | День | |
|---|---|---|---|
| 0 | 2019 год | 1 | 5 |
| 1 | 2019 год | 3 | 8 |
| 2 | 2019 год | 3 | 3 |
| 3 | 2019 год | 1 | 27 |
| 4 | 2019 год | 2 | 8 |
Что мы только что сделали, так это разделили столбец даты, который был в формате «год-месяц-день», на отдельные столбцы, а именно год, месяц и день. Это информация, которую модель теперь может использовать для прогнозирования, поскольку новые столбцы являются числовыми.
Доменный подход
Не существует строгой границы между подходами к разработке функций, основанными на доменах и контрольных списках. Я бы сказал, что это различие весьма субъективно: при использовании предметно-ориентированных функций вы по-прежнему применяете множество методов, которые мы уже обсуждали, но с большим упором на знание предметной области.
Функции, основанные на предметной области, будут включать в себя множество специальных показателей, таких как коэффициенты и формулы. и т. д. Мы увидим примеры этого в примере ниже.
Пример тематического исследования: данные о кассовых сборах фильмов
Теперь, когда мы изучили несколько методов проектирования функций, давайте применим их!
Для нашего тематического исследования мы будем работать с данными о кассовых сборах фильмов. Более подробную информацию о наборе данных можно найти, нажав здесь .
Обычно нашим первым шагом будет проведение исследовательского анализа набора данных, но поскольку эта статья посвящена разработке функций, мы сосредоточимся на этом. Обратите внимание: многие идеи по разработке функций, представленные ниже, были вдохновлены ядром Kaggle, ссылка на которое приведена здесь .
df = pd.read_csv('data/movies.csv') df.head() Вне:
| идентификатор | принадлежит_to_collection | бюджет | жанры | домашняя страница | imdb_id | исходный_язык | original_title | обзор | популярность | ... | Дата выпуска | время выполнения | разговорные языки | положение дел | слоган | заголовок | Ключевые слова | бросать | экипаж | доход | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | [{'id': 313576, 'name': 'Машина времени для гидромассажной ванны... | 14000000 | [{'id': 35, 'name': 'Comedy'}] | НЭН | тт2637294 | ru | Машина времени в гидромассажной ванне 2 | Когда Лу, ставший «отцом In... | 6,575393 | ... | 20.02.15 | 93,0 | [{'iso_639_1': 'en', 'name': 'English'}] | Выпущенный | Законы пространства и времени скоро будут нарушены... | Машина времени в гидромассажной ванне 2 | [{'id': 4379, 'name': 'путешествие во времени'}, {'id': 9... | [{'cast_id': 4, 'персонаж': 'Лу', 'credit_id... | [{'credit_id': '59ac067c92514107af02c8c8', 'де... | 12314651 |
| 1 | 2 | [{'id': 107674, 'name': 'Дневники принцессы... | 40000000 | [{'id': 35, 'name': 'Comedy'}, {'id': 18, 'nam... | НЭН | тт0368933 | ru | Дневники принцессы 2: Королевская помолвка | Миа Термополис сейчас выпускница колледжа и... | 8,248895 | ... | 06.08.04 | 113,0 | [{'iso_639_1': 'en', 'name': 'English'}] | Выпущенный | Чтобы найти настоящую любовь, может потребоваться целая жизнь; она'... | Дневники принцессы 2: Королевская помолвка | [{'id': 2505, 'name': 'коронация'}, {'id': 42... | [{'cast_id': 1, 'character': 'Миа Термополис'... | [{'credit_id': '52fe43fe9251416c7502563d', 'де... | 95149435 |
| 2 | 3 | НЭН | 3300000 | [{'id': 18, 'name': 'Драма'}] | http://sonyclassics.com/whiplash/ | тт2582802 | ru | Хлыстовая травма | Под руководством безжалостного инструктора... | 64,299990 | ... | 10.10.14 | 105,0 | [{'iso_639_1': 'en', 'name': 'English'}] | Выпущенный | Дорога к величию может привести вас к краю. | Хлыстовая травма | [{'id': 1416, 'name': 'джаз'}, {'id': 1523, 'н... | [{'cast_id': 5, 'персонаж': 'Эндрю Нейманн',... | [{'credit_id': '54d5356ec3a3683ba0000039', 'де... | 13092000 |
| 3 | 4 | НЭН | 1200000 | [{'id': 53, 'name': 'Триллер'}, {'id': 18, 'н... | http://kahaanithefilm.com/ | tt1821480 | привет | Кахани | Видья Багчи (Видья Балан) приезжает в Калькутту... | 3,174936 | ... | 09.03.12 | 122,0 | [{'iso_639_1': 'en', 'name': 'English'}, {'iso... | Выпущенный | НЭН | Кахани | [{'id': 10092, 'name': 'тайна'}, {'id': 1054... | [{'cast_id': 1, 'персонаж': 'Видья Багчи', '... | [{'credit_id': '52fe48779251416c9108d6eb', 'де... | 16000000 |
| 4 | 5 | НЭН | 0 | [{'id': 28, 'name': 'Действие'}, {'id': 53, 'название... | НЭН | тт1380152 | ко | ???? | Морской пехотинец — это история бывшего национального солдата... | 1,148070 | ... | 05.02.09 | 118,0 | [{'iso_639_1': 'ко', 'имя': '???/???'}] | Выпущенный | НЭН | Морской мальчик | НЭН | [{'cast_id': 3, 'персонаж': 'Чон Су', 'кредит... | [{'credit_id': '52fe464b9251416c75073b43', 'де... | 3923970 |
5 строк x 23 столбца
Заполнение пропущенных значений
Сначала давайте обработаем пропущенные значения. Мы визуализируем их с помощью Seaborn, а затем заполняем числовые недостающие значения медианой и категориальные недостающие значения с помощью режима.
