Шпаргалка для алгособеса — алгоритмическая сложность, структуры данных, методы сортировки и Дейкстра
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2024-02-20 13:28
Привет, Хабр!
Так уж повелось, что любой уважающий себя работодатель перенимает передовые![]() методики FAANG — по этой причине практически во всех IT-собесах есть она: секция алгоритмов. Кто-то ей рад, кто-то не очень, но секция есть и уходить пока не планирует. Поэтому нужно закатать рукава и достойно встретить суровую реальность.
методики FAANG — по этой причине практически во всех IT-собесах есть она: секция алгоритмов. Кто-то ей рад, кто-то не очень, но секция есть и уходить пока не планирует. Поэтому нужно закатать рукава и достойно встретить суровую реальность.
При изучении алгоритмов расслабьтесь и получайте удовольствие, ведь есть ненулевая вероятность, что вам понадобятся полученные знания вне собеса. Кто знает, может однажды умение быстро обходить двоичное дерево поможет спасти вам мир (как и знание регулярок):

Да и вообще, изучение алгоритмов может быть очень залипательным и полезным; Миша Ломоносов говорит, что это ум в порядок приводит.
Разбор огромного количества вопрос с собеседований Python в моем канале и вопрос по машинному обучению, а здесь собрана целая папка с каналами для подготовки к собеседованиям.
Тема алгоритмов очень велика, так выглядят отдельные области и понятия:

Немало всего) Как можно убедиться, тема алгоритмов и правда обширна, поэтому в этой статье коснёмся только самых основных вещей:
-
алгоритмическая сложность, асимптотика и О-нотация
-
структуры данных: связный список, стек, очередь, множество, map и другие
-
алгоритмы сортировки
-
и внезапно — отдельно алгоритм Дейкстры; мне показалось довольно интересным коснуться именно его
Для структур данных и алгоритмов сортировки напишем реализацию на Python, чтобы можно было сразу затестить, как всё это работает
Поехали!

Алгоритмическая сложность и асимптотический анализ
Сложность алгоритмов обычно оценивают по времени выполнения или по используемой памяти (временная и пространственная сложность). В обоих случаях сложность зависит от размеров входных данных: массив из 100 элементов будет обработан быстрее, чем аналогичный из 1000. При этом точное время мало кого интересует: оно зависит от процессора, типа данных, языка программирования и множества других параметров. Важна лишь асимптотическая сложность, т. е. сложность при стремлении размера входных данных к бесконечности.
Допустим, некоторому алгоритму нужно выполнить 4n^3 + 7n условных операций, чтобы обработать n элементов входных данных. При увеличении n на итоговое время работы будет значительно больше влиять возведение n в куб, чем умножение его на 4 или же прибавление 7n. В этом случае временная сложность этого алгоритма равна О(n^3), т. е. зависит от размера входных данных кубически.
Использование заглавной буквы О (О-нотация) пришло из математики, где её применяют для сравнения асимптотического поведения функций. Формально O(f(n)) означает, что время работы алгоритма (или объём занимаемой памяти) растёт в зависимости от объёма входных данных не быстрее, чем некоторая константа, умноженная на f(n).
Встречайте типичных представителей каждого уровня сложности:


O(1) — константная сложность
Случается, что время работы алгоритма вообще не зависит от размера входных данных. Тогда сложность обозначают как O(1). Например, для определения значения третьего элемента массива не нужно ни запоминать элементы, ни проходить по ним сколько-то раз. Всегда нужно просто дождаться в потоке входных данных третий элемент и это будет результатом, на вычисление которого для любого количества данных нужно одно и то же время.
Характерные примеры со сложностью O(1): арифметические операции, вызов функции

O(n) — линейная сложность
Такой сложностью обладает, например, алгоритм поиска наибольшего элемента в не отсортированном массиве. Нам придётся пройтись по всем n элементам массива, чтобы понять, какой из них максимальный.

O(log n) — логарифмическая сложность
Простейший пример — бинарный поиск. Если массив отсортирован, мы можем проверить, есть ли в нём какое-то конкретное значение, методом деления пополам. Проверим средний элемент, если он больше искомого, то отбросим вторую половину массива — там его точно нет. Если же меньше, то наоборот — отбросим начальную половину. И так будем продолжать делить пополам, в итоге проверим log n элементов.
Вот ниже последовательность шагов при поиске числа 47 в отсортированном массиве.

O(n^2) — квадратичная сложность
Такую сложность имеет, например, алгоритм сортировки вставками. В канонической реализации он представляет из себя два вложенных цикла: один, чтобы проходить по всему массиву, а второй, чтобы находить место очередному элементу в уже отсортированной части. Таким образом, количество операций будет зависеть от размера массива как n*n, т. е. n^2.

В итоге
Лучшие алгоритмы имеют сложность O(1) или O(log n), в этом случае время выполнения разных операций растёт слабо при увеличении количества элементов или вообще постоянно для О(1). Худшие алгоритмы имеют сложность O(n!), O(2^n) или O(n^2), что сильно затрудняет их использование для больших структур данных.

Как растёт время выполнения операций в зависимости от размера массива для разных видов сложности.

Алгоритмическая сложность операций добавления, удаления, поиска и других для массива, стека, связных списков, хеш-таблицы и других структур данных.

Временная и пространственная сложность разных методов сортировки:

Со сложностями разобрались, поехали к структурам данных!

Структуры данных
В этой статье мы рассмотрим такие структуры данных как:
-
связный список
-
стек
-
очередь
-
множество
-
map
-
хеш-таблица
-
двоичное дерево поиска
-
префиксное дерево
-
двоичная куча
-
граф

Связный список
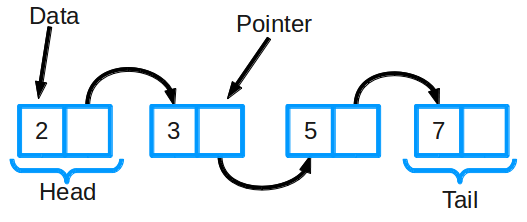
Связный список — одна из базовых структур данных. Ее часто сравнивают с массивом, так как многие другие структуры можно реализовать с помощью либо массива, либо связного списка.
Связный список состоит из группы узлов, которые вместе образуют последовательность. Каждый узел содержит две вещи: фактические данные, которые в нем хранятся (это могут быть данные любого типа) и указатель (или ссылку) на следующий узел в последовательности. Самый первый элемент списка называют головой (head) односвязного списка, а последний — хвостом (tail). Последний элемент односвязного списка в качестве ссылки содержит null-значение.
В отличие от классического массива, где данные в памяти расположены строго последовательно, в односвязном списке, наоборот, данные расположены хаотично и связывание узлов списка происходит посредством ссылок. За счёт этой особенности в односвязный список можно добавлять произвольное число элементов, однако, доступ будет осуществляться только последовательно. Произвольного доступа к элементам в односвязном списке нет.
Также существуют двусвязные списки: в них у каждого узла есть указатель и на следующий, и на предыдущий элемент в списке. Есть ещё кольцевой связный список — у него хвост (последний узел) ссылается на голову (первый узел).
Вот так, например, выглядит удаление узла с числом 99 из односвязного списка:

Связные списки могут быть использованы для реализации стека и очереди (здесь вместо связных списков можно использовать и массивы).
Стек
-
это LIFO-структура данных (last in, first out)
-
голова связного списка, лежащего в основе стека, единственное место для вставки и удаления элементов
Очередь
-
это FIFO-структура данных (first in, first out)
-
очередь представляет собой двусвязный список, в котором элементы удаляются из головы, а добавляются в хвост

Алгоритмическая сложность для основных операций со связным списком:
| действие | сложность |
|---|---|
поиск элемента | O(n) |
добавление элемента | O(1) |
удаление элемента | O(n) |
подсчёт элементов, подходящих под условие | O(n) |

Вот так можно реализовать связный список на Python:
class Node(object): # каждый узел содержит данные data и указатель next на следующий узел def __init__(self, data, next = None): self.data = data; self.next = next; def setData(self, data): self.data = data; def getData(self): # функция для получения значения data из узла return self.data def setNext(self, next): # функция для создания следующего узла self.next = next def getNext(self): # функция для получения следующего узла return self.next class LinkedList(object): def __init__(self): # определяем head в списке self.head = None def printLinkedList(self): # печатаем data из связного списка temp = self.head while(temp): print(temp.data, end=' ') temp = temp.next def insertAtStart(self, data): # вставка узла в начало newNode = Node(data) newNode.next = self.head self.head = newNode def insertBetween(self, previousNode, data): # вставка узла после previousNode if (previousNode.next is None): print('Previous node should have next node!') else: newNode = Node(data) newNode.next = previousNode.next previousNode.next = newNode def insertAtEnd(self, data): # вставка в конец связного списка newNode = Node(data) temp = self.head while(temp.next != None): # get last node temp = temp.next temp.next = newNode def delete(self, data): # удаление элемента по data или key temp = self.head if (temp.next is not None): # если data/key найден в первом узле if(temp.data == data): self.head = temp.next temp = None return else: while(temp.next != None): # иначе искать все узлы if(temp.data == data): break prev = temp temp = temp.next if temp == None: # если узел не найден return prev.next = temp.next return # итеративный поиск def search(self, node, data): if node == None: return False if node.data == data: return True return self.search(node.getNext(), data) if __name__ == '__main__': List = LinkedList() List.head = Node(1) # создаём первый узел - head node2 = Node(2) List.head.setNext(node2) # создаём второй узел --> node2 node3 = Node(3) node2.setNext(node3) # после node2 идёт node3 List.insertAtStart(4) # вставляем node4 вначало, сейчас: 4 1 2 3 List.insertBetween(node2, 5) # вставляем node5 после node2, сейчас: 4 1 2 5 3 6 List.insertAtEnd(6) # вставляем 6 в конец List.printLinkedList() List.delete(3) # удаляем 3, получаем: 4 1 2 5 6 List.printLinkedList() print(List.search(List.head, 1)) 
Стек

Стек — базовая структура данных, которая позволяет добавлять или удалять элементы только в ее начале. Она похожа на стопку книг: если вы хотите взглянуть на книгу в середине стека, сперва придется убрать лежащие сверху.
Стек организован по принципу LIFO (Last In First Out, "последним пришел — первым вышел")?, то есть элементы кладутся наверх и сверху же берутся. Последний элемент, который вы добавили в стек, первым выйдет из него.
Реализаций стека уйма — на массиве, на односвязном списке, на двусвязном списке и т.д. В этой статье речь будет идти о реализации стека на односвязном списке.
Стоит отметить, что стек представляет собой список с элементами и указателя на вершину стека, указывающего на последний элемент, добавленный в стек.
Каждый раз, когда в стек добавляется новый элемент, указатель на вершину смещается на следующий элемент. Когда элемент удаляется из вершины стека, указатель смещается на предыдущий элемент. Если указатель находится в конце стека, то стек пуст.

