Обнаружение объектов. Часть 2: Локализация и классификация
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2024-02-11 18:00

Простая локализация и классификация объектов с использованием сборки сверточной нейронной сети с помощью Tensorflow/Keras на Python.
В моем предыдущем посте я писал о простой проблеме локализации объекта: предсказании ограничивающей рамки одного прямоугольника на нейтральном фоне. Однако этот подход был ограничен одной формой и не позволял различать несколько форм. В этом посте я решу эту проблему, расширив предыдущую модель, чтобы она могла классифицировать и форму объектов.
Для этого я создам простой игрушечный набор данных и построю простую CNN с двумя головками: головкой регрессии для прогнозирования ограничивающей рамки и головкой классификации для распознавания формы.
Задание
Входные данные сети — это  изображение с черным фоном, отображающее одну из трех фигур: прямоугольник, круг или треугольник. Для простоты я решил использовать изображения в оттенках серого вместо цветных.
изображение с черным фоном, отображающее одну из трех фигур: прямоугольник, круг или треугольник. Для простоты я решил использовать изображения в оттенках серого вместо цветных.

У сети две основные цели: локализация объекта и классификация формы. Локализация происходит путем прогнозирования ограничивающей рамки фигуры, которая имеет форму  , где
, где  это координаты верхнего левого угла, а
это координаты верхнего левого угла, а  и
и  ширина и высота соответственно. Для классификации будет использоваться вектор горячего кодирования. Таким образом, конечный целевой вектор имеет форму
ширина и высота соответственно. Для классификации будет использоваться вектор горячего кодирования. Таким образом, конечный целевой вектор имеет форму  , где первые три позиции отвечают за классификацию формы ( прямоугольник, круг, треугольник ), а последние четыре — за предсказание ограничивающей рамки.
, где первые три позиции отвечают за классификацию формы ( прямоугольник, круг, треугольник ), а последние четыре — за предсказание ограничивающей рамки.
Создать набор данных
Как и в предыдущем посте, я создам набор данных самостоятельно, используя numpy и OpenCV. Визуализация осуществляется с помощью matplotlib. Изображения будут иметь форму  , а минимальный размер каждого объекта в пикселях
, а минимальный размер каждого объекта в пикселях  . Для каждого класса будет создано 10 000 изображений.
. Для каждого класса будет создано 10 000 изображений.
import numpy as np import matplotlib.pyplot as plt import cv2 n_samples_per_class = 10000 image_size = 64 min_size = 12Создание прямоугольников довольно простое. Сначала  создается массив изображений с размерностью , где
создается массив изображений с размерностью , где  соответствует цветовому каналу (серый = 1). Тогда
соответствует цветовому каналу (серый = 1). Тогда  ,
,  , и генерируются случайным образом с соблюдением минимального размера. После этого функция OpenCV
, и генерируются случайным образом с соблюдением минимального размера. После этого функция OpenCV  используется для добавления прямоугольника в массив черных изображений. Функция возвращает изображение, а также целевой вектор, который состоит из горячего кодирования классификации
используется для добавления прямоугольника в массив черных изображений. Функция возвращает изображение, а также целевой вектор, который состоит из горячего кодирования классификации ![[1, 0, 0]](https://johfischer.com/wp-content/ql-cache/quicklatex.com-2d3a54a0d902e111906139813b2f7252_l3.svg) , указывающего, что фигура представляет собой прямоугольник, и соответствующих значений ограничивающей рамки
, указывающего, что фигура представляет собой прямоугольник, и соответствующих значений ограничивающей рамки ![[х, у, ш, ч]](https://johfischer.com/wp-content/ql-cache/quicklatex.com-2de64e122964d2af9a9624a30053da14_l3.svg) .
.
def create_rectangleXY(img_size, min_obj_size): x_rect = np.zeros((img_size, img_size, 1), dtype="uint8") # get random top-left corner x, y = np.random.randint(0, img_size - min_obj_size, 2) # get random width and height w = np.random.randint(min_obj_size, img_size - x) h = np.random.randint(min_obj_size, img_size - y) color = np.random.randint(150, 255, dtype=int) cv2.rectangle(x_rect, (x, y), (x+w,y+h), color, -1, lineType=cv2.LINE_AA) return x_rect, [1, 0, 0, x, y, w, h]Изображение круга генерируется аналогичным образом, но вместо генерации случайной ширины и высоты случайным образом генерируется радиус.