plt.figure(figsize=(15, 15)) sns.heatmap(df.isnull(), cbar=False); РЕЗУЛЬТАТ:
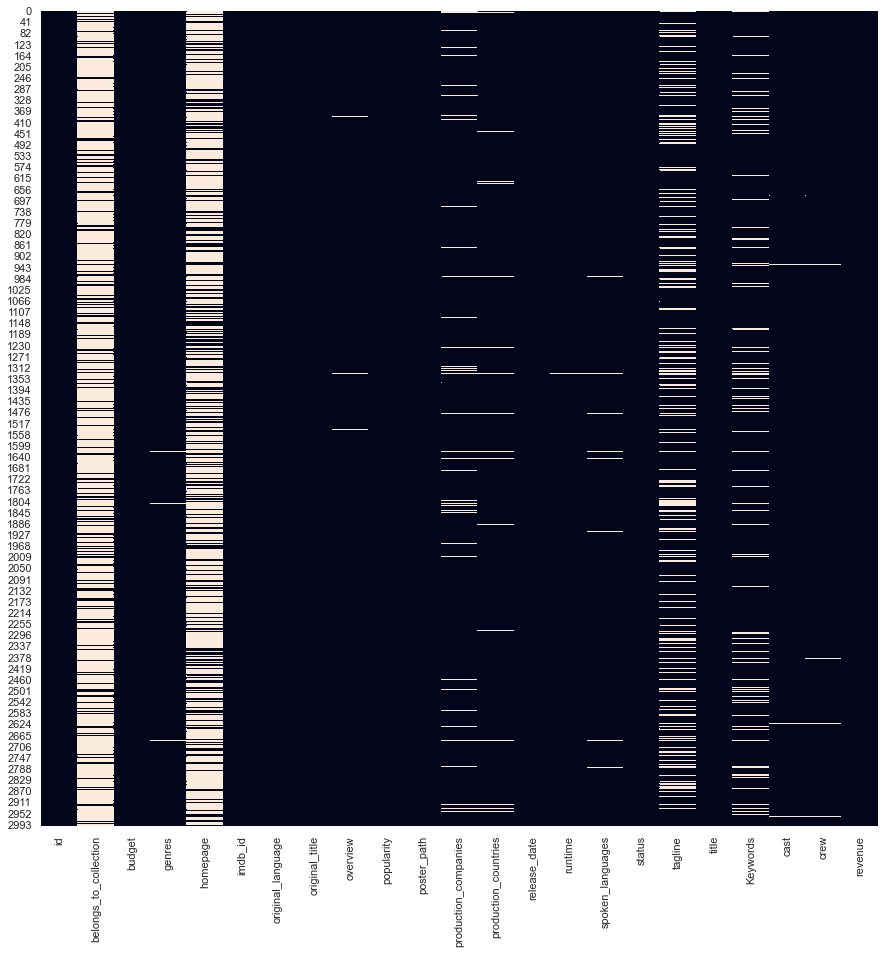
Мы заполним недостающие числовые переменные медианой и категориальный столбец модой. Мы займемся категориальными пропущенными значениями после того, как завершим разработку функций других столбцов (в самом конце).
