
OpenAI добавил поддержку плагинов в ChatGPT, и теперь он может подключаться к сторонним сервисам и искать информацию в сети. А помните, была такая компания Гугл?
В этой статье я хотел бы рассказать о самом, на мой взгляд, интересном плагине, который позволяет искать ответы в собственной базе.
Основные преимущества плагина
- Семантический поиск: Плагин позволяет получать наиболее релевантные фрагменты документов, задавая вопросы на естественном языке.
- Интеграция с векторными базами данных: Retrieval Plugin использует модель эмбеддингов OpenAI для генерации векторных представлений документов и их поиска в векторной базе данных. Причем он позволяет использовать разные базы для векторного поиска.
- Функция памяти для ChatGPT: Плагин позволяет сохранять фрагменты разговоров для дальнейшего использования, тем самым обеспечивая контекстно-зависимый диалог.
Установка и интеграция плагина
Чтобы начать использовать Retrieval Plugin, вам потребуется:
- Получитьключ для использования OpenAI API.
- Сгенерировать
BEARER_TOKEN. Можно использовать этотсервис. - Настроить базу данных для хранения собственных документов. Плагин предоставляет возможность выбрать из следующего списка (
pinecone,weaviate,zilliz,milvus,qdrant, илиredis), но код можно допилить и для собственного варианта (куда же без elasticsearch). В обзоре я буду использоватьpinecone. - Создать и настроить собственный сервер FastAPI.
Настраиваем хранилище pinecone
- Регистрируемсяв pinecone. Можно с помощью github-аккаунта.
- Получаем ключ API.
- Создаем свой собственный индекс, это можно сделать в приложении либо через питоновскую библиотеку.
# PINECONE_ENVIRONMENT - можно посмотреть в приложении, в моем примере выше это значение равно us-west4-gcp # PINECONE_INDEX - название для вашего индекса import os, pinecone pinecone.init(api_key=os.environ['PINECONE_API_KEY'], environment=os.environ['PINECONE_ENVIRONMENT']) pinecone.create_index(name=os.environ['PINECONE_INDEX'], dimension=1536, # размерность вектора, в данном случае будут использоваться эмбеддинги Open AI metric='cosine', metadata_config={ "indexed": ['source', 'source_id', 'url', 'created_at', 'author', 'document_id']}) Настраиваем окружение для проекта
- Поставьте Python 3.10
- Клонируйте репозиторий:
git clone https://github.com/openai/chatgpt-retrieval-plugin.git - Перейдите в папку с репозиторием:
cd /path/to/chatgpt-retrieval-plugin - Установите poetry:
pip install poetry. Можно использовать и другой способ создания виртуального окружения, но тогда надо будет внести исправления в код проекта. - Создайте виртуальное окружение с Python 3.10:
poetry env use python3.10 - Активируйте виртуальное окружение:
poetry shell - Установите зависимости приложения:
poetry install - Задайте необходимые переменные окружения.
export BEARER_TOKEN=<your_bearer_token> export OPENAI_API_KEY=<your_openai_api_key> export DATASTORE=pinecone export PINECONE_API_KEY=<your_pinecone_api_key> export PINECONE_ENVIRONMENT=<your_pinecone_env_key> export PINECONE_INDEX=<your_pinecone_index> - Запустите API локально:
poetry run start. Если вы все сделали по инструкции, то в терминале вы увидите нечто похожее на картинку ниже. Я создал индекс с оригинальным названиемtest, поэтому плагин подключается к нему.
