Построение HPC/GPU кластеров для машинного обучения
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2023-05-30 12:05
За последние несколько лет машинное обучение сильно изменилось. В обиход вошли так называемые Fundation model. Вы обучаете одну огромную общую модель, которая умеет делать почти всё одинаково. Это как вырастить огромное дерево. Однако для небольшой такой модели из 3 млрд параметров вам потребуется 400 GPU и обучение в течение 5 дней. Поэтому необходимо переходить на Machine Learning-кластера.
Разобраться нам поможет Дмитрий Монахов, на момент написания статьи он занимался разработкой ядра Linux в Яндексе. Был участником революции в Machine Learning, которая произошла за последние несколько лет. Того, что модели выросли до такого размера, что уже не влезают ни в один сервер, ни в несколько серверов, ни даже в одну стойку. Стали строить что-то огромное, но вдруг вспомнили, что был какой-то чудак, который имел опыт работы с распределёнными файловыми системами, а машинное обучение — это и есть использование распределённых алгоритмов.
Введение
На первых этапах своего развития модели, такие как BERT RAY GPT-3 Light, имели 1,3 млрд параметров и обучались на самом обычном современном сервере с 128 ядрами сроком в 20 лет.
Но модели за последние 10 лет выросли ещё в 10 раз, и это означает, что модель на одном сервере будет обучаться 200 лет, что абсолютно непрактично. Поэтому надо как-то учиться распараллеливать обучение модели на несколько узлов CPU. Но хорошо ли подходит CPU для этого?

Типичное ядро general-purpose вычислителя выдаёт 0.03-0.04 TFlops (операций с плавающей точкой). В стандартный современный сервер можно поставить 2 CPU, и тогда с одной системы вы получите лишь 4-5 TFlops, при этом 1 TFlops будет стоить порядка 5000$.
Если взять для этой же операции GPU, то ядра у него слабее примерно в 10 раз, но Cuda ядер там в 70 раз больше. Самое главное, что в сервер можно поставить не 2, а 8 GPU. Тем самым плотность вычислений с одного сервера будет в 25 раз больше.
Более того, большинство Machine Learning на самом деле сейчас использует не двойную, а одинарную точность TF32. Производители GPU оптимизированы этот случай. При этом разница в цене одного TFlops уже не 2 раза, а в 20 раз. Поэтому все современные кластеры для машинного обучения и суперкомпьютеры практически базируются на GPU, так как он подходит для решения таких задач намного лучше.
Как получить кластер для обучения
После того как в Яндекс разобрались, что хотят обучать свои модели, встал вопрос: "Как получить кластер для такого обучения?". Нашли 4 варианта:

-
Купить готовый кластер «под ключ»
Когда есть деньги, можно позвонить в NVIDIA и сказать, что вы хотите самый лучший суперкомпьютер на рынке — NVIDIA SuperPOD. В течение месяца его установят в ДЦ с иголочки «под ключ». Так сделали в CAMBRIDGE-1, Sber, CHRISTOFARI NEO.
Однако любое готовое решение залочено под то, что уже есть. Если вы захотите что-то поменять, то возникнут проблемы. В таком случае вам всё равно придётся наращивать экспертизу.
-
Купить железо, настроить самим
Так поступают в основном академические институты по той простой причине, что умных людей там много, а задачи специфические.
-
Купить компоненты, разработать собственную платформу
Иной уровень инженерной сложности, по которому идут cloud-провайдеры. Большое количество клиентов позволяет строить большие кластера. Самое главное, что на таких масштабах можно позволить себе построить кластер, который будет оптимально решать конкретные задачи обучения LLM. Так поступают Microsoft/OpenAI v5, Amazon AWS P4/P5 и Meta со своим Research SuperCluster (RSC).
-
Разработать компоненты (ускорители, interconnect).
Но есть еще и четвёртый, самый сложный путь, когда оптимизации заходят настолько далеко, что компания готова изобретать собственное железо, чтобы оптимально решать свой класс задач. Так поступает Google со своим TPU и Tesla с project Dojo, Amazon с TRN/INF. Стоит отметить, что за последний год практически все крупные облачные провайдеры поняли — A.I. бум это всерьез и разрабатывают собственные ускорители.