Выбор метода вменения пропущенных значений не является сложной наукой. Большинство практиков тестируют несколько методов вменения пропущенных значений и выбирают тот, который получает лучший оценочный балл.
Разложение даты
И теперь мы можем разложить столбец даты по его атрибутам. Обратите внимание, что мы кодируем месяц и день как строковые переменные, поскольку внутри них нет числовых связей. Дни и месяцы имеют фиксированные границы (месяц не превышает 12, день не превышает 31). День 10 и 31 — это просто разные дни (считайте их категориями).
Давайте поместим год, месяц и день в отдельные столбцы в кадре данных:
df['release_date'] = pd.to_datetime(df['release_date']) # decomposition df['Year'] = df['release_date'].dt.year df['Month'] = df['release_date'].dt.month.astype(str) df['Day'] = df['release_date'].dt.day.astype(str) df[['Year','Month','Day']].head() Вне:
| Год | Месяц | День | |
|---|---|---|---|
| 0 | 2015 год | 2 | 20 |
| 1 | 2004 г. | 8 | 6 |
| 2 | 2014 год | 10 | 10 |
| 3 | 2012 год | 3 | 9 |
| 4 | 2009 год | 2 | 5 |
Корректировка бюджета
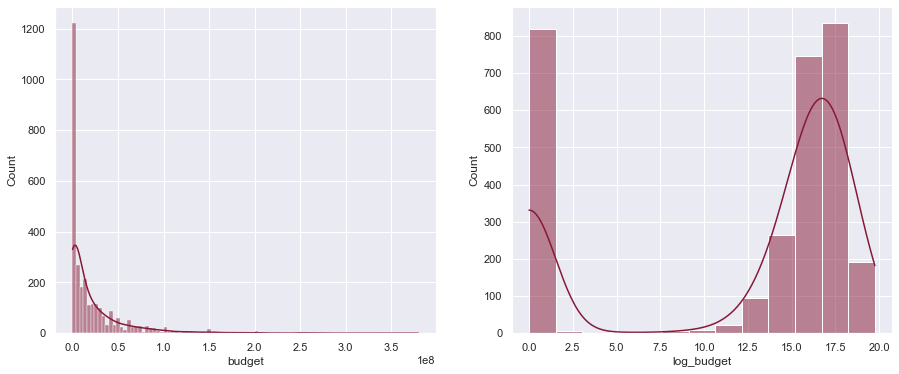
Поскольку бюджет сильно искажен вправо, мы берем логарифм бюджета, чтобы скорректировать его. Обратите внимание, что мы берем логарифм, budget + 1поскольку у многих фильмов бюджет равен 0 долларов, и мы не можем взять логарифм 0.
df['log_budget'] = np.log(df['budget'] + 1) plot_hist(df['budget'], df['log_budget']) РЕЗУЛЬТАТ:
Кодирование инфляции
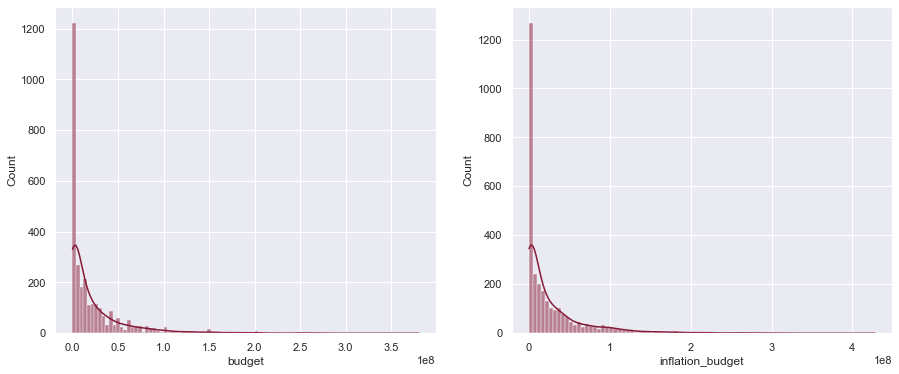
Мы знаем, что бюджет ежегодно увеличивается в некоторой степени из-за инфляции. Мы можем закодировать это, используя простую формулу инфляции следующим образом:
Гдекаждая строка и
— максимальный год набора данных (в нашем случае 2018 год). Вот его создание для нашего фрейма данных:
df['inflation_budget'] = df['budget'] * (1 + (1.8 / 100) * (2018 - df['Year'])) plot_hist(df['budget'], df['inflation_budget']) РЕЗУЛЬТАТ:
Другие интересные особенности
Основываясь на знаниях предметной области, мы можем создать несколько полезных переменных соотношения, как показано ниже.
