Практическое трансферное обучение с использованием Keras и модели VGG16
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2024-03-06 14:34

В предыдущей статье мы представили основы классификации изображений с помощью Keras , где мы создали CNN для классификации изображений еды. Наша модель показала себя не очень хорошо, но мы можем значительно повысить точность, не тратя много времени на обучение, используя концепцию под названием Transfer Learning.
К концу этой статьи вы сможете:
- Загрузите предварительно обученную модель из Keras для трансферного обучения.
- Точная настройка предварительно обученной модели на основе пользовательского набора данных.
Давайте начнем.
Что такое трансферное обучение?
В предыдущей статье мы определили нашу собственную сверточную нейронную сеть и обучили ее на наборе данных изображений продуктов питания. Мы увидели, что производительность этой модели, созданной с нуля, была резко ограничена.
Эта модель должна была сначала научиться обнаруживать общие особенности на изображениях, такие как края и цветные пятна, прежде чем обнаруживать более сложные особенности.
В реальных приложениях для достижения высокой производительности могут потребоваться дни обучения и миллионы изображений. Нам было бы проще загрузить общую предварительно обученную модель и переобучить ее на нашем собственном наборе данных. Вот что влечет за собой трансферное обучение.
Таким образом, трансферное обучение — это подход, при котором мы используем одну модель, обученную для выполнения задачи машинного обучения, и повторно используем ее в качестве отправной точки для другой работы. Этот подход используется во многих областях глубокого обучения, включая классификацию изображений, обработку естественного языка и даже игры! Возможность адаптировать обученную модель под другую задачу невероятно ценна.
Обзор CNN
В этом руководстве предполагается, что вы имеете представление о сверточных нейронных сетях. Если вы хотите более подробно изучить эти сети, прочтите нашу предыдущую статью.
В этом разделе мы рассмотрим строительные блоки CNN. Не стесняйтесь пропустить реализацию Python.
Архитектура сверточной нейронной сети

Рис. 1. Графическое представление архитектуры CNN.

Напомним, что архитектура CNN содержит некоторые важные строительные блоки, такие как:
1. Сверточный слой:
- Конв. Слои будут вычислять выходные данные узлов, которые подключены к локальным областям входной матрицы.
- Скалярное произведение вычисляется между набором весов (обычно называемым фильтром) и значениями, связанными с локальной областью входных данных.
2. Слой ReLu (активация):
- Выходной объем Conv. Слой передается поэлементной функции активации, обычно выпрямленно-линейной единице (ReLu).
- Уровень ReLu будет определять, будет ли входной узел «срабатывать» с учетом входных данных. Это «срабатывание» сигнализирует о том, обнаружили ли фильтры слоя свертки визуальную особенность.
- Функция ReLu будет применять
- функция, пороговое значение равно 0.
- Размеры тома оставляем без изменений.
3. Уровень объединения:
- Для уменьшения ширины и высоты выходного тома применяется стратегия понижающей дискретизации.
4. Полносвязный слой:
- Выходной объем, то есть «свернутые объекты», передаются на полностью связанный уровень узлов.
- Как и в обычных нейронных сетях, каждый узел в этом слое связан с каждым узлом в объеме передаваемых признаков.
- Вероятности классов вычисляются и выводятся в трехмерном массиве (выходной слой) с размерами:
[1 x 1 x K], где K — количество классов.
Написание моделей такого типа с нуля может быть невероятно сложным, особенно если у нас нет набора данных достаточного размера. Модель CNN, которую мы обсудим позже в этой статье, была предварительно обучена на миллионах фотографий! Мы рассмотрим, как можно использовать предварительно обученную архитектуру для решения нашей задачи пользовательской классификации.
Прогнозирование этикеток продуктов питания с помощью Keras CNN
Изначально мы написали простую CNN с нуля. Мы загрузим ту же модель, что и раньше, чтобы сгенерировать некоторые прогнозы и рассчитать ее точность, которая будет использоваться для сравнения производительности новой модели с использованием трансферного обучения.