Почему нужно строить свои кластеры
Оптимизация архитектуры
Оптимизация железа под решение конкретных задач
В Яндексе понимали, что тензорная революция трансформер навсегда. За Machine Learning будущее, поэтому нужно иметь по нему экспертизу. Довольно логично научиться строить и планировать кластера для решения конкретных задач. Класс задач, которые планировали решать — обучение трансформеров, и в частности LLM (Large Language Models).
Оптимальное соотношение Compute/Interconnect
Это примерно как подобрать нужный транспорт: чем самолёт лучше корабля? Смотря для чего. Соотношение грузоподъемность/скорость для решения разных задач разное. Корабль медленно идёт, но много перевозит. В нашей ситуации подобрать хорошее соотношение Compute/Interconnect — суперважно, потому что это позволит нам экономить проценты, возможно, десятки процентов, а на наших объёмах это миллион долларов. Ситуацию усложняет и тот факт, что соотношение compute/interconnect сильно зависит от типа модели, которую вы обучаете. Например, тенденция последнего времени строить LLM по модели MixtureOfExperts, которая требует в два раза больше коммуникаций по сети.
Бюджетная эксплуатация
Размещение в ДЦ с дешевым электричеством
После того как был создан правильный кластер, его надо эксплуатировать. Чтобы сэкономить, нужно поставить его в дата-центре с дешёвой электроэнергией.
Free-cooling (охлаждение)
Другая важная история — охлаждение. Чем выше его КПД, тем больше можно на нём экономить. Поэтому все современные дата-центры работают на free-cooling. Он забирает воздух снаружи, прокачивает через сервер и выбрасывает обратно. Нет никакого принудительного охлаждения воздуха через кондиционеры.
Обслуживание своими силами
С другой стороны, когда NVIDIA производит свои сервера, она вынуждена проектировать их под эксплуатацию в любых условиях, даже там, где пыльно, плохое охлаждение и прочее. Поэтому они очень перезакладываются на охлаждение. В дата-центрах Яндекса все сделано для максимальной эффективности. Именно поэтому уровень запыленности у них снижен настолько, что можно не использовать обычные, казалось бы, тряпочки на радиаторах, чтобы они не запылились. Таким образом десятки тысяч долларов в месяц экономятся банально на охлаждении.
Вторая жизнь GPU
Разбираем морально устаревший DL-кластер
Что происходит с кластером, когда он начинает морально и физически устаревать? Спустя несколько лет железо для Deep Learning кластеров довольно быстро деградирует в моральном смысле, потому что вы можете позволить себе купить новое железо, которое будет быстрее решать задачу. Именно поэтому нужно придумать, что делать со старыми DL-кластерами.
Более того, GPU со временем деградируют на физическом уровне, когда количество ошибок памяти на HBM GPU начинает значительно расти. Это становится большой проблемой для DL-кластеров, которые работают как единое целое. Представьте, у вас один GPU ловит сбой один раз в год, что в принципе не проблема. Но если 1,5 тысячи GPU работают как единое целое, то это означает, что ваш кластер будет ловить сбои 3-5 раз в день. В таком варианте обучать модель уже очень сложно.
Поэтому с какого-то момента лучше разобрать кластер и отдать его в Inference, а задачи Inference затрагивают только одну реплику. Одна реплика — один GPU. Если произойдёт сбой, то просто перезагрузите ноду.
Чтобы сэкономить и отдать GPU на вторую очередь жизни в какой-то момент, нам надо учиться с ним работать. Ровно поэтому надо учиться строить свои кластера.
Способ построения кластера
GPU-кластер со свалки (Уровень №1)
Начали с самого простого — собрать кластер «со свалки». У RnD-инженеров в Яндексе под столами лежали какие-то сервера. Их набили тем, что было под рукой, а именно:
-
x8 V100 NVIDIA GPU;
-
x2 ConnectX5 RoCEv2 (x8 PCIe, Gen3).