Алгоритмическая сложность для основных операций с элементами стека:
| действие | сложность |
|---|---|
добавление элемента в вершину стека (push) | O(1) |
удаление элемента из вершины стека (pop) | O(1) |
возврат верхнего элемента без его удаления (peek) | O(1) |
проверка стека на пустоту (isEmpty) | O(1) |

Смоделировать стек в Python, используя список в качестве резервного хранилища, мы можем так (здесь аннотации типов, если кто не в теме):
from typing import TypeVar, Generic, List T = TypeVar('T') class Stack(Generic[T]): def __init__(self) -> None: self._container: List[T] = [] def push(self, item: T) -> None: self._container.append(item) def pop(self) -> T: return self._container.pop() def __repr__(self) -> str: return repr(self._container) Стеки идеально подходят для задачи о ханойских башнях. Для того чтобы переместить диск на башню, мы можем использовать операцию push. Для того чтобы переместить диск с одной башни на другую, мы можем вытолкнуть его с первой (pop) и поместить на вторую (push). Определим башни как объекты Stack и заполним первую из них дисками:
num_discs: int = 3 tower_a: Stack[int] = Stack() tower_b: Stack[int] = Stack() tower_c: Stack[int] = Stack() for i in range(1, num_discs + 1): tower_a.push(i) Ну и вот так может выглядеть функция hanoi(), отвечающая за перемещение дисков с одной башни на другую, используя третью временную башню:
def hanoi(begin: Stack[int], end: Stack[int], temp: Stack[int], n: int) -> None: if n == 1: end.push(begin.pop()) else: hanoi(begin, temp, end, n — 1) hanoi(begin, end, temp, 1) hanoi(temp, end, begin, n - 1) После вызова функции hanoi() можно проверить башни tower_a, tower_b и tower_c, и убедиться, что диски были успешно перемещены.

Очередь

Эту структуру можно представить как очередь в продуктовом магазине. Первым обслуживают того, кто пришел в самом начале — все как в жизни.
Очередь устроена по принципу FIFO (First In First Out, "первый пришел — первый вышел"). Это значит, что удалить элемент можно только после того, как были убраны все ранее добавленные элементы.
Основные операции:
-
Добавление элемента в конец (
enqueue) -
Удаление первого элемента (
dequeue)
Алгоритмическая сложность:
| Алгоритм | Среднее значение | Худший случай |
|---|---|---|
Поиск | O(n) | O(n) |
Вставка | O(1) | O(1) |
Удаление | O(1) | O(1) |

Очередь можно реализовать так:
from typing import TypeVar, Generic, Deque T = TypeVar('T') class Queue(Generic[T]): def __init__(self) -> None: self._container: Deque[T] = Deque() @property def empty(self) -> bool: return not self._container # не равно True для пустого контейнера def push(self, item: T) -> None: self._container.append(item) def pop(self) -> T: return self._container.popleft() # FIFO def __repr__(self) -> str: return repr(self._container) Кстати, в этой реализации очереди Queue в качестве резервного хранилища применяется deque, а не list. Это связано с тем, откуда извлекаются данные в процессе операции pop. В стеке мы помещаем элементы с правого конца и извлекаем их тоже справа. В очереди мы помещаем элементы справа, а извлекаем слева. Структура данных list в Python имеет эффективный метод pop для извлечения справа, но не слева. Структура данных deque позволяет эффективно извлекать данные с любой стороны, например, есть встроенный метод popleft(), у которого нет эквивалента в list.

Множество

Множество хранит значения данных без определенного порядка (не везде, в C++ упорядоченное множество), не повторяя их (есть ещё мультимножество, там могут быть повторы). Оно позволяет не только добавлять и удалять элементы: есть еще несколько важных функций, которые можно применять к двум множествам сразу.
-
Объединение комбинирует все элементы из двух разных множеств, превращая их в одно (без дубликатов)
-
Пересечение анализирует два множества и ?создает еще одно из тех элементов, которые присутствуют в обоих изначальных множествах
-
Разность выводит список элементов, которые есть в одном множестве, но отсутствуют в другом
-
Подмножество выдает булево значение, которое показывает, включает ли одно множество все элементы другого множества

Алгоритмическая сложность для основных операций с элементами множества:
| действие | сложность |
|---|---|
поиск элемента | O(1) |
добавление элемента | O(1) |
удаление элемента (для неупорядоченного множества) | O(1) |

Работать с множествами в Python просто и приятно:
a = set([1, 2, 1, 3, 4]) b = {4, 4, 5, 6} c = {1, 2} print(a, b, c) # {1, 2, 3, 4} {4, 5, 6} {1, 2} print(c.issubset(a), c <= a) # True True print(a.union(b), a | b) # {1, 2, 3, 4, 5, 6} {1, 2, 3, 4, 5, 6} print(a.intersection(b), a & b) # {4} {4} print(a.difference(b), a - b) # {1, 2, 3} {1, 2, 3} print(c) # {1, 2} c.add(3) print(c) # {1, 2, 3} c.remove(2) print(c) # {1, 3} c.pop() print(c) # {3} c.clear() print(c) # set() 
Map (словарь, ассоциативный массив)
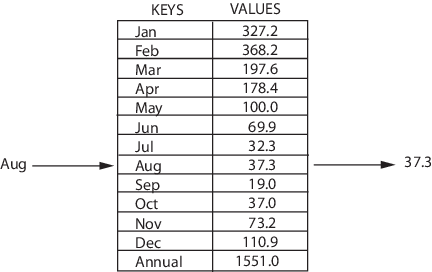
Map — структура, которая хранит данные в парах ключ/значение, где каждый ключ уникален. Иногда ее также называют ассоциативным массивом или словарем. Map часто используют для быстрого поиска данных.
Нередко под капотом у Map хеш-таблица, поэтому можно рассматривать Map как обёртку над более общими хеш-таблицами, о которых поговорим ниже.
Алгоритмическая сложность для основных операций с элементами Map (в случае реализации на хеш-таблицах):
| действие | сложность |
|---|---|
добавление нового элемента с уникальным ключом | О(1) |
удаление элемента по ключу | О(1) |
изменение значения по ключу | О(1) |
получение значения по ключу | О(1) |

Хеш-таблица
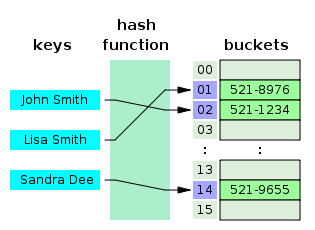
Хеш-таблица — структура, которая содержит пары ключ/значение. Она использует хеш-функцию для вычисления индекса в массиве из блоков данных, чтобы найти желаемое значение. Хеш-таблицы часто используются для реализации Map (словарей).
Обычно хеш-функция принимает строку символов в качестве вводных данных и выводит числовое значение. Для одного и того же ввода хеш-функция должна возвращать одинаковое число. Если два разных ввода хешируются одинаково, возникает коллизия. Коллизий нужно избегать, они приводят к тому, что разные элементы получают один и тот же адрес в памяти, что снижает производительность хеш-таблицы.
Когда вы вводите пару ключ/значение в хеш-таблицу, ключ проходит через хеш-функцию, функция возвращает число. В дальнейшем это число используется как фактический ключ, который соответствует определенному значению. Когда вы снова введете тот же ключ, хеш-функция обработает его и вернет такой же числовой результат. Затем этот результат будет использован для поиска связанного значения. Это позволяет мгновенно извлекать элементы с минимальной сложностью O(1).
Хеш-таблицы часто используются для реализации словарей и множеств. Они позволяют выполнять операции вставки и удаления быстрее, чем структуры данных, основанные на деревьях. С другой стороны, для корректной работы хеш-таблицы требуют выделения большого блока непрерывной памяти.
Сложность для основных операций с элементами хеш-таблицы:
| действие | сложность |
|---|---|
добавление нового элемента с уникальным ключом | О(1) |
удаление элемента по ключу | О(1) |
изменение значения по ключу | О(1) |
получение значения по ключу | О(1) |

Вот так может выглядеть простая реализация хеш-таблицы со самыми важными методами:
class HashTable: def __init__(self): self.hashTable = [[],] * 10 def checkPrime(self, n): if n == 1 or n == 0: return 0 for i in range(2, n//2): if n % i == 0: return 0 return 1 def getPrime(self, n): if n % 2 == 0: n = n + 1 while not self.checkPrime(n): n += 2 return n def hashFunction(self, key): capacity = self.getPrime(10) return key % capacity def insertData(self, key, data): index = self.hashFunction(key) self.hashTable[index] = [key, data] def removeData(self, key): index = self.hashFunction(key) self.hashTable[index] = 0 def __str__(self): return str(self.hashTable) hash_table = HashTable() hash_table.insertData(123, "apple") hash_table.insertData(432, "mango") hash_table.insertData(213, "banana") hash_table.insertData(654, "guava") print(hash_table) hash_table.removeData(123) print(hash_table) # [[], [], [123, 'apple'], [432, 'mango'], [213, 'banana'], [654, 'guava'], [], [], [], []] # [[], [], 0, [432, 'mango'], [213, 'banana'], [654, 'guava'], [], [], [], []] Отлично, поехали к следующей структуре — двоичному дереву

Двоичное (бинарное) дерево

Дерево — структура данных, состоящая из узлов. Ей присущи следующие свойства:
-
Каждое дерево имеет корневой узел (вверху)
-
Корневой узел имеет 0 или более дочерних узлов
-
Каждый дочерний узел имеет 0 или более дочерних узлов, и т.д.
У двоичного дерева поиска есть 2 дополнительных свойства:
-
Каждый узел имеет до 2 дочерних узлов (потомков)
-
Каждый узел меньше своих потомков справа, а его потомки слева меньше его самого
Двоичные деревья поиска позволяют быстро находить, добавлять и удалять элементы. Они устроены так, что время каждой операции пропорционально логарифму общего числа элементов в дереве.

