Проверьте свои факты и попробуйте еще раз: Улучшение больших языковых моделей с помощью внешних знаний и автоматической обратной связи
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2023-04-06 15:47

Большие языковые модели (LLM), такие как ChatGPT, способны генерировать человекоподобные, беглые ответы для многих последующих задач, например, диалог, ориентированный на выполнение задач, и ответы на вопросы. Однако применение LLM к реальным критически важным приложениям остается сложной задачей, главным образом из-за их склонности порождать галлюцинации и неспособности использовать внешние знания.
В этом блоге представлена наша работа над LLM-Augmenter, системой, которая решает именно эти проблемы, дополняя LLM из черного ящика набором модулей plug-and-play: наша система позволяет LLM генерировать ответы, основанные на внешних знаниях, например, хранящихся в базах данных для конкретных задач. Он также итеративно пересматривает подсказки LLM для улучшения ответов модели, используя обратную связь, генерируемую служебными функциями, например, оценку достоверности ответа, сгенерированного LLM.
Мы проверяем эффективность LLM-Augmenter, используя два типа задач: диалог поиска информации и ответы на вики-вопросы открытого домена (Wiki QA). Наши эксперименты показывают, что во всех задачах LLM-Augmenter значительно улучшает основательность ChatGPT во внешних знаниях, не жертвуя при этом человечностью генерируемых ответов. Например, в диалоговой задаче обслуживания клиентов оценка персонала показывает, что LLM-Augmenter улучшает ChatGPT на 32,3% по полезности и на 12,9% по человечности (измерение беглости и информативности ответов модели). Задача контроля качества Wiki чрезвычайно сложна для ChatGPT в том смысле, что для ответа на эти вопросы часто требуется многоходовое рассуждение, чтобы собрать воедино информацию различных модальностей, разбросанную по разным документам. Наши результаты показывают, что, хотя закрытая книга ChatGPT работает плохо и часто вызывает галлюцинации, LLM-Augmenter существенно улучшает оценку достоверности ответов (+10% в F1), основывая ответы ChatGPT на консолидированных внешних знаниях и автоматической обратной связи.
Мы более подробно описываем эту работу в нашей статье и размещаем ее код на github.
Обзор
LLM-Augmenter улучшает LLM с помощью внешних знаний и автоматической обратной связи с использованием модулей plug-and-play (PnP), как показано в следующем примере:
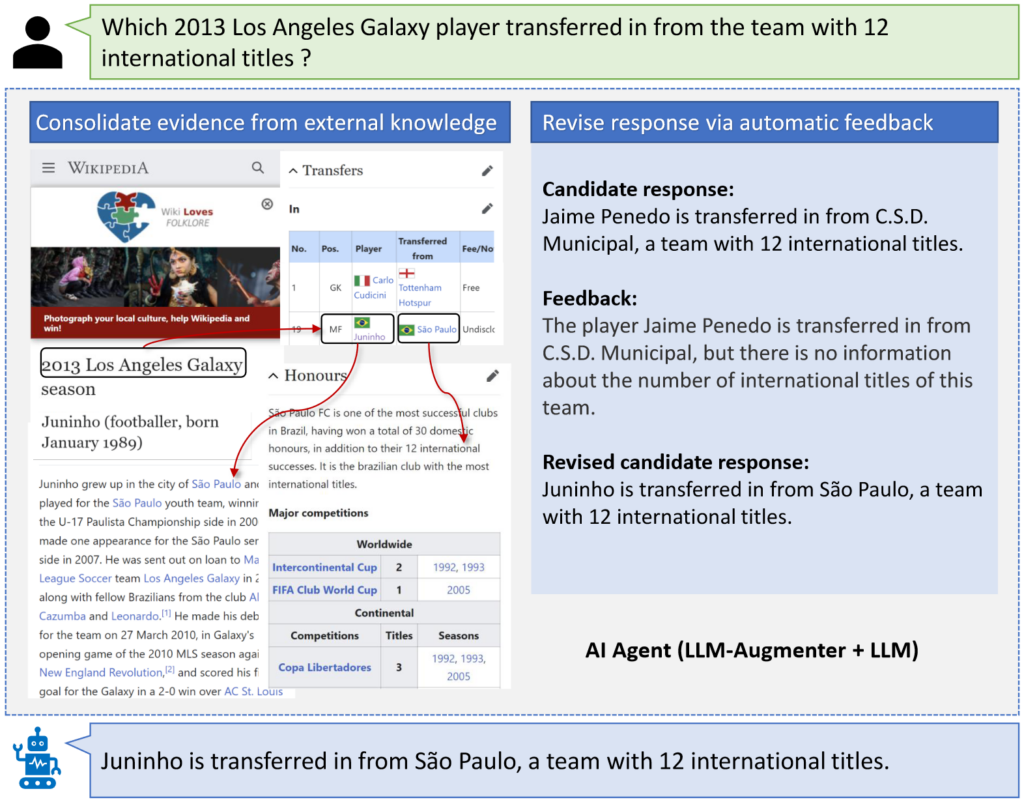
LLM-AUGMENTER улучшает фиксированный LLM путем (1) объединения доказательств из внешних источников, чтобы LLM генерировал ответы, основанные на доказательствах, и (2) пересмотра ответов LLM (кандидата) с использованием автоматической обратной связи.