Поставили, включили и получили забавные проблемы:
i. Плохая поддержка Ipv6 в HPC-библиотеках;
HPC мир до сих пор живёт в прошлом, в основном все библиотеки используют протокол Ipv4. В дата-центрах Яндекса уже несколько десятков лет живут только в Ipv6. Поэтому им пришлось дописать некоторые патчи для Open MPI, Fuse и прочего. Они опубликованы тут.
ii. Адаптация container runtime;
Как практически все большие компании, Яндекс использует свой контейнер runtime, а не Docker. Поэтому потребовались некоторые усилия, чтобы засунуть GPU в контейнер.
iii. Проблемы с масштабируемостью на два узла.
Самая большая проблема возникает тогда, когда все уже готово, собран прототип, но обучение не масштабируется. При объединении двух узлов в один кластер, у Яндекс сначала не получалось ожидаемое линейное масштабирование. В попытках понять, что пошло не так, один из RnD-инженеров предложил очень простую, но суперэффективную методологию, которую назвали кардиограммой машинного обучения.
Кардиограмма машинного обучения

На одном графике строится потребление энергии GPU и BW передачи информации по сети. Тут всё сразу становится понятно: синяя полка — это шаг когда отдельный GPU считает свой кусочек. После того как он закончил, он должен обменяться посчитанными градиентами со всеми GPU, которые участвуют в обучении. Видно, что на это тратится примерно половина времени, потому что соотношение compute/interconnect подобрано неправильно. Поэтому максимум, что мы можно получить на подобном кластере «со свалки» — масштабирование 50%.
Это был простой, но очень важный урок. Стало понятно, где могут быть засады. Что-то тестировать на таком кластере уже было можно, у ML инженеров появились первые данные. А разработчики начали проектировать на чём обучать настоящие большие модели.
Первый большой кластер (Уровень №1)
Первый большой кластер, который впоследствии назвали Ляпунов, был первого уровня:
-
Платформа Inspur;
-
X8 NVIDIA GPU A100 40G (100 TFlops);
-
Mellanox 200 Gb/s Infiniband;
-
Пропускная способность памяти 180 GB/s
Для этого купили готовое железо Inspur с 8 A100 GPU, и решили использовать в качестве Interconnect Infiniband.
Выбор типа сети
Почему именно Infiniband?
Когда вы имеете дело с вычислителями GPU, нужны микросекундные latency, потому что скорость вычислителя настолько большая, что это может обеспечить только Infiniband или очень специально отпимизированныйй Ethernet.
Скорость копирования одной страницы памяти 4к по 200 Gb/s Infiniband — это 24GB/s, latency — 1 ms. По факту это равно копированию памяти внутри хоста.
Дальше встал ещё один важный вопрос.
Сколько сети нужно добавить в один сервер
Можно было пойти стандартным путем и сделать так, как это делает NVIDIA: 8 GPU = 8 сетевых карт. Но это универсальный суперкомпьютер, а хотелось чуть-чуть сэкономить, поэтому решили поэкспериментировать:
-
X2 48 GB/s => 400 узлов в кластере
-
x4 96 GB/s => 200 узлов в кластере
-
x8 192 GB/s => 100 узлов в кластере
Перед вами кардиограмма машинного обучения, когда в сервере стоят 8 GPU и 4 сетевых карты:

Видно, что обмен данными (жёлтая ступень) занимает немного времени. Если увеличить бандл сети в 2 раза, то пик станет в 2 раза уже. Но если оставить соотношение 8/4, то это позволит строить кластера в 2 раза большего размера, потому что стандартная топология Infiniband ограничена 800 портами. Кроме этого, построение кластера станет чуть дешевле, потому что Interconnect в кластерах машинного обучения составляет довольно большую часть стоимости.
Кластер после оптимизации внутри хоста
Дальше были попытки выжать максимум заявленного перформанса. Об этом подробнее описано в статье «Суперкомпьютеры Яндекса: взгляд изнутри». Здесь подведём итог:

В какой-то момент после долгих ночных хакатонов на 136 узлах получили из теоретической пропускной способности в 96 GB/s на реальном NCCL-тесте, который эмулирует передачу данных по GPU через Interconnect 86 GB/s. Тогда это показалось достаточным.