Алгоритмическая сложность операций над двоичным деревом:
| действие | сложность | сложность в худшем случае |
|---|---|---|
поиск элемента | O(log n) | O(n) |
вставка элемента | O(log n) | O(n) |
удаление элемента | O(log n) | O(n) |

Что ж, напишем реализацию двоичного дерева:
class BinaryTreeNode: def __init__(self, value, parent=None): self.left = None # ссылка на левый дочерний узел self.right = None # ссылка на правый дочерний узел self.parent = parent # ссылка на родителя self.value = value # полезная нагрузка Теперь нам необходимо расширить наш класс и реализовать необходимые операции, чтобы взаимодействовать с проектируемым классом. Вообще, у нас возможны такие операции: поиск узла, вставка и удаление узла, обход дерева.
Начнем с операции поиска узла. Если искомое значение бинарного дерева поиска меньше значения узла, то оно может находиться только в левом поддереве. Искомое значение, которое больше значения узла, может быть только в правом поддереве. В таком случае мы можем применить рекурсивный подход, допишем наше определение класса вот такой операцией поиска:
def find_node(root, value): node = self while node: if value == node.value: return node if value < node.value: node = node.left if value > node.value: node = node.right return None 
Теперь вставка узла. Все значения меньше текущего значения узла надо размещать в левом поддереве, а большие — в правом. Чтобы вставить новый узел, нужно проверить, что текущий узел не пуст. Далее может быть два пути:
-
если это так, сравниваем значение со вставляемым. По результату сравнения проводим проверку для правого или левого поддеревьев
-
если узел пуст, создаем новый и заполняем ссылку на текущий узел в качестве родителя
Операция вставки использует рекурсивный подход аналогично операции поиска:
def insert_node(self, value): return self._insert_node(value, self) def _insert_node(self, value, parent_node): if value < parent_node.value: if parent_node.left is None: parent_node.left = BinaryTreeNode(value, parent_node) else: self._insert_node(value, parent_node.left) elif value > parent_node.value: if parent_node.right is None: parent_node.right = BinaryTreeNode(value, parent_node) else: self._insert_node(value, parent_node.right) 
Удаление узла. Чтобы удалить элемент в связном списке, нужно найти его и ссылку на следующий элемент перенести в поле ссылки на предыдущем элементе.
Если необходимо удалить корневой узел или промежуточные вершины и сохранить структуру бинарного дерева поиска, выбирают один из следующих двух способов:
-
находим и удаляем максимальный элемент левого поддерева и используем его значение в качестве корневого или промежуточного узла
-
находим и удаляем минимальный элемент правого поддерева и используем его значение в качестве корневого или промежуточного узла
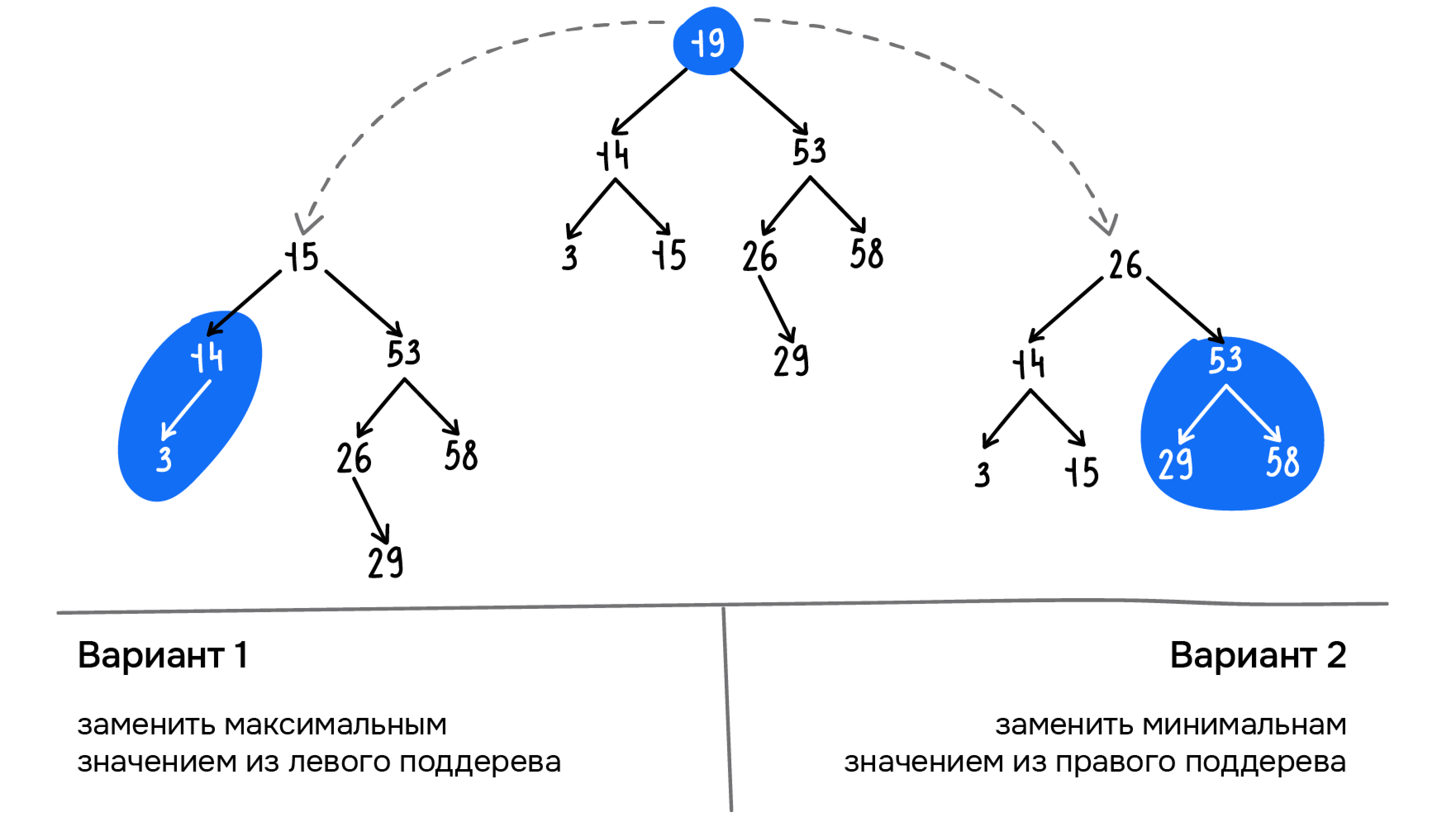
Оба варианта подходят для нашего дерева. Реализуем в коде второй вариант:
def remove_node(self, value): return self._remove_node(value, self) def _remove_node(self, value, node): if node is None: return None if value < node.value: node.left = self._remove_node(value, node.left) return node elif value > node.value: node.right = self._remove_node(value, node.right) return node else: if node.left is None: return node.right elif node.right is None: return node.left else: original = node node = node.right while node.left: node = node.left node.right = self._remove_min(original.right) node.left = original.left return node 
Обход деревьев. Когда мы поработали с деревом и нам нужно его сохранить в файл или вывести в печать, нам больше не нужен древовидный формат. Здесь мы прибегаем к обходу дерева — последовательное единоразовое посещение всех вершин дерева.
Существуют такие 3 варианта обхода деревьев:
-
Прямой обход (КЛП): корень ? левое поддерево ? правое поддерево
-
Центрированный обход (ЛКП): левое поддерево ? корень ? правое поддерево
-
Обратный обход (ЛПК): левое поддерево ? правое поддерево ? корень
Такие обходы называются поиском в глубину. На каждом шаге итератор пытается продвинуться вертикально вниз по дереву перед тем, как перейти к родственному узлу — узлу на том же уровне. Еще есть поиск в ширину — обход узлов дерева по уровням: от корня и далее:

Реализация поиска в глубину может осуществляться или с использованием рекурсии, или с использованием стека. А поиск в ширину реализуется за счет использования очереди:
def traverse_recursive(node): if node is not None: print(f"node = {node.value}") traverse_recursive(node.left) traverse_recursive(node.right) def traverse_with_stack(root): stack = [] stack.append(root) while len(stack) > 0: current_node = stack.pop() print(f"node = {current_node.value}") if current_node.right is not None: stack.append(current_node.right) if current_node.left is not None: stack.append(current_node.left) def traverse_with_queue(root): queue = [] queue.append(root) while len(queue) > 0: current_node = queue.pop(0) print(f"node = {current_node.value}") if current_node.left: queue.append(current_node.left) if current_node.right: queue.append(current_node.right) Вот мы и реализовали двоичное дерево со всеми важными методами, переходим к следующей структуре — префиксному дереву.

