Визуализация весов в машинном обучении на примере алгоритма Random Forest и Decision Tree
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2023-05-03 15:00
Меня зовут Александр Серов, я Data Scientist и являюсь участником профессионального сообщества NTA. Сегодня загляну «под капот» алгоритмов, использующих в своей основе деревья решений. Один из самых мощных алгоритмов контролируемого машинного обучения на сегодня – градиентный бустинг (Catboost, XBGR), построен на столь казалось легком и базовом элементе, как бинарное дерево, или же дерево решений. Оно является строительным блоком данного алгоритма, в данном случае можно привести притчу про веник и его части, но в этом случае, иногда даже одно дерево решений способно выдать неплохой результат в решениях задач классификации и регрессии. Сегодня я рассмотрю его подробнее, на примере Decision Tree и Random Forest из библиотеки sklearn, а также визуализирую работу.
В практике всегда возникает проблема верного выявления гипотез, в моей работе с этим помогают модели машинного обучения, но и их необходимо контролировать. Визуализация весов - один из способов это сделать.
Обучать и тестировать модели буду на двух наборах данных, взятых из открытого источника - Kaggle.
-
Данные с числовыми признаками для задачи классификации наличия диабета у человека.
-
Данные с категориальными признаками для задачи предсказания оценок по математике.
DecisionTree - задача классификации
# импортируем набор данных по диабету import pandas as pd df_clf = pd.read_csv('../input/pima-indians-diabetes-database/diabetes.csv') df_clf.head()
Начну с задачи классификации. Набор данных основан на определенных диагностических измерениях, ограничен 1000 значений, где были выбраны женщины из индейского племени Пима. Изучим подробное описание каждого признака:
-
Pregnancies – количество беременностей;
-
Glucose – концентрация глюкозы в плазме крови;
-
BloodPressure – дистолическое давление крови;
-
SkinThickness – толщина кожи трицепса;
-
Insulin – содержания инсулина в крови;
-
BMI – индекс массы тела;
-
DiabetesPedigreeFunction – показатель функции генетического диабета;
-
Age – возраст;
-
Outcome – наша целевая переменная, где 0 – нет диабета, 1 – есть.
Цель, как указывалось выше, переменная "Outcome", то есть бинарный признак. В следующем шаге разделим набор данных на тренировочную выборку и тестовую, с пропорциями 71:29 (можете поэкспериментировать с данным показателем, допустим разброс, зависимый от количества данных и их разнообразия).
from sklearn.model_selection import train_test_split target_df_clf = df_clf['Outcome'] feature_df_clf = df_clf.drop(columns=['Outcome']) X_train_clf, X_test_clf, y_train_clf, y_test_clf = train_test_split(feature_df_clf, target_df_clf, test_size=0.29, random_state=11)После того, как подготовил данные, начну обучение с модели DecisionTreeClassifier. Это всё то же бинарное дерево решений, для автоматического подбора параметров модели используем GridSearchCV. Необходимо для нахождения оптимального решения и оптимизации затрат по времени.
from sklearn.model_selection import GridSearchCV from sklearn.metrics import accuracy_score from sklearn.tree import DecisionTreeClassifier tree_param = [{'criterion': ['entropy', 'gini'], 'max_depth': [i for i in range(1, 20)], 'min_samples_leaf': [i for i in range(1, 25)], 'max_leaf_nodes': [i for i in range(1, 20)]}] dtc_model = GridSearchCV(DecisionTreeClassifier(), tree_param, cv=10) dtc_model.fit(X = X_train_clf.values, y = y_train_clf) prediction_clf = dtc_model.best_estimator_.predict(X_test_clf) score = accuracy_score(y_test_clf, prediction_clf) print(f'Лучшие найденные параметры: {dtc_model.best_estimator_}') print(f'Точность на тренировочных данных: {round(dtc_model.best_score_*100, 2)}') print(f'Точность на тестовых данных: {round(score*100, 2)}') Точность на тренировочных данных: 74.31
Точность на тестовых данных: 72.65
Полученная точность нашей модели - 72%, что уже довольно неплохо, а это ведь только 1 дерево. К сведению, если применять данную модель в реальных условиях мы можем уменьшить порог для классификации положительного результата (tresholding), так как в жизни ложноположительный результат лучше, чем ложноотрицательный, потому что можно провести углубленные исследование. Но для этой модели сейчас важна абсолютная точность.