После этого встал выбор, что дальше делать:
i) Либо отдавать кластер ML-инженерам, чтобы они могли начать обучать свои модели.
ii) Либо начать тестировать для ТОП-500, как советовали инженеры из NVIDIA.
В Яндекс решили, что второе решение слишком расточительно (было 25 декабря и кластер бы простаивал все Новогодние праздники), поэтому его отдали ML-инженерам, а замер ТОП-500 отложили на попозже.
Второе поколение кластеров (Уровень №2)

Следующим шагом стало построению собственной платформы на основе готовых компонентов. Для этого взяли уже готовую, созданную в Яндексе CPU платформу Yandex-4.0. В неё добавили самый свежий на тот момент NVIDIA GPU A100-80, те же самые соотношения сети. Это уже был серьезный кластер из 200 узлов. Появилась возможность провести полноценные тесты для ТОП-500.
Казалось бы, что может пойти не так?
Оказалось, что примерно всё.
Как получить хорошее масштабирование
Для попадания в ТОП-500 необходимо прогнать очень простой тест Linpack, современная версия которого называется HPL. По факту он просто решает систему линейных уравнений.
Вот два последовательных измерения на одном и том же кластере:

Здесь видны графики, хотя результатом теста будет только число. Эти два измерения отличаются примерно на 1 PFLops. Для вычисления 1 PFLops требуется оборудования примерно на миллион долларов. Такая девиация производительности означает, что что-то не то. Поэтому посмотрели на характеристики в runtime. Идеальный график обмена по сети Interconnect — это плоская ступенька на уровне максимальной скорости сети, потому что количество вычислений — это площадь фигуры под графиком. Видно, что на тесте есть провалы. Надо было разобраться откуда они взялись.
Схема работы распределённого алгоритма
Здесь надо вспомнить какая задача решается. Дети, которые передают друг другу мяч — это и есть распределённый алгоритм. Мы все хорошо понимаем, что произойдет, если девочка, которая сейчас ловит мяч, отвлечется — мячик упадет, игра остановится, все дети заскучают.

Ровно то же самое у нас. Если данные от одного единственного GPU не были вовремя доставлены по сети, все остальные тысячи GPU простаивают в ожидании этих данных. А скорость работы GPU столь огромна, что даже микросекундные задержки серьезно влияют на производительность.
Linpack под микроскопом
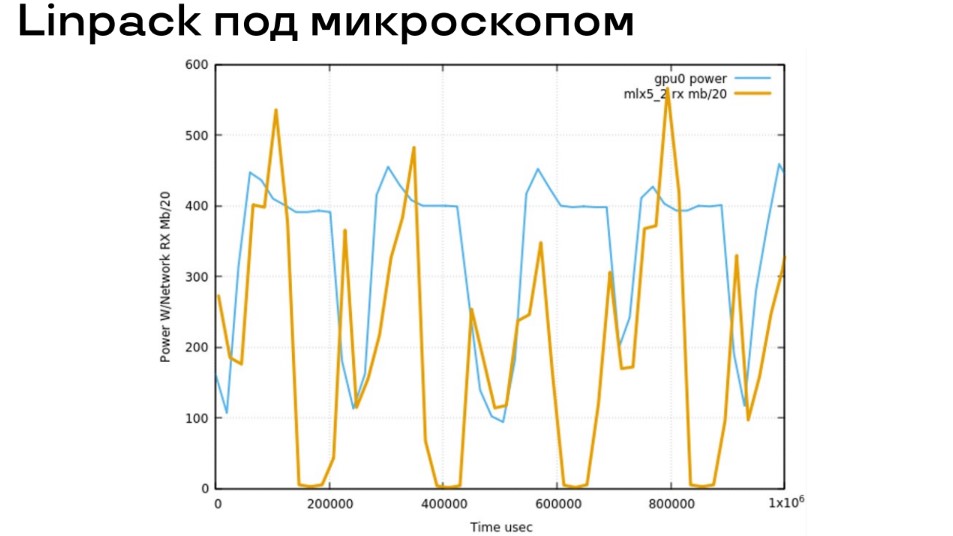
На самом деле эта кардиограмма Linpack под микроскопом за 1 секунду демонстрирует тот же распределённый алгоритм, что и в детской игре в мяч. Видно, что за секунду происходит больше 4 циклов. Более того, есть первый шаг, где данные передаются параллельно с вычислением на GPU. Это означает, что передачей данных управляет процессор, то есть процессор в вычислениях тоже важен, а не только GPU. Вторая важная часть, когда вычисления на GPU закончились, есть некоторая синхронная фаза, когда после окончания вычислений синхронно посылаются данные.