- Если перейти по ссылке
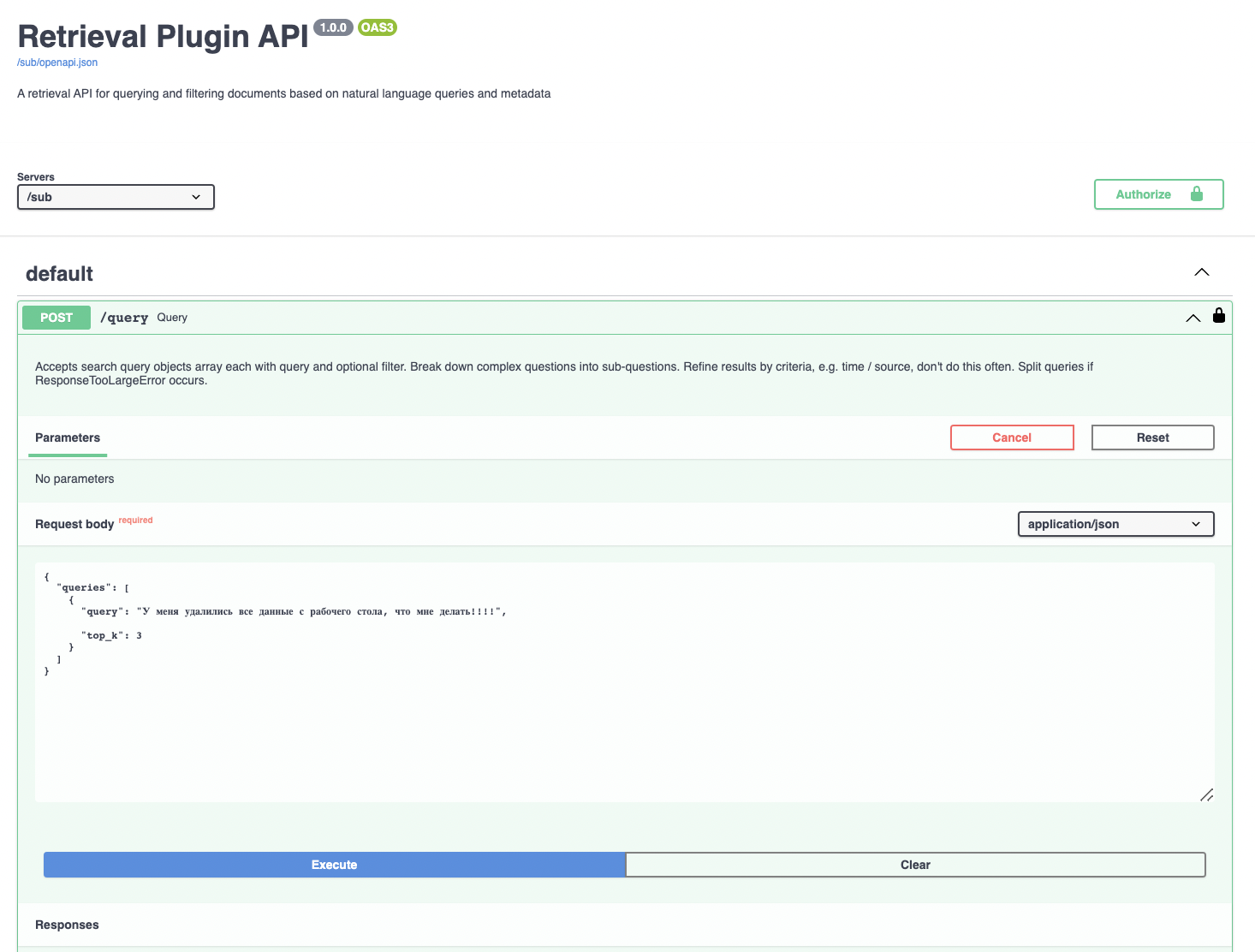
http://0.0.0.0:8000/docs, то попадете на страничку с документацией. Здесь же можно производить отладку. Нажмите наauthorizeи введитеBEARER_TOKEN, который указали в настройках.
Больше полезных материалов вы найдете на нашем телеграм-канале «Библиотека data scientist’а»
Описание эндпоинтов
Плагин предоставляет следующие эндпоинты для работы с документами:
/upsert: Загрузка и хранение текста и метаданных одного или нескольких документов в векторной базе данных. Документы разбиваются на фрагменты размером около 200 токенов, каждый с уникальным идентификатором./upsert-file: Позволяет загрузить один файл (PDF, TXT, DOCX, PPTX или MD) и сохранить его текст и метаданные в векторной базе данных. Файл конвертируется в простой текст и разбивается на части примерно по 200 токенов, каждая с уникальным идентификатором./query: Запрос к векторной базе данных с использованием одного или нескольких запросов на естественном языке и дополнительных фильтров метаданных. Возвращает список объектов, каждый из которых содержит список наиболее релевантных фрагментов документов для заданного запроса./delete: Удаление одного или нескольких документов из базы данных с использованием их идентификаторов, фильтра метаданных или флага удаления всех документов.
Тестируем индекс
Пришло время опробовать плагин в работе. К сожалению, это не получится сделать в самом приложении ChatGPT, т. к. функционал пока ограничен, и для интеграции нужно вставать в очередь. Но кое-что можно попробовать сделать, например, протестировать векторный поиск.