Префиксное дерево (бор)
(в каждом узле хранится только по 1 букве, слова тут для наглядности)

Префиксное (нагруженное) дерево (бор) — разновидность дерева поиска. Оно хранит данные в метках, каждая из которых представляет собой узел на дереве. Такие структуры часто используют, чтобы хранить слова и выполнять быстрый поиск по ним — например, для функции автозаполнения.
Каждый узел в языковом префиксном дереве содержит 1 букву слова. Чтобы составить слово, нужно следовать по ветвям дерева, проходя по одной букве за раз. Дерево начинает ветвиться, когда порядок букв отличается от других имеющихся в нем слов или когда слово заканчивается. Каждый узел содержит букву (данные) и булево значение, которое указывает, является ли он последним в слове.
Префиксное дерево можно использовать для разных задач:
-
хранение строк: если есть много повторяющихся длинных префиксов, то бор может занимать гораздо меньше места, чем массив или
setстрок -
сортировка строк: по построенному бору можно пройтись
DFS-ом и вывести все строки в лексикографическом порядке -
просто как множество строк: в бор легко добавлять и удалять слова, а также делать проверки вхождения

Префиксное дерево может выступать в качестве ассоциативного массива. Эта структура объединяет некоторые преимущества дерева и хеш-таблицы и позволяет одновременно делать операции более эффективно:

Здесь не без ложки дёгтя, вот 2 недостатка использования бора в качестве ассоциативного массива:
-
Бор хранит строки или символы, а это значит, что у значения ключа будет ограничение на тип (строки, символы, либо числа, представленные как строки). Чтобы это исправить, нужно приводить любой тип данных к строке
-
Если реализовывать ассоциативный массив на обычном боре, а ключами будут являться строки, то будет использоваться слишком много памяти (возможен, например, вариант, когда у слов нет пересечений по префиксу)
Как-то вот так, не будет тут сильно засиживаться, поехали к двоичной куче)

Двоичная куча (пирамида)
Двоичные кучи с максимальным и минимальным корневым элементом:
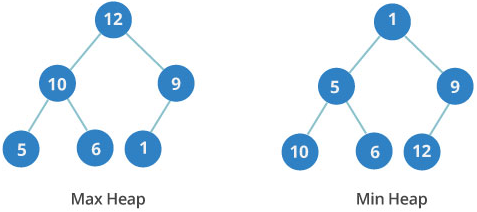
Отображение древовидного представления кучи на его представление в виде массива:

Двоичная куча — еще одна древовидная структура данных. В ней у каждого узла не более двух потомков. Также она является совершенным деревом: это значит, что в ней полностью заняты данными все уровни, а последний заполнен слева направо.
Двоичная куча может быть минимальной или максимальной. В максимальной куче ключ любого узла всегда больше ключей его потомков или равен им. В минимальной куче все устроено наоборот: ключ любого узла меньше ключей его потомков или равен им.
Порядок уровней в двоичной куче важен, в отличие от порядка узлов на одном и том же уровне.
Алгоритмическая сложность:
| Алгоритм | Среднее значение | Худший случай |
|---|---|---|
Поиск | O(n) | O(n) |
Вставка | O(1) | O(log n) |
Удаление | O(log n) | O(log n) |

Давайте имплементируем нашу двоичную кучу на Python. Поскольку куча целиком может быть представлена в виде обычного списка, то всё, что нужно сделать, - это инициализировать список и атрибут currentSize, через который отслеживается текущий размер кучи.
Создадим класс BinHeap:
class BinHeap: def __init__(self): self.heapList = [0] self.currentSize = 0 
Теперь нужно написать метод insert. Простейший и наиболее эффективный способ добавить элемент — просто присоединить его к концу списка. Хорошая новость — таким образом мы поддержим свойство полноты дерева. Плохая — весьма вероятно, что это нарушит структурное свойство кучи. К счастью, существует способ написать метод, позволяющий нам восстановить структуру с помощью сравнения нового элемента с его предком. Если добавляемый элемент меньше родителя, то мы можем просто поменять их местами. Вот тут ниже видно серию перестановок, необходимую для “просачивания” нового элемента на его законное место в дереве:

Теперь мы готовы написать метод insert. Большую часть его работы уже делает percUp. После того, как в дерево вставлен новый элемент, percUp позиционирует его как положено:
def percUp(self,i): while i // 2 > 0: if self.heapList[i] < self.heapList[i // 2]: tmp = self.heapList[i // 2] self.heapList[i // 2] = self.heapList[i] self.heapList[i] = tmp i = i // 2 def insert(self,k): self.heapList.append(k) self.currentSize = self.currentSize + 1 self.percUp(self.currentSize) 
С правильно определённым методом insert мы можем перейти к методу delMin. Так как свойство кучи требует, чтобы корень был наименьшим элементом дерева, найти её минимум очень легко. Сложная часть delMin - восстановить соответствие свойствам структуры и упорядоченности кучи после удаления корневого элемента. Мы будем это делать в два шага. Во-первых, восстановим корневой элемент, взяв последний элемент списка и передвинув его на место корня. Так мы поддержим структурное свойство кучи. Однако, весьма вероятно, что при этом нарушится её свойство упорядоченности. Поэтому вторым шагом станет спуск корня на его правильную позицию. На рисунке ниже показана серия перестановок, необходимая для перемещения корня до соответствующего положения в куче:

Чтобы поддержать свойство упорядоченности, нам надо всего лишь поменять местами корень с меньшим, чем он потомком. После начальной перестановки мы можем повторять процесс для узла и его потомков до тех пор, пока он не переместится на позицию, в которой будет меньше обоих своих детей. Код для “просачивания” узла вниз по дереву можно найти в методах percDown и minChild ниже:
def percDown(self,i): while (i * 2) <= self.currentSize: mc = self.minChild(i) if self.heapList[i] > self.heapList[mc]: tmp = self.heapList[i] self.heapList[i] = self.heapList[mc] self.heapList[mc] = tmp i = mc def minChild(self,i): if i * 2 + 1 > self.currentSize: return i * 2 else: if self.heapList[i*2] < self.heapList[i*2+1]: return i * 2 else: return i * 2 + 1 
Код для операции delMin ниже. Вся сложная работа снова отдана вспомогательной функции (в данном случае - percDown):
def delMin(self): retval = self.heapList[1] self.heapList[1] = self.heapList[self.currentSize] self.currentSize = self.currentSize - 1 self.heapList.pop() self.percDown(1) return retval 
Ну и в завершение рассмотрим метод, который позволяет построить кучу из списка ключей:
def buildHeap(self,alist): i = len(alist) // 2 self.currentSize = len(alist) self.heapList = [0] + alist[:] while (i > 0): self.percDown(i) i = i - 1 На рисунке ниже видно создание кучи из списка [9, 6, 5, 2, 3] при выполнении кода
bh = BinHeap() bh.buildHeap([9,5,6,2,3]) 
Готово, вот мы и реализовали двоичную кучу или пирамиду, можно переходить к следующей структуре)

Граф

В простонародье граф — это совокупность узлов (вершин) и связей между ними (рёбер).
Графы можно поделить на 2 типа: ориентированные и неориентированные. У неориентированных графов ребра между узлами не имеют какого-либо направления, тогда как у ребер в ориентированных графах оно есть.
Чаще всего граф изображают в каком-либо из двух видов: это может быть список смежности или матрица смежности.
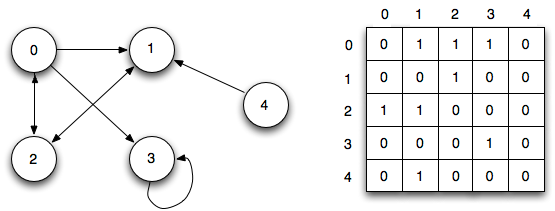
Список смежности можно представить как перечень элементов, где слева находится один узел, а справа — все остальные узлы, с которыми он соединяется.
Матрица смежности — это сетка с числами, где каждый ряд или колонка соответствуют отдельному узлу в графе. На пересечении ряда и колонки находится число, которое указывает на наличие связи. Нули означают, что связь отсутствует; единицы — что она есть. Чтобы обозначить вес каждой связи, используют числа больше единицы.
Существуют специальные алгоритмы для просмотра ребер и вершин в графах — так называемые алгоритмы обхода. К их основным типам относят поиск в ширину (breadth-first search) и поиск в глубину (depth-first search). С их помощью можно, например, определить, насколько близко к корневому узлу находятся те или иные вершины графа.

Для реализации структуры данных "граф" определим вначале класс Edge (связь между 2 вершинами):
from __future__ import annotations from dataclasses import dataclass @dataclass class Edge: u: int # вершина "откуда" v: int # вершина "куда" def reversed(self) -> Edge: return Edge(self.v, self.u) def __str__(self) -> str: return f"{self.u} -> {self.v}" Теперь определим класс Graph с использованием Edge (остальная часть определения ниже):
from typing import TypeVar, Generic, List, Optional from edge import Edge V = TypeVar('V') # тип вершин графа class Graph(Generic[V]): def __init__(self, vertices: List[V] = []) -> None: self._vertices: List[V] = vertices self._edges: List[List[Edge]] = [[] for _ in vertices] Здесь список _vertices — это сердце графа. Все вершины сохраняются в списке, а впоследствии мы будем ссылаться на них по их целочисленному индексу в этом списке. Сама вершина может быть сложным типом данных, но ее индекс всегда имеет тип int, с которым легко работать. На другом уровне, между графовыми алгоритмами и массивом _vertices, этот индекс позволяет получить две вершины
с одним и тем же именем в одном графе.
Допишем наше определение класса Graph:
@property def vertex_count(self) -> int: return len(self._vertices) # Количество вершин @property def edge_count(self) -> int: return sum(map(len, self._edges)) # Количество ребер # Добавляем вершину в граф и возвращаем ее индекс def add_vertex(self, vertex: V) -> int: self._vertices.append(vertex) self._edges.append([]) # Добавляем пустой список для ребер return self.vertex_count - 1 # Возвращаем индекс по добавленным вершинам # Это ненаправленный граф, # поэтому мы всегда добавляем вершины в обоих направлениях def add_edge(self, edge: Edge) -> None: self._edges[edge.u].append(edge) self._edges[edge.v].append(edge.reversed()) # Добавляем ребро, используя индексы вершин (удобный метод) def add_edge_by_indices(self, u: int, v: int) -> None: edge: Edge = Edge(u, v) self.add_edge(edge) # Добавляем ребро, просматривая индексы вершин (удобный метод) def add_edge_by_vertices(self, first: V, second: V) -> None: u: int = self._vertices.index(first) v: int = self._vertices.index(second) self.add_edge_by_indices(u, v) # Поиск вершины по индексу def vertex_at(self, index: int) -> V: return self._vertices[index] # Поиск индекса вершины в графе def index_of(self, vertex: V) -> int: return self._vertices.index(vertex) # Поиск вершин, с которыми связана вершина с заданным индексом def neighbors_for_index(self, index: int) -> List[V]: return list(map(self.vertex_at, [e.v for e in self._edges[index]])) # Поиск индекса вершины; возвращает ее соседей (удобный метод) def neighbors_for_vertex(self, vertex: V) -> List[V]: return self.neighbors_for_index(self.index_of(vertex)) # Возвращает все ребра, связанные с вершиной, имеющей заданный индекс def edges_for_index(self, index: int) -> List[Edge]: return self._edges[index] # Поиск индекса вершины; возвращает ее ребра (удобный метод) def edges_for_vertex(self, vertex: V) -> List[Edge]: return self.edges_for_index(self.index_of(vertex)) # Упрощенный красивый вывод графа def __str__(self) -> str: desc: str = "" for i in range(self.vertex_count): desc += f"{self.vertex_at(i)} -> {self.neighbors_for_index(i)}
" return desc Хмм, немало всего. Как видно, большинство методов этого класса существует в 2 версиях. Из определения класса мы знаем, что список _vertices содержит элементы типа V, который может быть любым классом Python. Таким образом, у нас есть вершины типа V, которые хранятся в списке _vertices. Но если мы хотим получить эти вершины и впоследствии ими манипулировать, то нужно знать, где они хранятся в данном списке. Следовательно, с каждой вершиной в этом массиве связан индекс (целое число). Если индекс вершины неизвестен, то его нужно найти, просматривая _vertices. Именно для этого нужны 2 версии каждого метода: одна оперирует внутренними индексами, другая — самим V.