После этого стало понятно в чём проблемы схемы работы распределенного алгоритма:
-
Скорость работы алгоритма равна скорости самого медленного звена.
В случае детей потеря мячика — это задержка игры, а в случае перегрева одного единственного GPU из полутора тысяч, которые участвуют в кластере, все остальные простаивают и ждут от него данных. Поэтому требовалось научиться находить такие перегревающиеся GPU.
-
Перегрев одного GPU тормозит конвейер вычислений.
Раньше в Яндексе такое не детектировали, потому что у них был стресс тест для GPU, который проверял GPU не “плавится” при 100% нагрузке. Но в случае достижения определенной температуры активизировался температурный тротлинг и производительность GPU снижалась и тормозился весь кластер. Linpack очень надежно загонял GPU в критические режимы и выявлял перегрев GPU, после чего инженеры меняли радиаторы с термопастой и проблема решалась.
-
Привязки CPU к NUMA недостаточно. Явный cpuse.
Если говорить о передаче данных по сети, речь идёт о микросекундных задержках. Если вовлекается Linux шедулер, то идет потеря в перформансе. Поэтому только явное пробивание процессов к CPU исключает Linux шедулер из уравнения, и получается плюс 15%.
-
Форсирование HUGEPAGES (2 MB) => +5-10%.
Любые дробилки чисел выигрывают, если использовать HUGEPAGE. Это даёт +5-10%.
-
Неполный набор устройств в контейнере runtime => +10%
В Яндекс был кластер, который находился в продакшне примерно полгода. Оказалось, что Linpack смотрел на одно из устройств, которое на самом деле не участвует в тесте. По этому устройству он делал некоторые выводы, и вместо того, чтобы падать, работал на 10% медленнее. Поэтому, когда вы что-то тестируете, всегда надо сравнивать производительность bare-metal контейнера.
Первый большой замер
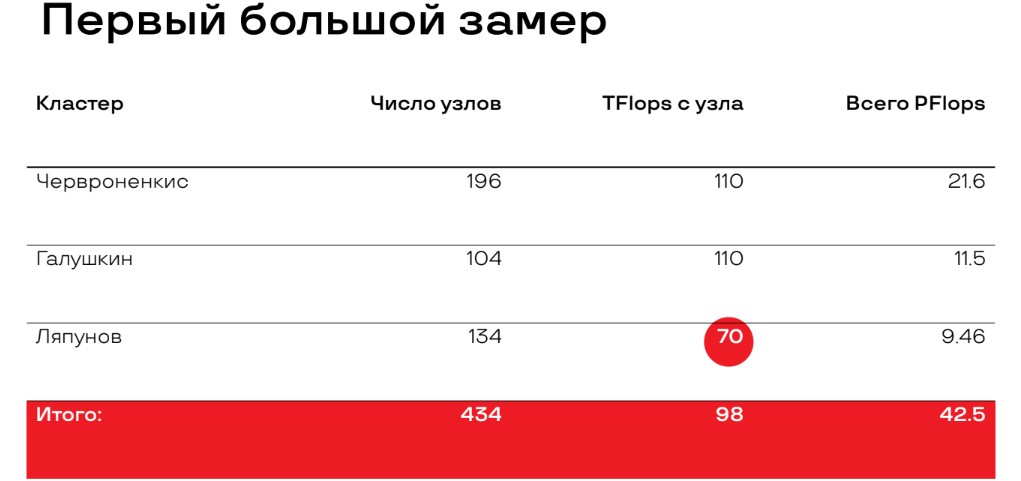
Все наработки были внедрены в два самых новых кластера. Замеры показали, что они дают довольно приличный перформанс, а тот кластер, который был в продакшене уже 9 месяцев, показал крайне неубедительный результат. Стало понятно, что надо выводить его на обслуживание и разбираться, что не так.