"""Load the written-from-scratch cnn""" from keras.models import load_model scratch_model = load_model('scratch_img_model.hdf5') scratch_model.summary() Вне:
Model: "sequential" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= conv2d (Conv2D) (None, 128, 128, 32) 896 _________________________________________________________________ conv2d_1 (Conv2D) (None, 126, 126, 32) 9248 _________________________________________________________________ max_pooling2d (MaxPooling2D) (None, 63, 63, 32) 0 _________________________________________________________________ dropout (Dropout) (None, 63, 63, 32) 0 _________________________________________________________________ conv2d_2 (Conv2D) (None, 63, 63, 64) 18496 _________________________________________________________________ conv2d_3 (Conv2D) (None, 61, 61, 64) 36928 _________________________________________________________________ max_pooling2d_1 (MaxPooling2 (None, 30, 30, 64) 0 _________________________________________________________________ dropout_1 (Dropout) (None, 30, 30, 64) 0 _________________________________________________________________ conv2d_4 (Conv2D) (None, 30, 30, 128) 73856 _________________________________________________________________ conv2d_5 (Conv2D) (None, 28, 28, 128) 147584 _________________________________________________________________ activation (Activation) (None, 28, 28, 128) 0 _________________________________________________________________ max_pooling2d_2 (MaxPooling2 (None, 14, 14, 128) 0 _________________________________________________________________ dropout_2 (Dropout) (None, 14, 14, 128) 0 _________________________________________________________________ conv2d_6 (Conv2D) (None, 14, 14, 512) 1638912 _________________________________________________________________ conv2d_7 (Conv2D) (None, 10, 10, 512) 6554112 _________________________________________________________________ max_pooling2d_3 (MaxPooling2 (None, 2, 2, 512) 0 _________________________________________________________________ dropout_3 (Dropout) (None, 2, 2, 512) 0 _________________________________________________________________ flatten (Flatten) (None, 2048) 0 _________________________________________________________________ dense (Dense) (None, 1024) 2098176 _________________________________________________________________ dropout_4 (Dropout) (None, 1024) 0 _________________________________________________________________ dense_1 (Dense) (None, 10) 10250 ================================================================= Total params: 10,588,458 Trainable params: 10,588,458 Non-trainable params: 0 _________________________________________________________________ Наша CNN, созданная с нуля, имеет относительно простую архитектуру: 7 сверточных слоев, за которыми следует один плотносвязный слой.
Используя старую CNN для расчета показателя точности (подробности о котором вы можете найти в предыдущей статье ), мы обнаружили, что у нас показатель точности составляет ~58% .
С таким показателем точности CNN, созданная с нуля, работает в лучшем случае умеренно хорошо. Мы могли бы повысить точность с помощью набора обучающих данных достаточного размера, которого у нас нет.
На практике вам следует писать CNN с нуля, только если у вас большой набор данных. В этом уроке мы загрузим предварительно обученную модель и повторно обучим ее на нашем собственном наборе данных, чтобы создать лучшую модель.
Как работает трансферное обучение?
Трансферное обучение частично устраняет ограничения парадигмы изолированного обучения :
«В настоящее время доминирующей парадигмой МО является запуск алгоритма МО на заданном наборе данных для создания модели. Затем модель применяется в реальных задачах. Мы называем эту парадигму изолированным обучением, потому что она не учитывает какую-либо другую связанную информацию или знания, полученные в прошлом». ( Лю, 2016 )
Трансферное обучение дает нам возможность использовать изученные функции в различных учебных задачах.
Домены и задачи
Мы можем понимать трансферное обучение с точки зрения областей и задач . В нашем случае областью деятельности является классификация изображений, а наша задача — классифицировать изображения продуктов питания. Как и раньше, запуск с нуля потребует множества оптимизаций, большего количества данных и более длительного обучения для повышения производительности. Если мы используем CNN, которая уже оптимизирована и обучена для аналогичной области и задачи, мы можем преобразовать ее для работы с нашей задачей. Именно этого и добивается трансферное обучение.
Мы будем использовать предварительно обученную модель VGG16, которая представляет собой сверточную нейронную сеть, обученную на 1,2 миллионах изображений для классификации 1000 различных категорий. Поскольку домен и задача для VGG16 аналогичны нашему домену и задаче, мы можем использовать его предварительно обученную сеть для выполнения этой работы.
Подробности о более математическом определении см. в статье Улучшение классификации эмоций на основе ЭЭГ с использованием обучения с условным переносом .
Использование предварительно обученных сверточных слоев
Наш подход к трансферному обучению будет включать использование слоев, предварительно обученных на исходной задаче, для решения целевой задачи . Обычно мы загружаем некоторую предварительно обученную модель и «отрезаем» ее верхнюю часть (полностью связный слой), оставляя нам только сверточные слои и слои пула.
Используя предварительно обученные слои, мы извлечем визуальные функции из нашей целевой задачи/набора данных .