Теперь попробуем визуализировать результат и посмотреть, как модель распределяла веса для классификации целевого признака.
import matplotlib.pyplot as plt from sklearn.tree import plot_tree plt.figure(figsize=(15,15)) plot_tree(dtc_model.best_estimator_, filled=True, impurity=True) 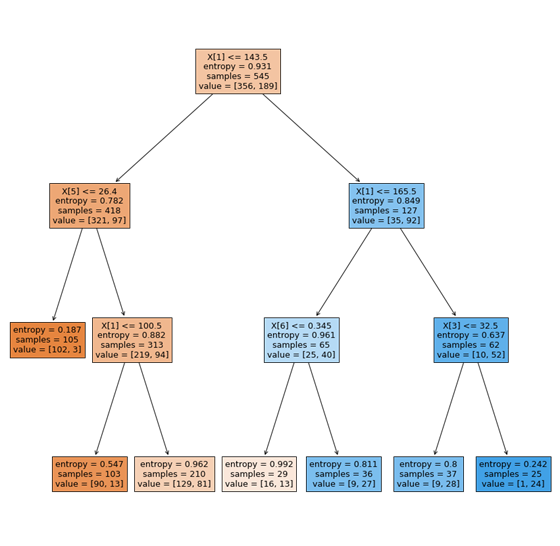
Нужно добавить немного теории, чтобы понять нашу визуализацию.
Модель выбрала алгоритм работы на основе энтропии:
-
Энтропия в свою очередь направлена на максимизацию получения информации. Это можно легко представить, как будто мы угадываем загаданного персонажа. И чтобы как можно быстрее это сделать, нам необходимо сужать круг вариантов как можно больше с каждым вопросом.
Также популярен другой вариант, это коэффициент Gini:
-
С индексом Джини в качестве цели дерево выбирает на каждом шаге признак и порог, который будет их разделять.
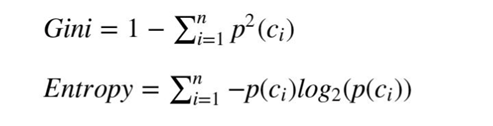
Но мне больше нравится другой способ визуализации c помощью библиотеки dtreeviz, давайте посмотрим на него.
# %pip install dreeviz from dtreeviz.trees import dtreeviz image_est = dtreeviz(dtc_model.best_estimator_, x_data=X_train_clf, y_data=y_train_clf, target_name='class', feature_names=[i for i in X_train_clf.columns], class_names=['Не диабет', 'Диабет'], title="Визуализация подбора весов Decision Tree") image_est.save('dtreeviz.svg')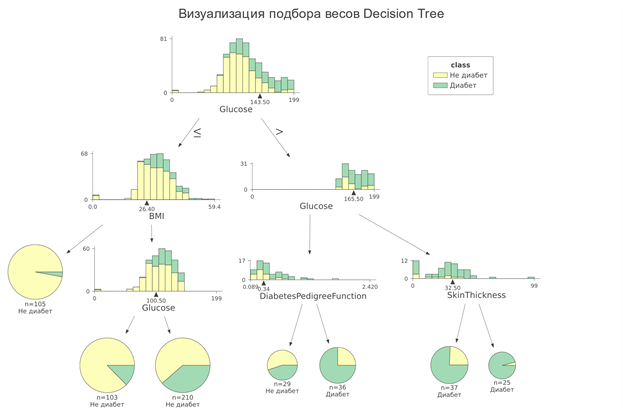
Инфографика процесса представлена более подробно. Видим, как дерево отбирает решения, максимизирует информацию. Глубина дерева получилось всего 3, где задействованы все признаки, а это отличный результат для анализа.
Это действительно полезно, так как можем сравнить полученную информацию с медицинскими гипотезами, подтвердив точность своей модели. Судя из графиков, при высоком уровне сахара в крови - шанс наличия диабета повышен, что совпадает с общепринятыми данными.
DecisionTree – задача регрессии
Сейчас предлагаю рассмотреть вариант с задачей регрессии (предсказания). Для этого используем второй набор данных об успеваемости студентов на экзамене. Он состоит из полученных оценок по различным предметам.
-
Gender – пол студента;
-
Race/ethnicity – этническая группа (данные обезличены);
-
Parental level of education – уровень образования родителей;
-
Lunch – тип питания;
-
Test preparation score – оценка подготовки к экзаменам;
-
Math score – оценка по математике;
-
Reading score – оценка по чтению;
-
Writing score – оценка по письму.
Выберу целевой признак - оценки по математике (math score), метрику - абсолютную ошибку.
Так как данные являются категориальными, необходимо их обработать и перевести в числовой формат, использую для этого LabelEncoder.
df_reg = pd.read_csv('../input/students-performance-in-exams/StudentsPerformance.csv') df_reg.head()
from sklearn.preprocessing import LabelEncoder le = LabelEncoder() df_reg = df_reg.apply(le.fit_transform) target_df_reg = df_reg['math score'] feature_df_reg = df_reg[[i for i in df_reg.columns if i != 'math score']] X_train_reg, X_test_reg, y_train_reg, y_test_reg = train_test_split(feature_df_reg, target_df_reg, test_size=0.29, random_state=11)Обучу модель, применяя аналогичный подход с авто-параметрами.