df['budget_runtime_ratio'] = df['budget'] / df['runtime'] df['budget_popularity_ratio'] = df['budget'] / df['popularity'] df['budget_year_ratio'] = df['budget'] / (df['Year'] * df['Year']) df['releaseYear_popularity_ratio'] = df['Year'] / df['popularity'] Индикаторные переменные
Мы кодируем индикаторную переменную, указывающую, есть ли у фильма домашняя страница или нет, и был ли фильм на английском языке:
# Has a homepage df['has_homepage'] = 1 df.loc[pd.isnull(df['homepage']), "has_homepage"] = 0 # Was in English df['is_english'] = np.where(df['original_language']=='en', 1, 0) И теперь мы можем заполнить недостающие значения категориального столбца.
# Fill remaining columns - categorical columns - with mode df = df.apply(lambda x: x.fillna(x.value_counts().index[0])) Мы подустанавливаем фрейм данных, чтобы включить только те переменные, которые нам нужны.
engineered_df = df[['budget_runtime_ratio', 'budget_popularity_ratio', 'budget_year_ratio', 'releaseYear_popularity_ratio', 'inflationBudget', 'Year', 'Month', 'is_english', 'has_homepage', 'budget', 'popularity', 'runtime', 'revenue']] Мы оперативно кодируем категориальные столбцы. В нашем случае у нас есть только один категориальный столбец — месяц.
engineered_df = engineered_df.replace([np.inf, -np.inf], np.nan).dropna(axis=1) engineered_df = pd.get_dummies(engineered_df) Наш новый фрейм данных выглядит так
engineered_df.head() Вне:
| Budget_popularity_ratio | Budget_year_ratio | ReleaseYear_popularity_ratio | инфляцияБюджет | Год | is_english | has_homepage | бюджет | популярность | время выполнения | ... | Месяц_11 | Месяц_12 | Месяц_2 | Месяц_3 | Месяц_4 | Месяц_5 | Месяц_6 | Месяц_7 | Месяц_8 | Месяц_9 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2.129150e+06 | 3,448085 | 306.445562 | 14756000.0 | 2015 год | 1 | 0 | 14000000 | 6,575393 | 93,0 | ... | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 4.849134e+06 | 9.960120 | 242,941630 | 50080000.0 | 2004 г. | 1 | 0 | 40000000 | 8,248895 | 113,0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 |
| 2 | 5.132194e+04 | 0,813570 | 31.321933 | 3537600.0 | 2014 год | 1 | 1 | 3300000 | 64,299990 | 105,0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 3 | 3.779604e+05 | 0,296432 | 633.713561 | 1329600.0 | 2012 год | 0 | 1 | 1200000 | 3,174936 | 122,0 | ... | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| 4 | 0,000000е+00 | 0,000000 | 1749.893299 | 0,0 | 2009 год | 0 | 0 | 0 | 1,148070 | 118,0 | ... | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
5 строк x 23 столбца
Теперь, когда наш набор данных готов, мы можем пройти процесс выбора полезных функций (выбора функций) и сделать прогнозы.
Прогноз
Чтобы доказать, что разработка функций работает и повышает производительность модели, мы можем построить простую регрессионную модель для прогнозирования доходов от фильмов.
Обычно мы выбираем, какие функции использовать, с помощью процесса, называемого выбором функций, однако, поскольку эта статья посвящена разработке функций, мы будем использовать простой процесс выбора функций: корреляционный анализ .
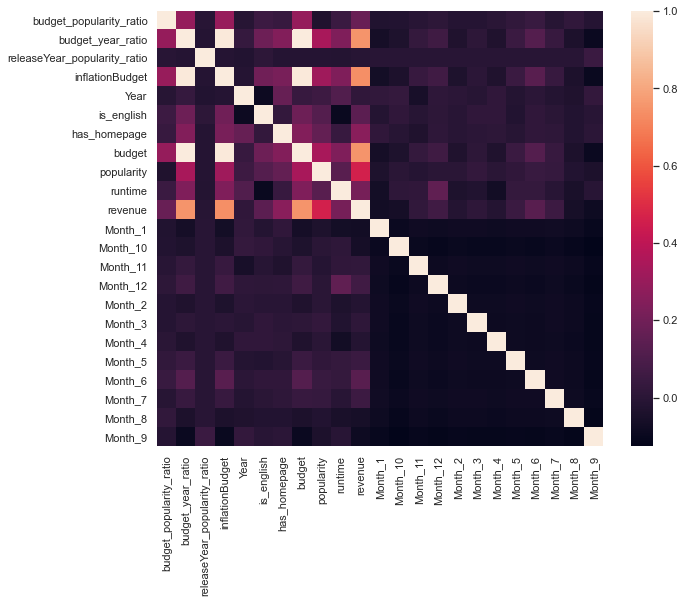
Построив корреляционную матрицу (ниже), мы видим, что большинство созданных нами функций не позволяют прогнозировать доход. Именно это происходит в большинстве случаев: вы создаете массу функций, но лишь немногие из них оказываются полезными, но те функции, которые полезны, имеют значение.