Представим себе, что мы хотим автоматизировать службу поддержки. Наша цель – научить бота автоматически отвечать на вопросы пользователей и давать им дополнительную информацию в виде ссылок на внутреннюю документацию(это может быть confluence).
Попросим ChatGPT придумать нам примеры для такого индекса. Мой промт для этой цели:
Сгенерируй набор из 10 тестовых примеров документов, которые будут добавлены в векторное хранилище pinecone. В документах содержится информаци о запросах в службу поддержки компании. Каждый документ должен иметь следующую структуру: 1. id: int (уникальный идентификатор документа) 2. text: str(основной текст документа) 3. metadata: dict(содержит дополнительную информацию о документе): - title (необязательное поле с названием или описанием документа) - url (ссылка на источник информации, предпочтительно страницу confluence) Обратите внимание, что тексты документов и метаданные должны быть разнообразными и содержательными. Результат должен быть реализован в виде python кода ChatGPT мне предложил следующие варианты:
documents = [ { "id": 1, "text": "Как настроить автоматическое обновление ПО?", "metadata": { "title": "Настройка автоматического обновления", "url": "https://confluence.example.com/display/support/automatic-updates", } }, { "id": 2, "text": "Необходимо восстановить удаленные данные. Какие есть варианты?", "metadata": { "title": "Восстановление удаленных данных", "url": "https://confluence.example.com/display/support/data-recovery", } }, { "id": 3, "text": "Проблемы с подключением к интернету. Как исправить?", "metadata": { "title": "Решение проблем с подключением", "url": "https://confluence.example.com/display/support/internet-connection-issues", } }, { "id": 4, "text": "Как ускорить работу компьютера?", "metadata": { "title": "Оптимизация работы компьютера", "url": "https://confluence.example.com/display/support/computer-optimization", } }, { "id": 5, "text": "Как настроить VPN подключение?", "metadata": { "title": "Настройка VPN", "url": "https://confluence.example.com/display/support/vpn-setup", }, }, { "id": 6, "text": "Сбой при обновлении системы. Как решить проблему?", "metadata": { "title": "Решение проблем с обновлением системы", "url": "https://confluence.example.com/display/support/update-failure", } }, { "id": 7, "text": "Как настроить электронную почту на мобильном устройстве?", "metadata": { "title": "Настройка электронной почты на мобильных устройствах", "url": "https://confluence.example.com/display/support/mobile-email-setup", } }, { "id": 8, "text": "Проблемы с печатью на сетевом принтере. Как исправить?", "metadata": { "title": "Решение проблем с сетевой печатью", "url": "https://confluence.example.com/display/support/network-printing-issues", } }, { "id": 9, "text": "Как восстановить пароль пользователя?", "metadata": { "title": "Восстановление пароля пользователя", "url": "https://confluence.example.com/display/support/password-recovery", }, } { "id": 10, "text": "Как установить и настроить брандмауэр?", "metadata": { "title": "Установка и настройка брандмауэра", "url": "https://confluence.example.com/display/support/firewall-setup", } } ] Теперь индексируем эти примеры в Pycone:
# pip install requests tqdm import os import requests from requests.adapters import HTTPAdapter from requests.packages.urllib3.util.retry import Retry from typing import List, Dict, Optional from tqdm import tqdm BEARER_TOKEN = os.environ.get('BEARER_TOKEN') headers = { 'Authorization': f'Bearer {BEARER_TOKEN}' } def upsert_documents(documents: List[Dict], endpoint_url: str = "http://localhost:8000", batch_size: int = 100, headers: Optional[Dict[str, str]] = None, timeout: float = 10.0): s = requests.Session() # Устанавливаем стратегию повторных попыток для 5xx ошибок retries = Retry( total=5, # количество попыток перед вызовом ошибки backoff_factor=0.1, status_forcelist=[500, 502, 503, 504] ) s.mount('http://', HTTPAdapter(max_retries=retries)) for i in tqdm(range(0, len(documents), batch_size)): i_end = min(len(documents), i + batch_size) try: # Отправляем POST-запрос, разрешая до 5 повторных попыток res = s.post( f'{endpoint_url}/upsert', headers=headers, json={ "documents": documents[i:i_end] }, timeout=timeout ) res.raise_for_status() except requests.exceptions.RequestException as e: print(f'Ошибка при вставке/обновлении: {e}') upsert_documents(documents, headers=headers) В случае успеха в pycone вы должны увидеть проиндексированные документы:
Осталось узнать, будет ли работать этот гениальный код. Для этого надо перейти по адресуhttp://0.0.0.0:8000/sub/docs (да, создатели не поленились и создали отдельную страничку) и написать запрос в нашу базу:
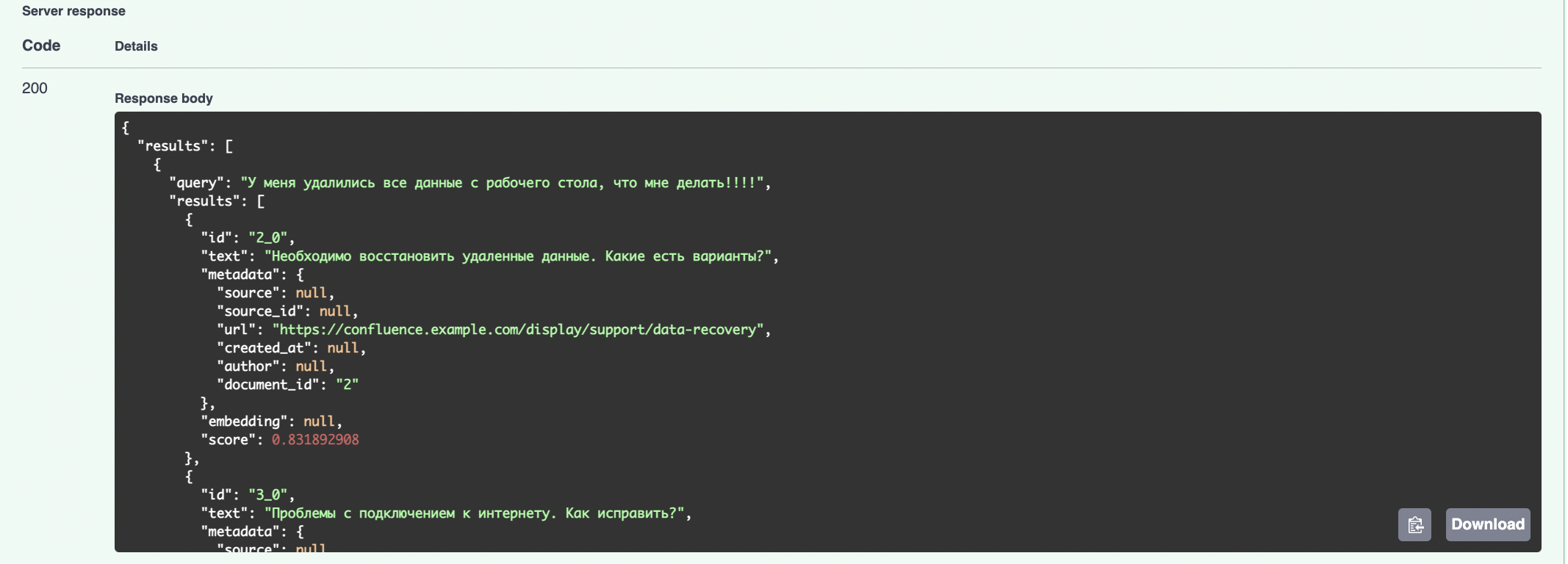
ИИ выдал следующие варианты решения проблемы нашего пользователя:
Внимательный читатель ресурса, возможно, начал догадываться, что где-то он уже это видел. Все верно, похожий функционал был описан в моей предыдущей статье. В ней была реализована базовая версия векторного поиска, но без использования модного хранилища(кстати, тоже на FastAPI).
На сегодня у меня все – в следующей части, если CloseAI все-таки выдаст мне талон, посмотрим, как это будет работать в самом интерфейсе ChatGPT, а также попробуем сохранить историю наших запросов в векторной базе.
Подписывайтесь также на мой канал, в котором я хайпую и спекулирую на теме NLP и AI.
Заключение
Retrieval Plugin значительно расширяет возможности ChatGPT, предоставляя функции семантического поиска, интеграции с векторными базами данных и поддержки памяти. Это позволит погружать модель в контекст необходимой для вас информации. Такой функционал откроет огромные возможности для организаций, которые хотят использовать AI для работы с внутренними документами.