Лгоритм K-ближайшего соседа (KNN) в машинном обучении
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2024-02-26 18:36

KNN — это достаточно простой метод классификации, который определяет класс, к которому принадлежит образец, путем измерения его сходства с другими близлежащими точками.
Хотя это элементарно для понимания, это мощный метод определения класса неизвестной точки выборки.
В этой статье мы подробно рассмотрим алгоритм KNN в машинном обучении, как он работает, его преимущества и недостатки, приложения и т. д. Мы также представим код Python для алгоритма KNN в машинном обучении для лучшего понимания читателей.
Кроме того, мы настоятельно рекомендуем наш комплексный курс машинного обучения , который охватывает широкий спектр тем, включая алгоритм KNN, чтобы помочь читателям углубить свое понимание и практические навыки в этой области.
Давайте начнем
Введение в алгоритм KNN в машинном обучении
Существует три основных подмножества машинного обучения:
Обучение с учителем , обучение без учителя и обучение с подкреплением.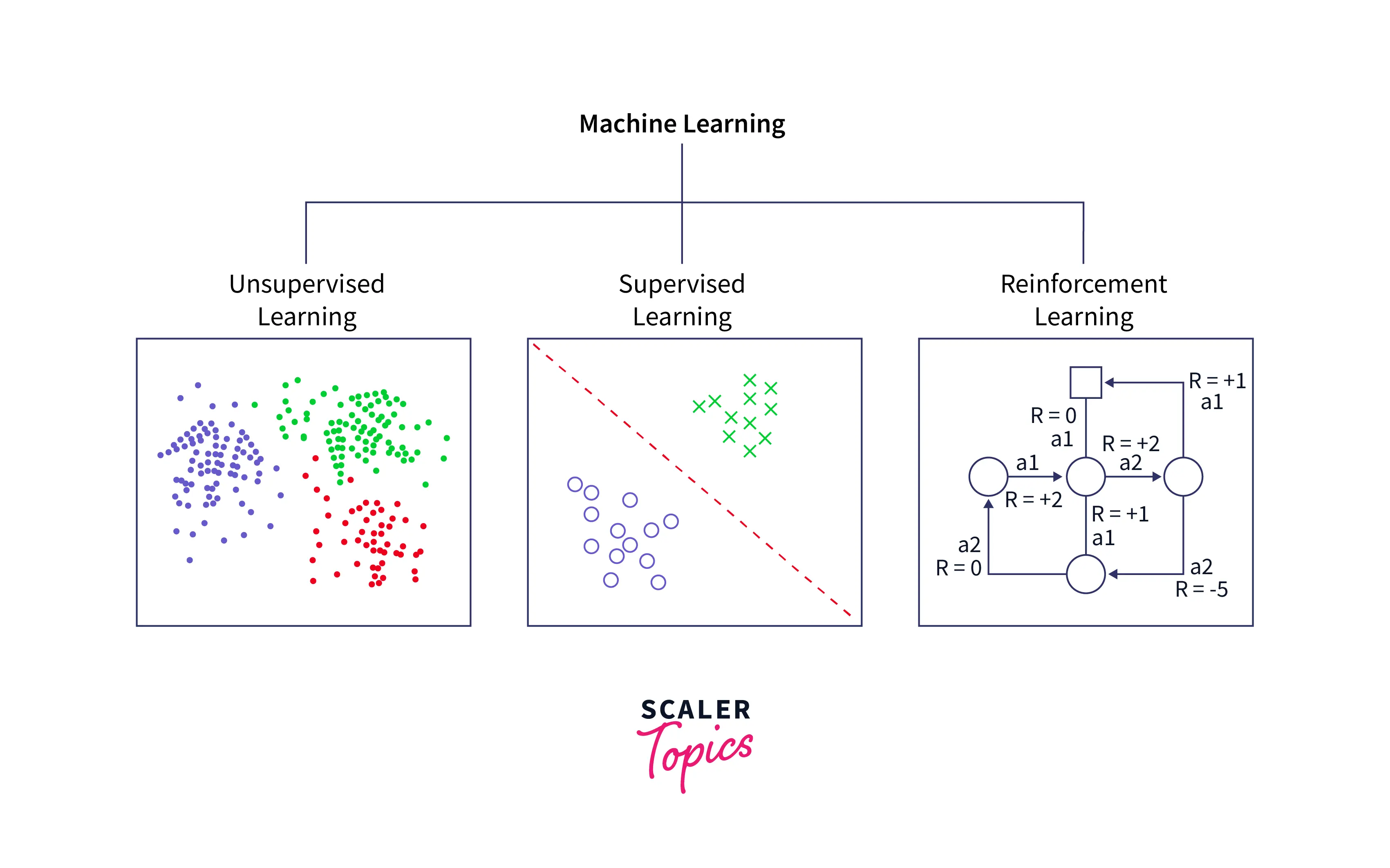
При обучении без учителя мы пытаемся решить проблему, не используя прошлые данные. Например, учитывая диаграмму рассеяния, наша задача — найти соответствующие кластеры и соответствующим образом сгруппировать данные.
В обучении с подкреплением мы определяем набор благоприятных результатов и набор неблагоприятных результатов. Затем алгоритму разрешается исследовать проблемное пространство. Если он достигает благоприятного результата, он пытается повторить действия, которые к нему привели, а если достигает неблагоприятного результата, он пытается избежать действий, которые к нему привели.
При обучении с учителем вам предоставляется набор входных данных и набор правильных выходных данных.
Используя эти контрольные данные, вам необходимо написать алгоритм, который изучает закономерности на основе этих сопоставлений ввода-вывода, чтобы в следующий раз, когда вы получите новые входные данные, вы могли точно оценить соответствующие выходные данные. Учитывая площади многих соседних домов (в квадратных футах) и их цены, мы можем спрогнозировать цену нового дома.
Зная биологические параметры многих опухолей (размер клеток, форму клеток и т. д.) и то, являются ли они доброкачественными или злокачественными, мы можем предсказать поведение новой, неизвестной опухоли. Этот конкретный пример называется проблемой классификации, и именно ее решает KNN.
Важно отметить, что тип обучения зависит не от того, какой из них выглядит лучше или имеет лучшую точность, а от характера проблемы.
Как работают K-ближайшие соседи?
Шаги для алгоритма KNN в машинном обучении следующие:
- Шаг 1:
выберите количество K соседей. - Шаг 2:
Рассчитайте евклидово расстояние каждой точки от целевой точки. - Шаг 3.
Возьмите K ближайших соседей на рассчитанное евклидово расстояние. - Шаг 4.
Среди этих k соседей подсчитайте количество точек данных в каждой категории. - Шаг 5.
Назначьте новые точки данных той категории, для которой количество соседей максимально.