def create_circleXY(img_size, min_obj_size): x_circle = np.zeros((img_size, img_size, 1), dtype="uint8") # get random radius radius = np.random.randint(min_obj_size // 2, img_size // 2) # get random top-left corner x, y = np.random.randint(radius, img_size - radius, 2) color = np.random.randint(150, 255, dtype=int) cv2.circle(x_circle, (x, y), radius, color, -1, lineType=cv2.LINE_AA) return x_circle, [0, 1, 0, x-radius, y-radius, radius*2, radius*2]Наконец, нам нужна функция для создания треугольников. Это делается путем генерации случайных , , и , с помощью которых можно создать четыре точки прямоугольника. Затем одна из этих четырех точек случайным образом удаляется, а оставшиеся три точки используются как углы треугольника.
def create_triangleXY(img_size, min_obj_size): x_triangle = np.zeros((image_size, image_size, 1), dtype="uint8") # get random top-left corner x, y = np.random.randint(0, image_size - min_size, 2) # get random width and height w = np.random.randint(min_size, image_size - x) h = np.random.randint(min_size, image_size - y) # create all four points from x,y,w,h pts = [(x,y), (x+w, y+h), (x+w, y), (x, y+h)] # select 3 points as edges for the triangle pts.pop(np.random.randint(0, len(pts)-1)) color = np.random.randint(150, 255, dtype=int) cv2.drawContours(x_triangle, [np.array( pts )], 0, color, -1, lineType=cv2.LINE_AA) return x_triangle, [0, 0, 1, x, y, w, h]Теперь мы можем собрать все вместе и создать наш набор данных следующим образом.
np.random.seed(280295) X = [] Y = [] for i in range(n_samples_per_class): # rectangle image x_rect, y_rect = create_rectangleXY(image_size, min_size) X.append(x_rect) Y.append(y_rect) # circle image x_circle, y_circle = create_circleXY(image_size, min_size) X.append(x_circle) Y.append(y_circle) # triangle image x_triangle, y_triangle = create_triangleXY(image_size, min_size) X.append(x_triangle) Y.append(y_triangle) X = np.array( X ) Y = np.array( Y ) print("X: ", X.shape) # (30000, 64, 64, 1) print("Y: ", Y.shape) # (30000, 7)Позже мы также реализуем функцию, которая преобразует вектор горячего кодирования в письменную метку. Например, ![[1, 0, 0] ightarrow](https://johfischer.com/wp-content/ql-cache/quicklatex.com-b12e35ace14be9af71974ed9b25f7039_l3.svg) прямоугольник .
прямоугольник .
LABELS = ['rect', 'circle', 'triangle'] def onehot2label(onehot_vec): return LABELS[np.argmax(onehot_vec)]Теперь давайте отобразим некоторые из наших данных, чтобы проверить, правильно ли они сработали.
plt.figure(figsize=(12, 5)) for i in range(10): ax = plt.subplot(2, 5, i+1) plt.imshow(X[i], "gray") plt.title(onehot2label(Y[i, :3]) ) plt.show()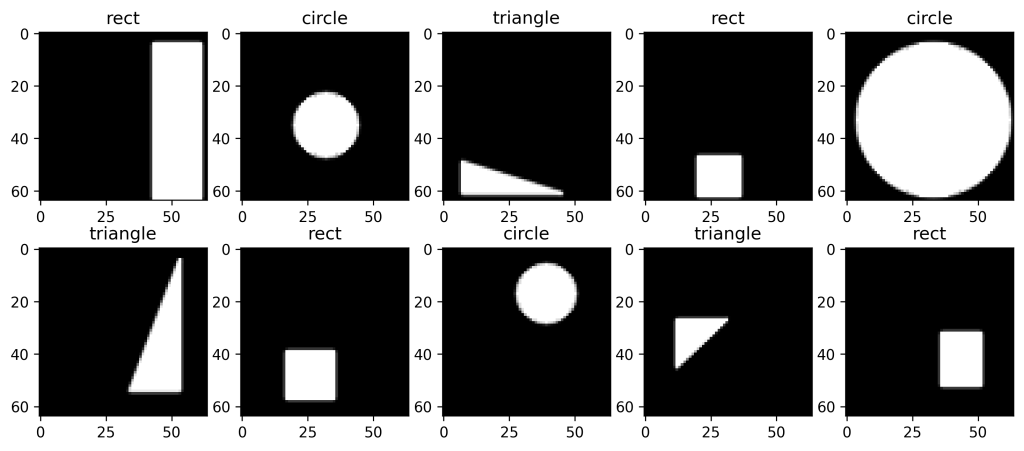
Подготовьте данные
При обработке изображений принято нормализовать значение пикселя по центру вокруг 0, что я и сделаю, разделив значения изображения на 255 (максимальное значение RGB) и вычитая 0,5. Кроме того, я перетасую данные, так как на данный момент образцы заказаны.
