Большой тест GPT4, GPT3.5, YandexGPT, GigaChat, Saiga в RAG-задаче. Часть 1
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2023-12-24 12:11
Предисловие и тема статьи
Меня зовут Дмитрий Гуреев. Я занимаю должность CDTO в одной из медицинских компаний и параллельно веду работу по популяризации ИИ в среднем бизнесе. Генеративные модели привлекли мое внимание в феврале 2022 года. Тогда я внедрил цифрового ассистента для полевых продавцов. Система позволяет им озвучивать результаты встреч в телеграм-бот, на основе чего формируется официальный протокол, который затем записывается в Битрикс.
Мои исследования продолжились, и летом 2022 года хороший знакомый из крупной компании предложил совместный эксперимент. Задача состояла в создании цифрового юриста, способного отвечать на вопросы первой линии, используя в качестве базы знаний 200-страничный регламент из более чем 1200 пунктов. Каждый пункт содержал информацию о том, что можно и что нельзя делать, сроках, ответственности и прочем. Все это должно было функционировать в закрытом контуре.
Задача представлялась крайне интересной:
-
Объем регламента значительно превышал максимальный размер промпта, даже для GPT4-Turbo (128к), который вышел позже.
-
Все должно было работать локально, требования ИБ, что исключало готовые решения.
Мы договорились двигаться последовательно, начиная с использования возможностей OpenAI, постепенно переходя к отечественным облачным решениям YandexGPT и GigaChat, подбору локальных токенайзеров и внедрению Saiga, включая кастомизированные варианты.
К августу мы сформировали Dream-Team (ИТ + Бизнес):
-
Я взял на себя роли TeamLead, инвестора (железо и аутсорс части решений)
-
Знакомый возглавил группу из четырех экспертов-юристов, которые на каждом этапе валидировали систему.
Эта статья является промежуточным итогом наших работ. Мы исследовали различные модели и типы токенайзеров, а эксперты оценивали качество работы модели. На сегодня это, возможно, самое подробное и детальное исследование в данной области, где для оценки привлекались живые люди из бизнеса и я надеюсь, что оно окажется полезным.
Методология