Предположим, у нас есть новая точка данных, и нам нужно поместить ее в требуемую категорию. Рассмотрим изображение ниже:
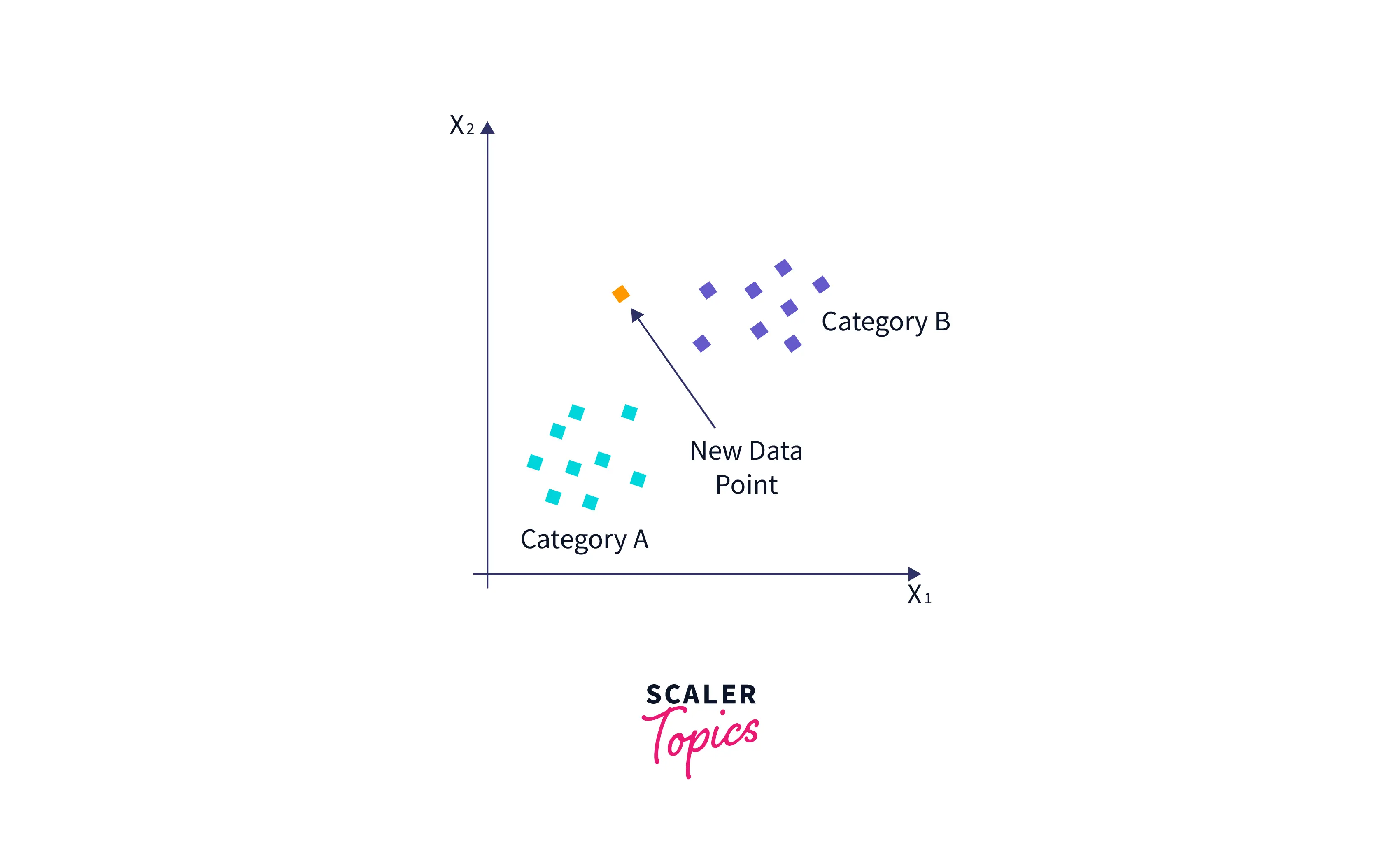
- Сначала мы выберем количество соседей k=5 .
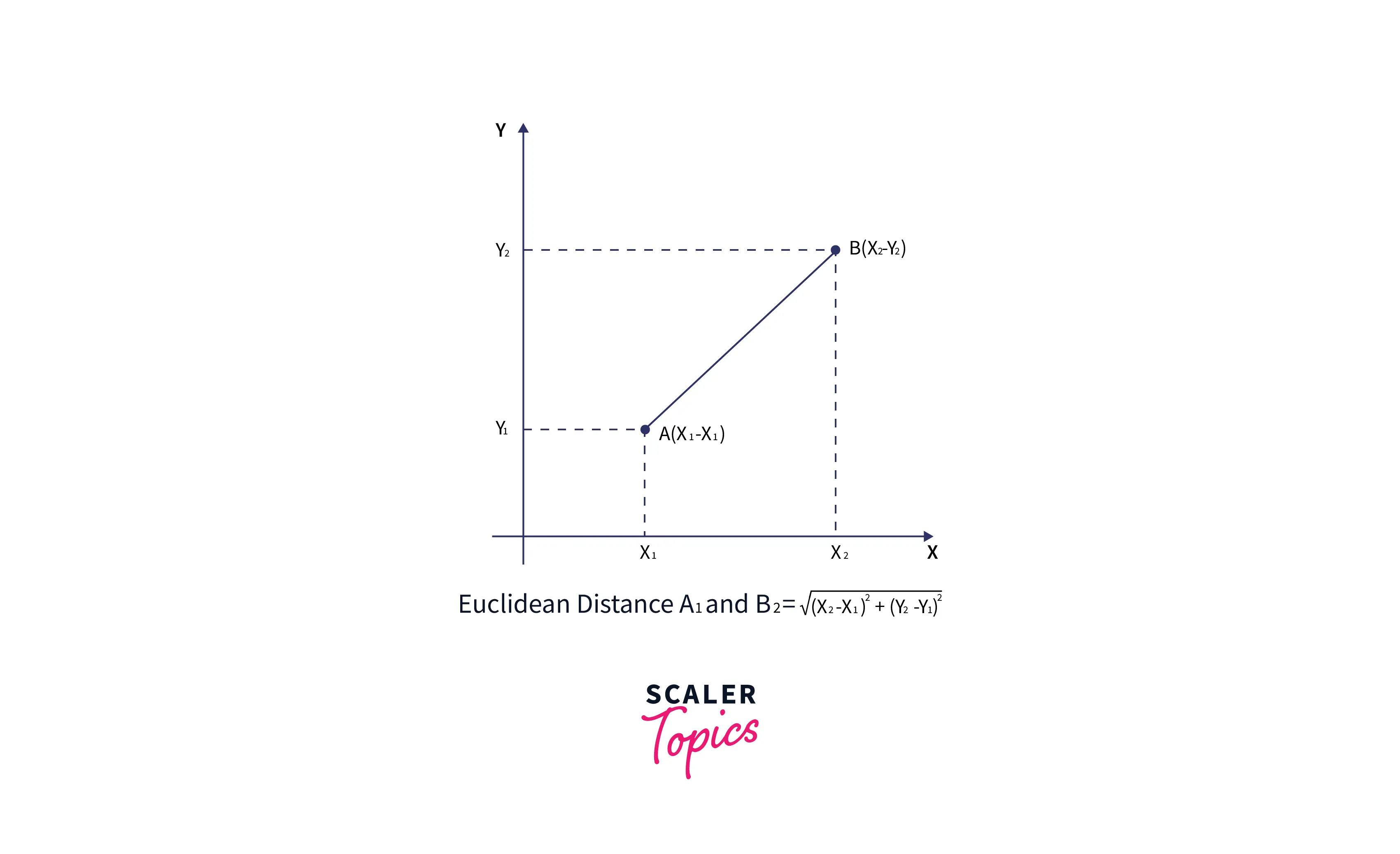
- Далее мы рассчитаем евклидово расстояние между точками данных. Евклидово расстояние – это расстояние между двумя точками, которое мы уже изучали в геометрии. Его можно рассчитать как:
- Вычислив евклидово расстояние, мы получили ближайших соседей: трех ближайших соседей в категории A и двух ближайших соседей в категории B. Рассмотрим изображение ниже:
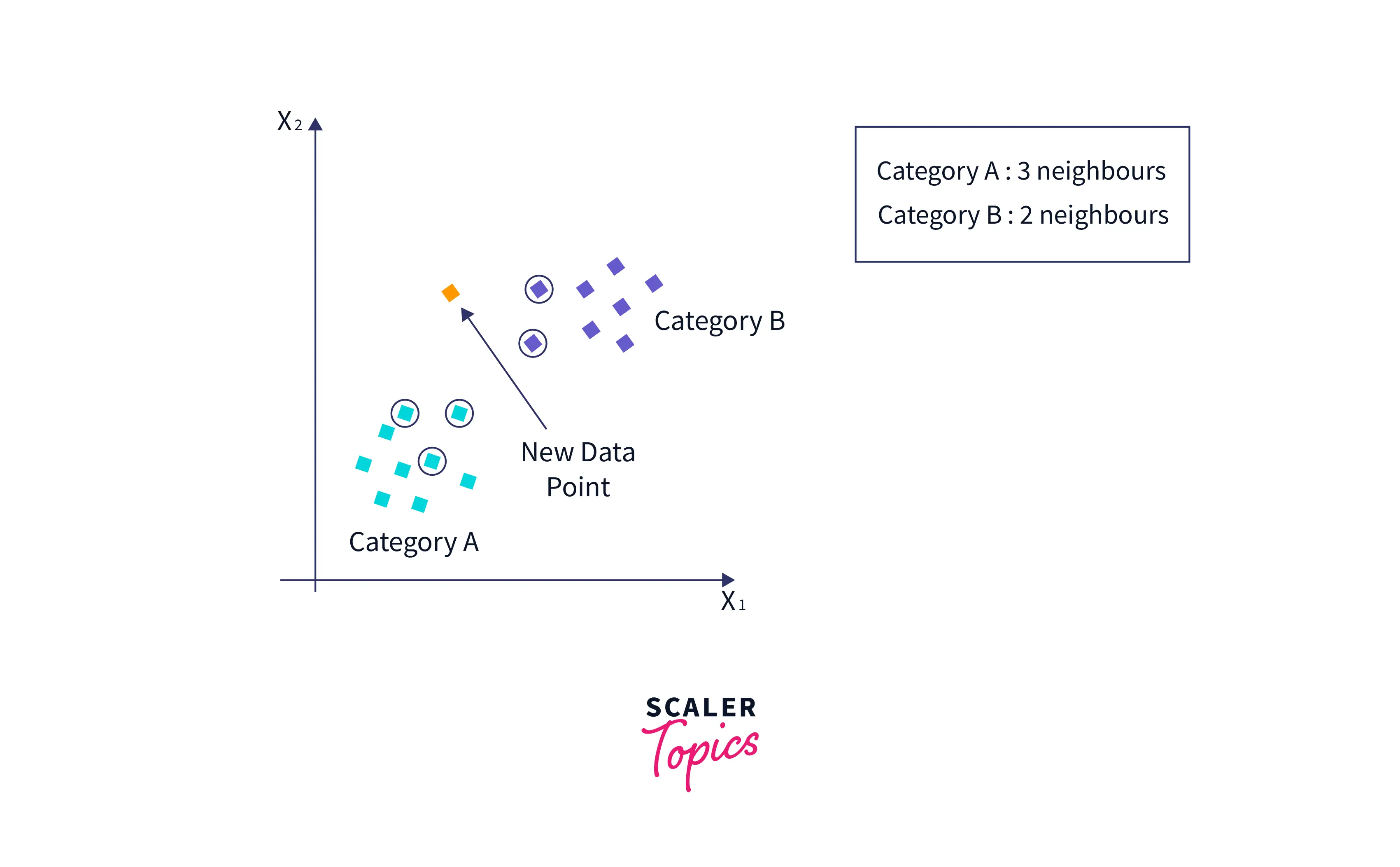
- Как мы видим, три ближайших соседа из категории А. Следовательно , эта новая точка данных должна принадлежать категории A.
Зачем нам нужен алгоритм K-ближайших соседей?
K Nearest Neighbor — один из фундаментальных алгоритмов машинного обучения. Модели машинного обучения используют набор входных значений для прогнозирования выходных значений. KNN — это одна из простейших форм алгоритмов машинного обучения, которая чаще всего используется для классификации. Он классифицирует точку данных в зависимости от того, как классифицируется ее сосед.
KNN классифицирует новые точки данных на основе меры сходства ранее сохраненных точек данных. Например, если у нас есть набор данных о помидорах и бананах. KNN сохранит аналогичные критерии, такие как форма и цвет. Затем, когда появится новый предмет, он проверит его сходство по цвету (красному или желтому) и форме.
Как определить значение К?
Выбор подходящего значения k в KNN имеет решающее значение для получения максимальной отдачи от модели. Если значение K мало, частота ошибок модели будет большой, особенно для новых точек данных, поскольку количество голосов невелико. Следовательно, модель переоснащена и очень чувствительна к шуму на входе. Более того, границы классификации становятся слишком жесткими, как видно на изображении ниже.