При использовании этих предварительно обученных слоев мы можем решить заморозить обучение определенных слоев. Мы будем использовать предварительно обученные веса по мере их поступления и не обновлять их с помощью обратного распространения ошибки.
В качестве альтернативы мы можем заморозить большинство предварительно обученных слоев, но разрешить другим слоям обновлять свои веса, чтобы улучшить классификацию целевых данных .
Как использовать модель VGG16
VGG16 — это сверточная нейронная сеть, обученная на подмножестве набора данных ImageNet , коллекции из более чем 14 миллионов изображений, относящихся к 22 000 категориям. К. Симоньян и А. Зиссерман предложили эту модель в статье 2015 года « Очень глубокие сверточные сети для крупномасштабного распознавания изображений ».
В конкурсе ImageNet Classification Challenge 2014 года VGG16 достиг точности классификации 92,7%. Но что еще более важно, он был обучен на миллионах изображений. Его предварительно обученная архитектура может обнаруживать общие визуальные особенности, присутствующие в нашем наборе данных о продуктах питания.
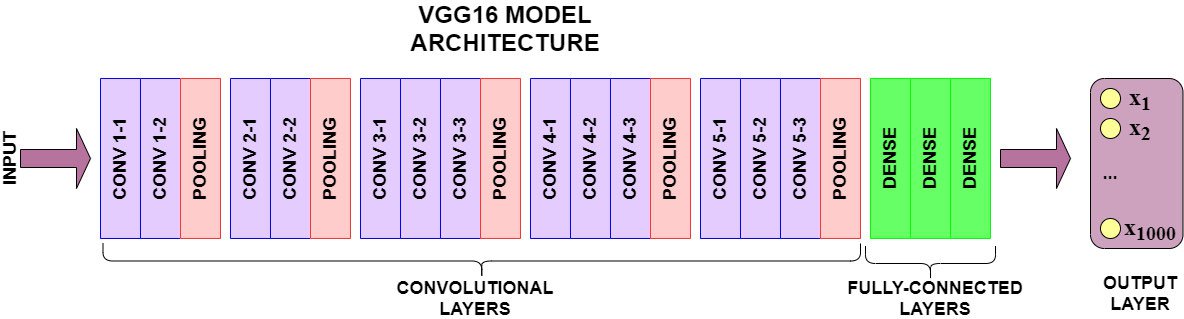
Рис. 2. Модель VGG16 имеет 16 сверточных слоев и слоев максимального пула, 3 плотных слоя для полностью связанного слоя и выходной слой из 1000 узлов.

Теперь предположим, что у нас есть много изображений двух типов автомобилей: спортивных автомобилей Ferrari и легковых автомобилей Audi. Мы хотим создать модель, которая сможет классифицировать изображение как один из двух классов. Написание собственной CNN не является вариантом, поскольку у нас нет достаточного по размеру набора данных. Вот тут-то и приходит на помощь трансферное обучение!
Мы знаем , что набор данных ImageNet содержит изображения различных транспортных средств (спортивных автомобилей, пикапов, минивэнов и т. д.). Мы можем импортировать модель, предварительно обученную на наборе данных ImageNet, и использовать ее предварительно обученные слои для извлечения признаков.
Теперь мы не можем использовать всю архитектуру предварительно обученной модели. Слой Fully-Connected генерирует 1000 различных выходных меток, тогда как наш целевой набор данных имеет только два класса для прогнозирования. Итак, мы импортируем предварительно обученную модель, такую как VGG16 , но «отрежем» слой Fully-Connected, также называемый «верхней» моделью.
После импорта предварительно обученных слоев, за исключением «верхней части» модели, мы можем использовать один из двух подходов к трансферному обучению.
1. Подход к извлечению функций
В этом подходе мы используем архитектуру предварительно обученной модели для создания нового набора данных из наших входных изображений. Мы импортируем слои Convolutional и Pooling, но оставим «верхнюю часть» модели (полностью связанный слой).
Напомним, что наша модель VGG16 была обучена на миллионах изображений, включая изображения транспортных средств. Его сверточные слои и обученные веса могут обнаруживать общие функции, такие как края, цвета, колеса, лобовые стекла и т. д.
Мы пропустим наши изображения через сверточные слои VGG16, которые выведут стек обнаруженных визуальных функций. Отсюда легко объединить трехмерный стек функций в массив NumPy, готовый к любому моделированию, которое вы предпочитаете проводить.