Выяснилось несколько простых вещей.
Второй замер Ляпунов

Баг в Interconnect, который вроде бы давным-давно починили, на новых кластерах очень сильно влиял на большие обучения. Адаптивный роутинг по факту был сломан.
Последний баг самый смешной. На кластере было несколько GPU, у которых программно было ограничено потребление энергии в 350 W. Казалось бы, в чём проблема от того, что несколько GPU работают на 25% медленнее? Дело в том, что мы имеем дело с распределённым алгоритмом, и скорость его работы лимитируется самым медленным звеном. Это означает, что по факту весь кластер работал как самый медленный GPU, то есть на 25% медленнее.
После того как все поправили, получился плюс 3,5 PFlops, а именно 35%, грубо говоря, из воздуха.
Более того, было еще третье измерение. После второго измерения заметили, что график обмена по сети всё равно ещё не идеален. А пытаясь понять, что пошло не так, выяснили, что мониторинги, собирающие метрики GPU, стоили 2% производительности GPU. После того как починили и это, суммарная производительность кластеров, которую по факту уже заявили в ТОП-500, составила 50 PFlops.
Итог
Оптимальный размер кластера
Как правильно строить: один большой кластер или несколько кластеров среднего размера, но идентичных?
У одного кластера есть очевидные плюсы:
-
Можно наращивать по мере необходимости;
-
Простой планировщик задач.
Проблема в том, что когда у вас один кластер, он становится тотемом для поклонения. С ним ничего нельзя сделать: его нельзя вывести в обслуживание, Иначе ML-инженерам не будет на чём обучать модели.
С несколькими кластерами среднего размера, наоборот. Один из кластеров всегда можно вывести на обслуживание, а обучение продолжится на остальных. Это очень практичный инженерный подход:
-
Ограничение максимального параллелизма 1600 GPU
-
Экономия на затратах на Interconnect
-
Легко обновлять окружение
-
Возможность проводить эксперименты
Правила эксплуатации и построения GPU кластеров
Вот то, к чему каждый ML-инженер должен быть готов:
— Распределённое обучение — это новая норма.
Распределённое обучение означает использование распределённых алгоритмов, которые являются самой сложной областью исследования в Computer Science. Поэтому, если вы собираетесь обучать огромные модели, то стоит уделить некоторое время основам. Это сильно сэкономит ваше время и деньги компании.
— Тестирование железа на всех этапах обучения.
Когда в обучении задействованы сотни или тысячи GPU и тысячи сетевых карт, отказы железа неизбежны. Поэтому необходимо уметь детектить их на любом этапе обучения.
— Обучение должно быть готово к отказам железа.
Обучение, которое длится месяцами, должно быть готово к отказу единственного узла. Перезапуск задачи должен происходить максимально быстро, иначе вы будете терять время и огромные деньги.
— Постоянный семплинг статуса ML-задачи в runtime.
Это будет гарантировать, что вы не потеряете время, если ваша ML-задача вдруг зависнет.
— Традиционные способы отладки слишком дороги на таких объёмах, когда один день простоя кластера стоит 20 тысяч долларов.
Если мы занимаемся проблемой неделю, то это означает, что компания в это время теряет сотни тысяч долларов, что неприемлемо. Поэтому надо учиться максимально быстро справляться с задачами и, самое главное, уметь заранее предвидеть их.
— Размер кластеров не должен превышать уровень экспертизы, который у вас уже есть.
В какой-то момент размер кластера может обогнать ваше понимание, тогда вы начнёте терять в темпе и кластера будут простаивать. Поэтому во время новых экспериментов, можно сокращать размер кластера, чтобы время его простая не было столь значительным.
Телеграм: t.me/ainewsline
Источник: habr.com