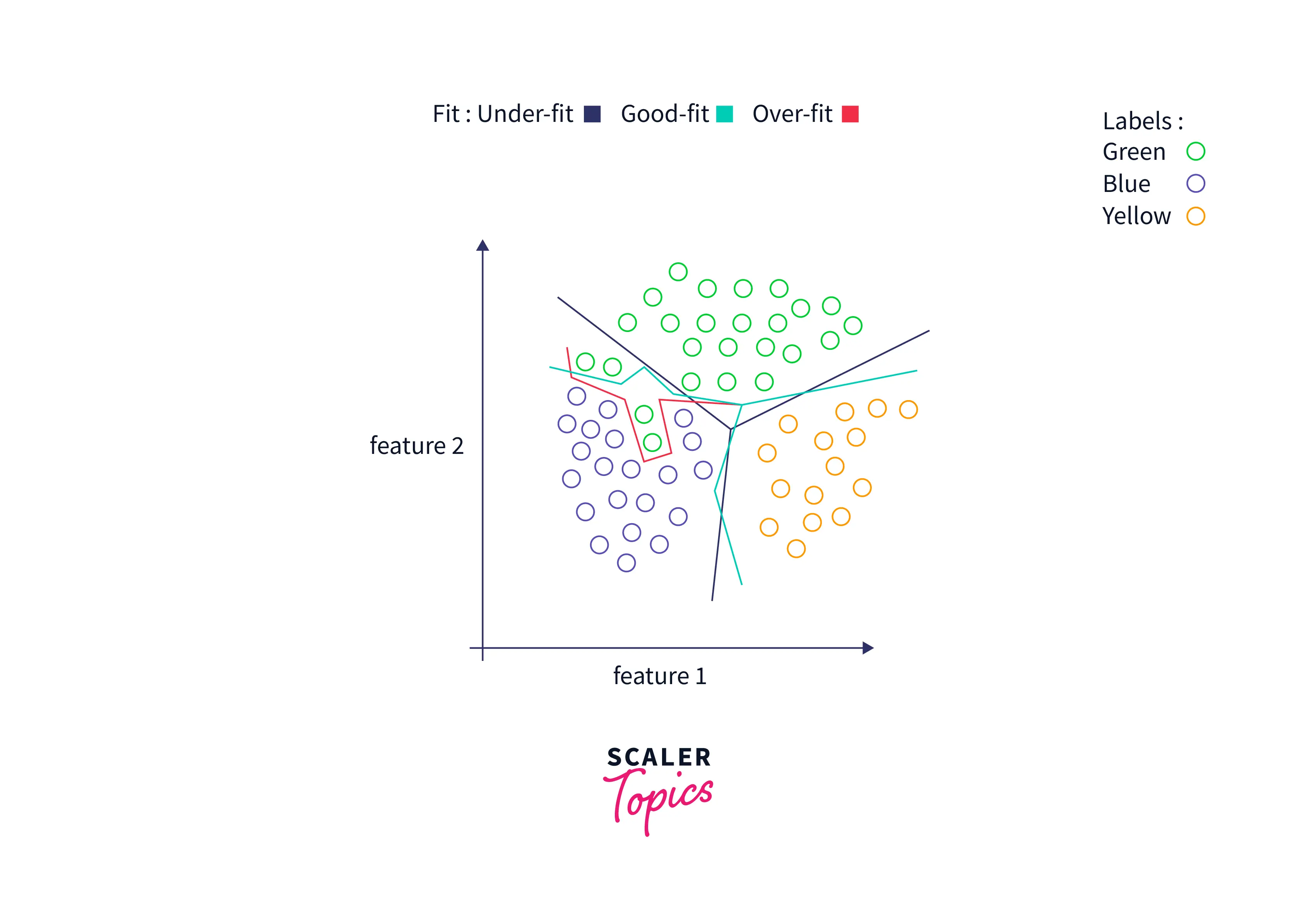 С другой стороны, если значение K велико, границы модели становятся размытыми и количество ошибочных классификаций увеличивается. В этом случае говорят, что модель недооснащена.
С другой стороны, если значение K велико, границы модели становятся размытыми и количество ошибочных классификаций увеличивается. В этом случае говорят, что модель недооснащена.
Не существует фиксированного метода определения k , но могут помочь следующие моменты:
Задайте K как нечетное число, чтобы у нас было дополнительное очко для решения тай-брейков в крайних случаях.
Приличное значение k может быть квадратным корнем из количества точек данных, включенных в набор обучающих данных. Конечно, этот метод может работать не во всех случаях.
Постройте график зависимости частоты ошибок от K :
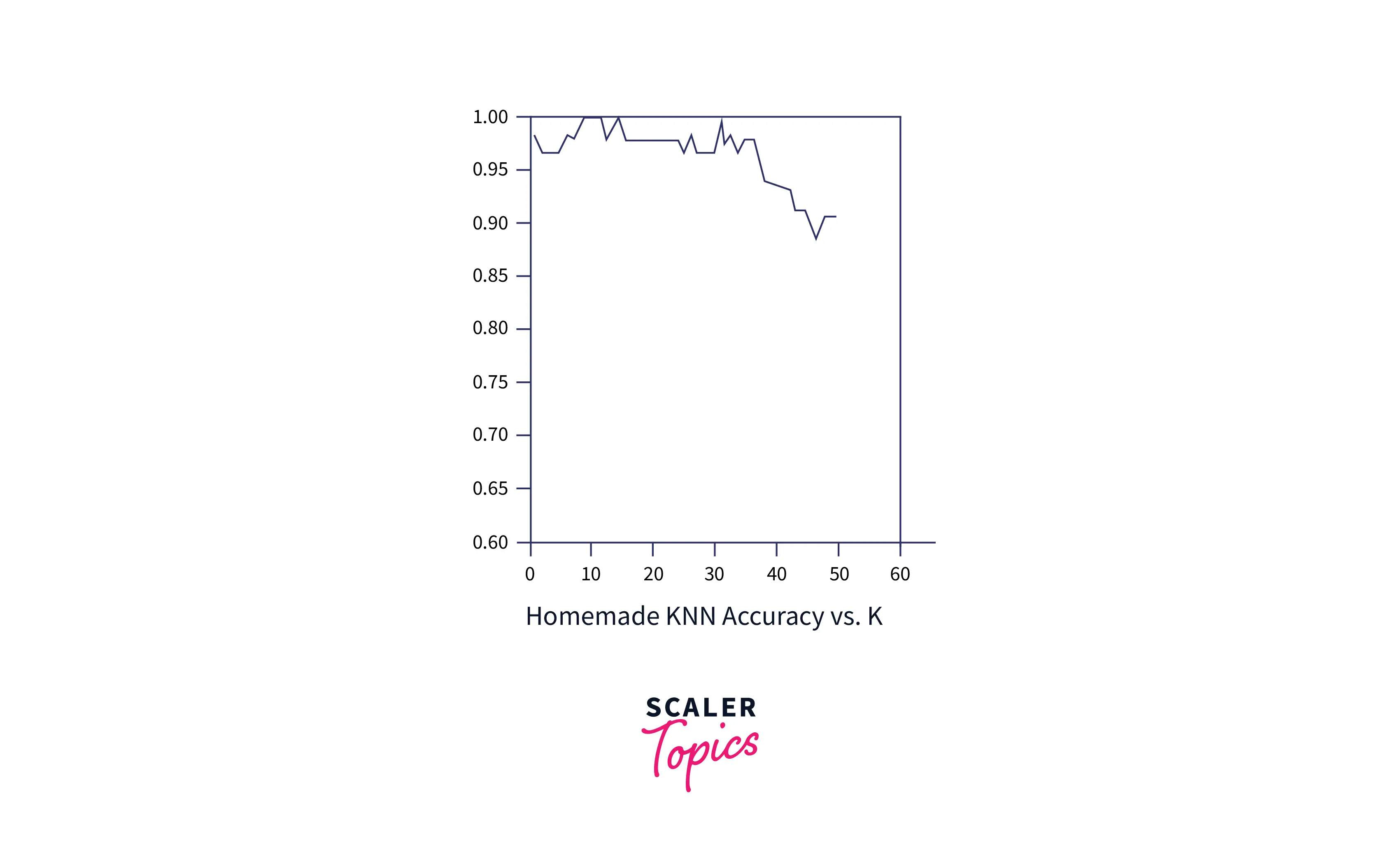
Во-первых, разделите набор надзорных данных на две категории:
- Обучение и
- Данные тестирования.
Данные обучения должны быть больше, чем последние. Начните с k = 1 и спрогнозируйте с помощью KNN для каждой точки данных в данных тестирования. Сравните эти прогнозы с фактическими метками и определите точность модели. Найдите коэффициент ошибок.
Повторите этот процесс для разных значений k , постройте график зависимости частоты ошибок от k и выберите значение k , которое имеет наименьшую частоту ошибок.
Типы метрики расстояния
Решения, принимаемые KNN, зависят от выбранного нами типа метрики расстояния. Метрика расстояния — это количественная мера того, насколько «далеко» или «близко» находятся две точки. Помимо евклидова расстояния, в качестве показателей расстояния для KNN можно использовать расстояния Манхэттена, Минковского и Хэмминга.