Рис. 3. На рисунке выше показана удаленная «верхняя» часть модели. Модель свертывает предварительно обученные выходные слои в виде трехмерного стека карт объектов.
Мы можем выполнить извлечение признаков следующим образом:
- Загрузите предварительно обученную модель. Убедитесь, что «верхняя» часть модели — полностью связанный слой — не включена.
- Пропустите данные изображения через предварительно обученные слои, чтобы извлечь свернутые визуальные особенности.
- Выведенный стек признаков будет трехмерным, и чтобы его можно было использовать для прогнозирования другими классификаторами машинного обучения, его необходимо сгладить.
- На этом этапе у вас есть два варианта:
- Автономный экстрактор : в этом сценарии вы можете использовать предварительно обученные слои для однократного извлечения функций изображения. Извлеченные объекты затем создадут новый набор данных, который не требует какой-либо обработки изображений.
- Bootstrap Extractor : напишите свой собственный полностью связанный слой и интегрируйте его с предварительно обученными слоями. В этом смысле вы загружаете свою собственную «топ-модель» на предварительно обученные слои. Инициализируйте этот полностью связный слой со случайными весами, которые будут обновляться посредством обратного распространения ошибки во время обучения.
В этой статье будет показано, как реализовать «загрузочное» извлечение данных изображения с помощью VGG16 CNN. Предварительно обученные слои будут свертывать данные изображения в соответствии с весами ImageNet. Мы загрузим полностью связанный слой для генерации прогнозов.
2. Подход тонкой настройки
В этом подходе мы используем стратегию под названием «Точная настройка» . Цель тонкой настройки — позволить части предварительно обученных слоев переобучиться.
В предыдущем подходе мы использовали предварительно обученные слои VGG16 для извлечения признаков. Мы передали наш набор данных изображений через сверточные слои и веса, выведя преобразованные визуальные функции. Фактического обучения на этих предварительно обученных слоях не проводилось.
Точная настройка предварительно обученной модели включает в себя:
- Начальная загрузка новой «верхней» части модели (т. е. полностью подключенного и выходного слоев)
- Замораживание предварительно обученных сверточных слоев
- Разморозка последних нескольких предварительно обученных слоев тренировки.
Замороженные предварительно обученные слои будут свертывать визуальные элементы, как обычно. Незамороженные (т. е. «обучаемые») предварительно обученные слои будут обучаться на нашем пользовательском наборе данных и обновляться в соответствии с прогнозами полностью связанного слоя.
Рис. 4. В приведенном выше графическом представлении окончательные слои свертки и объединения разморожены, чтобы обеспечить возможность обучения. Полностью подключенный уровень определен для обучения и прогнозирования.
В этой статье мы покажем, как реализовать тонкую настройку на CNN VGG16. Мы загрузим некоторые предварительно обученные слои как «обучаемые», пропустим данные изображения через предварительно обученные слои и «точно настроим» обучаемые слои вместе с нашим полностью подключенным слоем.
Загрузка набора данных
Прежде чем мы продемонстрируем любой из этих подходов, убедитесь, что вы загрузили данные для этого руководства.
Чтобы получить доступ к данным, используемым в этом руководстве, ознакомьтесь со статьей «Классификация изображений с помощью Keras» . В этом разделе вы можете найти команды терминала и функции для разделения данных . Если вы начинаете с нуля, обязательно запустите split_datasetфункцию после загрузки набора данных, чтобы изображения находились в правильных каталогах для этого руководства.
Использование трансферного обучения для классификации продуктов питания
Предварительно обученные модели, такие как VGG16, легко загружаются с помощью API Keras. Мы продолжим использовать VGG16 для обучения, но вам следует изучить и другие доступные модели! Многие из них прошли обучение на наборе данных ImageNet и имеют свои преимущества и недостатки. Список доступных моделей вы можете найти здесь .
preprocess_functionВместе с моделью VGG16 мы также импортировали нечто, называемое a . Напомним, что данные изображения необходимо нормализовать перед тренировкой. Изображения состоят из трехмерных матриц, содержащих числовые значения в диапазоне [0, 255]. Однако не все CNN имеют одинаковую схему нормализации.
Модель VGG16 была обучена на данных, в которых значения пикселей находились в диапазоне от [0, 255], а средние значения пикселей набора данных вычитались из каждого канала изображения.
Другие модели имеют другие схемы нормализации, подробности о которых можно найти в их документации. Некоторые модели требуют масштабирования числовых значений в диапазоне (-1, +1).