from sklearn.tree import DecisionTreeRegressor from sklearn.metrics import mean_absolute_error tree_param = [{'criterion': ['squared_error', 'friedman_mse', 'absolute_error'], 'max_depth': [i for i in range(1, 20)], 'min_samples_leaf': [i for i in range(1, 25)], 'max_leaf_nodes': [i for i in range(2, 20)], }] dtr_model = GridSearchCV(DecisionTreeRegressor(), tree_param, cv=5) dtr_model.fit(X = X_train_reg.values, y = y_train_reg) prediction_reg = dtr_model.best_estimator_.predict(X_test_reg) score_reg = mean_absolute_error(prediction_reg, y_test_reg) print(f'Лучшие найденные параметры: {dtr_model.best_estimator_}') print(f'Средняя абсолютная ошибка на тестовых данных: {round(score_reg, 3)}') Средняя абсолютная ошибка на тестовых данных: 5.722
plt.figure(figsize=(15,15)) plot_tree(dtr_model.best_estimator_, filled=True, impurity=True)
image_est2 = dtreeviz(dtr_model.best_estimator_, x_data=X_train_reg, y_data=y_train_reg, target_name='class', feature_names=[i for i in X_train_reg.columns], title="Визуализация подбора весов Регрессии") image_est2.save('dtreeviz2.svg')Дерево решений получилось глубже, чем в первом случае, так как задача регрессии здесь требует больше данных. Здесь алгоритмом работы бинарного дерева выступала средняя абсолютная ошибка.
По визуализации весов можно сделать несколько выводов:
-
Модель в основном задействовала оценки по другим предметам.
-
Навыки письма имеют связь с гендером, то есть значительно коррелируют.
-
Этническая принадлежность студента не использовалась*.
-
Образование родителей также не влияет на оценки*.
"*" - имеют очень малое влияние, поэтому бинарное дерево выбрало другие признаки
Возможно, исключив оценки по другим предметам, были бы задействованы не вошедшие факторы, но пострадала бы и точность предсказания. В моем случае разброс +-6 баллов из 100.
Random Forest
И настал заключительный момент, проверить визуализации весов на алгоритме случайного леса. Он является ансамблевой моделью, то есть он использует для предсказания переменной несколько моделей внутри себя. В данном случае модель обучает несколько бинарных деревьев (со случайной генерацией random_seed) и усредняет их показатели, в результате повышается точность.
Обучать буду модель классификации, после чего выведу визуализацию всех деревьев в его ансамбле.
def GridSearch_CV_RFС(X_train, y_train): from sklearn.ensemble import RandomForestClassifier as rfc estimator = RandomForestClassifier() param_tree = { "n_estimators" : [i for i in range(1, 21)], "max_features" : ["auto", "sqrt", "log2"], "min_samples_split" : [2,4,8], "bootstrap": [True, False], "max_depth": [i for i in range(1, 15)], 'criterion': ['entropy', 'gini'], 'n_jobs': [-1] } model_rfc = GridSearchCV(estimator, param_tree, n_jobs=-1, cv=5) model_rfc.fit(X_train, y_train) return model_rfc.best_score_ , model_rfc.best_estimator_ def RFR(X_train, X_test, y_train, y_test, best_params): from sklearn.ensemble import RandomForestRegressor estimator = RandomForestRegressor(n_jobs=-1).set_params(**best_params) estimator.fit(X_train,y_train) y_predict = estimator.predict(X_test) print ("R2 score:",r2(y_test,y_predict)) return y_test,y_predictscore, model = GridSearch_CV_RFС(X_train_clf, y_train_clf)print(f'Точность на тестовых данных: {round(score*100, 2)}%')Точность на тестовых данных: 77.8%
plt.figure(figsize=(10,15)) fn = [i for i in X_train_clf.columns] cn = ['Диабет', 'Не диабет'] # обозначим набор графиков для вывода нескольких деревьев fig, axes = plt.subplots(nrows = 1,ncols = 5,figsize = (30,10)) for index in range(0, 5): # Построение графика 1 дерева, выбираем по индексу из общей модели plot_tree(model.estimators_[index], feature_names = fn, class_names=cn, filled = True, ax = axes[index]); axes[index].set_title('Дерево № ' + str(index+1), fontsize = 11) fig.savefig('rf_5trees.svg')Как можно увидеть - выросла точность предсказания с 72% до 77%, в общем итоге, в «лесу» 12 бинарных деревьев, в идеале можно вывести каждые из них и проанализировать. Для примера я вывел 5 первых деревьев, чтобы в общем рассмотреть их структуру. Сохранять изображение лучше в векторном формате «svg», чтобы можно было увеличить изображения без потери качества. Анализируя структуру вижу, что увеличилась глубина деревьев, она выросла до 7, также многие из них стали несимметричные (одна из веток имеет значительно больше разветвлений).
Вывод
Обобщу полученные в ходе работы результаты. Деревья решений - строительный блок более серьёзных и эффективных моделей, поэтому, контролируя его, аналитики повышают общие результаты работы. В нашем случае, визуализация помогает не только выполнять прямое назначение - видеть результаты работы весов внутри обученной модели, но и помогает создавать и подтверждать гипотезы, которые предлагает машинное обучение, как видно на примере классификации диабета. Проделанной работой можно повысить качество любого исследования, а также предоставить специалистам, не работающим с машинным обучением, полезную информацию.
Источник: habr.com