Евклидово расстояние предполагает, что объект может свободно перемещаться в пространстве и достичь точки B( Икс 1 , й 1 х_1,у_1 Икс1,й1) из точки А( Икс 2 , й 2 х_2,у_2 Икс2,й2) по прямой.
Формула евклидова расстояния: ( Икс 1 - Икс 2 ) 2 + ( й 1 - й 2 ) 2 sqrt{(x_1-x_2)^2+(y_1-y_2)^2} ( Икс1-Икс2)2+( у1-й2)2
Однако, когда движение объекта ограничено вертикальным или горизонтальным перемещением, предпочтительным является Манхэттенское расстояние между двумя точками. Оно определяется суммой смещений x и y между двумя точками A и B в двумерном пространстве. | Икс 2 - Икс 1 | |x_2 - x_1| | х2-Икс1|+ | й 2 - й 1 | |y_2 - y_1| | у2-й1|. Здесь, | Икс 2 - Икс 1 | |x_2 - x_1| | х2-Икс1|это абсолютная разница между x2 и x1 .
Расстояние Хэмминга — это еще одна метрика расстояния, вычисляемая путем нахождения побитового исключающего ИЛИ двух чисел и количества единиц в результате. Например,

Евклидово расстояние является наиболее распространенной метрикой расстояния, тогда как другие метрики используются в нишевых задачах. Например, наименьший путь, пройденный самолетом из точки A в точку B на Земле, представляет собой кривую, поскольку кривизна Земли ограничивает движение самолета.
Ускорение KNN
Алгоритм KNN непараметричен, что означает, что нет никаких предположений о базовом распределении данных. Это полезно в реальных сценариях, когда данные не соответствуют теоретическим предположениям. Но KNN также является ленивым алгоритмом, а это означает, что ему не нужны какие-либо обучающие данные для создания модели. Все данные обучения, используемые на этапе тестирования. Следовательно, это ускоряет обучение, а этап тестирования — медленнее и дороже. Таким образом, для ускорения KNN предлагается несколько методов. Здесь мы подробно обсудим некоторые из этих методов.
КД Дерево
В методе на основе дерева KD обучающие данные делятся на несколько блоков. Далее, вместо расчета расстояния со всеми точками обучающих данных, рассматриваются выборки из тех же блоков.
Как работает дерево КД:
Дерево KD строится путем разделения обучающих данных на основе любых случайных измерений. В целях иллюстрации давайте попробуем создать дерево КД для двумерных данных.
Рассмотрим обучающие данные как: (1,9) , (2,3) , (4,1) , (3,7) , (5,4) , (6,8) , (7,2) , (8, 8) , (7,9) , (9,6) — ниже показаны шаги по разделению данных на несколько частей с помощью KD Tree.
- Выберите разделенный размер:
здесь выбран размер x . Значения координат X для точек данных: 1 , 2 , 4 , 3 , 5 , 6 , 7 , 8 , 7 и 9 . - Найдите медианное значение:
Далее сортировка результатов координат x 1 , 2 , 3 , 4 , 5 , 6 , 7 , 7 , 8 , 9 . Среднее значение — 6 . - Далее разделите данные примерно на равные половины.
- Повторите шаги с 1 по 3 : на следующей итерации выбирается координата y , вычисляется ее медиана и данные снова разделяются. Второй и третий шаг пересчитываются для разделения данных на несколько частей. На графике ниже показано, что пространство сначала делится на x=6 , а затем на y=4 и y=8 .
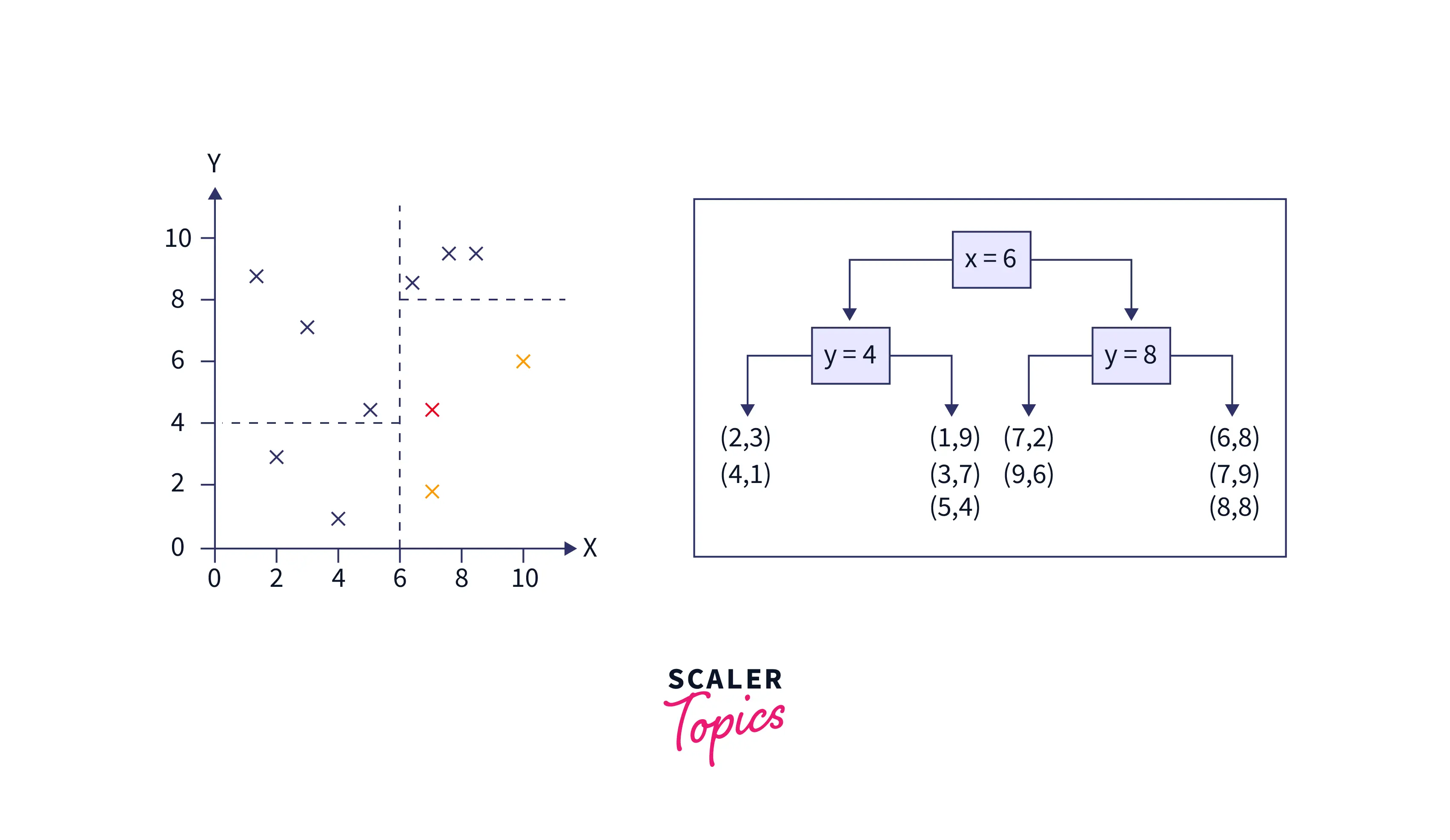
При тестировании его расстояние измеряется только с образцами одного и того же блока, чтобы найти k ближайших соседей.