Теперь мы без проблем можем создать граф, написав что-то в духе:
city_graph: Graph[str] = Graph(["Seattle", "San Francisco", "LosAngeles", "Riverside", "Phoenix", "Chicago", "Boston", "New York", "Atlanta", "Miami", "Dallas", "Houston", "Detroit", "Philadelphia", "Washington"]) city_graph.add_edge_by_vertices("Seattle", "Chicago") city_graph.add_edge_by_vertices("Seattle", "San Francisco") city_graph.add_edge_by_vertices("San Francisco", "Riverside") city_graph.add_edge_by_vertices("San Francisco", "Los Angeles") city_graph.add_edge_by_vertices("Los Angeles", "Riverside") city_graph.add_edge_by_vertices("Los Angeles", "Phoenix") city_graph.add_edge_by_vertices("Riverside", "Phoenix") city_graph.add_edge_by_vertices("Riverside", "Chicago") city_graph.add_edge_by_vertices("Phoenix", "Dallas") city_graph.add_edge_by_vertices("Phoenix", "Houston") city_graph.add_edge_by_vertices("Dallas", "Chicago") city_graph.add_edge_by_vertices("Dallas", "Atlanta") city_graph.add_edge_by_vertices("Dallas", "Houston") city_graph.add_edge_by_vertices("Houston", "Atlanta") city_graph.add_edge_by_vertices("Houston", "Miami") city_graph.add_edge_by_vertices("Atlanta", "Chicago") city_graph.add_edge_by_vertices("Atlanta", "Washington") city_graph.add_edge_by_vertices("Atlanta", "Miami") city_graph.add_edge_by_vertices("Miami", "Washington") city_graph.add_edge_by_vertices("Chicago", "Detroit") city_graph.add_edge_by_vertices("Detroit", "Boston") city_graph.add_edge_by_vertices("Detroit", "Washington") city_graph.add_edge_by_vertices("Detroit", "New York") city_graph.add_edge_by_vertices("Boston", "New York") city_graph.add_edge_by_vertices("New York", "Philadelphia") city_graph.add_edge_by_vertices("Philadelphia", "Washington") print(city_graph) # Seattle -> ['Chicago', 'San Francisco'] # San Francisco -> ['Seattle', 'Riverside', 'Los Angeles'] # Los Angeles -> ['San Francisco', 'Riverside', 'Phoenix'] # Riverside -> ['San Francisco', 'Los Angeles', 'Phoenix', 'Chicago'] # Phoenix -> ['Los Angeles', 'Riverside', 'Dallas', 'Houston'] # Chicago -> ['Seattle', 'Riverside', 'Dallas', 'Atlanta', 'Detroit'] # Boston -> ['Detroit', 'New York'] # New York -> ['Detroit', 'Boston', 'Philadelphia'] # Atlanta -> ['Dallas', 'Houston', 'Chicago', 'Washington', 'Miami'] # Miami -> ['Houston', 'Atlanta', 'Washington'] # Dallas -> ['Phoenix', 'Chicago', 'Atlanta', 'Houston'] # Houston -> ['Phoenix', 'Dallas', 'Atlanta', 'Miami'] # Detroit -> ['Chicago', 'Boston', 'Washington', 'New York'] # Philadelphia -> ['New York', 'Washington'] # Washington -> ['Atlanta', 'Miami', 'Detroit', 'Philadelphia'] 
Кстати, что это за транспортная сеть? Подсказка — что-то, связанное с 700 миль/час, пишите, кто угадал)

Алгоритмы сортировки
Ловите табличку сложности разных алгоритмов сортировки:

А вот сравнение разных алгоритмов:

Что ж, давайте теперь о каждом алгоритме поподробнее.

Быстрая сортировка (Quick Sort)
Как и сортировка слиянием, быстрая сортировка использует подход «Разделяй и властвуй». Алгоритм чуть сложнее, но в стандартных реализациях он работает быстрее сортировки слиянием, а его сложность в худшем случае достигает O(n^2), но это редкое явление. Quick Sort состоит из 3 этапов:
-
Выбирается 1 опорный элемент.
-
Все элементы меньше опорного перемещаются слева от него, остальные — направо. Это называется операцией разбиения.
-
Рекурсивно повторяются 2 предыдущих шага к каждому новому списку, где новые опорные элементы будут меньше и больше оригинального соответственно.

def partition(array, begin, end): # разделяем массив пополам по опорному элементу pivot_idx = begin for i in xrange(begin+1, end+1): if array[i] <= array[begin]: pivot_idx += 1 array[i], array[pivot_idx] = array[pivot_idx], array[i] array[pivot_idx], array[begin] = array[begin], array[pivot_idx] return pivot_idx def quick_sort_recursion(array, begin, end): # рекурсивно вызываем сортировку подмассивов пока размер подмассива != 1 if begin >= end: return pivot_idx = partition(array, begin, end) quick_sort_recursion(array, begin, pivot_idx-1) quick_sort_recursion(array, pivot_idx+1, end) def quick_sort(array, begin=0, end=None): if end is None: end = len(array) - 1 return quick_sort_recursion(array, begin, end) 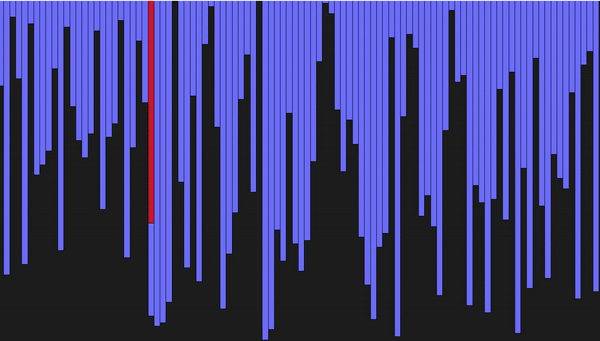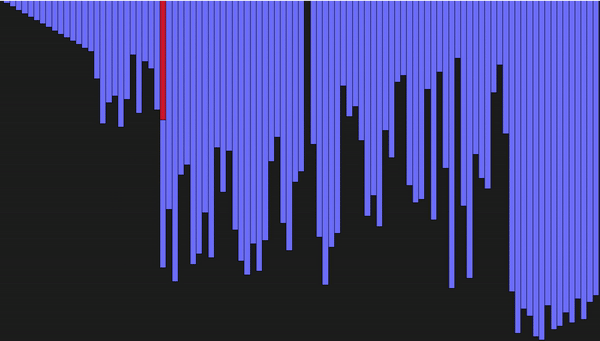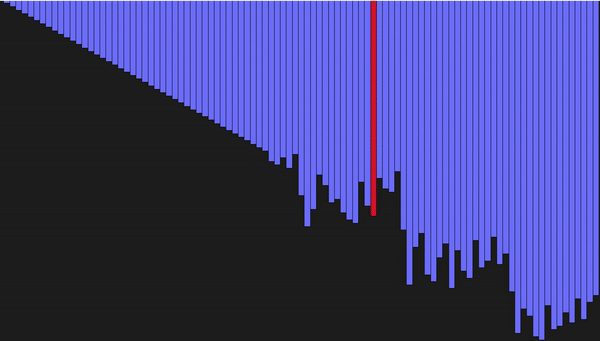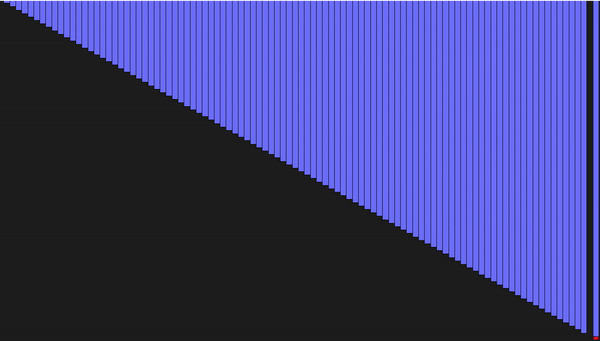

Сортировка слиянием (Merge Sort)
Сортировка слиянием — ещё один пример использования подхода «Разделяй и властвуй». Состоит из двух этапов:
-
Несортированный список последовательно делится на N списков, где каждый включает один «несортированный» элемент, а N — это число элементов в оригинальном массиве.
-
Списки последовательно сливаются группами по два, создавая новые отсортированные списки до тех пор, пока не появится один финальный отсортированный список.