Подготовка данных для обучения и тестирования
Давайте сначала импортируем некоторые необходимые библиотеки.
import os from keras.models import Model from keras.optimizers import Adam from keras.applications.vgg16 import VGG16, preprocess_input from keras.preprocessing.image import ImageDataGenerator from keras.callbacks import ModelCheckpoint, EarlyStopping from keras.layers import Dense, Dropout, Flatten from pathlib import Path import numpy as np В предыдущей статье мы определили генераторы изображений ( см. здесь ) для нашего конкретного случая использования. Теперь нам нужно будет использовать функцию предварительной обработки VGG16 для данных нашего изображения.
BATCH_SIZE = 64 train_generator = ImageDataGenerator(rotation_range=90, brightness_range=[0.1, 0.7], width_shift_range=0.5, height_shift_range=0.5, horizontal_flip=True, vertical_flip=True, validation_split=0.15, preprocessing_function=preprocess_input) # VGG16 preprocessing test_generator = ImageDataGenerator(preprocessing_function=preprocess_input) # VGG16 preprocessing С помощью нашего ImageDataGenerator мы теперь можем flow_from_directoryиспользовать тот же каталог изображений, что и в предыдущей статье:
download_dir = Path('<your_directory_here>') train_data_dir = download_dir/'food-101/train' test_data_dir = download_dir/'food-101/test' class_subset = sorted(os.listdir(download_dir/'food-101/images'))[:10] # Using only the first 10 classes traingen = train_generator.flow_from_directory(train_data_dir, target_size=(224, 224), class_mode='categorical', classes=class_subset, subset='training', batch_size=BATCH_SIZE, shuffle=True, seed=42) validgen = train_generator.flow_from_directory(train_data_dir, target_size=(224, 224), class_mode='categorical', classes=class_subset, subset='validation', batch_size=BATCH_SIZE, shuffle=True, seed=42) testgen = test_generator.flow_from_directory(test_data_dir, target_size=(224, 224), class_mode=None, classes=class_subset, batch_size=1, shuffle=False, seed=42) Вне:
Found 6380 images belonging to 10 classes. Found 1120 images belonging to 10 classes. Found 2500 images belonging to 10 classes. Использование предварительно обученных слоев для извлечения признаков
В этом разделе мы покажем, как выполнить трансферное обучение без тонкой настройки предварительно обученных слоев. Вместо этого мы сначала будем использовать предварительно обученные слои для обработки нашего набора данных изображений и извлечения визуальных функций для прогнозирования. Затем мы создаем полносвязный слой и выходной слой для нашего набора данных изображений. Наконец, мы обучим эти слои с помощью обратного распространения ошибки.
В функции вы увидите create_modelразличные компоненты нашей модели трансферного обучения:
- В строке 13 мы присваиваем переменной стек предварительно обученных слоев модели
conv_base. Обратите внимание, чтоinclude_top=Falseнеобходимо исключить предварительно обученный полностью подключенный слой VGG16. - Если в строках 18–25 для аргумента
fine_tuneустановлено значение 0, все предварительно обученные слои будут заморожены и останутся необучаемыми.nВ противном случае для обучения будут доступны последние слои. - В строках 29–30 мы создаем новую «верхнюю» часть модели, захватывая
conv_baseвыходные данные и выравнивая их. - В строках 31–33 мы определяем новый полносвязный слой, который будем обучать с помощью обратного распространения ошибки. Мы включаем регуляризацию отсева, чтобы уменьшить переобучение.
- Строка 34 определяет выходной слой модели, где общее количество выходов равно
n_classes.