from sklearn.utils import shuffle # normalize and center pixel values X = (X.astype("float32") / 255 ) - 0.5 X, Y = shuffle(X, Y)Следующим шагом является разделение набора данных на обучающий, проверочный и тестовый набор.
from sklearn.model_selection import train_test_split X_train_val, X_test, Y_train_val, Y_test = train_test_split(X, Y, test_size=0.2) # further split train_val X_train, X_val, Y_train, Y_val = train_test_split(X_train_val, Y_train_val, test_size=0.2, random_state=29) print("Shape X train: ", X_train.shape) # (19200, 64, 64, 1) print("Shape X validate: ", X_val.shape) # (4800, 64, 64, 1) print("Shape X test: ", X_test.shape) # (6000, 64, 64, 1)Сверточная нейронная сеть
Цель сети — предсказать ограничивающую рамку, а также класс объекта. Следовательно, у нас есть регрессия, а также проблема классификации. Для задач регрессии среднеквадратическая ошибка обычно является подходящей функцией потерь, тогда как для задач классификации часто лучше использовать категориальную перекрестную энтропию.
Кроме того, для классификации обычно используется функция активации Softmax, поскольку она преобразует выходные данные в распределение вероятностей, где каждый выходной сигнал находится в диапазоне, ![[0, 1]](https://johfischer.com/wp-content/ql-cache/quicklatex.com-caffaae885a1287e3dfc31bfb1cd0694_l3.svg) и все выходные данные в сумме дают 1.
и все выходные данные в сумме дают 1.
![[softmax(y_i) = frac{e^{y_i}}{sum_{j=1}^{n} e^{y_j}}.]](https://johfischer.com/wp-content/ql-cache/quicklatex.com-965f2f86b1fbb197d59dc8b8350b1ed7_l3.svg)
Следовательно, чтобы иметь как результаты классификации, так и результаты регрессии, нам нужно разделить выходные данные сетей на две части. Тогда архитектура будет следующей:
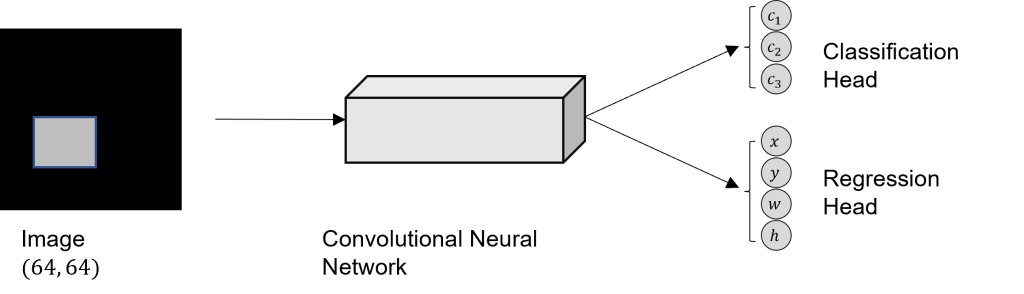
Для двух голов сети (регрессии и классификации) нам нужно разделить целевой вектор  .
.
Y_train_split = (Y_train[:, :3], Y_train[:, 3:]) Y_val_split = (Y_val[:, :3], Y_val[:, 3:]) Y_test_split = (Y_test[:, :3], Y_test[:, 3:])Теперь пришло время построить окончательную модель. Эта сеть не представляет собой линейный стек слоев, поэтому нам нужно использовать функциональный API Tensorflow, который позволяет реализовать две выходные головки.