def merge_sort(arr): # Последнее разделение массива if len(arr) <= 1: return arr mid = len(arr) // 2 # Выполняем merge_sort рекурсивно с двух сторон left, right = merge_sort(arr[:mid]), merge_sort(arr[mid:]) # Объединяем стороны вместе return merge(left, right, arr.copy()) def merge(left, right, merged): left_cursor, right_cursor = 0, 0 while left_cursor < len(left) and right_cursor < len(right): # Сортируем каждый и помещаем в результат if left[left_cursor] <= right[right_cursor]: merged[left_cursor+right_cursor]=left[left_cursor] left_cursor += 1 else: merged[left_cursor + right_cursor] = right[right_cursor] right_cursor += 1 for left_cursor in range(left_cursor, len(left)): merged[left_cursor + right_cursor] = left[left_cursor] for right_cursor in range(right_cursor, len(right)): merged[left_cursor + right_cursor] = right[right_cursor] return merged 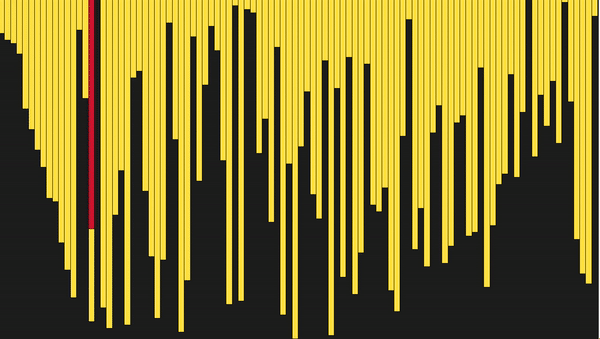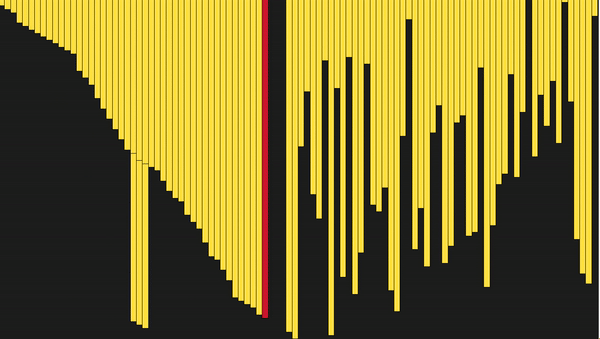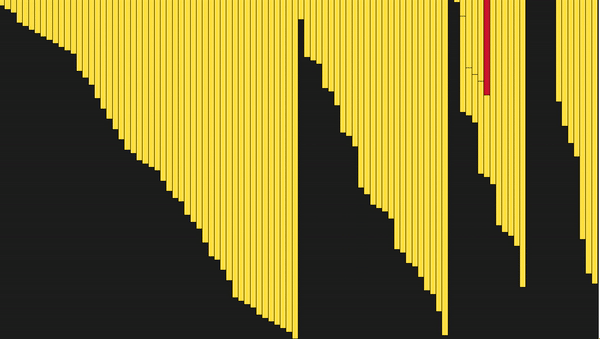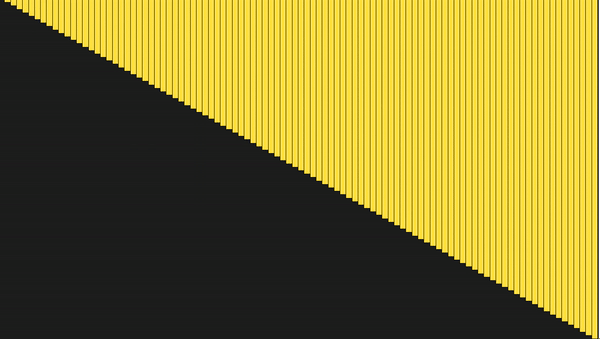

Сортировка вставками (Insertion Sort)

В сортировке вставками на каждом шаге которого массив постепенно перебирается слева направо. При этом каждый последующий элемент размещается так, чтобы он оказался между ближайшими элементами с минимальным и максимальным значением. Вот и вся идея.
def insertion_sort(arr): for i in range(len(arr)): cursor = arr[i] pos = i while pos > 0 and arr[pos - 1] > cursor: # Меняем местами число, продвигая по списку arr[pos] = arr[pos - 1] pos = pos - 1 # Остановимся и сделаем последний обмен arr[pos] = cursor return arr 

Сортировка пузырьком (Bubble Sort)

Алгоритм сортировки пузырьком состоит в повторяющихся проходах по сортируемому массиву. На каждой итерации последовательно сравниваются соседние элементы, и, если порядок в паре неверный, то элементы меняют местами. За каждый проход по массиву как минимум один элемент встает на свое место, поэтому необходимо совершить не более ![]() проходов, чтобы отсортировать массив размером
проходов, чтобы отсортировать массив размером ![]()
def bubble_sort(arr): def swap(i, j): arr[i], arr[j] = arr[j], arr[i] n = len(arr) swapped = True x = -1 while swapped: swapped = False x = x + 1 for i in range(1, n-x): if arr[i - 1] > arr[i]: # если элементы стоят в неправильном порядке, swap(i - 1, i) # то меняем их местами, пока не отсортируем arr swapped = True 

Сортировка перемешиванием (шейкерная сортировка)

Шейкерная сортировка отличается от пузырьковой тем, что она двунаправленная: алгоритм перемещается не строго слева направо, а сначала слева направо, затем справа налево.

Сортировка расчёской

Сортировка расчёской — очередное улучшение сортировки пузырьком. Идея в том, чтобы «устранить» элементы с небольшими значения в конце массива, которые замедляют работу алгоритма. Если при пузырьковой и шейкерной сортировках при переборе массива сравниваются соседние элементы, то при «расчёсывании» сначала берётся достаточно большое расстояние между сравниваемыми значениями, а потом оно сужается вплоть до минимального. Первоначальный разрыв нужно выбирать не случайным образом, а с учётом специальной величины — фактора уменьшения, оптимальное значение которого равно 1.247. Сначала расстояние между элементами будет равняться размеру массива, поделённому на 1.247; на каждом последующем шаге расстояние будет снова делиться на фактор уменьшения — и так до окончания работы алгоритма.

Сортировка выбором (Selection Sort )

На каждом ![]() -ом шаге алгоритма находим
-ом шаге алгоритма находим ![]() -ый минимальный элемент и меняем его местами с
-ый минимальный элемент и меняем его местами с ![]() -ым элементом в массиве. Таким образом будет получен массив, отсортированный по неубыванию.
-ым элементом в массиве. Таким образом будет получен массив, отсортированный по неубыванию.
def selection_sort(arr): for i in range(len(arr)): minimum = i for j in range(i + 1, len(arr)): # находим наименьшее значение if arr[j] < arr[minimum]: minimum = j # помещаем его перед отсортированным концом массива arr[minimum], arr[i] = arr[i], arr[minimum] return arr 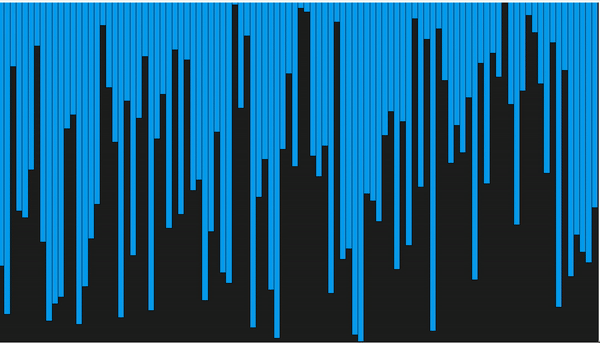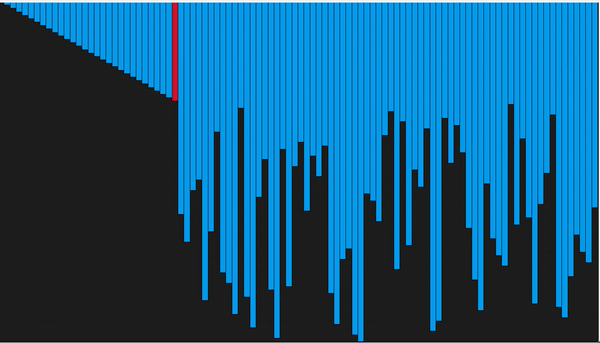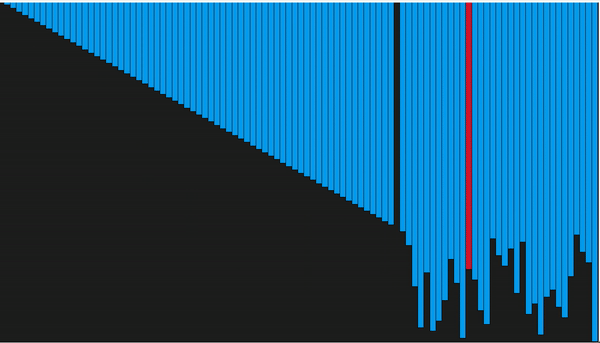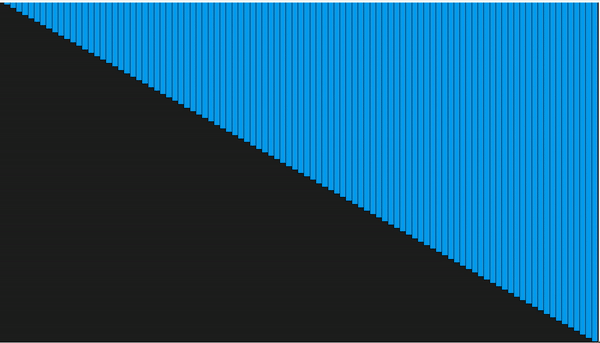
Вот и разобрались с основными алгоритмами сортировки, вперёд к алгоритму Дейкстры.

Алгоритм Дейкстры
Одна гифка лучше тысячи слов:

Или вот пошаговый пример, тут ниже у нас происходит поиск всех кратчайших путей из множества S с использованием алгоритма Дейкстры. Каждая строка таблицы представляет один шаг, на котором мы обрабатываем ранее необработанную вершину с наименьшим весом.