На графике ниже мы будем использовать has_homepage, budget_year_ratio, и is_englishв нашей модели, в дополнение к функциям, которые появились до разработки функций - budget, runtimeи popularity.
plt.figure(figsize=(10, 8)) sns.heatmap(engineered_df.corr()); РЕЗУЛЬТАТ:
Мы будем использовать примерно 80% набора данных для обучения базовых и функциональных моделей и сравнивать их производительность на скрытом тестовом наборе.
train_engineered = engineered_df[['budget','runtime','popularity', 'has_homepage','budget_year_ratio','is_english']].iloc[:2500] train_baseline = engineered_df[['budget','runtime','popularity']].iloc[:2500] test_engineered = engineered_df[['budget','runtime','popularity', 'has_homepage','budget_year_ratio','is_english']].iloc[2500:] test_baseline = engineered_df[['budget','runtime','popularity']].iloc[2500:] target_train = engineered_df['revenue'].iloc[:2500] target_test = engineered_df['revenue'].iloc[2500:] reg_baseline = LinearRegression().fit(train_baseline, target_train) reg_predict_baseline = reg_baseline.predict(test_baseline) reg_engineered = LinearRegression().fit(train_engineered, target_train) reg_predict_engineered = reg_engineered.predict(test_engineered) rmse_baseline = np.sqrt(mean_squared_error(target_test, reg_predict_baseline)) rmse_engineered = np.sqrt(mean_squared_error(target_test, reg_predict_engineered)) rmse_difference = rmse_baseline - rmse_engineered print ("The difference in RMSE is", round(rmse_difference, 2), "dollars") Вне:
The difference in RMSE is 909146.83 dollars Разница весьма существенная! Прогнозы базовой модели, которая использует только и в качестве функций, в среднем на 909 146,83 доллара хуже, чем у модели, в которой мы использовали наши построенные функции budget. Мы пришли к такому выводу, сравнив среднеквадратическую ошибку (RMSE) обеих моделей на тестовом наборе.runtimepopularity
Используя разработку функций, мы позволили нашей модели лучше понять наш набор данных и, следовательно, сделать более точные прогнозы.
Заключение
Подводные камни при проектировании функций
Некоторые из распространенных ошибок при разработке функций:
- Переобучение. Когда мы создаем слишком много функций, мы рискуем переобучить данные. Это часто называют проклятием размерности . Короче говоря, чем больше функций имеет модель, тем больше гибкости она должна устанавливать взаимосвязи между предиктором и целевой переменной. Это может звучать хорошо, но если модель обладает слишком большой гибкостью, она в некотором смысле будет чрезмерно оптимизировать данные, на которых она обучена. Это приведет к получению высокой производительности, но будет плохо работать со скрытыми данными или новыми данными, поскольку новые данные будут иметь различия, не наблюдаемые в обучающих данных. Мы должны помнить об этом и учитывать выборочное тестирование при оценке функций (на этапе выбора функций).
- Утечка информации: если разработка функций не выполнена должным образом, это может привести к утечке информации. Обычно это включает в себя создание новых функций с использованием целевой переменной. Разработка признаков всегда должна выполняться независимо от целевой переменной и должна включать только интересующие переменные-предикторы.
Мышление разработки функций
Подход к разработке функций очень экспериментальный. Обычно количество ценится выше качества. Качество играет важную роль, когда мы имеем дело с выбором функций, который происходит после разработки функций. У нас может быть какое-то указание относительно того, какие функции могут быть полезны, но мы не должны позволять нашей предвзятости вступать в игру — создайте как можно больше подходящих функций на основе ваших данных (конечно, если позволяют вычисления и время) и дополните их с помощью надежной функции. процесс отбора, чтобы отсеять плохие черты.
Дальнейшее обучение:
Многие курсы по науке о данных и машинному обучению содержат разделы, посвященные разработке функций. Вот отличный курс, который стоит попробовать:
Источник: www.learndatasci.com