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Dense from tensorflow.keras.layers import Flatten, Dropout from tensorflow.keras import Input, Model inputs = Input(shape=(image_size, image_size, 1)) x = Conv2D(16, kernel_size=(3,3), activation="relu")(inputs) x = MaxPooling2D(pool_size=(2,2))(x) x = Conv2D(32, kernel_size=(3,3), activation="relu")(x) x = MaxPooling2D(pool_size=(2,2))(x) x = Flatten()(x) x = Dropout(0.5)(x) class_out = Dense(3, activation="softmax", name="class")(x) bbox_out = Dense(4, name="bbox")(x) model = Model(inputs=inputs, outputs=(class_out, bbox_out))Как вы можете видеть в этом блоке кода, мы сначала создаем простой линейный стек сверточных слоев и слоев с максимальным пулом, которые свертывают изображение. Затем входные данные сглаживаются и добавляется выпадающий слой, чтобы предотвратить переобучение. Теперь самое сложное. Выходные данные слоя исключения передаются как в плотный слой для классификации с активацией Softmax, так и в плотный слой для регрессии. Чтобы лучше представить себе, что произошло, давайте построим модель.
from tensorflow.keras.utils import plot_model plot_model(model, "./blog images/model_regAndClassHead.png", show_shapes=True)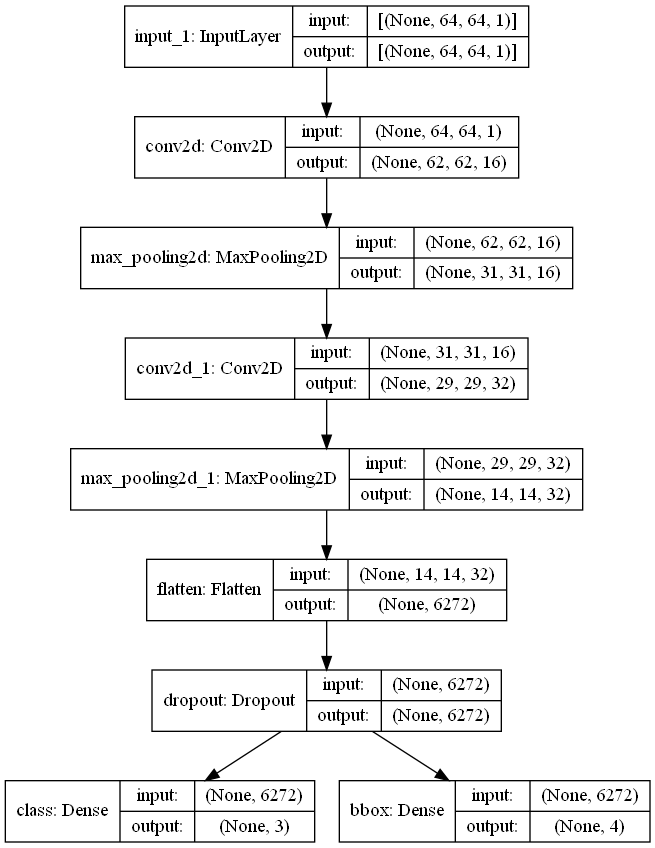
Теперь ясно видно, что выходные данные слоя исключения передаются как в классификацию, так и в головку регрессии.
Пришло время скомпилировать модель.
model.compile("adam", loss=['categorical_crossentropy', 'mse'], metrics=["accuracy"])Я использую Оптимизатор Адама и два разных Потери, по одному на каждую голову. Головка классификации обучается с использованием категориальной перекрестной энтропийной потери и головы регрессии со среднеквадратической ошибкой.
Пришло время обучить модель. Здесь важно передать разделенную версию целевого вектора .
%%time epochs = 35 history = model.fit(X_train, Y_train_split, epochs=epochs, validation_data=(X_val, Y_val_split))Обучение модели в течение 35 эпох на моей установке (графический процессор: Nvidia GeForce GTX 1050 Ti, процессор: Intel i5-3470) занимает около 3 минут 57 секунд.
Полученные результаты
Оценивая историю процесса обучения, можно увидеть, как уменьшаются потери обеих головок, а точность классификации увеличивается с течением времени.
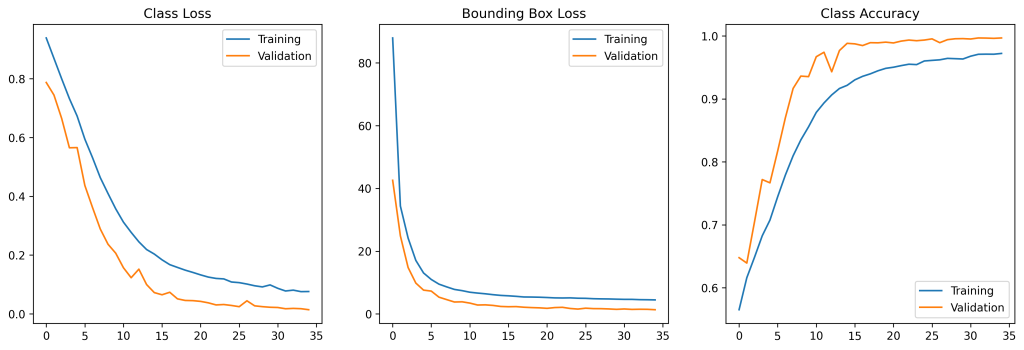
Давайте оценим модель на (невидимых) тестовых данных.