Итак, алгоритм Дейкстры — это популярный алгоритм поиска, используемый для определения кратчайшего пути между двумя узлами в графе. Алгоритм Дейкстры можно использовать для решения любой задачи, которая может быть представлена в виде графа. Предложения друзей в социальных сетях, маршрутизация пакетов через Интернет или поиск пути через лабиринт — все это может сделать алгоритмом Дейкстры.
Псевдокод алгоритма может выглядеть так:

Алгоритм Дейкстры для графов, а это означает, что он может быть применим к проблеме, только если она представлена в графоподобном виде. Дальше разберём самый интуитивно понятный пример — нахождение кратчайшего пути между 2 городами.
Будем искать наилучший маршрут между европейскими городами Рейкьявиком и Белградом. Для простоты представим, что все города связаны дорогами (реальный маршрут должен включать как минимум один паром).
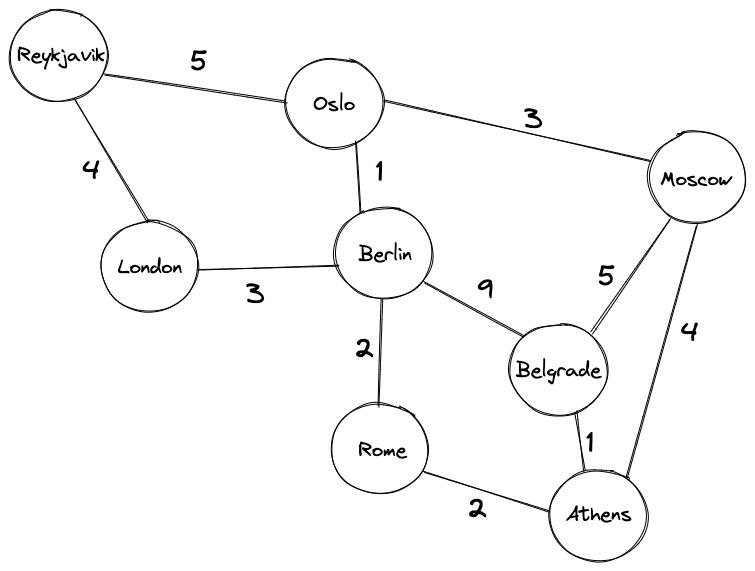
-
каждый город — это узел
-
каждая дорога — это ребро
-
у каждой дороги есть своя ценность. Это может быть расстояние между городами, плата за проезд или интенсивностью движения. Как правило, мы отдаем предпочтение рёбрам с более низкими значениями. В нашем конкретном случае связанное значение определяется расстоянием между двумя городами.
Как видно, здесь добраться из Рейкьявика до Белграда напрямую невозможно. Но есть несколько путей из Рейкьявика в Белград, которые проходят через другие города:
-
Reykjavik
 Oslo
Oslo  Berlin
Berlin  Belgrade
Belgrade -
Reykjavik
 London
London  Berlin
Berlin  Rome
Rome  Athens
Athens  Belgrade
Belgrade -
Reykjavik
 London
London  Berlin
Berlin  Rome
Rome  Athens
Athens  Moscow
Moscow  Belgrade
Belgrade
Каждый из этих путей заканчивается в Белграде, но все они имеют разные ценности. Мы можем использовать алгоритм Дейкстры, чтобы найти путь с наименьшим общим значением.

Итак, как работает алгоритм Дейкстры?
Сначала инициализируем алгоритм:
-
Устанавливаем Рейкьявик в качестве начального узла.
-
Устанавливаем расстояния между Рейкьявиком и всеми другими городами в
 , за исключением расстояния между Рейкьявиком и самим собой, которое принимаем равным 0.
, за исключением расстояния между Рейкьявиком и самим собой, которое принимаем равным 0.
После этого, итеративно выполняем следующие шаги:
-
Выбираем узел с наименьшим значением в качестве «текущего узла» и посещаем всех соседей. При посещении каждого соседа, обновляем их ориентировочное расстояние от начального узла.
-
Как только мы посетим всех соседей текущего узла и обновили их расстояния, помечаем текущий узел как «посещенный»). Отметка узла как «посещенного» означает, что найдена его окончательная ценность.
-
Возвращаемся к 1 шагу и повторяем до тех пор, пока не посетим все узлы графа.
В нашем примере начинаем с отметки Рейкьявика, поскольку его значение равно 0, как «текущего узла». Далее посетим два соседних узла Рейкьявика: Лондон и Осло. В начале алгоритма их значения устанавливаются на бесконечность, но, когда мы посещаем узлы, то обновляем значение для Лондона до 4 и Осло до 5.
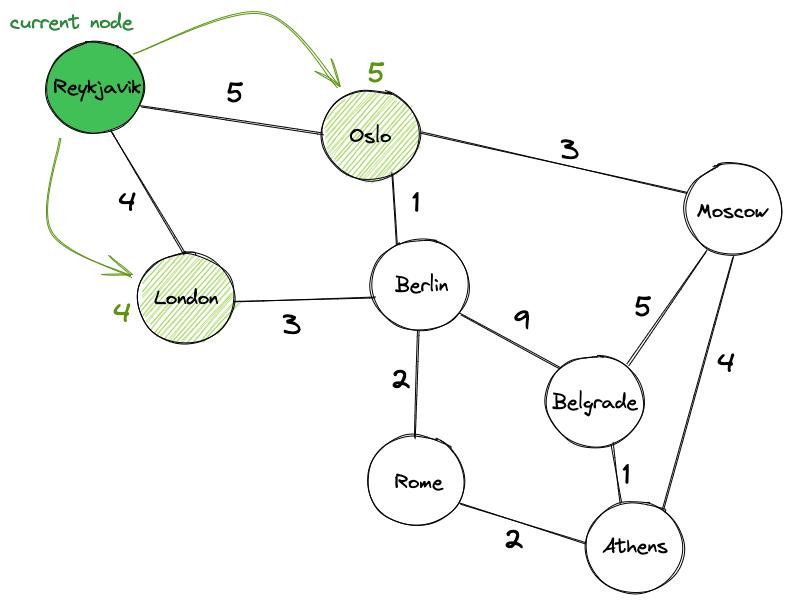
Затем отмечаем Рейкьявик как «посещенный». Мы знаем, что его окончательная стоимость равна нулю, и нам больше не нужно его посещать. Продолжаем со следующего узла с наименьшим значением, которым является Лондон.
Посещаем все соседние узлы Лондона, которые не помечены как «посещенные». Соседи Лондона — Рейкьявик и Берлин. Но мы игнорируем Рейкьявик, потому что мы уже были в нем. Вместо этого обновляем значение Берлина, добавляя значение ребра, соединяющего Лондон и Берлин (3), к значению Лондона (4), что дает нам значение 7.
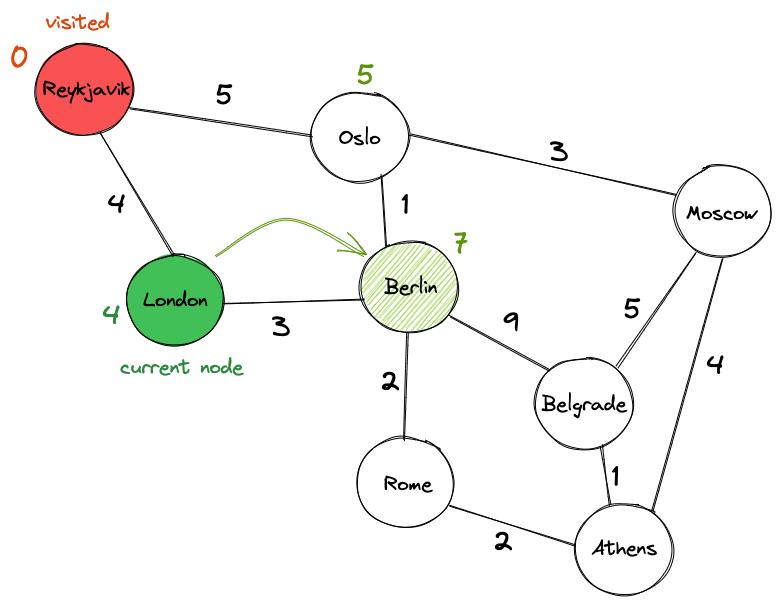
Отмечаем Лондон как посещенный и выбираем следующий узел — Осло. Посещаем соседей Осло и обновляем их ценности. Оказывается, можно лучше добраться до Берлина через Осло (со значением 6), чем через Лондон, поэтому соответствующим образом обновляем его значение. Также обновляем текущее значение Москвы с бесконечности до 8.
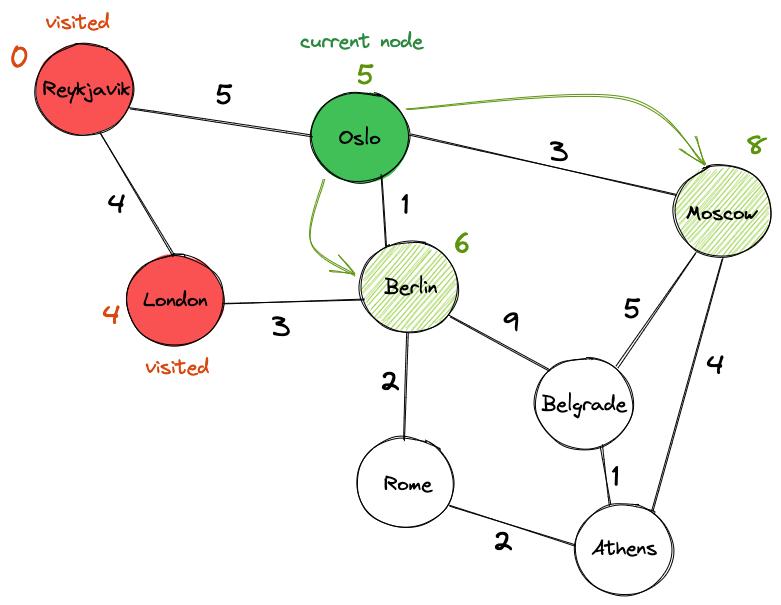
Отмечаем Осло как «посещенный» и обновляем его окончательное значение до 5. Между Берлином и Москвой выбираем Берлин в качестве следующего узла, потому что его значение (6) ниже, чем у Москвы (8). Действуем так же, как и раньше: посещаем Рим и Белград и обновляем их предварительные значения, прежде чем пометить Берлин как «посещенный» и перейти к следующему городу.
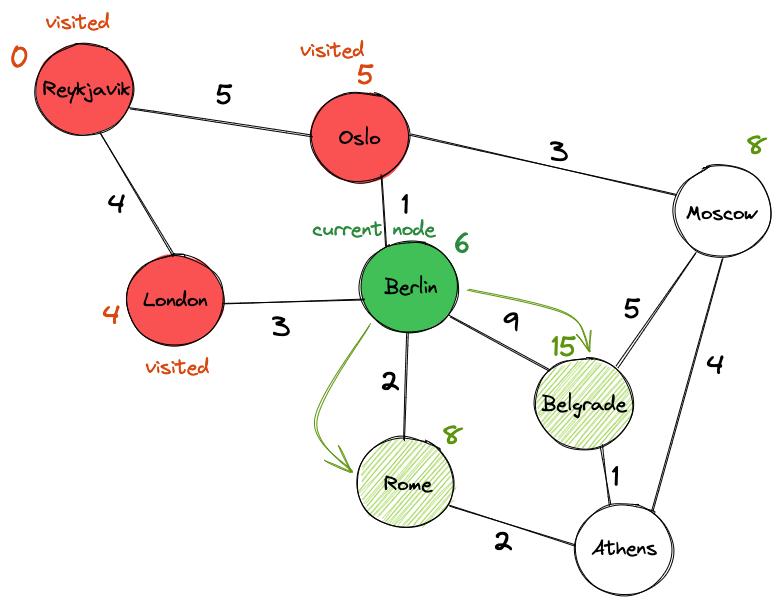
Обратите внимание, что мы уже нашли путь из Рейкьявика в Белград со значением 15. Но лучший ли он?
Не совсем. Опустим нахождение лучшего пути, им оказывается Рейкьявик ![]() Осло
Осло ![]() Берлин
Берлин ![]() Рим
Рим ![]() Афины
Афины ![]() Белград со значением 11.
Белград со значением 11.