Использование больших языковых моделей для поиска ответов по документам является классическим подходом. Я не буду углубляться в методологию, так как уже существует множество статей на эту тему (на langchain, или вот на habr), а лишь напомню основной принцип.
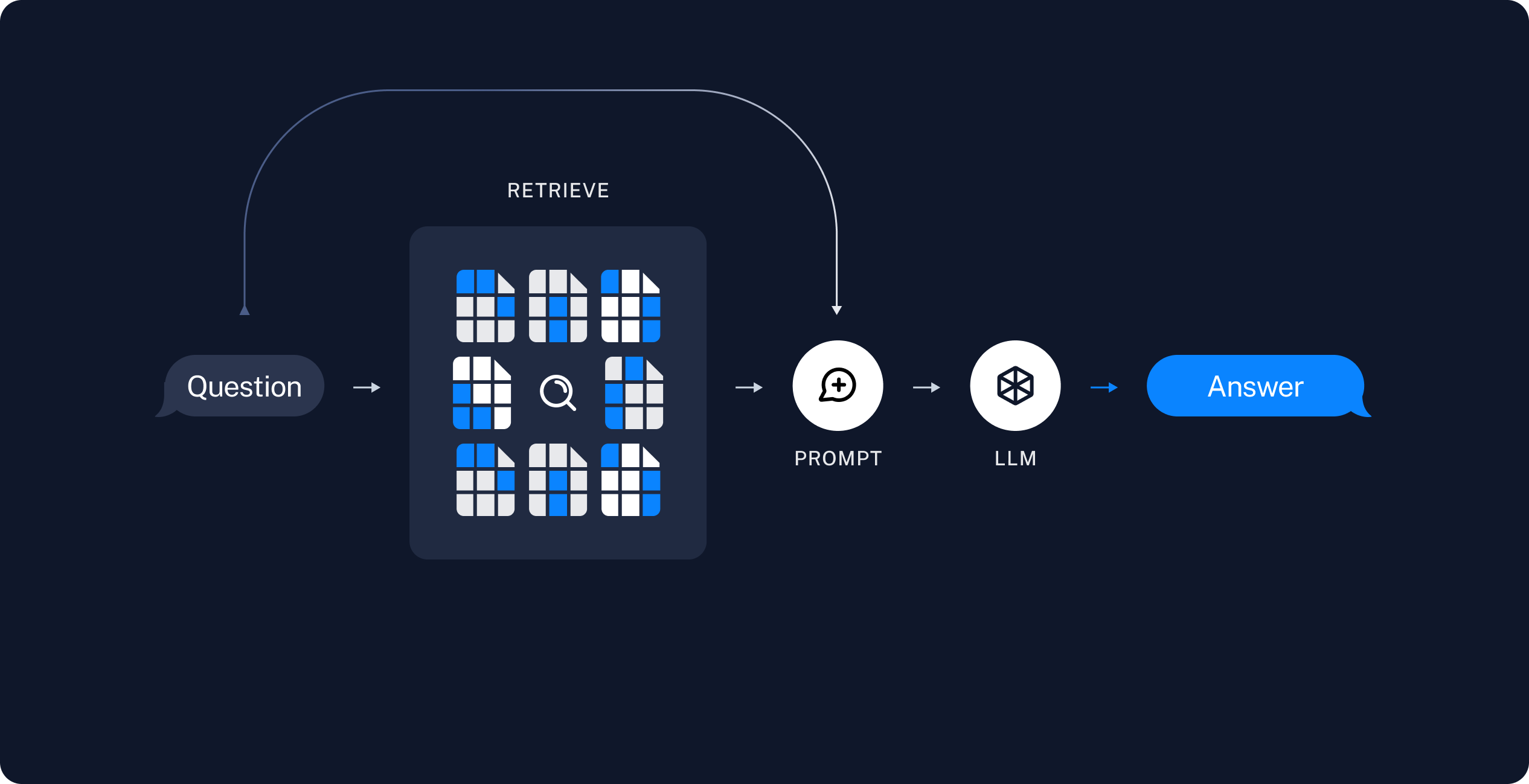
Основной принцип заключается в разбиении большого документа, который нельзя поместить в промпт, на мелкие части или чанки. Затем, когда задается вопрос, система ищет наиболее релевантные куски текста, где может находиться ответ. Из них формируется финальный промпт:
-
Ты цифровой юрист. Твоя задача отвечать на вопросы используя части текста из регламента. Ответь на вопрос: [вопрос] Используя сведения из следующих кусков текста: [текстовые куски]. Отвечай кратко. Ничего не придумывай. Если ответ не знаешь, то так и скажи.
Реализация этого механизма включает несколько этапов:
-
Разбить текст на чанки (100-400 слов).
-
Перевести эти чанки в векторный вид для последующего выбора наиболее релевантных с помощью косинусной близости.
-
Сформировать промпт из этих кусков.
-
Отправить промпт в выбранную модель и получить ответ.
Таким образом, нам предстоит:
-
Подобрать алгоритм разбития текста на чанки (куски).
-
Подобрать токензайзер для получения эмбедингов по этим кускам.
-
Подобрать промпт.
-
Подобрать модель.
Классическое описание данного механизма, описанное в Langchain, предполагает:
-
Делить текст по переносам строк, стараясь сохранить слова целыми, с ограничением по количеству символов или токенов.
-
Для токенизации предлагается использовать модель ada-002 от OpenAI.
-
Использование OpenAI для генерации ответа.
Это подход отлично работает, если не стоит задача использовать отечественные или локальные решения. Так как исходный документ был публичным и не содержал коммерческой тайны, то мы решили использовать модель на базе GPT4-Turbo (10К контекст) с их родным токенайзером ada-002 для рефернса.
Однако, исходя из нашей задачи, мы должны были последовательно перебрать различные модели и токенайзеры, чтобы выбрать наиболее близкий к рефернс. В итоге мы получили:
-
Один алгоритм чанкования.