Вот create_modelфункция:
def create_model(input_shape, n_classes, optimizer='rmsprop', fine_tune=0): """ Compiles a model integrated with VGG16 pretrained layers input_shape: tuple - the shape of input images (width, height, channels) n_classes: int - number of classes for the output layer optimizer: string - instantiated optimizer to use for training. Defaults to 'RMSProp' fine_tune: int - The number of pre-trained layers to unfreeze. If set to 0, all pretrained layers will freeze during training """ # Pretrained convolutional layers are loaded using the Imagenet weights. # Include_top is set to False, in order to exclude the model's fully-connected layers. conv_base = VGG16(include_top=False, weights='imagenet', input_shape=input_shape) # Defines how many layers to freeze during training. # Layers in the convolutional base are switched from trainable to non-trainable # depending on the size of the fine-tuning parameter. if fine_tune > 0: for layer in conv_base.layers[:-fine_tune]: layer.trainable = False else: for layer in conv_base.layers: layer.trainable = False # Create a new 'top' of the model (i.e. fully-connected layers). # This is 'bootstrapping' a new top_model onto the pretrained layers. top_model = conv_base.output top_model = Flatten(name="flatten")(top_model) top_model = Dense(4096, activation='relu')(top_model) top_model = Dense(1072, activation='relu')(top_model) top_model = Dropout(0.2)(top_model) output_layer = Dense(n_classes, activation='softmax')(top_model) # Group the convolutional base and new fully-connected layers into a Model object. model = Model(inputs=conv_base.input, outputs=output_layer) # Compiles the model for training. model.compile(optimizer=optimizer, loss='categorical_crossentropy', metrics=['accuracy']) return model Обучение без тонкой настройки
Теперь мы определим параметры аналогично первой статье, но с большей формой ввода. Дальше создадим модель без доработок:
input_shape = (224, 224, 3) optim_1 = Adam(learning_rate=0.001) n_classes=10 n_steps = traingen.samples // BATCH_SIZE n_val_steps = validgen.samples // BATCH_SIZE n_epochs = 50 # First we'll train the model without Fine-tuning vgg_model = create_model(input_shape, n_classes, optim_1, fine_tune=0) Наша скомпилированная модель содержит предварительно обученные веса и слои VGG16. В данном случае мы выбрали параметр set fine_tune=0, который заморозит все предварительно обученные слои.
Эта модель будет выполнять извлечение признаков с использованием замороженных предварительно обученных слоев и обучать полностью связанный слой для прогнозирования. Дополнительную информацию об используемых обратных вызовах и параметрах подгонки см. в этом разделе предыдущей статьи.
from livelossplot.inputs.keras import PlotLossesCallback plot_loss_1 = PlotLossesCallback() # ModelCheckpoint callback - save best weights tl_checkpoint_1 = ModelCheckpoint(filepath='tl_model_v1.weights.best.hdf5', save_best_only=True, verbose=1) # EarlyStopping early_stop = EarlyStopping(monitor='val_loss', patience=10, restore_best_weights=True, mode='min') Теперь мы можем обучить модель, определенную выше:
%%time vgg_history = vgg_model.fit(traingen, batch_size=BATCH_SIZE, epochs=n_epochs, validation_data=validgen, steps_per_epoch=n_steps, validation_steps=n_val_steps, callbacks=[tl_checkpoint_1, early_stop, plot_loss_1], verbose=1) РЕЗУЛЬТАТ:
Вне:
accuracy training (min: 0.307, max: 0.628, cur: 0.628) validation (min: 0.439, max: 0.617, cur: 0.597) Loss training (min: 1.070, max: 16.712, cur: 1.087) validation (min: 1.151, max: 1.559, cur: 1.224) 99/99 [==============================] - 110s 1s/step - loss: 1.0867 - accuracy: 0.6284 - val_loss: 1.2235 - val_accuracy: 0.5965 Wall time: 52min 7s # Generate predictions vgg_model.load_weights('tl_model_v1.weights.best.hdf5') # initialize the best trained weights true_classes = testgen.classes class_indices = traingen.class_indices class_indices = dict((v,k) for k,v in class_indices.items()) vgg_preds = vgg_model.predict(testgen) vgg_pred_classes = np.argmax(vgg_preds, axis=1) from sklearn.metrics import accuracy_score vgg_acc = accuracy_score(true_classes, vgg_pred_classes) print("VGG16 Model Accuracy without Fine-Tuning: {:.2f}%".format(vgg_acc * 100)) Вне:
VGG16 Model Accuracy without Fine-Tuning: 73.24% Использование предварительно обученных слоев для точной настройки
Ух ты! Какое улучшение по сравнению с нашим пользовательским CNN! Интеграция предварительно обученных слоев VGG16 с инициализированным полностью подключенным слоем позволила достичь точности 73% ! Но как мы можем добиться большего?
В следующем разделе мы перекомпилируем модель, но разрешим обратное распространение ошибки для обновления двух последних предварительно обученных слоев.
Вы заметите, что мы скомпилировали эту модель точной настройки с более низкой скоростью обучения, что поможет полностью связанному слою «разогреться» и изучить ранее изученные надежные шаблоны, прежде чем выделять более мелкие детали изображения.
Как и прежде, мы инициализируем наш полностью связанный слой и его веса для обучения.