Получив запрос пользователя (например, относительно трансфера игрока "Лос-Анджелес Гэлакси" в 2013 году), LLM-Augmenter сначала извлекает доказательства из внешних источников (например, из Интернета или наборов данных, специфичных для конкретной задачи). При необходимости он дополнительно консолидирует доказательства, связывая извлеченные исходные доказательства с соответствующим контекстом (например, информация о компании “Лос-Анджелес Гэлакси 2013”) и выполняет рассуждения для формирования цепочек доказательств (например, таблица-отрывок на рисунке). Затем LLM-Augmenter запрашивает фиксированный LLM (т.е. ChatGPT в нашей работе), используя приглашение, содержащее сводные данные для ChatGPT, чтобы сгенерировать ответ кандидата, основанный на внешних знаниях. Затем LLM-Augmenter проверяет ответ кандидата, например, проверяя, не является ли он доказательством галлюцинации. Если это так, LLM-Augmenter генерирует сообщение обратной связи (например, о команде “C.S.D. Municipal”). Это сообщение используется для пересмотра запроса на повторный запрос ChatGPT. Процесс повторяется до тех пор, пока ответ-кандидат не пройдет проверку и не будет отправлен пользователю.
Архитектура
Архитектура LLM-Augmenter проиллюстрирована на следующем рисунке:

Архитектура LLM-Augmenter показывает, как его модули plug-and-play взаимодействуют с LLM и пользовательской средой.
LLM-Augmenter состоит из набора модулей PnP (т.е. рабочей памяти, политики, исполнителя действий и утилиты) для улучшения фиксированного LLM (например, ChatGPT) с помощью внешних знаний и автоматической обратной связи для смягчения проблем генерации, таких как галлюцинации. Мы формулируем диалог между человеком и системой как марковский процесс принятия решений (MDP), который использует следующие модули PnP:
- Рабочая память: отслеживает состояние диалога, в котором фиксируется вся необходимая информация из разговора на данный момент.
- Исполнитель действия: Этот модуль выполняет действие, выбранное модулем политики. Он состоит из двух компонентов: средства консолидации знаний и механизма подсказок. Средство консолидации знаний предоставляет LLM возможность основывать свои ответы на внешних знаниях, чтобы уменьшить галлюцинации при выполнении заданий, таких как ответы на вопросы, касающиеся последних новостей, и бронирование столика в ресторане. Механизм подсказок генерирует приглашение для запроса LLM.
- Полезность: Учитывая возможный ответ, модуль полезности генерирует оценку полезности и соответствующую обратную связь, используя набор функций полезности для конкретной задачи (например, KF1).
- Политика: Этот модуль выбирает следующее системное действие, которое приведет к наилучшему ожидаемому вознаграждению. Эти действия включают в себя (1) получение доказательств из внешних источников, (2) вызов LLM для генерации ответа-кандидата и (3) отправку ответа пользователям, если он проходит проверку служебным модулем.
Политика может быть реализована с использованием правил, созданных вручную, или обучена взаимодействию человека с системой. В нашей работе мы реализуем обучаемую политику в виде модели нейронной сети и оптимизируем ее с помощью REINFORCEMENT. Подробная информация о нашем подходе и этих модулях PnP представлена в документе.
Результаты
В нашей статье представлены обширные эксперименты по трем задачам, но в этом блоге мы сосредоточимся на задаче поддержки клиентов. Мы сравниваем ChatGPT с LLM-Augmenter и без него. В общей сложности для оценки персонала используется около 1000 случайно выбранных примеров из набора данных службы поддержки клиентов. Мы наблюдаем сильное предпочтение LLM-Augmenter перед одним только ChatGPT как с точки зрения полезности, так и гуманности. Результат согласуется с результатами автоматической оценки, представленными в документе.
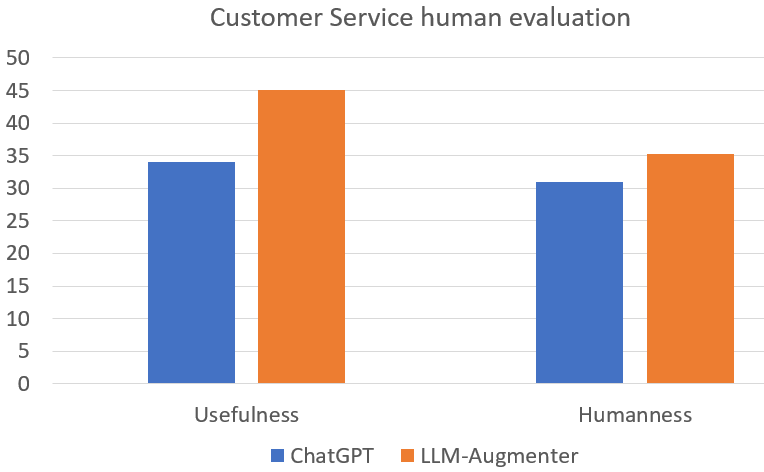
LLM-Augmenter значительно превосходит ChatGPT как с точки зрения полезности, так и гуманности.