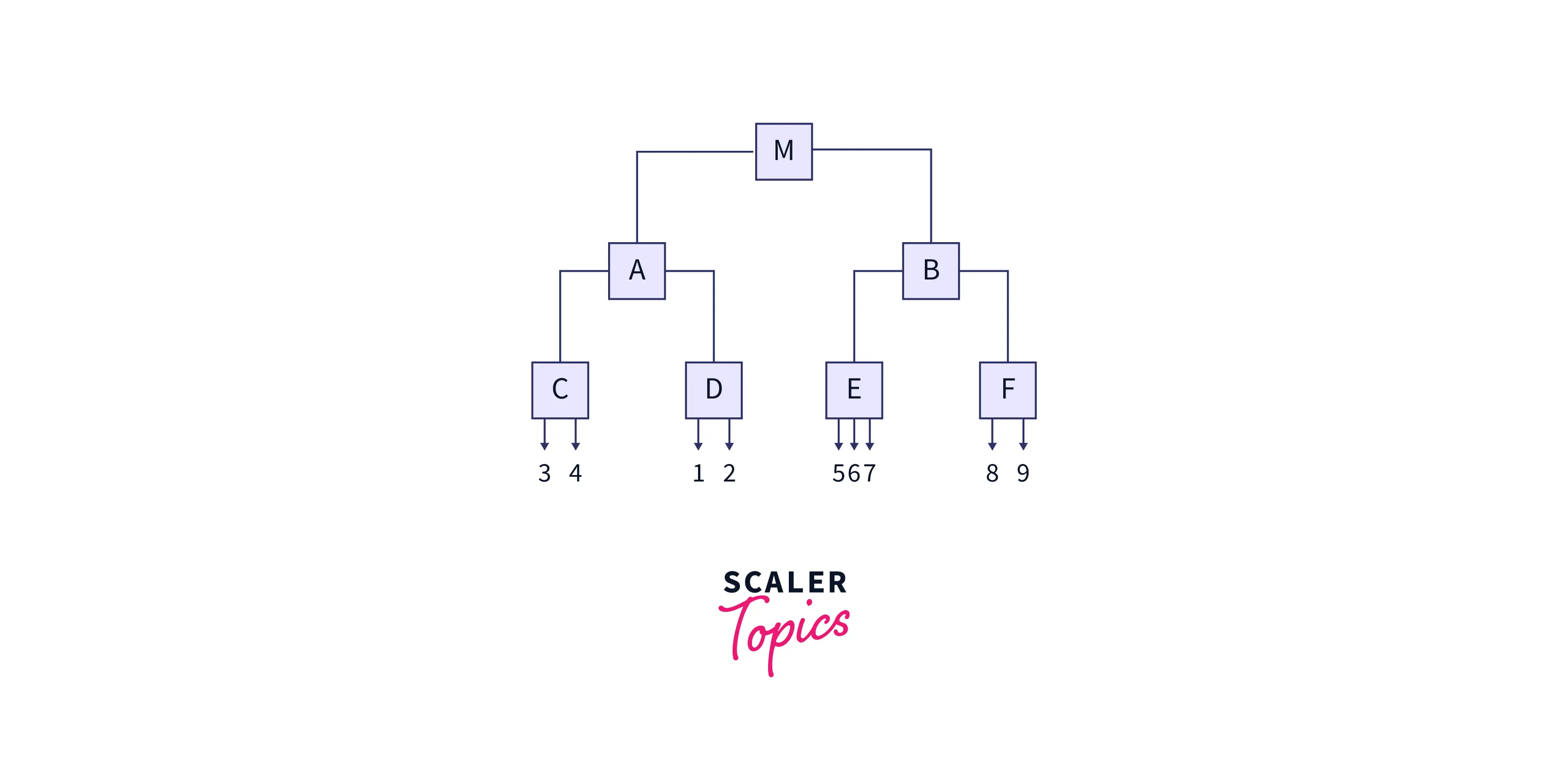
Шаровое дерево
Ball Tree делит тренировочные данные на круглые шары (круглые блоки). Сходство тестовых данных рассчитывается только с учетом обучающих точек в этом блоке. Давайте посмотрим, как строится шаровое дерево.
Сначала устанавливается центроид всех обучающих данных. Затем точка выборки, наиболее удаленная от первого центроида, выбирается в качестве центра первого кластера и дочернего узла. Затем точка, наиболее удаленная от центра первого кластера, выбирается в качестве центроида второго кластера. Все остальные точки данных относятся к кластеру 1 или кластеру 2 . Метод разделения точек данных на два кластера/сферы повторяется внутри каждого кластера до глубины. Он создает вложенный кластер, содержащий все больше и больше кругов. После того как кластеры построены, они могут пересекаться, но каждая точка назначается одному кластеру. Это концепция алгоритма Ball Tree .
Пример:
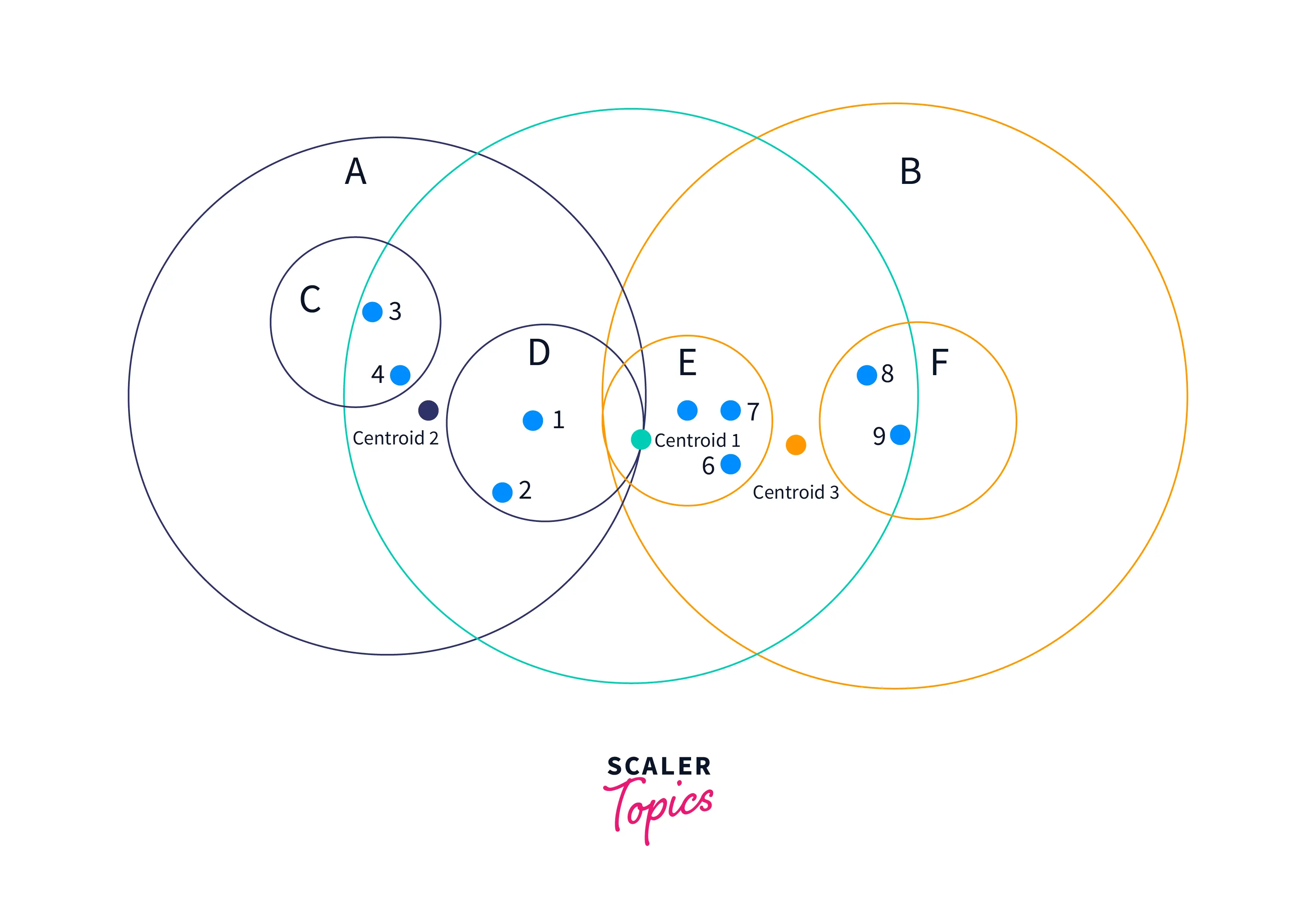
На рисунке выше центроид 1 запускает алгоритм. Серая сфера (2D) расположена вокруг обучающих данных. Из центра выбирается самая дальняя точка кластера (номер 3 или 9 ). Самая дальняя точка от номера три — это центр кластера 2 . Остальные кластеры строятся, как обсуждалось выше.