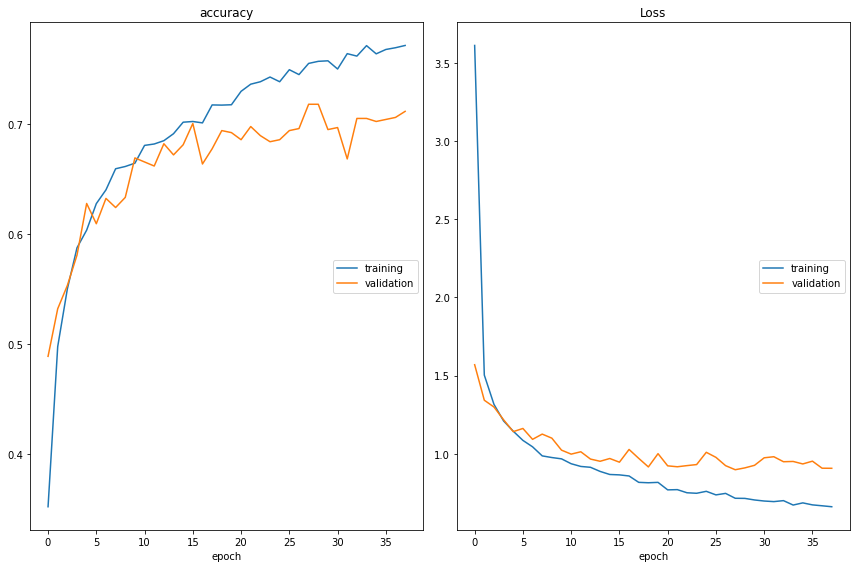
# Reset our image data generators traingen.reset() validgen.reset() testgen.reset() # Use a smaller learning rate optim_2 = Adam(lr=0.0001) # Re-compile the model, this time leaving the last 2 layers unfrozen for Fine-Tuning vgg_model_ft = create_model(input_shape, n_classes, optim_2, fine_tune=2) %%time plot_loss_2 = PlotLossesCallback() # Retrain model with fine-tuning vgg_ft_history = vgg_model_ft.fit(traingen, batch_size=BATCH_SIZE, epochs=n_epochs, validation_data=validgen, steps_per_epoch=n_steps, validation_steps=n_val_steps, callbacks=[tl_checkpoint_1, early_stop, plot_loss_2], verbose=1) РЕЗУЛЬТАТ:
Вне:
accuracy training (min: 0.352, max: 0.771, cur: 0.771) validation (min: 0.489, max: 0.718, cur: 0.711) Loss training (min: 0.661, max: 3.611, cur: 0.661) validation (min: 0.898, max: 1.569, cur: 0.907) 99/99 [==============================] - 110s 1s/step - loss: 0.6611 - accuracy: 0.7712 - val_loss: 0.9069 - val_accuracy: 0.7114 Wall time: 1h 12min 19s ![]()
# Generate predictions vgg_model_ft.load_weights('tl_model_v1.weights.best.hdf5') # initialize the best trained weights vgg_preds_ft = vgg_model_ft.predict(testgen) vgg_pred_classes_ft = np.argmax(vgg_preds_ft, axis=1) vgg_acc_ft = accuracy_score(true_classes, vgg_pred_classes_ft) print("VGG16 Model Accuracy with Fine-Tuning: {:.2f}%".format(vgg_acc_ft * 100)) Вне:
VGG16 Model Accuracy with Fine-Tuning: 81.52% Точность 81% ! Удивительно, как разморозка последних сверточных слоев может повлиять на производительность модели. Давайте лучше поймем, как наши различные модели показали себя при классификации данных.
Сравнение моделей
Помимо сравнения моделей, созданных в этой статье, мы также хотим сравнить пользовательскую модель из последней статьи. В начале этой статьи мы загрузили полученные веса модели с нуля, поэтому нам нужно сделать прогнозы для сравнения с моделями трансферного обучения.