Примеры
На следующем рисунке показаны реальные примеры сравнения ChatGPT с LLM-Augmenter:
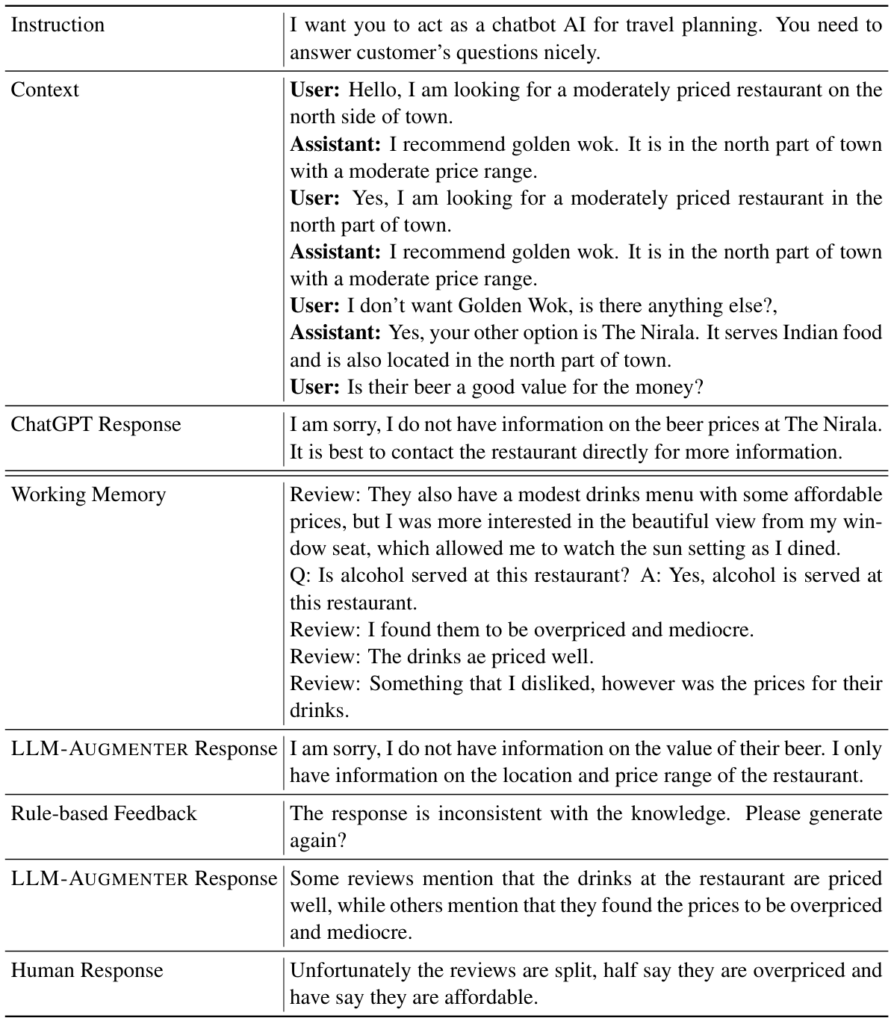
Примеры LLM-дополнения.
В приведенной выше таблице приведены примеры ответов, сравнивающих LLM-Augmenter с ChatGPT. Во-первых, мы видим, что ChatGPT не может предоставить ответ, связанный с конкретными знаниями, относящимися к пользователю, например, о местном индийском ресторане. Во второй части таблицы мы показываем рабочую память LLM-Augmenter, которая выделяет более богатую информацию, полученную из внешних знаний, чтобы помочь базовому LLM (т.е. также ChatGPT) генерировать более удовлетворительные ответы. Первый ответ LLM, полученный LLM-Augmenter, к сожалению, неудовлетворителен, поскольку качество и специфичность генерации LLM могут быть непредсказуемыми. В этом случае служебный модуль определил, что первый ответ не соответствовал его критериям (т.е. KF1 превышает заданный порог), и выдает обратную связь модулю LLM (т.е. “ответ не соответствует знаниям”). Второй ответ, полученный LLM-Augmenter, гораздо более удовлетворителен в соответствии с функцией полезности и, следовательно, отправлен пользователю.
Подтверждения
Это исследование было проведено Баолином Пэном, Мишелем Галли, Пэнчэн Хэ, Хао Чэном, Юцзя Се, Ю Ху, Цююань Хуаном, Ларсом Лиденом, Чжоу Юем, Вэйчжу Ченом, Цзяньфэн Гао из Microsoft Research. Мы также благодарим Салиму Амерши, Ахмеда Авадаллу, Нгуен Баха, Пола Беннетта, Криса Броккетта, Вэйсин Кая, Дивью Эсваран, Адама Фурни, Сяо-Вен Хона, Чуньюань Ли, Рики Лойнда, Хойфунг Пуна, Корби Россета, Бин Ю, Шэн Чжана и членов группы глубокого обучения Microsoft Research за ценные обсуждения и комментарии.
Источник: www.microsoft.com