-
Четыре вида токенайзеров: ada-002, RuBert, YandexEmbeding, RuBert Finetuned.
-
Один промпт.
-
7 видов моделей: GPT4, GPT3.5, YandexGPT, GigaChat, Saiga, FineTuned Saiga.
В первой части мы рассмотрим 2 вида токензайров и 4 модели. Во второй части статьи остальные.
Итого первая часть состоит 8 комбинаций настроек.
Наши эксперты сформировал 31 вопросов от простых, до достаточно сложных на пересечении нескольких тем. Целью было получить 248 ответов (31 вопрос * 8 комбинаций), каждый из которых будет проверен вручную на адекватность с оценкой: верно, спорно, неверно.
Результаты можно увидеть в конце статьи, а теперь давайте рассмотрим каждый из этапов.
Делаем чанки
В классическом подходе предлагается разбивать текст на абзацы или, где это невозможно, по словам с некоторым перекрытием. Этот метод хорош, когда каждый абзац содержит законченную мысль, абзацы схожи по размеру и структуре. Однако, в случае с юридическими документами, некоторые абзацы могут быть подпунктами более крупных разделов. Например, пункт 3.3.3 описывает случаи, когда запрещено использовать температурную перевозку, с подпунктами 3.3.3.1 и 3.3.3.2, детализирующими отдельные случаи. Важно не разделять такие связанные пункты.
Мы также заметили, что чем длиннее чанк, тем хуже качество токенизации – она становится более обобщенной. Поэтому мы решили, что оптимальный чанк – это не только техническое, но и творческое решение, которое учитывает контекст. В итоге выбрали чанки размером до 150 слов, сгруппированные в соответствии с иерархией документа. Для этого был разработан скрипт, который анализирует структуру документа, создавая чанки, максимально крупные в рамках ограничений.
Токенизатор (получение эмбедингов)
Каждый чанк необходимо было преобразовать в вектор, который затем записывался в PSQL. Мы рассмотрели различные варианты: облачные сервисы OpenApi (ada-002) и YandexEmbeding (с ограничением до 10 запросов в секунду), а также множество локальных вариантов, включая Word2Vec, RuBert, rugpt и даже слои эмбеддингов у Llama.
Облачные сервисы работали отлично, хотя у Яндекса была низкая квота по умолчанию, а у Сбера (ГигаЧат) мы не нашли подходящего токенайзера.
С локальными вариантами было сложнее. Пришлось написать что-то вроде автотеста. Выбрали около 10 вопросов и соответствующими куски регламента, где точно есть ответ на них. Далее меняя разные токенайзеры смотрели, какие из них покажут хорошую косинусную близость между вопросом и куском.
RuBert-Large оказался наиболее адекватным для нашей задачи, с использованием среднего пулинга (mean pooling). Скрытый слой Llama оказался полностью бесполезным. RuGPT, Fred и прочие от ai-forever - оказались хуже.
Промпты
Мы понимаем, что от промпта многое зависит, но для эксперимента решили оставить классический вариант: Ты цифровой юрист. Твоя задача отвечать на вопросы используя части текста из регламента. Ответь на вопрос: [вопрос] Используя сведения из следующих кусков текста: [текстовые куски]. Отвечай кратко. Ничего не придумывай. Если ответ не знаешь, то так и скажи..
Размер промпта ограничили до 10000 символов, так как этот размер хорошо подходил под все рассматриваемые модели, несмотря на разное количество занимаемых токенов для русских символов в разных моделях (например, 2-3 символа на каждый из 4096 токенов у Llama или 1 токен = 1 символ для GPT4).
Модели
Для нашего проекта мы использовали несколько источников: доступ к OpenAI, YandexGPT, GigaChat, а также мощную видеокарту 4090 для запуска и обучения локальных моделей. В качестве базовых моделей были выбраны Llama и Saiga, а также мы попытались обучить собственную модель. Подробности об этом будут во второй части статьи.