Поскольку наша последняя модель имела другой целевой размер изображения, сначала нам нужно создать новый ImageDataGenerator для прогнозирования. Вот этот код:
# Loading predictions from last article's model test_generator = ImageDataGenerator(rescale=1/255.) testgen = test_generator.flow_from_directory(download_dir/'food-101/test', target_size=(128, 128), batch_size=1, class_mode=None, classes=class_subset, shuffle=False, seed=42) scratch_preds = scratch_model.predict(testgen) scratch_pred_classes = np.argmax(scratch_preds, axis=1) scratch_acc = accuracy_score(true_classes, scratch_pred_classes) print("From Scratch Model Accuracy with Fine-Tuning: {:.2f}%".format(scratch_acc * 100)) Вне:
Found 2500 images belonging to 10 classes. From Scratch Model Accuracy with Fine-Tuning: 56.96% Теперь у нас есть прогнозы для всех трех моделей, которые мы хотим сравнить. Ниже приведена функция для визуализации прогнозов по классам в матрице путаницы с использованием heatmapметода Seaborn, библиотеки визуализации. Матрицы путаницы представляют собой матрицы NxN, где N — количество классов, а прогнозируемые и целевые метки отображаются вдоль осей X и Y соответственно. По сути, это говорит нам, сколько правильных и неправильных классификаций сделала каждая модель путем сравнения истинного класса с прогнозируемым классом. Естественно, чем больше значения по диагонали, тем лучше работает модель.
Вот наш код визуализации:
import seaborn as sns from sklearn.metrics import confusion_matrix # Get the names of the ten classes class_names = testgen.class_indices.keys() def plot_heatmap(y_true, y_pred, class_names, ax, title): cm = confusion_matrix(y_true, y_pred) sns.heatmap( cm, annot=True, square=True, xticklabels=class_names, yticklabels=class_names, fmt='d', cmap=plt.cm.Blues, cbar=False, ax=ax ) ax.set_title(title, fontsize=16) ax.set_xticklabels(ax.get_xticklabels(), rotation=45, ha="right") ax.set_ylabel('True Label', fontsize=12) ax.set_xlabel('Predicted Label', fontsize=12) fig, (ax1, ax2, ax3) = plt.subplots(1, 3, figsize=(20, 10)) plot_heatmap(true_classes, scratch_pred_classes, class_names, ax1, title="Custom CNN") plot_heatmap(true_classes, vgg_pred_classes, class_names, ax2, title="Transfer Learning (VGG16) No Fine-Tuning") plot_heatmap(true_classes, vgg_pred_classes_ft, class_names, ax3, title="Transfer Learning (VGG16) with Fine-Tuning") fig.suptitle("Confusion Matrix Model Comparison", fontsize=24) fig.tight_layout() fig.subplots_adjust(top=1.25) plt.show() РЕЗУЛЬТАТ:

Модель трансферного обучения с тонкой настройкой является лучшей, о чем свидетельствует более сильная диагональ и более легкие ячейки повсюду. Из матрицы путаницы мы также можем видеть, что эта модель чаще всего ошибочно классифицирует яблочный пирог как хлебный пудинг. Однако в целом это явный победитель.
Улучшения
Напомним, что точность нашей пользовательской CNN, модели трансферного обучения с извлечением признаков и точно настроенной модели трансферного обучения составляет 58%, 73% и 81% соответственно.
Мы могли бы увидеть улучшение производительности нашего набора данных после введения тонкой настройки. Выбор подходящего количества слоев для размораживания может потребовать тщательного экспериментирования.
Другие параметры, которые следует учитывать при обучении сети, включают:
- Оптимизаторы: в этой статье мы использовали оптимизатор Адама для обновления наших весов во время тренировки. При обучении сети вам следует поэкспериментировать с другими оптимизаторами и скоростью их обучения .
- Dropout: напомним, что Dropout — это форма регуляризации, позволяющая предотвратить переобучение сети. Мы ввели один отпадающий слой в нашем полностью подключенном слое, чтобы ограничить переобучение сети определенным функциям.
- Полностью связанный уровень: если вы используете самозагрузочный подход к трансферному обучению, убедитесь, что ваш полностью связанный уровень структурирован соответствующим образом для задачи классификации. Соответствует ли количество входных узлов выходным объектам? Не слишком ли много плотно связанных слоев?
Краткое содержание
В этой статье мы решили проблему классификации изображений с использованием пользовательского набора данных с помощью Transfer Learning . Мы увидели, что, используя различные стратегии трансферного обучения, такие как точная настройка, мы можем создать модель, которая превосходит по производительности специально написанную CNN. Некоторые ключевые выводы:
- Трансферное обучение может стать отличной отправной точкой для обучения модели, если у вас нет большого объема данных.
- Трансферное обучение требует, чтобы модель была предварительно обучена на надежной исходной задаче , которую можно легко адаптировать для решения меньшей целевой задачи .
- Трансферное обучение легко доступно через API Keras. Вы можете найти доступные предварительно обученные модели здесь .
- Точная настройка части предварительно обученных слоев может значительно повысить производительность модели.
Источник: www.learndatasci.com