Давайте наконец реализуем алгоритм Дейкстры на Python.
Класс Graph. Сначала создадим класс Graph. Этот класс не охватывает никакой логики алгоритма Дейкстры, но сделает реализацию алгоритма более лаконичной.
Реализуем граф как словарь. Ключи словаря будут соответствовать городам, а его значения будут соответствовать рёбрам, где записывают расстояния до других городов на графе:
import sys class Graph(object): def __init__(self, nodes, init_graph): self.nodes = nodes self.graph = self.construct_graph(nodes, init_graph) def construct_graph(self, nodes, init_graph): ''' Этот метод обеспечивает симметричность графика: если существует путь от узла A к B со значением V, должен быть путь от узла B к узлу A со значением V. ''' graph = {} for node in nodes: graph[node] = {} graph.update(init_graph) for node, edges in graph.items(): for adjacent_node, value in edges.items(): if graph[adjacent_node].get(node, False) == False: graph[adjacent_node][node] = value return graph def get_nodes(self): "Возвращает узлы графа" return self.nodes def get_outgoing_edges(self, node): "Возвращает соседей узла" connections = [] for out_node in self.nodes: if self.graph[node].get(out_node, False) != False: connections.append(out_node) return connections def value(self, node1, node2): "Возвращает значение ребра между двумя узлами." return self.graph[node1][node2] 
Реализация самого алгоритма. Начнем с определения функции.
def dijkstra_algorithm(graph, start_node): Функция принимает два аргумента: graph и start_node. graph — это экземпляр класса Graph, который мы создали на предыдущем шаге, тогда как start_node — это узел, с которого мы начнем вычисления. Мы вызовем метод get_nodes() для инициализации списка непосещённых узлов:
unvisited_nodes = list(graph.get_nodes()) Затем создадим два словаря, shorttest_path и previous_nodes:
-
Shorttest_pathбудет хранить наиболее известную стоимость посещения каждого города на графике, начиная с start_node. Вначале стоимость начинается с бесконечности, но мы будем обновлять значения по мере продвижения по графику. -
previous_nodesбудет хранить траекторию текущего наиболее известного пути для каждого узла. Например, если нам известен лучший способ добраться до Берлина через Осло,previous_nodes["Берлин"]вернет «Осло», аprevious_nodes[Осло]вернет «Рейкьявик». Мы будем использовать этот словарь, чтобы найти кратчайший путь.
shortest_path = {} previous_nodes = {} # Мы будем использовать max_value для инициализации значения "бесконечности" непосещенных узлов max_value = sys.maxsize for node in unvisited_nodes: shortest_path[node] = max_value # Однако мы инициализируем значение начального узла 0 shortest_path[start_node] = 0 Теперь можно запустить алгоритм. Помните, что алгоритм Дейкстры выполняется до тех пор, пока не посетит все узлы в графе, поэтому представим это как условие выхода из цикла while.
while unvisited_nodes: Теперь алгоритм может начать посещать узлы. Приведенный ниже блок кода сначала инструктирует алгоритм найти узел с наименьшим значением.
current_min_node = None for node in unvisited_nodes: # Iterate over the nodes if current_min_node == None: current_min_node = node elif shortest_path[node] < shortest_path[current_min_node]: current_min_node = node После этого алгоритм посещает всех соседей узла, которые еще не посещены. Если новый путь к соседу лучше, чем текущий лучший путь, алгоритм вносит корректировки в словари shorttest_path и previous_nodes.
# Приведенный ниже блок кода извлекает соседей текущего узла и обновляет их расстояния. neighbors = graph.get_outgoing_edges(current_min_node) for neighbor in neighbors: tentative_value = shortest_path[current_min_node] + graph.value(current_min_node, neighbor) if tentative_value < shortest_path[neighbor]: shortest_path[neighbor] = tentative_value # Мы также обновляем лучший путь к текущему узлу previous_nodes[neighbor] = current_min_node После посещения всех его соседей мы можем пометить текущий узел как «посещенный»:
unvisited_nodes.remove(current_min_node) Наконец, мы можем вернуть два словаря:
return previous_nodes, shortest_path В итоге, весь алгоритм выглядит так:
def dijkstra_algorithm(graph, start_node): unvisited_nodes = list(graph.get_nodes()) # Мы будем использовать этот словарь, чтобы сэкономить на посещении каждого узла и обновлять его по мере продвижения по графику shortest_path = {} # тут храним кратчайший известный путь к найденному узлу previous_nodes = {} # инициализируем max_value как ? для непосещенных узлов max_value = sys.maxsize for node in unvisited_nodes: shortest_path[node] = max_value # инициализируем значение начального узла как 0 shortest_path[start_node] = 0 # до тех пор, пока не посетим все узлы while unvisited_nodes: # находим узел с наименьшей оценкой current_min_node = None for node in unvisited_nodes: # Iterate over the nodes if current_min_node == None: current_min_node = node elif shortest_path[node] < shortest_path[current_min_node]: current_min_node = node # извлекаем соседей текущего узла и обновляем их расстояния neighbors = graph.get_outgoing_edges(current_min_node) for neighbor in neighbors: tentative_value = shortest_path[current_min_node] + graph.value(current_min_node, neighbor) if tentative_value < shortest_path[neighbor]: shortest_path[neighbor] = tentative_value # We also update the best path to the current node previous_nodes[neighbor] = current_min_node # после посещения соседей отмечаем узел как "посещенный" unvisited_nodes.remove(current_min_node) return previous_nodes, shortest_path 
Вспомогательная функция для печати результатов. Наконец, нам нужно создать функцию, которая печатает результаты. Эта функция будет принимать два словаря, возвращаемые функцией dijskstra_algorithm, а также имена начального и целевого узлов. Он будет использовать два словаря, чтобы найти лучший путь и сделать его оценку.
def print_result(previous_nodes, shortest_path, start_node, target_node): path = [] node = target_node while node != start_node: path.append(node) node = previous_nodes[node] # Add the start node manually path.append(start_node) print("Найден следующий лучший маршрут {}.".format(shortest_path[target_node])) print(" -> ".join(reversed(path))) 
Теперь посмотрим, как работает алгоритм. Вручную инициализируем узлы и их рёбра.
nodes = ["Reykjavik", "Oslo", "Moscow", "London", "Rome", "Berlin", "Belgrade", "Athens"] init_graph = {} for node in nodes: init_graph[node] = {} init_graph["Reykjavik"]["Oslo"] = 5 init_graph["Reykjavik"]["London"] = 4 init_graph["Oslo"]["Berlin"] = 1 init_graph["Oslo"]["Moscow"] = 3 init_graph["Moscow"]["Belgrade"] = 5 init_graph["Moscow"]["Athens"] = 4 init_graph["Athens"]["Belgrade"] = 1 init_graph["Rome"]["Berlin"] = 2 init_graph["Rome"]["Athens"] = 2 Будем использовать эти значения для создания объекта класса Graph.
graph = Graph(nodes, init_graph) Когда наш граф полностью построен, можно передать его функции dijkstra_algorithm().
previous_nodes, shortest_path = dijkstra_algorithm(graph=graph, start_node="Reykjavik") А теперь распечатываем результаты:
print_result(previous_nodes, shortest_path, start_node="Reykjavik", target_node="Belgrade") Готово!

The end
Итак, мы рассмотрели то, что с вероятностью 99% попадётся на алгособесе: асимптотический анализ, основные структуры данных, разные алгоритмы сортировки, ну и алгоритм Дейкстры как бонус.
Вообще, для полной уверенности на собеседовании, можно полистать хотя бы по диагонали вот это:
-
«Теоретический минимум по Computer Science» — Владстон Феррейра Фило, Мото Пиктет
-
конечно же «Грокаем алгоритмы» — Адитья Бхаргава
Можете накидать свои любимые книги в комментах, уверен, многим будет полезно
Успешных собесов)
Источник: habr.com