metrics = model.evaluate(X_test, Y_test_split) for i, name in enumerate(model.metrics_names): print(name.replace("_", " ") + ": %.4f" % metrics[i]) # OUTPUT # loss: 1.3797 # class loss: 0.0173 # bbox loss: 1.3624 # class accuracy: 0.9960 # bbox accuracy: 0.9470В классификации модель работает достаточно хорошо, с потерей точности  в
в  %. Но, по правде говоря, эту задачу для сети освоить не так уж и сложно.
%. Но, по правде говоря, эту задачу для сети освоить не так уж и сложно.
Но и потеря среднеквадратической ошибки для регрессии ограничивающего прямоугольника кажется хорошей. Опять же, как упоминалось в предыдущем посте, точность регрессии ограничивающей рамки не является хорошим показателем оценки. Среднее значение пересечения по объединению здесь является лучшим показателем точности.
Примечание. Если вы не знаете, что такое Пересечение через Объединение, я бы рекомендовал прочитать этот пост.
# predict test set preds = model.predict(X_test) # compute mean IoU mean_IoU = IoU(Y_test_split[1], preds[1]) print("Mean IoU: %.2f%%" % (mean_IoU*100)) # Mean IoU: 84.84%Среднее Пересечение над Союзом  — это не так уж и плохо. Давайте визуализируем некоторые примеры нашего тестового набора:
— это не так уж и плохо. Давайте визуализируем некоторые примеры нашего тестового набора:
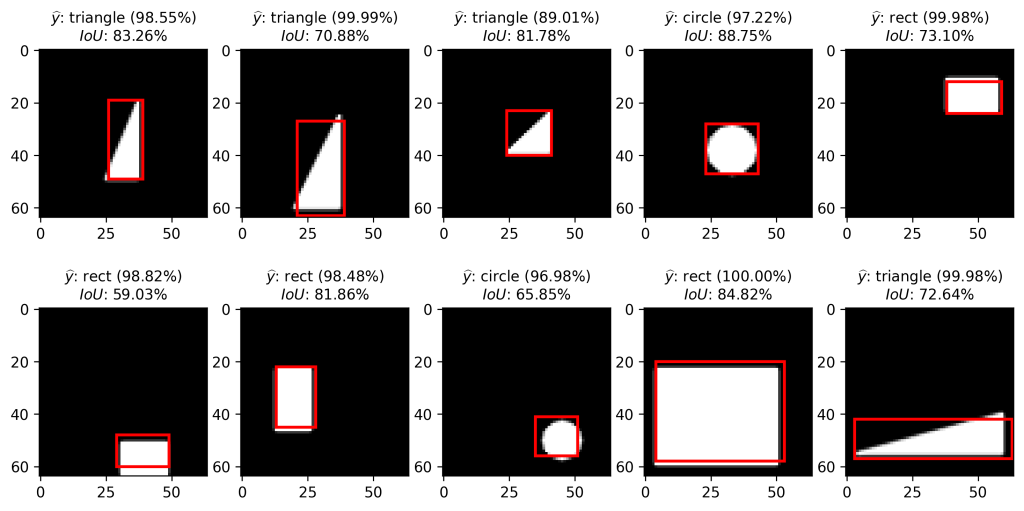
Каждая из фигур была правильно распознана, и каждая ограничивающая рамка была предсказана относительно точно.
Заключение
В этом сообщении блога мы создаем простую сверточную нейронную сеть, которая способна локализовать и классифицировать фигуру на нейтральном фоне. Для этого мы разделили голову сети на голову регрессии и классификации ограничительной рамки.
Однако по-прежнему существует недостаток: модель может классифицировать и локализовать только один объект на изображении. Как мы можем классифицировать и локализовать несколько объектов на изображении? В следующем посте я попытаюсь решить эту проблему и построить модель, которая сможет распознавать несколько фигур на изображении.
Если у вас есть какие-либо комментарии или сомнения по поводу того, что я уже сделал, не стесняйтесь оставлять комментарии или писать по электронной почте.
Телеграм: t.me/ainewsline
Источник: johfischer.com