Полученное дерево показано ниже.
Приблизительные ближайшие соседи
Алгоритм приближенного ближайшего соседа предлагает еще один подход к ускорению времени вывода стандартного алгоритма KNN с помощью следующих шагов.
- Случайным образом инициализируйте набор гиперплоскостей в том же пространстве, что и точки выборки. Он разделит плоскость на подпространства.
- Найдите подпространство для каждого образца в обучающих данных.
- Делая выводы, найдите образцы из одного и того же подпространства и рассматривайте их как соседей.
- Затем вычислите расстояние между тестовыми данными и их новыми соседями.
- Верните метки ближайшего образца K подпространства.
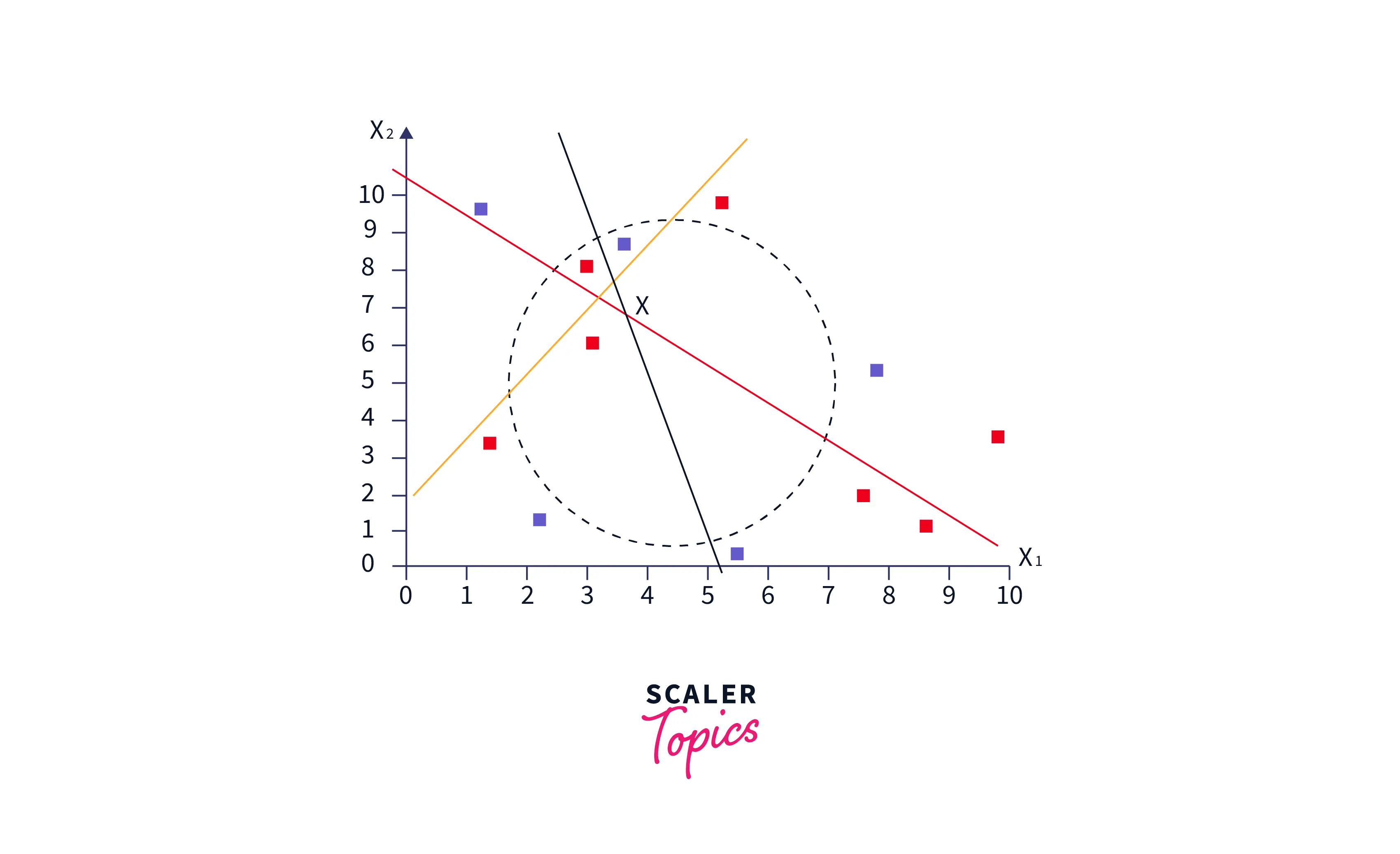
Проклятие размерности
Замечено, что для данных низкой размерности некоторые точки остаются близкими, а некоторые - далеко друг от друга. Однако в больших измерениях все точки почти равноудалены, скажем, d =100 . Это явление называется «Проклятием размерности».
Это проклятие для KNN, потому что при больших d идея k -ближайшего соседа терпит неудачу, поскольку набор из n точек почти равноудален друг от друга. KNN требует, чтобы все точки были близки по каждой оси. Добавление нового измерения усложняет нахождение двух конкретных точек близко друг к другу по каждой оси. Следовательно, производительность KNN ухудшается с увеличением размерности.