Для работы с облачными моделями мы устанавливали температуру генерации ответов на ноль, чтобы повысить точность и уменьшить креативность ответов. Доступы к моделям были получены через API.
Обвязка и devops
Для управления таким количеством параметров мы разработали бэкенд на Python, который был помещен в Docker-контейнер. Бэкенд обладает интерфейсом OpenAPI для взаимодействия с внешними системами. Это решение позволяло нам на лету изменять документы, модели, промпты и различные токенайзеры, обеспечивая максимальную универсальность и гибкость. Бэкенд работает как на CPU, так и на GPU, что позволяет тестировать локальные модели параллельно с облачными.

Также был создан микросервис для телеграм-бота, позволяющий легко добавлять документы в канал.
Дополнительно мы написали валидационный скрипт, который формировал ответы на вопросы, перебирая различные варианты на нашем бэкенде.
Итоги
Мы подошли к наиболее интересной части. Напомню, что эксперты задали 31 вопрос, на который система отвечала, используя разные комбинации моделей и токенайзеров. Каждый ответ затем был оценен экспертами вручную по следующей градации: верно (зелёный), спорно (желтый), неверно (красный).
Давайте теперь рассмотрим общую картину результатов. По горизонтали расположены вопросы, по вертикали – комбинации параметров. В ячейках таблицы указан цвет, соответствующий оценке ответа.

Из результатов тестирования видно, что GPT4-Turbo с использованием родного токенайзера ada-02 показал лучшие результаты: 71% ответов оценены как верные и только 23% как неверные. Наименее эффективной оказалась модель GigaChat с локальным токенайзером RuBert-Large. Результаты YandexGPT были чуть лучше, но разница несущественна.
Интересно отметить, что модели OpenAI также показали плохие результаты на токенайзере RuBert. Это подтверждает предположение, что неправильный выбор кусков текста (ошибка токенайзера) для формирования промпта приводит к неверным ответам. Почти во всех случаях, когда модели OpenAI давали неверные ответы, другие модели также показывали низкие результаты.
На основе первых данных стало ясно, что стоит сосредоточиться на разработке локализованных под конкретную задачу токенайзеров и использовать ada-002 в качестве эталонного токенайзера. Это подчеркивает важность правильного выбора инструментов для обработки и подготовки текста перед использованием языковых моделей. Не менее важно, чем сами модели.
На основе представленных данных можно провести анализ эффективности моделей и токенайзеров:
Неверные ответы:

-
С использованием токенайзера RuBert-Large количество неверных ответов у всех моделей значительно увеличивается, превышая 55%. Это подтверждает, что выбор токенайзера является критически важным для точности модели.
-
Наибольший процент ошибок у GigaChat с RuBert-Large (71%), а наименьший – у GPT4 с ada-02 (23%).
Спорные ответы:

-
Наибольшее количество спорных ответов наблюдается у моделей YandexGPT2 и GigaChat с токенайзером ada-02. Это может указывать на несовершенство этих моделей, а также на потенциальную возможность улучшения результатов за счет оптимизации промптов.
-
С RuBert-Large спорных ответов меньше, что может быть связано с более низкой точностью этого токенайзера в целом.
Верные ответы:

-
Наилучшие результаты по количеству верных ответов показывает GPT4 с ada-02 (71%).
-
Результаты YandexGPT2 и GigaChat значительно ниже, даже с использованием токенайзера ada-02. Это может свидетельствовать о том, что данные модели менее эффективны в данной задаче, либо требуют дополнительной настройки промптов.
Выводы и что наш ждет во второй части
Первая часть исследования показывает, что необходимо сосредоточить усилия на улучшении токенайзеров для повышения точности ответов и на доработке промптов для уменьшения количества спорных ответов. Во второй части статьи будут представлены:
-
Токенайзер от Яндекса.
-
Улучшенный (Fine-tuned) RuBert токенайзер.
-
Локальная модель Saiga.
-
Дообученная модель Saiga.
Источник: habr.com