AudioGPT модель генерации звуков из текста на основе трансформера
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2023-05-07 15:40

AudioGPT — text-to-speech и text-to-audio модель от OpenAI, основанная на серии языковых моделей GPT. AudioGPT способна генерировать аудио-сэмплы с естественно звучащей речью, музыку и выполнять задачи классификации. Модель может оказать значительное влияние на приложения, использующие голосовых помощников, синтез речи из текста и генерацию музыки. Это первая успешная попытка применения архитектуры трансформера к обработке аудио.

Исходный код модели
Разработчики выложили код модели в открытом доступе на Github. Репозиторий содержит реализацию модели на PyTorch и TensorFlow, а также скрипты для обработки данных и обучения модели. Кроме того, в репозитории также содержится набор данных, на котором была обучена модель, а также примеры использования модели для генерации аудио на основе заданных текстовых входных данных.
Репозиторий не является официальным источником кода модели AudioGPT, но может быть полезным для тех, кто заинтересован в использовании этой модели для своих задач.
Обучение
AudioGPT использует текст в качестве входных данных и обучается на любом языке. Модель принимает на вход текстовую последовательность, которая может быть произвольной длины — предложения, абзацы, статьи или диалоги, и генерирует соответствующую аудиозапись, которая соответствует заданному тексту.
В процессе обучения модели входные данные обычно подвергаются предварительной обработке, такой как токенизация и векторизация, чтобы представить текст в виде числовых последовательностей, которые могут быть использованы для обучения модели.
Архитектура AudioGPT
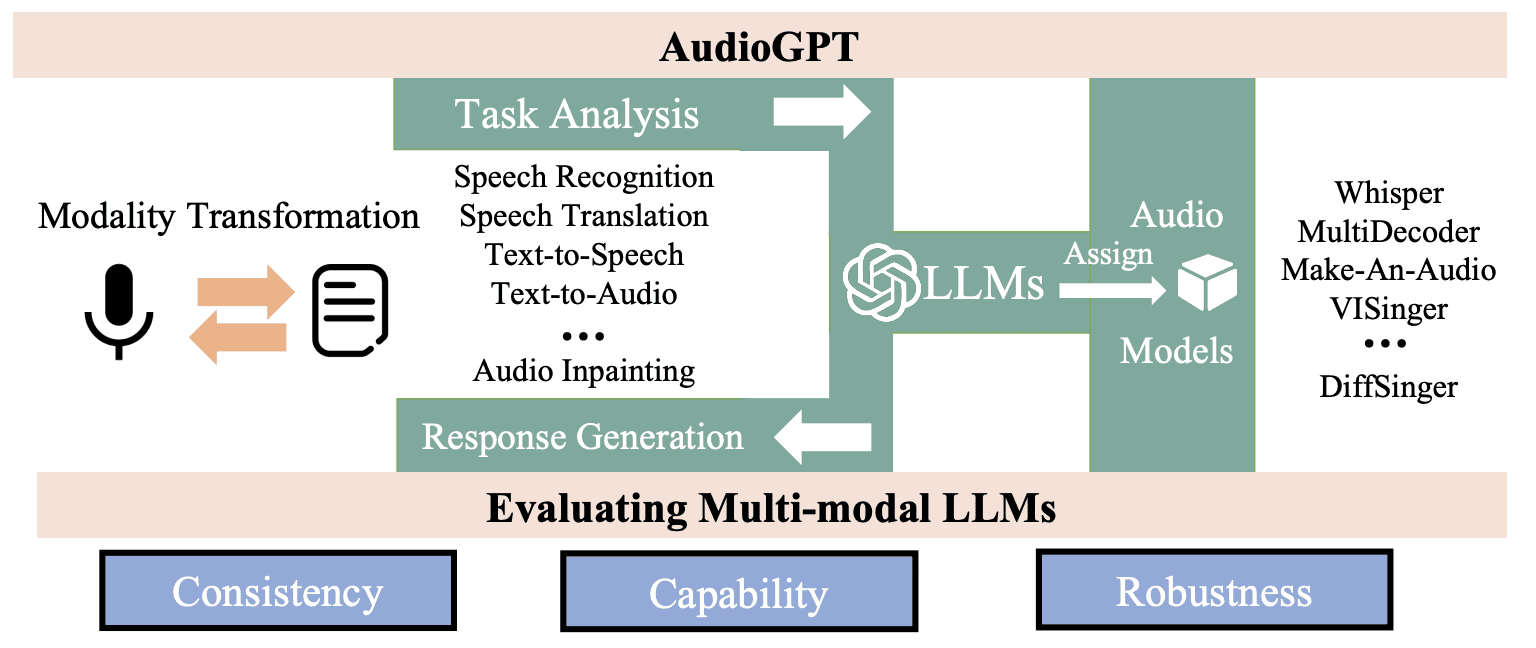
Модель AudioGPT построена на архитектуре трансформера, которая состоит из слоев само-внимания и нейронных сетей с обратной связью. Эта архитектура способна улавливать неочевидные корелляции и производить последовательные выводы. В AudioGPT архитектура используется для моделирования зависимостей между различными частями звукового сигнала, такими как частотные и временные компоненты. Модель обучается на большом наборе аудио-сэмплов, что позволяет ей изучать статистические закономерности, характерные для естественных звуков.
Датасет
AudioGPT обучалась на датасете LJSpeech. Это набор из более чем 13 000 аудиозаписей, продолжительностью в общей сложности около 24 часов (средняя длина семпла — 6,6 секунд). Аудиозаписи в наборе данных были записаны женским голосом на английском языке, для каждой аудиозаписи предоставлены транскрипции в виде текстовых файлов.
Результаты
Результаты оценивались по метрике MOS (Mean Opinion Score) — это среднее значение оценок качества, которые дает группа экспертов или респондентов на шкале от 1 до 5, где 1 — очень плохо, 3 — средне, 5 — отлично.
- Генерация звука: модель была обучена генерировать звуковые сигналы различной продолжительности. Среди сгенерированных звуковых сигналов были голоса людей, музыкальные композиции, шумы и звуки природы. В задаче генерации звука AudioGPT показала MOS в размере 3,57.
- Классификация звука: AudioGPT достигла точности классификации на уровне 90%. Ей было предложено распознать различные звуковые сигналы, включая голоса людей, звуки животных, шумы и музыку.
- Генерация речи: AudioGPT показала MOS в размере 3,7. В ходе эксперимента были использованы образцы текста на английском языке.
Телеграм: t.me/ainewsline
Источник: neurohive.io