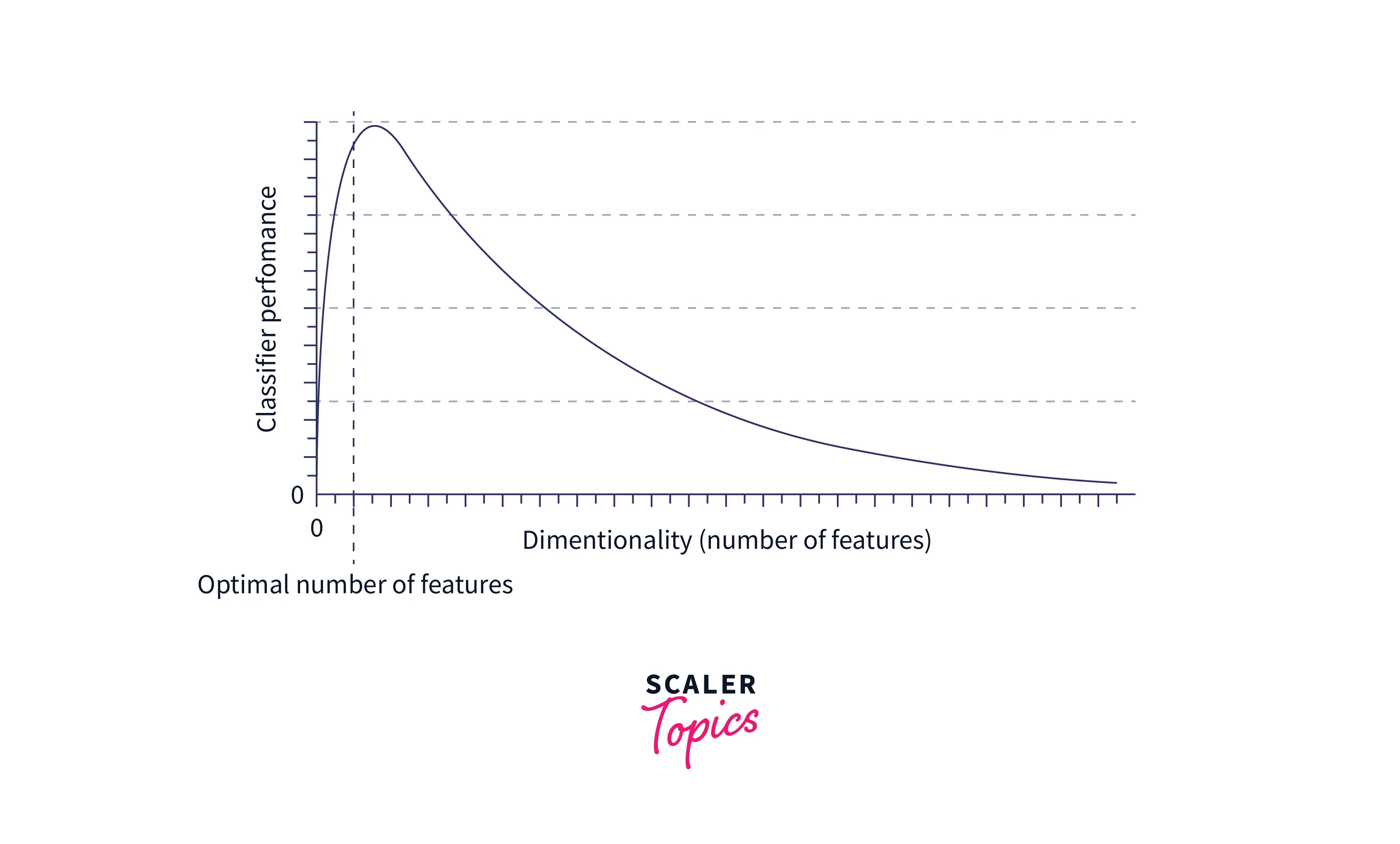
Решение
С увеличением размерности KNN требуется больше данных для поддержания плотности точек. В противном случае он потеряет всю предсказательную силу. Следовательно, добавление дополнительных данных является самым элементарным решением проблемы проклятия размерности для KNN. Однако, к сожалению, добавление дополнительных данных возможно лишь иногда из-за отсутствия данных или из-за того, что для обработки данных требуется больше памяти. Следовательно, уменьшение размерности данных является еще одним жизнеспособным вариантом устранения проблемы.
Преимущества алгоритма KNN в машинном обучении
- KNN чрезвычайно полезен в сценариях, требующих высокой точности и не содержащих много неизвестных точек для классификации. Концепция обучения не применима к KNN. Следовательно, если нам нужен быстрый прогноз для ограниченного числа точек данных, то KNN — это лучший алгоритм, поскольку другие модели, такие как нейронные сети и логистическая регрессия, требуют времени для обучения.
- Легко реализовать
- Простая настройка гиперпараметров (в отличие от нейронных сетей)
Недостатки алгоритма KNN в машинном обучении
- Мы можем неправильно классифицировать что-то, даже если уверенность составляет 100% из-за переобучения.
- KNN уверенно классифицирует точки данных, выходящие далеко за рамки фактического объема набора данных.
- KNN чувствителен к шуму, поэтому необходимо выполнить точную предварительную обработку данных.
- KNN использует обучение на основе экземпляров и представляет собой ленивый алгоритм, который относится к алгоритму, который ничего не изучает из набора данных. Каждый раз, когда предоставляется новая точка данных, он вычисляет расстояние между этой точкой и всеми другими точками в наборе данных, что требует больших вычислительных затрат. По сути, идеи обучения модели KNN не существует, поскольку она принимает новое решение, вычисляя расстояния от новой точки.
- Для больших наборов данных программа должна быть оптимизирована по памяти, иначе для выполнения классификации потребуется слишком много памяти. Существует множество обходных путей для многих из этих недостатков, что делает KNN мощным инструментом классификации. Например, мы можем применить алгоритм взвешенного KNN для повышения точности. Кроме того, если тестовый набор данных большой, мы можем использовать сетку-сетку, которая предварительно вычисляет прогнозы точек данных и сохраняет этот результат в сетке.
Применение K-ближайших соседей
- KNN можно использовать при проверке на плагиат, чтобы проверить, являются ли два документа семантически идентичными.
- Машинное обучение в здравоохранении использует KNN для диагностики заболеваний на основе едва заметных симптомов.
- Netflix использует KNN в своих системах рекомендаций.
- KNN используется в программном обеспечении для распознавания лиц.
- Политологи и психологи используют KNN для классификации людей на основе их поведения и реакции на раздражители.
Реализация алгоритма KNN на Python
Мы рассмотрим знаменитый набор данных Iris, чтобы понять, как реализован KNN. Настоятельно рекомендуется реализовать KNN с нуля, поскольку алгоритм довольно прост. Вы можете скачать набор данных отсюда .
Сначала прочитайте данные и сгенерируйте данные обучения и тестирования, используя train_test_split из sklearn.
Вывод приведенного выше кода показан ниже:
Далее давайте попробуем построить модель KNN для K=5 и измерить точность модели.
Вывод кода приведен ниже:
Из этой программы мы получаем точность около 98% последовательно для K = 5 .
Раскройте возможности математики в машинном обучении. Запишитесь на курс «Математика для машинного обучения» сегодня!
Заключение
- Алгоритм k-ближайших соседей — довольно простой для понимания и реализации алгоритм.
- Хотя лучше использовать библиотеки и хорошо разработанные инструменты, создание проекта с нуля дает нам лучшее представление о том, как все работает «под капотом», и обеспечивает большую гибкость.
- Кроме того, хотя алгоритм KNN в машинном обучении имеет множество недостатков, его можно устранить с помощью определенных модификаций и улучшений, что делает его одним из самых мощных алгоритмов классификации.
Телеграм: t.me/ainewsline
Источник: www.scaler.com